
爬虫学习基础
一、认识爬虫
爬虫概述:
通过编写程序爬取互联网的优秀资源(图片、音频、视频……),将我们希望能够保存互联网上的一些重要的数据为己所用。
推荐使用Python进行爬虫
软件推荐:
pycharm、anaconda、jupyter、Visual Studio Code、python(3.7及及以上版本)
爬虫是否合法?
取决于使用的人
善意爬虫:
不破坏爬取的网站的资源(正常访问,一般频率不高,不窃取用户隐私)
恶意爬虫:
影响网站的正常运营(抢票,秒杀,疯狂solo网站资源造成网站宕机)
爬虫的矛与盾:
反爬机制:
门户网站,可以通过指定相应的策略或者技术手段,防止爬虫程序进行网站数据的爬取。
反反爬策略:
爬虫程序可以通过相关的策略或者技术手段,破解门户网站中具备的反爬机制,从而获取门户网站中相关的数据,但需注意恶意爬虫。
robots.txt协议:
君子协议,规定网站中那些数据可以被爬取那些数据不可被爬取。
二、第一个爬虫开发案例
from urllib.request import urlopen url = "http://www.baidu.com" resp = urlopen(url) #print(resp.read().decode("utf-8")) #获取网页源代码 with open("mybaidu.html", mode="w", encoding="utf-8") as f: f.write(resp.read().decode("utf-8")) #打开网页
三、web请求解析
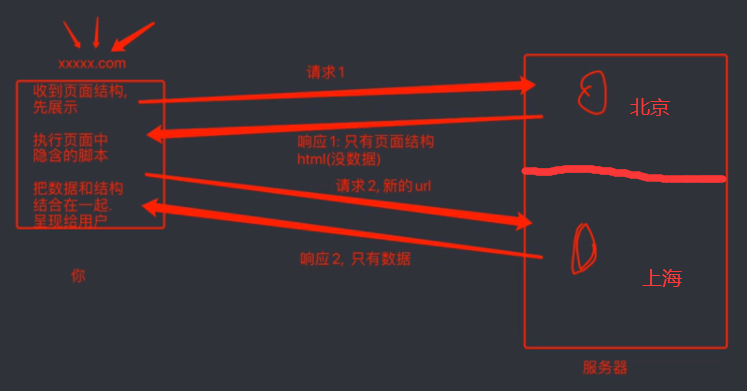
图片解析:
直接访问、返回:
页面和数据一起加载出来

分布式:
页面和数据分开加载
四、浏览器工具的使用
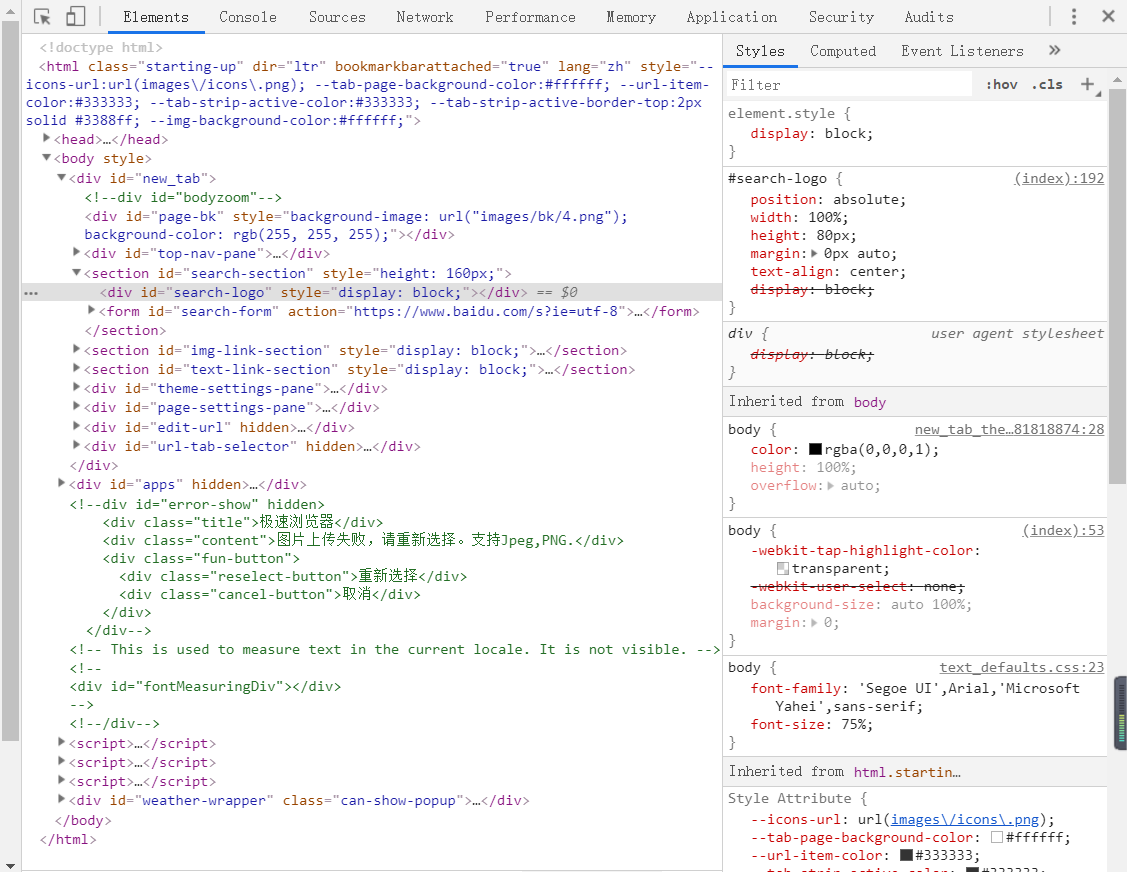
Elements:
参考以及动态的处理一些页面上不需要的东西(如:删除一些不想要的广告)
Console:
控制台,可以做一些js的调试,进行展示
前端经常使用
Sources:
整个页面所涉及到、使用到的资源,包括页面源代码
Network:
抓包工具(可使用Fn+F12打开)
可以看到整个网页加载过程中所有的网络请求
五、http协议
浏览器和服务器之间的数据家平湖遵守的就是HTTP协议
HTTP协议在进行数据传输时,有两种状态: 请求:
请求行-> 请求方式(get/post)请求url地址协议 请求头-> 放一些服务需要使用的附加信息 #主要做分割作用 请求体-> 一般放一些请求参数
响应:
状态行-> 协议 状态码 (200、302、404、500) 响应头-> 放一些客户端要使用的一些附加信息 (cookie、验证信息、解密的key) #主要做分割作用 响应体-> 服务器返回的正真客户端要用的内容(HTML,json等)
请求头中常见的一些重要内容(爬虫需要):
1.User-Agent:请求载体的身份标识(用啥发送的请求)
2.Referer:防盗链(这次请求是从哪个页面来的?反爬会用到)
3.cookie:本地字符串数据信息(用户登录信息,反爬的token)
响应头中一些重要的内容: 1.cookie:本地字符串数据信息(用户登录信息,反爬的token)
2.各种神奇的莫名的字符串(这个需要经验了,一般都是token字样,防止各种攻击和反爬)
请求方式: GET:显示提交
POST:隐示提交
六、正则表达式
re是 一门全新的语言,一种使用表达式的方式对字符串进行匹配的语法规则。
我们抓取到的网页源代码本质上就是一个超长的字符串,想从里面提取内容,用正则再适合不过。
优点:速度快、效率高、准确性高
缺点:新手难度高
. 匹配除换行符以外的任意字符 (注意:在未来Python的re模块中是一个坑——不能匹配换行符) \w 匹配字母或数字或下划线 \d 匹配数字 ^ 匹配字符串的开始 $ 匹配字符串的结尾 \W 匹配除了字母或数字或下划线 \D 匹配非数字 \S 匹配非空白符 a|b 匹配字符a或字符b () 匹配括号内的表达式,也表示一个组 [...] 匹配字符组中的字符 [^...] 匹配除了字符组中字符的所有字符 *\s 匹配任意的空白符* *\n 匹配一个换行符* *\t 匹配一个制表符*
量词:控制前面的元字符出现的次数
* 重复0次或更多次 + 重复1次或更多次 ? 重复0次或一次 *{n} 重复n次* *{n,} 重复N次或更多次* *{n,m} 重复n到m次*
贪婪匹配和惰性匹配:
.* 贪婪匹配 #尽可能多的匹配结果 .*? 惰性匹配 #尽可能少的匹配内容——>回溯
七、re解析
re:为了防止正则表达式被误认为转义字符,通常前面加个“r”
findall:提取内容,返回列表
import re result = re.findall("a", "我是一个abcdeafg") print(result)#['a', 'a'] result = re.findall(r"\d+", "我今年18岁,我有2000000000块") print(result) #['18', '2000000000']
finditer(重点):配内容
result = re.finditer(r"\d+", "我今年18岁") print(result) #得到的是迭代器 for item in result: print(item) #从迭代器中拿到内容 <re.Match object;span=(3, 5), match='18'> print(item.group()) #从匹配到的结果中拿到数据 18
search:拿到第一次匹配的内容
result = re.search(r"\d+","我叫周杰伦,今年32岁,我的班级是5年4班") print(result.group()) #32
match:在匹配的时候,是从字符串的开头开始进行匹配的,类似在正则前面加上了^
result = re.match(r"\d+","我叫周杰伦,今年32岁,我的班级是5年4班") print(result) #None
预加载:提前把正则对象加载完毕
obj = re.compile(r"\d+") #直接把加载好的正则进行使用 result = obj.findall("我叫周杰伦,今年32岁,我的班级是5年4班") print(result) #['32', '5', '4']
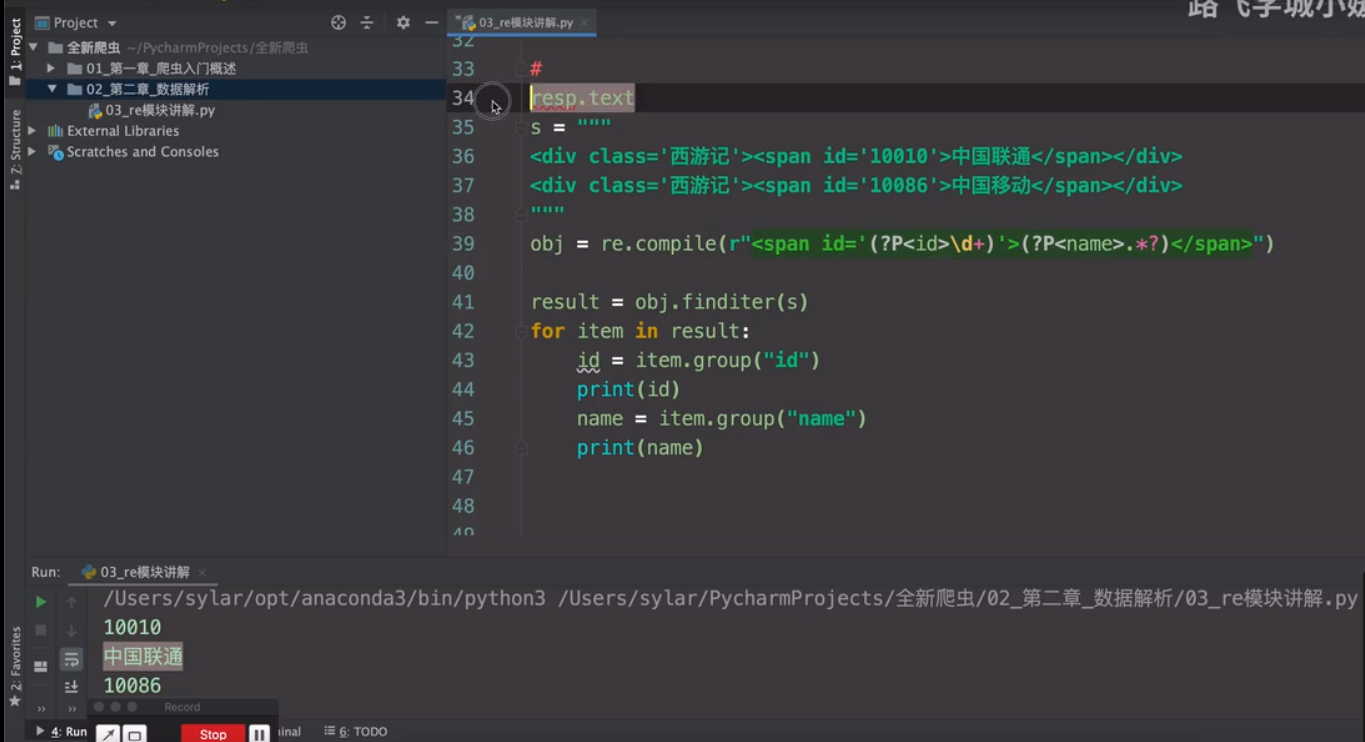
re_提取分组数据:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号