后缀数组简要总结
众所周知,后缀数组是解决字符串类问题的强力工具,一切与字符串公共子串相关联的都可能与它有关。
方便起见,我们令
a为需要处理的子串(长度为len)(从a[1]开始到a[len])
rank[i]数组表示以i位置开始的后缀子串在所有后缀子串的字典序排名(以i位置开始的后缀子串即a[i]~a[len])
sa[i]数组表示排名为i的后缀子串的开始位置
根据定义很显然有 sa[rank[i]]=i,rank[sa[i]]=i
要先牢牢把握好这些数组的含义。

(来自网络的一张图)
后缀数组指的就是sa[i]数组啦,我们现在要想办法如何求sa[i]数组。
思考了下感觉直接求sa[i]数组非常复杂,因为排名什么的是要建立在求出所有后缀子串的前提下才求得出来。
注意到sa[rank[i]]=i,我们可以先求rank[i]数组,然后就可以知道sa[i]数组了。
很显然有一个O(len2log len)的算法,就是直接把len个长度为O(len)的字符串排序,但要是我们采用这个算法的话就没有下文了。
计算机芯片有一个特性,通用的芯片处理能力不高,但它可以处理很多信息,而专用的芯片处理能力就很强,但它只能处理单一方面的信息。
而上述算法正因为是通用,所以效率才不高。我们要提高效率,就要去研究所处理的数据的性质,根据性质我们才能够得到更高效的算法,而这算法因为运用了这个数据的性质所以通用性减少了,只适用于拥有这一性质的数据。
这里,我们就要灵活运用所有字符串都是a的后缀这一性质(比如所有后缀子串右端点固定),去得到更高效的算法。
这里是一个由Manber和Myers发明的算法,基本思想是倍增。
我们考虑两个后缀子串i,j(i,j为该后缀子串的首字母位置,且i<j)
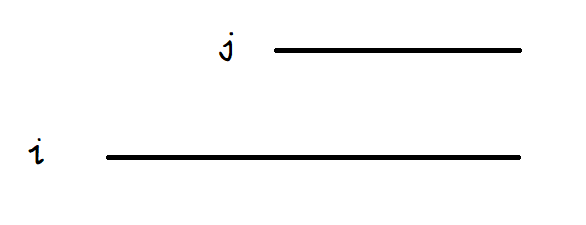
我们现在要比较它们的字典序大小,很显然i子串中,与首字母距离大于j子串长度的字符对大小比较没有任何贡献(除了前面全部相等的情况),我们可以把它们忽略。
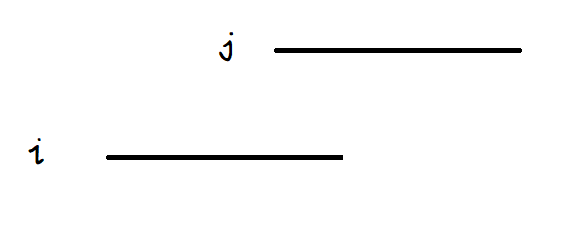
现在我们要比较的i,j子串的长度相等了,如何去比较呢?
逐位比较的话与上面那个算法没什么区别,我们将长度折半,将i,j分为前后的1,2部分,我们可以先比较i,j的1部分的大小,1部分大小相同再比较2部分的大小,而比较1部分的大小就又回到了原来比较两个字符串的大小的子问题了。
由此我们首先计算每个位置开始长度为1的子串的排名,再利用这个结果去计算长度为2的子串的排名,接下来计算长度为4的子串的排名,不断倍增,直到长度大于等于len,就得到了rank数组了。
当我们计算2k长度的子串排名时,2k-1长度的排名我们已经算出来了。
那么我们只要比较以i位置开始的2k-1长度的子串的排名与以j位置开始的2k-1长度的子串的排名(a[i......i+2k-1]与a[j......j+2k-1]),如果相等则再比较以i+2k-1位置开始的2k-1长度的子串的排名与以j+2k-1位置开始的2k-1长度的子串的排名(a[i+2k-1......i+2k-1+2k-1]与a[j+2k-1......j+2k-1+2k-1]),综合起来我们就能得到以i位置开始的2k的长度的子串与以j位置开始的2k的长度的子串的相对关系。
我们注意到这里i,j子串的大小比较其实就是比较一个由两部分排名所构成的两位数大小的关系,前半部分充当十位数,后半部分充当个位数
那么我们可以根据之前算好的每一位开始,长度为2k-1的子串的排名,去算出每一位开始在2k长度下的所谓的这个两位数,再把这些数进行离散,就能得到每一位开始长度为2k的子串的排名了。
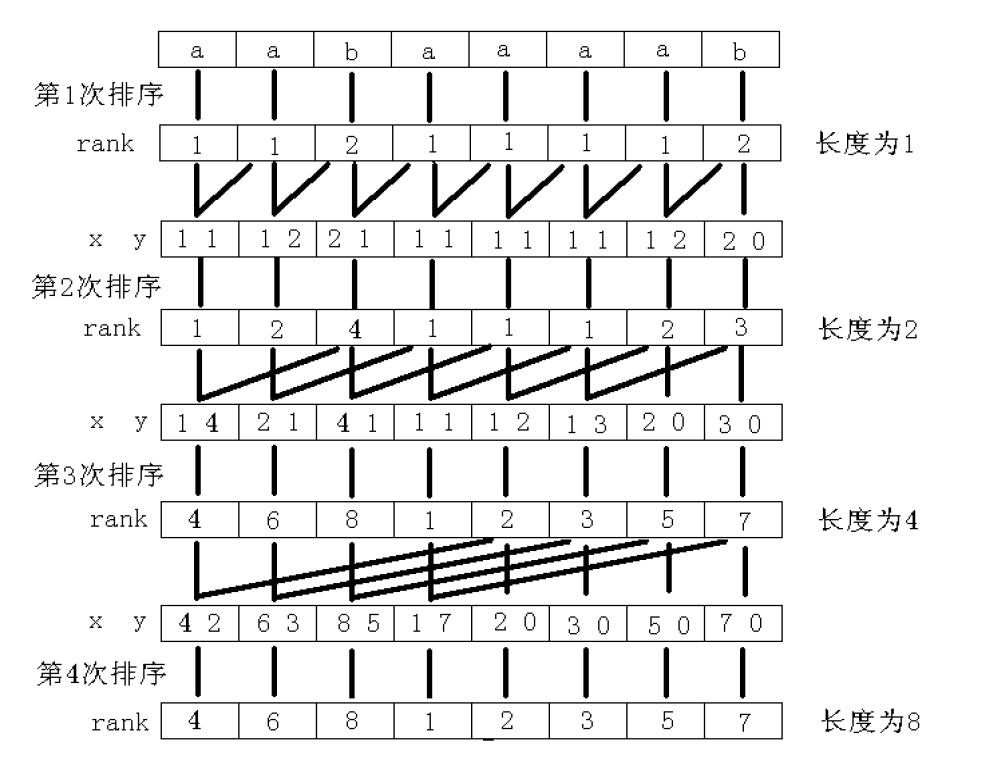
(来自网络的一张图)
接下来就是如何高效地去离散。
如果我们采用快排的话总复杂度就是O((len+len*log len)log len)也就是O(len*log2len),我们还可以再优化成O(len*log len)
我们注意到我们要离散的数只是两位数,那么我们可以采用基数排序的方法

(一张来自网络上基数排序的动态图)
它的时间复杂度是O(n+d),d是数的位数,n是数的个数。在这里复杂度就是O(len+2),而算法的总复杂度就是O((len+len+2)*log len),也就是O(len*log len)
因为每一个后缀的长度都不是一样的,最终的排名不可能有相同的,那么当离散后最大的数等于a的长度len的话就可以停止了。
这里离散的原理是这样的,但具体的代码实现由于过于简洁而可能会有点让人感到费解,必要时建议用纸笔画笔画。
到这里其实sa[i]数组的求解方法讲完的了(然后有道模板题)
但实际上后缀数组还有另外两个重要的数组,它们才是让后缀数组成为重复字符串处理强有力的原因。
heigh[i]数组表示排名为i的后缀子串与排名为i-1的后缀子串的最长公共前缀长度
h[i]数组表示从i位置开始的后缀子串与排名比它前一名的后缀子串的最长公众前缀长度,即h[i]=heigh[rank[i]]
排名不相邻的两个后缀子串的最长公共前缀子串的长度是两个排名之间heigh的最小值。(看图很显然的吧)

(还是来自网上的一张图)
那我们该如何求解heigh[i]数组呢?
如果我们暴力在sa数组求解的话复杂度就变成O(len2)了(我要你有何用)
注意到h[i]数组有个非常神奇的性质,运用这一性质我们可以把求heigh[i]数组的复杂度降到O(n)
h[i]>=h[i-1]-1
我们假设k=sa[rank[i]-1],即k是 排名比 从i位置开始的后缀子串的排名 前一位的 后缀子串的 开始位置
它们的最长公共前缀长度是h[i],即从i位置开始的后缀子串(a[i.....])与从k位置开始的后缀子串(a[k.....])的前h[i]个字符是相等的
那么,从i+1位置开始的后缀子串(a[i+1.....])与从k+1位置开始的后缀子串(a[k+1.....])分别是两者去掉首个字符的结果,所以它们头部的h[i]-1个字符是相等的
虽然在后缀数组中,排名比 从i+1位置开始的后缀子串(a[i+1.....]) 前一位的未必就是 从k+1位置开始的后缀子串(a[k+1.....])(即sa[rank[i+1]-1]的值不一定是k+1),但即便如此,公共前缀的长度也是会只增不减,所以这也是为什么是h[i+1]>=h[i]-1的原因。
因此,当计算i+1的h[i+1]时,只要从h[i]-1的长度开始检查,计算最长公共前缀的长度就好了。由于h最多只会增加len次,所以总的复杂度就是O(len)了。
得到h[i]数组后,heigh[i]数组也就能根据h[i]=heigh[rank[i]]算出来了。
这里的计算虽然简单,但非常巧妙,使用了类似尺取法的技巧。
当我们拥有heigh[i]数组后,我们就可以非常方便地求解很多问题了。
结合RMQ里的ST算法后,我们可以O(1)的时间得到任意两个后缀的最长公共前缀了。


1 #include <algorithm>
2 #include <cstring>
3 #include <cstdlib>
4 #include <cstdio>
5 #include <iostream>
6 #include <cmath>
7 #include <ctime>
8 #include <queue>
9 #define MIN(a,b) (((a)<(b)?(a):(b)))
10 #define MAX(a,b) (((a)>(b)?(a):(b)))
11 #define ABS(a) (((a)>0?(a):-(a)))
12 #define debug(a) printf("a=%d\n",a);
13 #define fo(i,a,b) for (int i=(a);i<=(b);++i)
14 #define fod(i,a,b) for (int i=(a);i>=(b);--i)
15 #define rep(i,a,b) for (int i=(a);i<(b);++i)
16 #define red(i,a,b) for (int i=(a);i>(b);--i)
17 #define N 200200
18 typedef long long LL;
19 using namespace std;
20 int heigh[N],sa[N],rank[N],tp[N],cnt[N],len; //tp[i]是基数排序的辅助数组,意义与sa[i]一样,cnt[i]即桶
21 char a[N];
22 void readint(int &x){
23 x=0;
24 char c;
25 int w=1;
26 for (c=getchar();c<'0'||c>'9';c=getchar())
27 if (c=='-') w=-1;
28 for (;c>='0'&&c<='9';c=getchar())
29 x=(x<<3)+(x<<1)+c-'0';
30 x*=w;
31 }
32 void readlong(long long &x){
33 x=0;
34 char c;
35 long long w=1;
36 for (c=getchar();c<'0'||c>'9';c=getchar())
37 if (c=='-') w=-1;
38 for (;c>='0'&&c<='9';c=getchar())
39 x=(x<<3)+(x<<1)+c-'0';
40 x*=w;
41 }
42 void init(){
43 scanf("%s",a+1);
44 len=strlen(a+1);
45 }
46 void rsort(){ //rank[i]数组相当于十位数(前部分),tp[i]数组相当于个位数(后部分),注意tp[i]与rank[i]意义不一样!
47 fo(i,1,m) cnt[i]=0;
48 fo(i,1,len) ++cnt[rank[tp[i]]];
49 fo(i,2,m) cnt[i]+=cnt[i-1]; //前缀和
50 fod(i,len,1) sa[cnt[rank[tp[i]]]--]=tp[i]; //个位(后部分子串排名)排后的十位(前部分子串排名)的排名
51 }
52 bool check(int *f,int x,int y,int w){
53 return (f[x]==f[y]&&f[x+w]==f[y+w]);
54 }
55 void get_sa(int m){
56 fo(i,1,len) {rank[i]=a[i]; tp[i]=i;} //初始化
57 rsort();
58 for (int w=1,p=0;p<len;w<<=1,m=p){ //w为当前子串长度,p为离散后的最大数
59 p=0;
60 fo(i,len-w+1,len) tp[++p]=i; //此部分子串没有后部分
61 fo(i,1,len) if (sa[i]>w) tp[++p]=sa[i]-w; //根据sa[i]数组得到后部分(个位)排名靠前的,并把其前部分的开头位置储存在tp[i]数组上
62 rsort();
63 swap(rank,tp); //交换两数组,因为离散需用到原rank数组,此处为节省空间而交换
64 rank[sa[1]]=p=1;
65 fo(i,2,len) rank[sa[i]]=check(tp,sa[i],sa[i-1],w)?p:++p; //若两子串前后两部分的排名分别一样,则视为同一子串,排名一样
66 }
67 for (int i=1,k=0,j=0;i<=len;heigh[rank[i++]]=k) //heigh[rank[i]]=h[i]
68 for(k=k?k-1:k,j=sa[rank[i]-1];a[i+k]==a[j+k];++k); //逐位比较
69 }
70 int main(){
71 freopen("testdata.in", "r", stdin);
72 freopen("test.out", "w", stdout);
73 init();
74 get_sa(128);
75 return 0;
76 }
注意tp[i]数组与rank[i]数组意义不一样!!rank[i]表示从位置i开始的后缀子串的排名,tp[i]表示排名第i的后缀子串的起始位置!!!
以下是一些应用的求法。
1.求字符串中可重叠的最长公共子串
根据height定义很显然这个就是height中的最大值了。
2.求字符串中不可重叠的最长公共子串
这个我们需要二分答案再验证,我们要二分可能的公共子串长度k,然后按sa的顺序对height进行分组,使组内的height值都不小于k,然后对于某个组内我们只要考察该组内sa的最大值和最小值的差是否大于等于k(实际上就是这两个后缀的开头是否相差k,从而避免重叠),有则k成立。
3.求字符串中可重叠K次的最长公共子串
这个我们跟2差不多,二分公共长度k,进行分组,然后我们考察每个组内的后缀个数是否大于等于K,有则K成立。
4.求字符串中不相同的子串个数
每个子串必定是某个后缀的前缀,那问题就是求所有后缀中不相同的前缀的个数,我们从顺序sa[1],sa[2],sa[3],不难发现每加入一个从位置i开始的后缀子串,它有n-sa[i]+1个前缀(就是这个后缀的长度),其中有height[i]是和前面的字符串相同(最长公共前缀嘛),所以这个字符串会贡献出n-sa[i]+1-height[i]不同的子串,累加后就可以了。
5.求字符串中最长的回文子串
所谓回文就是一个字符串满足中心对称,某个字符为对称中心,从这个字符向左和向右对应位置的字母都相等,如12345678987654321,我们设这个中心对称的字符为a[i],则我们就要判断 a[i-k]与a[i+k]是否相等,我们可以把整个字符串倒过来写在这个字符串后面(我们就得到了逆过来的那个12345678的字符串),其中加个特殊符号,这样我们可以简化判断,只用判断这新的字符串的某两个字符串的最长公共前缀(关于回文的查找还有Manacher算法等更为高效简单的算法)
6.求字符串中连续的重复子串
已知一个字符串L是由某个字符串S重复R次得到的,求重复次数R的最大值。
我们假设S的长度为k,首先L%k=0,然后判断从1位置开始的后缀子串和从k+1位置开始的后缀子串的最长公共前缀子串是否为n-k。因此在查找最长公共子串的时候就是求height[rank[k+1]]到height[rank[1]]之间的最小值。我们的做法就是求height数组中每一个数到height[rank[1]]之间的数的最小值k,R=L的长度/K
7.求字符串中重复次数最多的连续重复子串
8.求两个字符串的最长公共子串
将这两个字符串连接起来,其中用一个特殊符号分开,然后再求出不在同一个字符串中的最大的height值即可。
9.求两个字符串长度不小于K的最长公共子串
将两个字符串A、B连接起来,其中用一个特殊符号分开,然后用k对height数组分组,再统计每组的最长公共前缀和。每遇到一个B子串,就统计与前面A子串产生多少个长度不小于K的公共子串,这里A需要用栈来维护。然后对A也一样的处理。
10.求n个字符串的最长公共子串
这个用KMP可以处理,也可以将这n个字符串连成一个字符串,然后用不同的特殊符号分开,二分长度k对height数组进行分组判定是否该组中所有字符串的子串都出现在里面即可。
1 #include <algorithm>
2 #include <cstring>
3 #include <cstdlib>
4 #include <cstdio>
5 #include <iostream>
6 #include <cmath>
7 #include <ctime>
8 #include <queue>
9 #define MIN(a,b) (((a)<(b)?(a):(b)))
10 #define MAX(a,b) (((a)>(b)?(a):(b)))
11 #define ABS(a) (((a)>0?(a):-(a)))
12 #define debug(a) printf("a=%d\n",a);
13 #define fo(i,a,b) for (int i=(a);i<=(b);++i)
14 #define fod(i,a,b) for (int i=(a);i>=(b);--i)
15 #define rep(i,a,b) for (int i=(a);i<(b);++i)
16 #define red(i,a,b) for (int i=(a);i>(b);--i)
17 #define N 200200
18 typedef long long LL;
19 using namespace std;
20 int heigh[N],sa[N],rank[N],tp[N],cnt[N],la,lb,ans,m;
21 char a[N];
22 void readint(int &x){
23 x=0;
24 char c;
25 int w=1;
26 for (c=getchar();c<'0'||c>'9';c=getchar())
27 if (c=='-') w=-1;
28 for (;c>='0'&&c<='9';c=getchar())
29 x=(x<<3)+(x<<1)+c-'0';
30 x*=w;
31 }
32 void readlong(long long &x){
33 x=0;
34 char c;
35 long long w=1;
36 for (c=getchar();c<'0'||c>'9';c=getchar())
37 if (c=='-') w=-1;
38 for (;c>='0'&&c<='9';c=getchar())
39 x=(x<<3)+(x<<1)+c-'0';
40 x*=w;
41 }
42 void init(){
43 scanf("%s",a+1);
44 la=strlen(a+1);
45 scanf("%s",a+1+la);
46 lb=strlen(a+1);
47 }
48 void rsort(){
49 fo(i,1,m) cnt[i]=0;
50 fo(i,1,lb) ++cnt[rank[tp[i]]];
51 fo(i,2,m) cnt[i]+=cnt[i-1];
52 fod(i,lb,1) sa[cnt[rank[tp[i]]]--]=tp[i];
53 }
54 bool check(int *f,int x,int y,int w){
55 return (f[x]==f[y]&&f[x+w]==f[y+w]);
56 }
57 void get_sa(){
58 m=128;
59 fo(i,1,lb) {rank[i]=a[i]; tp[i]=i;}
60 rsort();
61 for (int w=1,p=0;p<lb;w<<=1,m=p){
62 p=0;
63 fo(i,lb-w+1,lb) tp[++p]=i;
64 fo(i,1,lb) if (sa[i]>w) tp[++p]=sa[i]-w;
65 rsort();
66 swap(rank,tp);
67 rank[sa[1]]=p=1;
68 fo(i,2,lb) rank[sa[i]]=check(tp,sa[i],sa[i-1],w)?p:++p;
69 }
70 for (int i=1,k=0,j=0;i<=lb;heigh[rank[i++]]=k)
71 for(k=k?k-1:k,j=sa[rank[i]-1];a[i+k]==a[j+k];++k);
72 }
73 void solve(){
74 ans=0;
75 fo(i,2,lb) if ((sa[i]<=la&&sa[i-1]>la)||(sa[i]>la&&sa[i-1]<=la)) ans=MAX(ans,heigh[i]);
76 }
77 int main(){
78 init();
79 get_sa();
80 solve();
81 printf("%d\n",ans);
82 return 0;
83 }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号