
数据采集与融合技术实践第五次作业
数据采集与融合技术实践第五次作业
姓名:刘心怡 学号:031904134 班级:2019级大数据一班
作业①
1)实验内容及结果
①实验内容
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/
关键词:学生自由选择
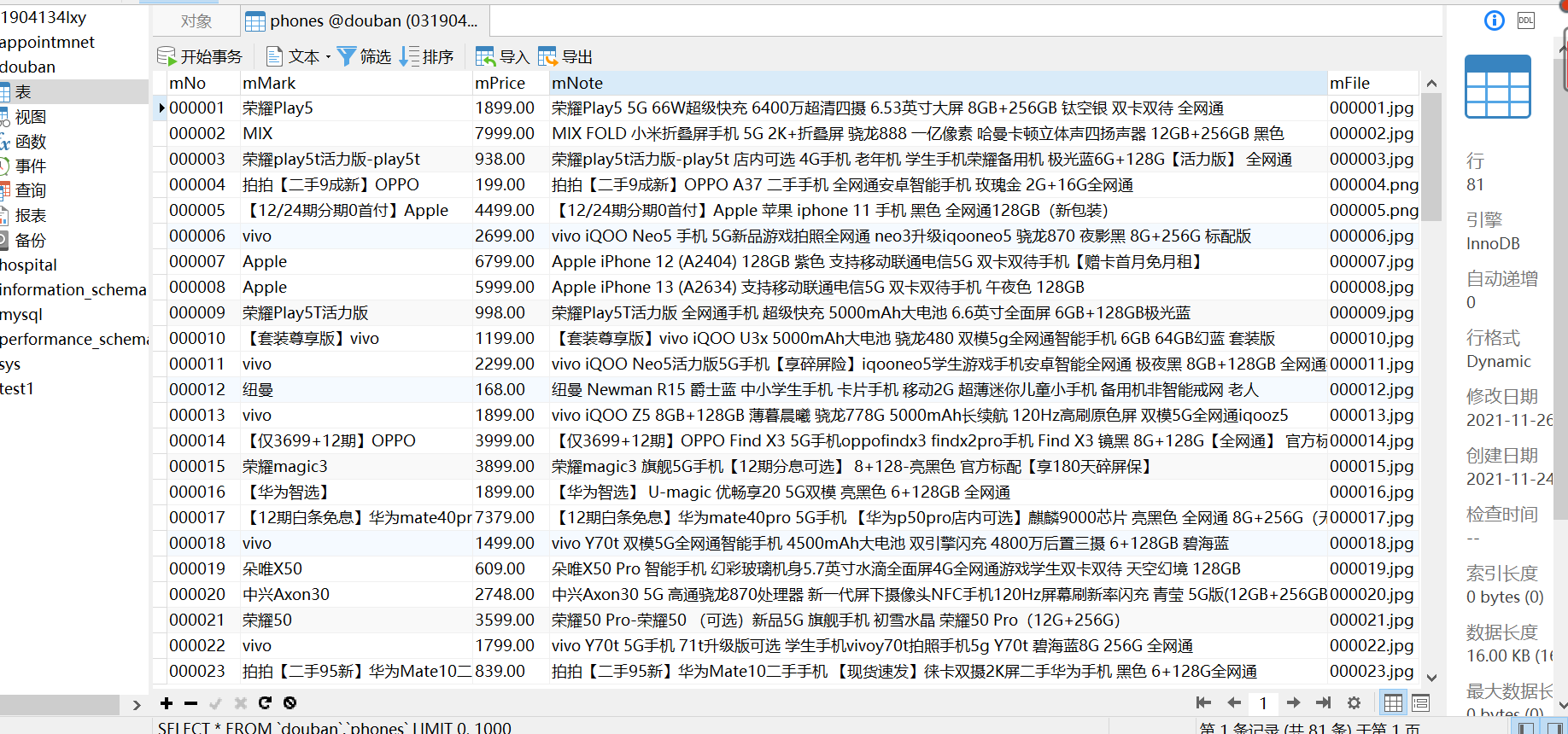
输出信息:
| mNo | mMark | mPrice | mNote | mFile |
|---|---|---|---|---|
| 000001 | 三星Galaxy | 9199.00 | 三星Galaxy Note20 Ultra 5G... | 000001.jpg |
| 000002...... |
②实验步骤
检查元素得

因此提取li代码为:
time.sleep(1)
print(self.driver.current_url)
lis =self.driver.find_elements_by_xpath("//div[@id='J_goodsList']//li[@class='gl-item']")
检查内部具体元素属性
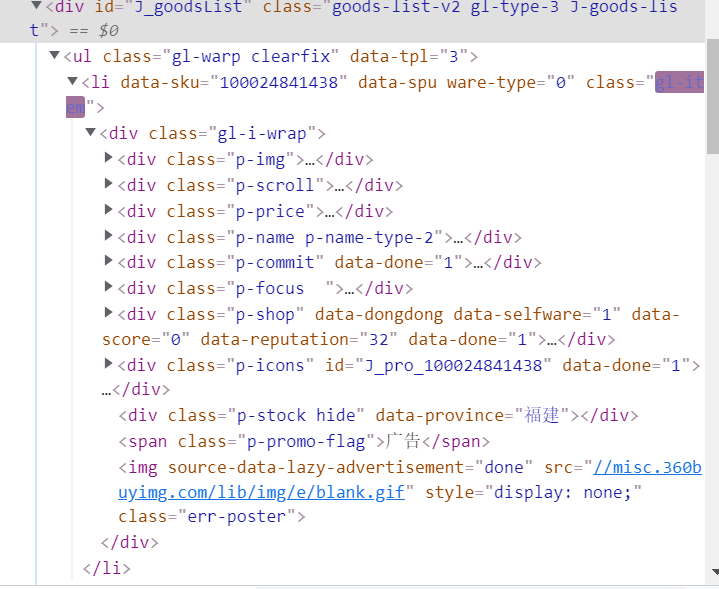
因此编写爬取代码为:
try:
src1 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("src")
except:
src1 = ""
try:
src2 = li.find_element_by_xpath(".//div[@class='p-img']//a//img").get_attribute("data-lazy-img")
except:
src2 = ""
try:
price = li.find_element_by_xpath(".//div[@class='p-price']//i").text
except:
price = "0"
try:
note = li.find_element_by_xpath(".//div[@class='p-name p-name-type-2']//em").text
mark = note.split(" ")[0]
mark = mark.replace("爱心东东\n", "")
mark = mark.replace(",", "")
note = note.replace("爱心东东\n", "")
note = note.replace(",", "")
except:
note = ""
mark = ""
因为涉及到翻页,因此查看页面“下一页”按钮属性为:

因此编写翻页部分为:
try:
self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next disabled']")
except:
nextPage = self.driver.find_element_by_xpath("//span[@class='p-num']//a[@class='pn-next']")
time.sleep(10)
nextPage.click()
self.processSpider()
编写写入数据库语句为:
sql = "insert into phones (mNo,mMark,mPrice,mNote,mFile) values (%s,%s,%s,%s,%s)"
self.cursor.execute(sql, (mNo, mMark, mPrice, mNote, mFile))
self.con.commit()
原本values后部分写为(?,?,?,?,?),后经询问老师发现这是不规范的写法,遂改为如上格式,此外,我的电脑必须写一条提交一条,否则无法写入数据库。
③代码链接
https://gitee.com/lyinkoy/crawl_project/blob/master/作业5/1.py
④运行结果:
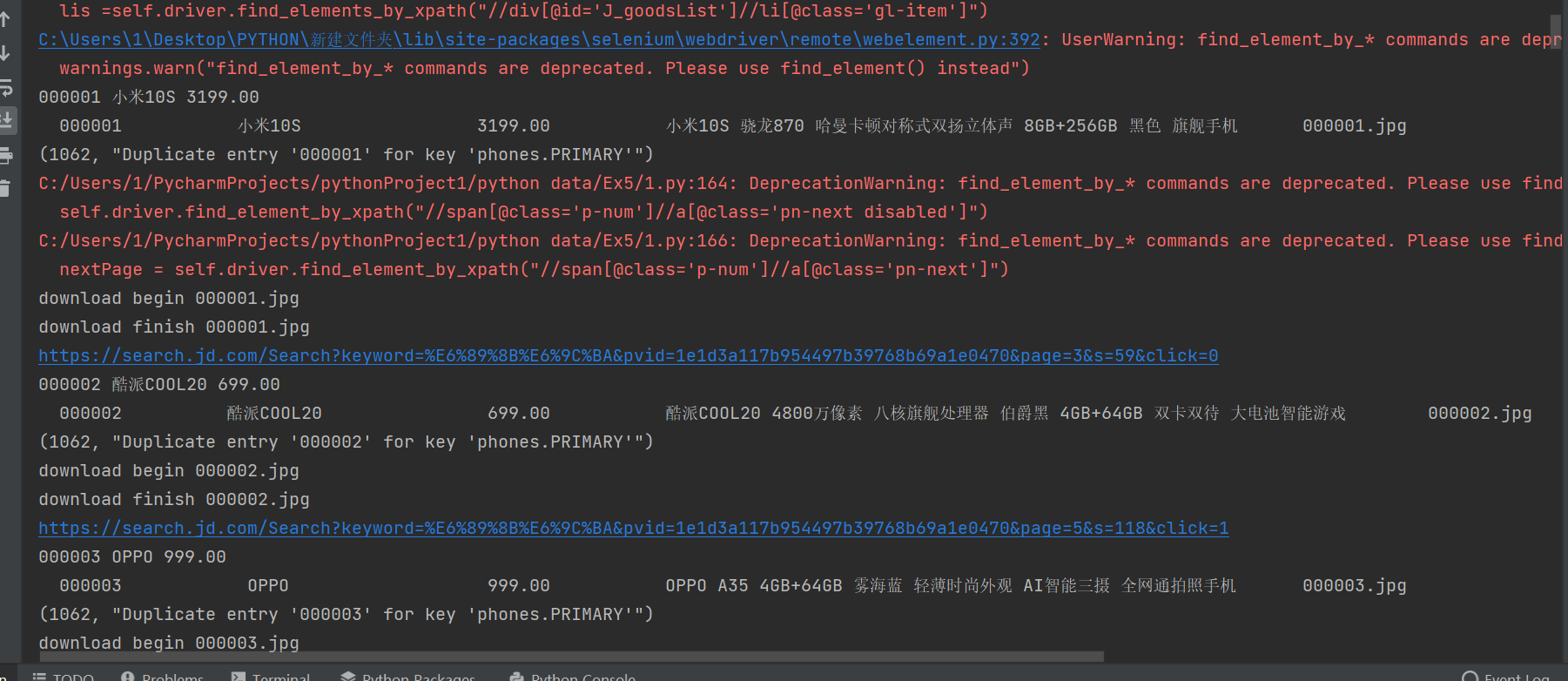

2)心得体会
在作业①中系统学习了使用Selenium 查找HTML元素,xpath爬取信息的方法以及MySQL数据库的连接与写入,我在这一实验中在网上查找了许多资料,了解了许多之前被自己忽略的细节。并且注意到了我的电脑的写入特点,此外,在写实验报告重新运行时,发现:

谷歌它失效了!说是版本有误…于是秉承着“得不到就毁掉”的心态,我卸载重装,检查版本无误后程序运行:

果然,卸载重装能解决90%的问题,受益颇多。
作业②
1)实验内容及结果
①实验内容
要求:熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
表头应是英文命名例如:课程号ID,课程名称:cCourse……,由同学们自行定义设计表头
| Id | cCourse | cCollege | cSchedule | cCourseStatus | cImgUrl |
|---|---|---|---|---|---|
| 1 | Python网络爬虫与信息提取 | 北京理工大学 | 已学3/18课时 | 2021年5月18日已结束 | http://edu-image.nosdn.127.net/C0AB6FA791150F0DFC0946B9A01C8CB2.jpg |
| 2...... |
②实验步骤
首先,要实现页面登录,就要了解页面中各页面按钮的分布,已我的课程为例

因此,可编写登录步骤代码为:
driver.find_element_by_xpath('//div[@class="unlogin"]//a[@class="f-f0 navLoginBtn"]').click() #登录或注册
sleep(2)
driver.find_element_by_class_name('ux-login-set-scan-code_ft_back').click() #其他登录方式
sleep(2)
driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']//li[@class='']").click()
sleep(2)
driver.switch_to.frame(driver.find_element_by_xpath("//div[@class='ux-login-set-container']//iframe"))
driver.find_element_by_xpath('//input[@id="phoneipt"]').send_keys("18870067165") #输入账号
sleep(2)
driver.find_element_by_xpath('//input[@placeholder="请输入密码"]').send_keys("Lxy671032") #输入密码
sleep(2)
driver.find_element_by_xpath('//div[@class="f-cb loginbox"]//a[@id="submitBtn"]').click() #点击登录
而点击我的课程这一步最开始的代码为:
driver.find_element_by_xpath('//div[@id="g-body"]//div[@class="_1Y4Ni"]//div[@class="_3uWA6"]').click()
总是点不进去,报这个错误:

上网查找资料得:
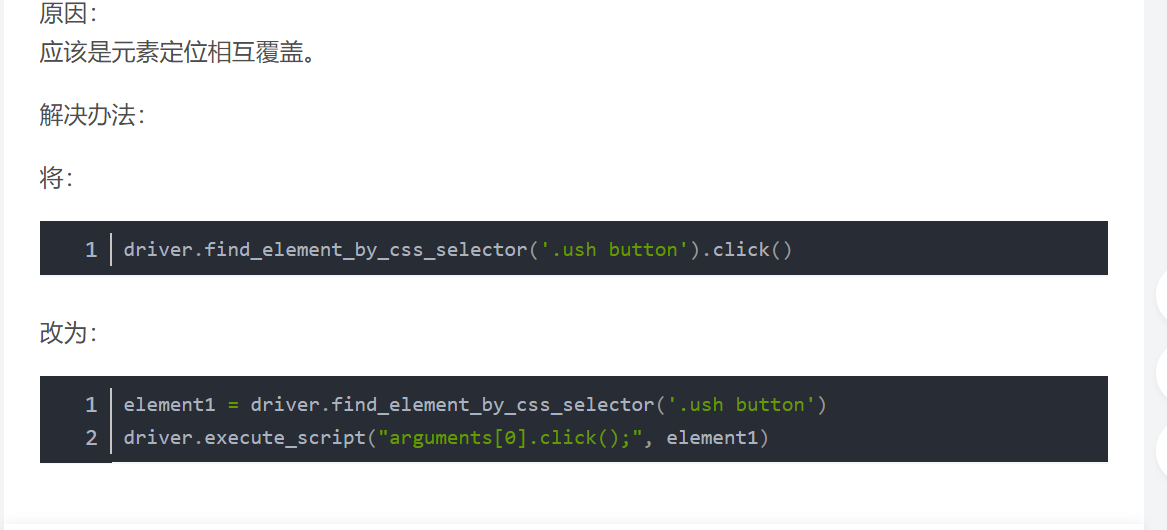
遂修改为如下
sleep(10)
element1 = driver.find_element_by_xpath('//div[@class="_3uWA6"]')#点击我的课程
driver.execute_script("arguments[0].click();", element1)
在编写option时,按照原有的跑了一版,报错如下:

在网上搜索资料得:

因此修改为:
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_argument('-enable-webgl')
option.add_argument('--no-sandbox')
option.add_argument('-disable-dev-shm-usage')
driver = webdriver.Chrome(options=option)
而在编写爬取代码时,检查页面元素得:
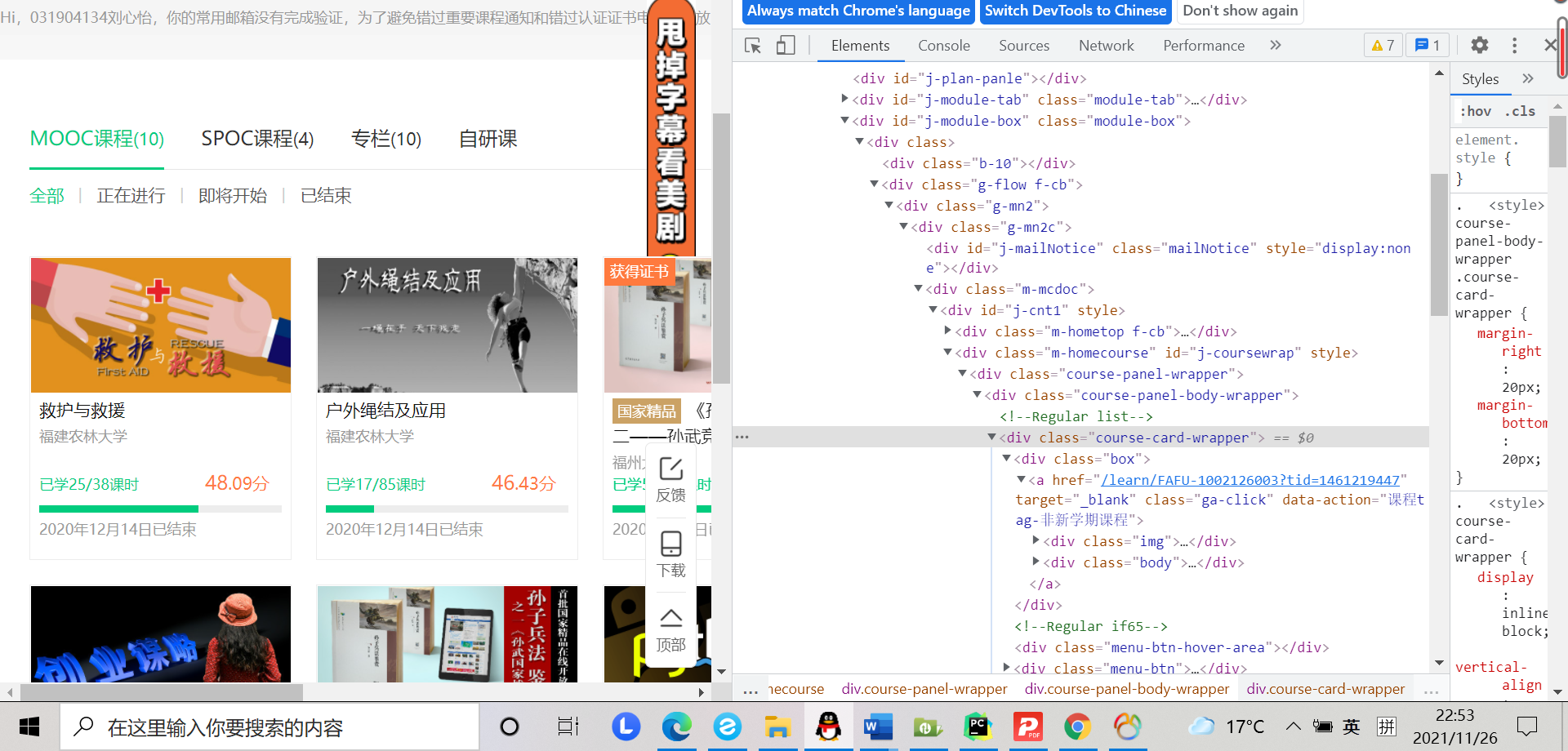
编写代码如下:
divs = driver.find_elements_by_xpath('.//div[@class="course-panel-body-wrapper"]//div')
for div in divs:
try:
count += 1
# print(count)
course = driver.find_element_by_xpath('//div[@class="title"]/div/span[@class="text"]').text
college = driver.find_element_by_xpath('//div[@class="school"]/a').text
schedule = driver.find_element_by_xpath('//div[@class="course-progress"]/div//a/span').text
coursestatus = driver.find_element_by_xpath('//div[@class="personal-info"]/div[@class="course-status"]').text
picurl = driver.find_element_by_xpath('//div[@class="img"]/img').get_attribute("src")
cid = str(count)
运行时报错如下:
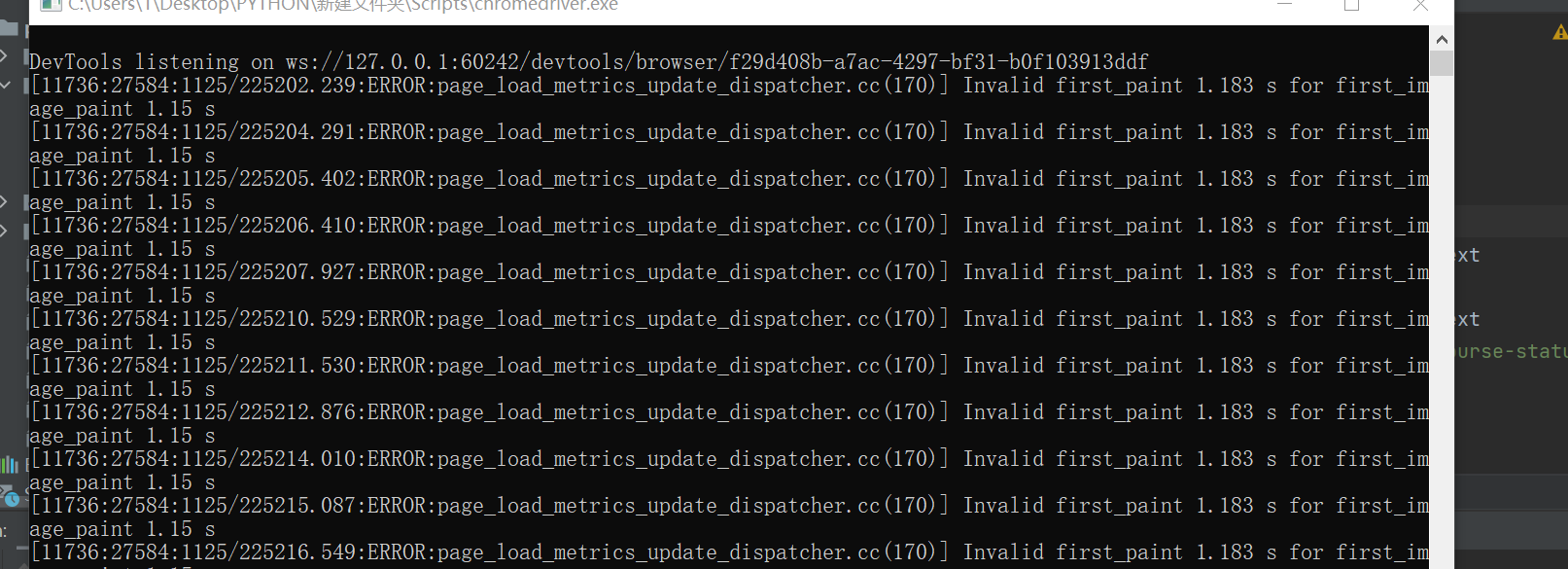
而询问助教,他说我的代码爬取结构有点问题,于是修改如下:
course = driver.find_elements(By.XPATH,'//*[@id="j-coursewrap"]/div/div[1]/div/div/a/div[2]/div/div/div/span[@class="text"]')
college = driver.find_elements(By.XPATH,'//*[@id="j-coursewrap"]/div/div[1]/div/div/a/div[2]/div/div[@class="school"]/a')
schedule = driver.find_elements(By.XPATH,'//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[2]/div[1]/div[1]/div[1]/a/span')
status = driver.find_elements(By.XPATH,'//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[2]/div[2]/div[2]')
imgurl = driver.find_elements(By.XPATH,'//*[@id="j-coursewrap"]/div/div[1]/div/div[1]/a/div[1]/img')
③代码链接
https://gitee.com/lyinkoy/crawl_project/blob/master/作业5/2.py
④运行结果:
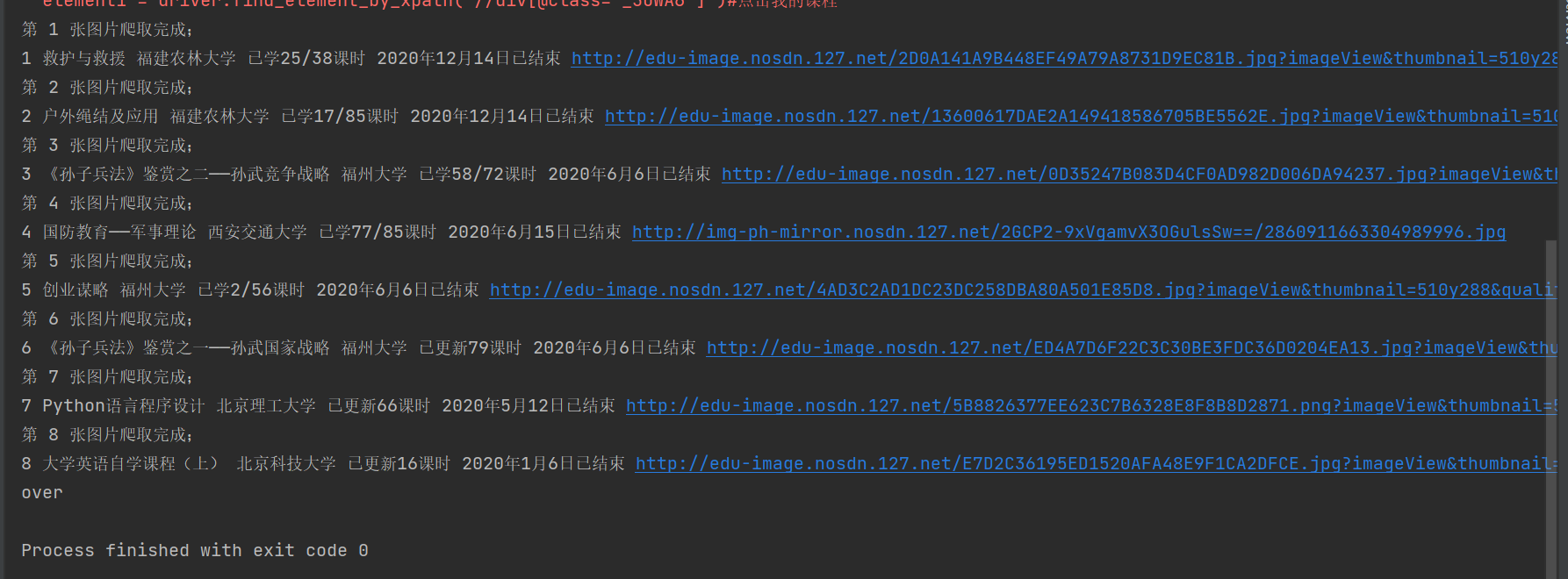


2)心得体会
在作业②中进一步系统学习了使用Selenium 查找HTML元素,xpath爬取信息的方法以及MySQL数据库的连接与写入,我在这一实验中在网上查找了许多资料,了解了许多之前被自己忽略的细节。并且注意到了我的电脑的写入特点,此外,在运行时发现:
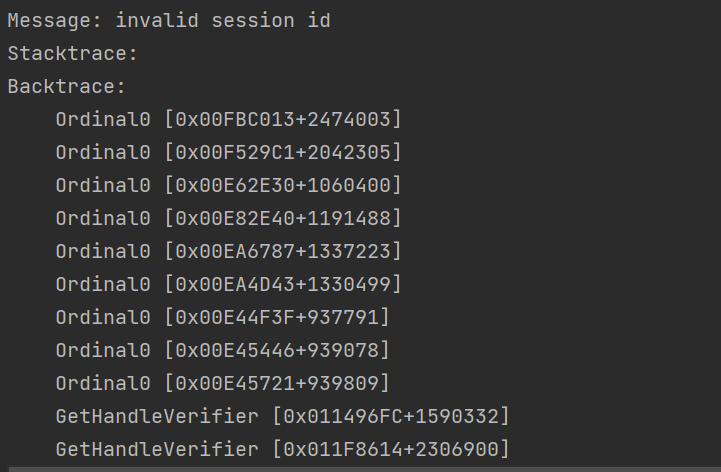
查资料得:
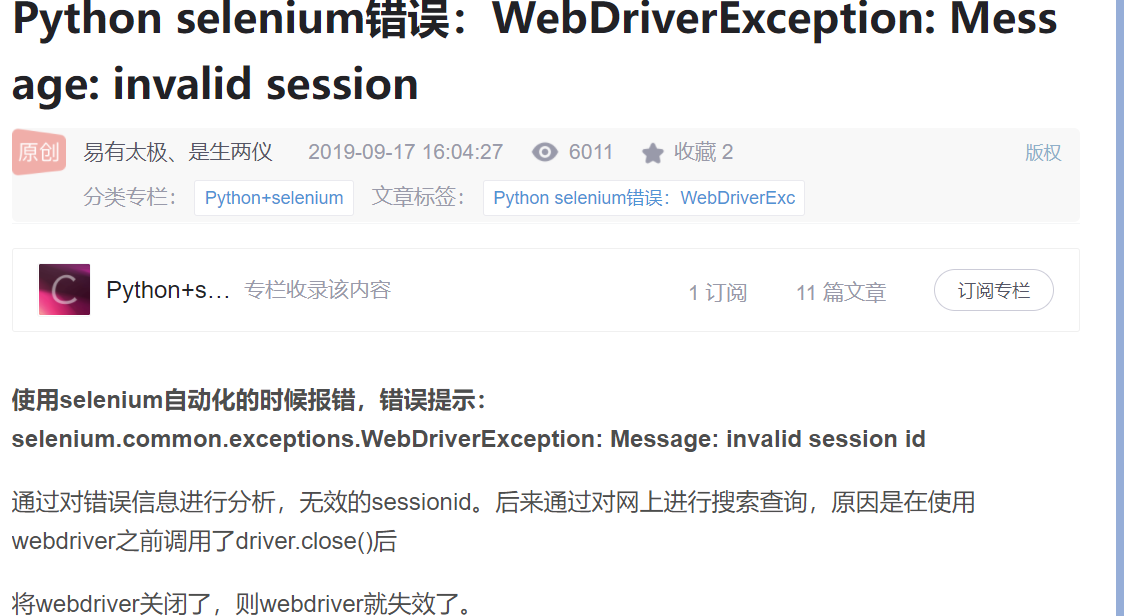
后检查driver的运行,修改成功。而在后面,又出现了这样的错误:

driver失效了,查资料得:

重装后解决,受益颇多。
作业③
1)实验内容及结果
①实验内容
要求:理解Flume架构和关键特性,掌握使用Flume完成日志采集任务。完成Flume日志采集实验,包含以下步骤:
任务一:开通MapReduce服务
任务二:Python脚本生成测试数据
任务三:配置Kafka
任务四:安装Flume客户端
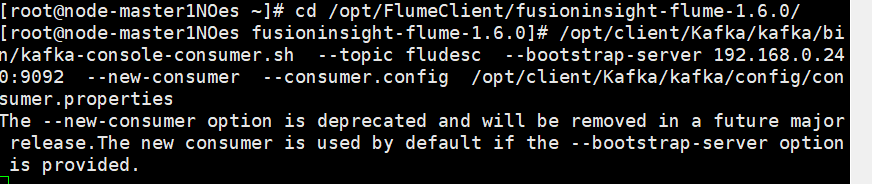
任务五:配置Flume采集数据
②运行结果:
开通MapReduce服务

Python脚本生成测试数据

配置Kafka
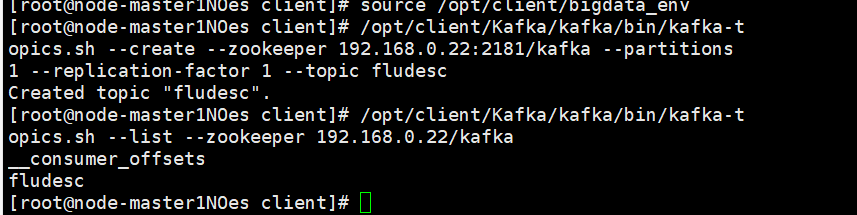
安装Flume客户端
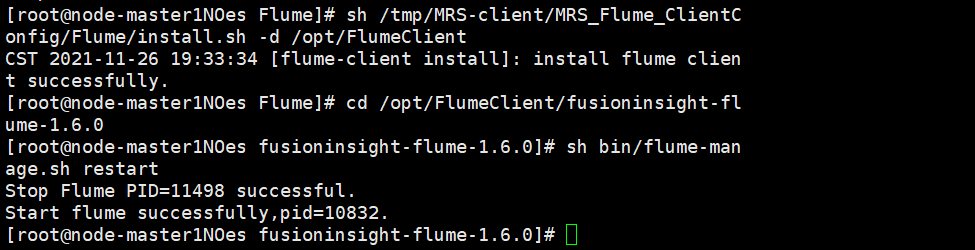
配置Flume采集数据
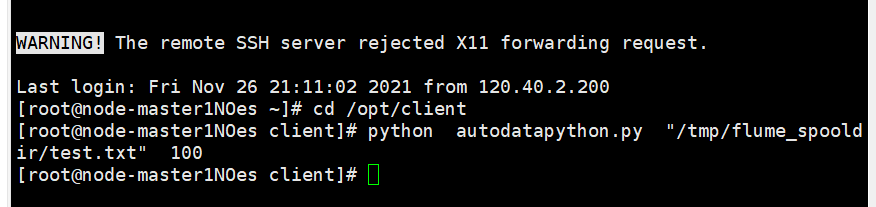
2)心得体会
在作业③初步的学习了华为云中Flume的基本使用,我在这一实验中尝试了理解Flume架构和关键特性,并且尝试掌握使用Flume完成日志采集任务,受益颇多。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号