
关于对话一致性三篇论文
1. A persona-Base Neural Conversation Model
基础知识
- 词袋模型(Bag of Words, BOW)与词向量(Word Embedding)模型
词袋模型就是将句子分词,然后对每个词进行编码,常见的有one-hot、TF-IDF、Huffman编码,假设词与词之间没有先后关系。 - 词向量模型是用词向量在空间坐标中定位,然后计算cos距离可以判断词于词之间的相似性。
- BERT
两个模型:
Spearker Model 个人信息
Speaker-Addressee Model 对不同的说话者有不同的反应
符号
- M = { m 1 , m 2 , . . . , m I } ⟶ M=\{m_1,m_2,...,m_I\}\longrightarrow M={m1,m2,...,mI}⟶ 输入序列
- R = { r 1 , r 2 , . . , r j , E O S } ⟶ R=\{r_1,r_2,..,r_j,EOS\}\longrightarrow R={r1,r2,..,rj,EOS}⟶ 回复序列
- K embedding 维度数
- V 词典个数
Speaker Model
- 将用户按照其中一些特征(例如年龄、居住国)单独基于响应进行分组。
- 将一个聊天者看作已经将个人信息编码了的向量或者词嵌入向量(embedding)
- 每一个说话者 i ∈ [ 1 , N ] i\in [1, N] i∈[1,N] 都对应 v i ∈ R K × 1 v_i\in R^{K\times1} vi∈RK×1
- 将信息 S S S使用编码器LSTM编码成 h S h_S hS
- 在解码器LSTM的每一步,结合前一时刻的的解码器,当前时刻的词表示(word representations),和说话者的词嵌入(embedding) v i v_i vi
- Speaker embedding { v i } \{v_i\} {vi}在整个上下文的对话存在
- 在训练过程中,通过将单词预测误差反向传播到每个神经组件来学习 { v i } \{v_i\} {vi}
- 两个speaker embedding 如果相近,那么个人信息也是相近的
如果一个人在对话过程中总是提到英国,也就是英国这个词在对话中出现多次,那么当问到他来自哪里时会回答英国
原本的LSTM:

加入信息后的LSTM


Speaker-Addressee Model
对不同的说话者有不同的反应
- 同上一个模型一样,将每个说话者对应到不同的K维向量 对于i说话者为 v i v_i vi,对于j说话者为 v j v_j vj
- 由此得到一个交互表示说话者i对说话者j的交互方式
V
i
,
j
∈
R
K
×
1
V_{i,j} \in R^{K\times}1
Vi,j∈RK×1,即LSTM每一步的target
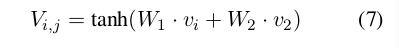
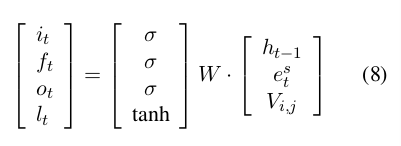
- 需要的数据集可能很大,我们可以根据相似的个人信息embedding
解码和重排
- beam size B=200
- 输出最大长度20
- 检查所有 B × B B\times B B×B 种可能的下一个词
- 将所有假设末尾都加上EOS 并添加到N-best 句子数组
- 保存前B个尚未完成的假设,移动到下一个词
- 为了避免无意义回复,使用一个scoring 函数重新排序N-best数组。这个函数包含一个长度乘法和根据target得到的source的最大似然估计
[外链图片转存失败(img-j4ZCTPdA-1569489082552)(6.png)]
- p ( R ∣ M , v ) − − > p(R|M,v) --> p(R∣M,v)−−> 根据输入序列M和回答者的speakerID
- ∣ R ∣ − − > |R| --> ∣R∣−−> target 句子长度
- γ − − > \gamma--> γ−−> 惩罚因子
- 使用MERT从N-best句子数组优化 γ , λ \gamma,\lambda γ,λ
- 为了计算 p ( R ∣ M , v ) p(R|M,v) p(R∣M,v),我们通过交换输入和响应训练一个反向seq2seq ,并且不考虑说话者个人信息
数据集
训练细节
- 只针对speaker model
- 4层LSTM 每层100个隐藏层单元
- Batch 批处理的规格为128句
- 学习率1
- 梯度阈值5
- 词典词的数目限制在50000以内
- dropout 比率为0.2
跑了14代 ,1个月 GPU
实验
评价标准
BLEU perplexity
3. Personalizing Dialogue Agents: I have a dog, do you have pets too?
在第一篇论文基础上,了解说话者另一方的信息,促进个人聊天对话
摘要
- 根据个人信息来训练模型
- 根据对方信息来训练模型
- 由于在对话时往往不知道对方的具体信息,可以通过先和对方谈论私人话题,预测对方信息
数据集
- 个人信息
- 修改过的个人信息,为了避免利用琐碎的单词重叠进行建模,我们众包相同的1155个角色的重写集,以及相关的句子,如短语、概括或专门化,
- 对话

- train_both_original.txt 包含说话者和对话者的个人信息和聊天记录
- train_both_revised.txt 聊天记录同上,但是说话者和对话者的个人信息有改变
- train_none_original.txt 聊天记录同上,没有个人信息
- train_other_original.txt 聊天记录同上,只有对话者的原始个人信息
- train_other_revised.txt 聊天记录同上,只有对话者的修改后的个人信息
- train_self_original.txt 聊天记录同上,只有自己的原始个人信息
- train_self_revised.txt 聊天记录同上,只有自己的修改后的个人信息
- 修改的个人信息和未修改的个人信息表达意思一样但是表达方式不同如i like getting friends.修改为i love to meet new people.
模型
Ranking Profile Memory Network
- 使用Starspace model 唯一区别是以下
- 输入:对话历史
- 中间:memory network 从简历里找到和输入相关的句子
- 输出:下一句话
- 计算输入
q
q
q 和简历句子
p
i
p_i
pi 的相似度,计算softmax 并且加和
[外链图片转存失败(img-FPf3MMjl-1569489082553)(8.png)] - 通过计算候选句子C 与 q + q^+ q+ 的相似度来得到最佳的句子进行输出
key-value Profile Memory Network
- key 对话历史
- value 对话的下一句话
- q + q^+ q+ 关注key 并且像上图一样输出一个权值总和 q + + q^{++} q++
- 通过计算候选句子C 与 q + + q^{++} q++ 的相似度来得到最佳的句子进行
seq2seq
- 在encoder中输入的句子后面加上个人信息,一起送入LSTM编码
Generative Profile Memory Network
-
对话历史通过LSTM编码器编码
-
最后一个状态state C 用来做decoder 的初始隐藏状态
-
profile中的每一个句子 i i i中的n个词embedding p i = { p i , 1 , p i , 2 , . . . , p i , n } ∈ P p_i=\{p_{i,1},p_{i,2},...,p_{i,n}\}\in P pi={pi,1,pi,2,...,pi,n}∈P进行加权求和 f ( p i ) = ∑ j ∣ p i ∣ α i p i , j f(p_i)={\sum_{j}^{|p_i|}{\alpha_i p_{i,j}}} f(pi)=∑j∣pi∣αipi,j,权值通过inverse-term-frequency进行计算,
α i = 1 1 + l o g ( 1 + t f ) \alpha_i=\dfrac{1}{1+log(1+tf)} αi=1+log(1+tf)1
最终得到profile中每一个句子的表征,存储在memory中,计作F: -
F 是编码的memories的集合,mask a t a_t at 上下文 c c c,下一个输入 x ^ t \hat{x}_t x^t
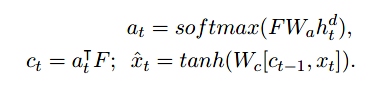
Assigning Personality/Identity to a Chatting Machine for Coherent Conversation Generation
参考https://blog.csdn.net/aliceyangxi1987/article/details/75276376
1. 模型

- 输入一句话,一个profile detector 探测器就会预测是否需要用到profile,并且决定使用profile的哪个value。否则使用普通的seq2seq
- 通过选定的这个值value 和Bidirectional Decoder双向解码来生成回复
- 为了更好地训练这个双向解码器,通过预测一个单词的位置,这个位置是解码时需要从选定的profile value 开始的,位置探测器(position detector )探测出在训练集和测试集之间不符合的问题
2. 编码
将输入句子(已经embedding)的通过GRU编码为隐藏层状态h1.
3. Profile Detector
其中 P(z|x) 是根据提问 x,看需要用档案来回答的概率,由 Profile Detector 计算出。
由训练的二分类器得到
P
(
z
∣
x
)
=
P
(
z
∣
h
~
)
=
σ
(
W
p
h
~
)
,
h
~
P (z|x) = P (z| \tilde{h}) = σ(W_p\tilde{h}),\tilde{h}
P(z∣x)=P(z∣h~)=σ(Wph~),h~ 是所有
h
j
h_j
hj隐藏层状态的和,
W
p
W_p
Wp 是分类器的参数。
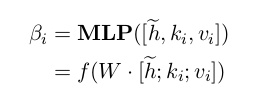
β i β_i βi,用来决定根据哪个关键字答复,其中 f 为 softmax 激活函数,选择概率最大的那一组 key-value
4. Bidirectional Decoder
P f ( y ∣ x ) P_f(y|x) Pf(y∣x) 是根据 x 生成 y,由通常的 forward decoder 生成。
P b ( y ∣ x , < k i , v i > ) P_b(y|x, {< ki, vi >}) Pb(y∣x,<ki,vi>)是根据 x 和档案生成 y,由 Bidirectional Decoder 生成:
即 y = ( y b , v ~ , y f ) y=(y_b, \tilde{v}, y_f ) y=(yb,v~,yf) 为生成的回复, v ~ \tilde{v} v~ 是选中的 value
先由 x , v ~ x,\tilde{v} x,v~ 得到 y b y_b yb,再由 x , v , y b x,v,yb x,v,yb 得到 y f y_f yf。
P
b
P_b
Pb,
P
f
P_f
Pf 通过下式计算:
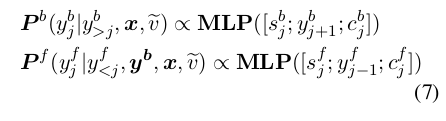
其中
s
j
s_j
sj 是 decoder 的相应状态,
c
j
c_j
cj 是语境的向量
5. position detector
因为用于训练的问答句是从社交网站上获得的,前面识别出来的 value 可能并不会出现在答复中,这样 bidirectional decoder 就会不知道从哪个位置开始,所以在这一步会做相关的处理。
例如
post x =你-1 有-2 什么-3 特长-4 ?-5
response y =我-1 非常-2 擅长-3 小提琴- 4
a profile key value pair “<特长, 钢琴>
那么 “小 提 琴-4 ” 的位置会传递给 decoder,然后替换成“钢 琴”。
用
P
(
j
∣
y
1
y
2
⋅
⋅
⋅
y
m
,
<
k
,
v
>
)
)
,
1
≤
j
≤
m
P (j|y_1y_2 · · · y_m, < k, v > )), 1 ≤ j ≤ m
P(j∣y1y2⋅⋅⋅ym,<k,v>)),1≤j≤m来表示
y
j
y_j
yj 可以被 v 替换的概率。
计算方法用两个单词的距离:
P ( j ∣ y , < k , v > ) ) ∝ c o s ( y j , v ) P(j|y,< k,v >)) ∝ cos(y_j,v) P(j∣y,<k,v>))∝cos(yj,v)
6. 损失函数
由两部分组成:
L = L 1 + α L 2 L = L1 + αL2 L=L1+αL2
- L1 是生成答复的,根据最开始的问题模型可以得到:

D ( c ) D(c) D(c) 是只有 post-response 对的, D ( p r ) D(p_r) D(pr) 是 post,value-response 的。
- L2 是 profile detector 预测是否用档案及用哪个关键词的,根据前面定义过的 P(z|x) 和 β i β_i βi:

z=0 不用,z=1 用, k ^ \hat{k} k^ 是锁定的 key。
总结
- A persona-Base Neural Conversation Model 2016
说话人的信息被编码,并在每一个时间步骤被注入到隐藏层,从而帮助预测整个生成过程中的个性化响应 - Assigning Personality/Identity to a Chatting Machine for Coherent Conversation Generation 2018
- 通过profile detector
- Bidirectional Decoder 根据value向前向后编码
- position detector 决定在哪个位置开始编码
- Personalizing Dialogue Agents: I have a dog, do you have pets too? 2018
- 提出了一个新的带有persona的对话数据集
- 将profile的信息存储在memory中
难点
- 第一篇论文与第二篇论文没有代码实现和数据,第一篇论文代码较好实现但仍需一定时间并且不确定结果是否会好
- 第三篇论文有代码实现和数据,但是查看源代码需要一定时间
- 上述论文都是基于英文,需要考虑对中文数据收集以及处理
- 生成式方法在对话一致性效果方面,大部分是生成式与检索式混用,如果采用检索式如何提高其检索速度

 浙公网安备 33010602011771号
浙公网安备 33010602011771号