/**
* 根据父编号 获取对应的子菜单信息
* @param list
* @param parentCid
* @return
*/
private List<CategoryEntity> queryByParentCid(List<CategoryEntity> list,Long parentCid){
List<CategoryEntity> collect = list.stream().filter(item -> {
return item.getParentCid().equals(parentCid);
}).collect(Collectors.toList());
return collect;
}
/**
* 查询出所有的2级和三级分类 数据 并封装为json对象
* @return
*/
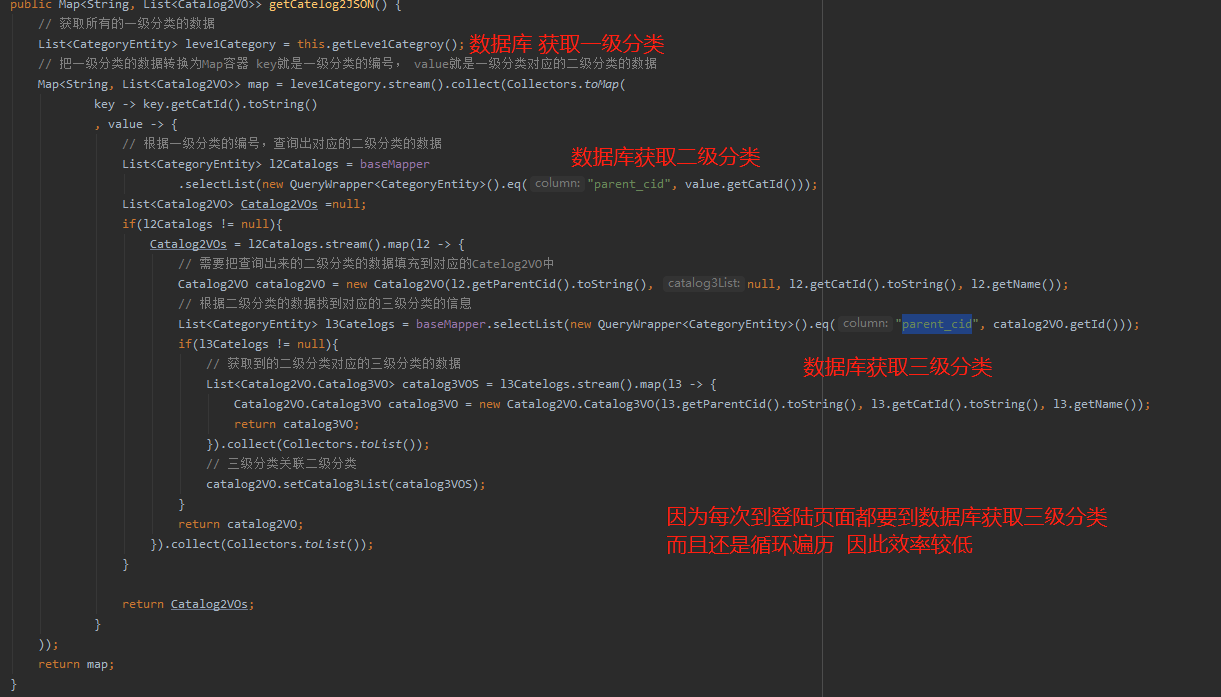
@Override
public Map<String, List<Catalog2VO>> getCatelog2JSON() {
//获取所有数据
List<CategoryEntity> list=baseMapper.selectList(new QueryWrapper<CategoryEntity>());
// 获取所有的一级分类的数据
List<CategoryEntity> leve1Category = this.queryByParentCid(list, 0L);
// 把一级分类的数据转换为Map容器 key就是一级分类的编号, value就是一级分类对应的二级分类的数据
Map<String, List<Catalog2VO>> map = leve1Category.stream().collect(Collectors.toMap(
key -> key.getCatId().toString()
, value -> {
// 根据一级分类的编号,查询出对应的二级分类的数据
List<CategoryEntity> l2Catalogs = this.queryByParentCid(list, value.getCatId());//以一级分类的cat_id 为二级分类的parentid
List<Catalog2VO> Catalog2VOs =null;
if(l2Catalogs != null){
Catalog2VOs = l2Catalogs.stream().map(l2 -> {
// 需要把查询出来的二级分类的数据填充到对应的Catelog2VO中
Catalog2VO catalog2VO = new Catalog2VO(l2.getParentCid().toString(), null, l2.getCatId().toString(), l2.getName());
// 根据二级分类的数据找到对应的三级分类的信息
List<CategoryEntity> l3Catelogs = this.queryByParentCid(list, l2.getCatId());
if(l3Catelogs != null){
// 获取到的二级分类对应的三级分类的数据
List<Catalog2VO.Catalog3VO> catalog3VOS = l3Catelogs.stream().map(l3 -> {
Catalog2VO.Catalog3VO catalog3VO = new Catalog2VO.Catalog3VO(l3.getParentCid().toString(), l3.getCatId().toString(), l3.getName());
return catalog3VO;
}).collect(Collectors.toList());
// 三级分类关联二级分类
catalog2VO.setCatalog3List(catalog3VOS);
}
return catalog2VO;
}).collect(Collectors.toList());
}
return Catalog2VOs;
}
));
return map;
}
就是将菜单中的信息和 传入的parentid 做比较 但是传入的parentid 是你获取目录的cateid
第一次是获取parentid 为0 的一级目录 根据一级目录获取 一级目录的cateid 来当二级目录的查询条件
找出二级目录后 查询出二级目录的 cateid 来当三级目录的查询条件
之前的查询方式是每级菜单都要进行数据库 查询 有多少层级 就要进行多少次数据库查询
而我们优化后只用查找数据库一次 后面的数据时根据前面的数据过滤而得到 减少了数据库的查询此时 因此效率得到显著提升


 浙公网安备 33010602011771号
浙公网安备 33010602011771号