
数据采集与融合技术实践第四次作业
数据采集与融合技术实践第四次作业
姓名:刘心怡 学号:031904134 班级:2019级大数据一班
作业①
1)实验内容及结果
①实验内容
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取当当网站图书数据
候选网站:http://search.dangdang.com/?key=python&act=input
关键词:学生可自由选择
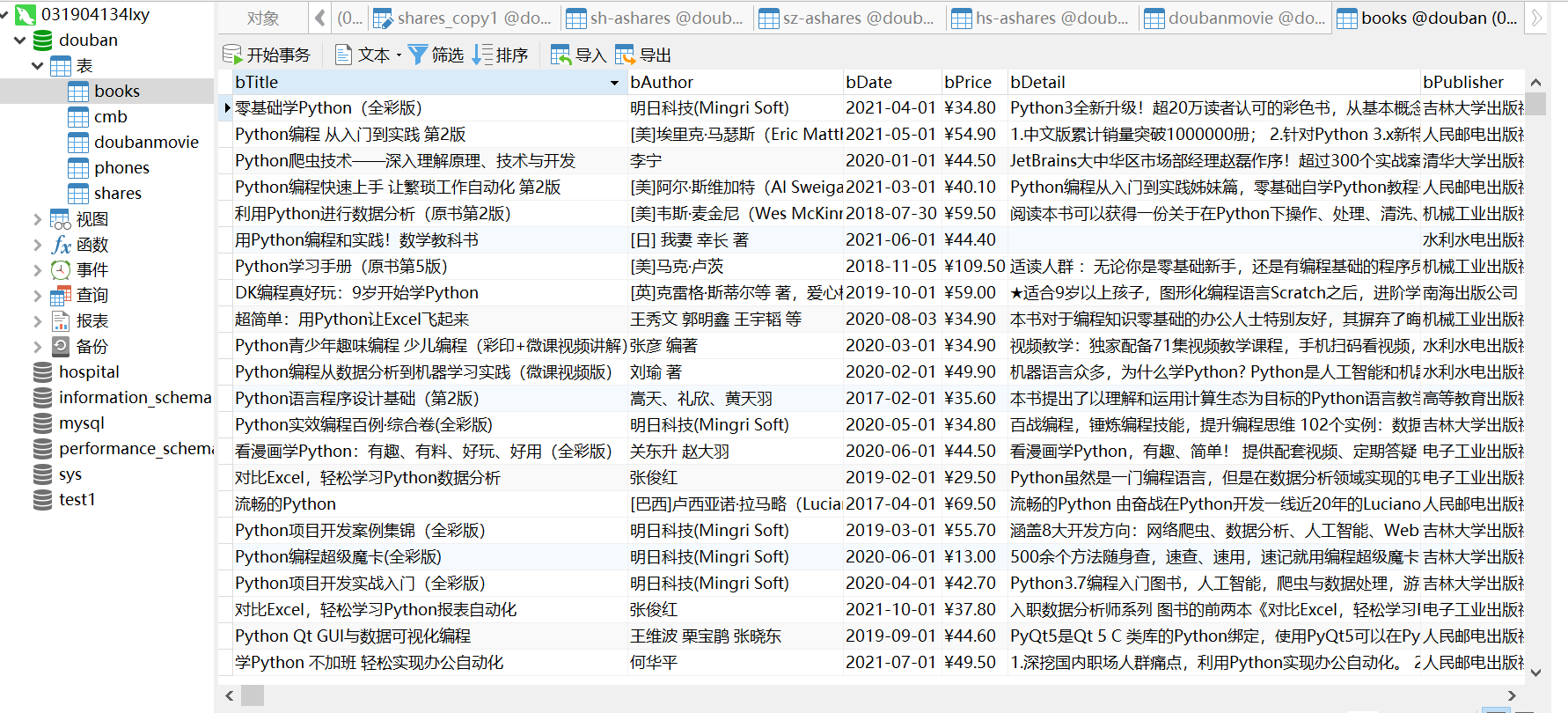
输出信息:MySQL的输出信息如下

②实验步骤
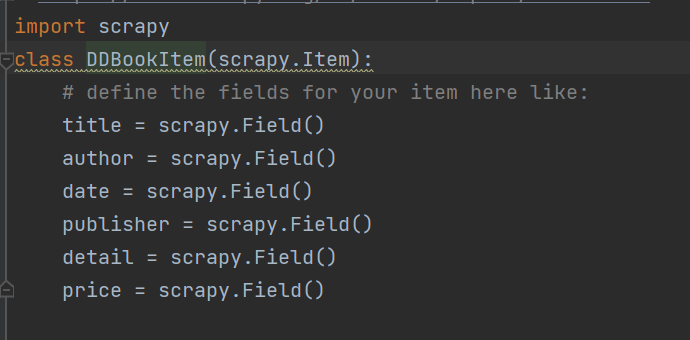
首先,题目需要爬取上述项目,因此编写item如下
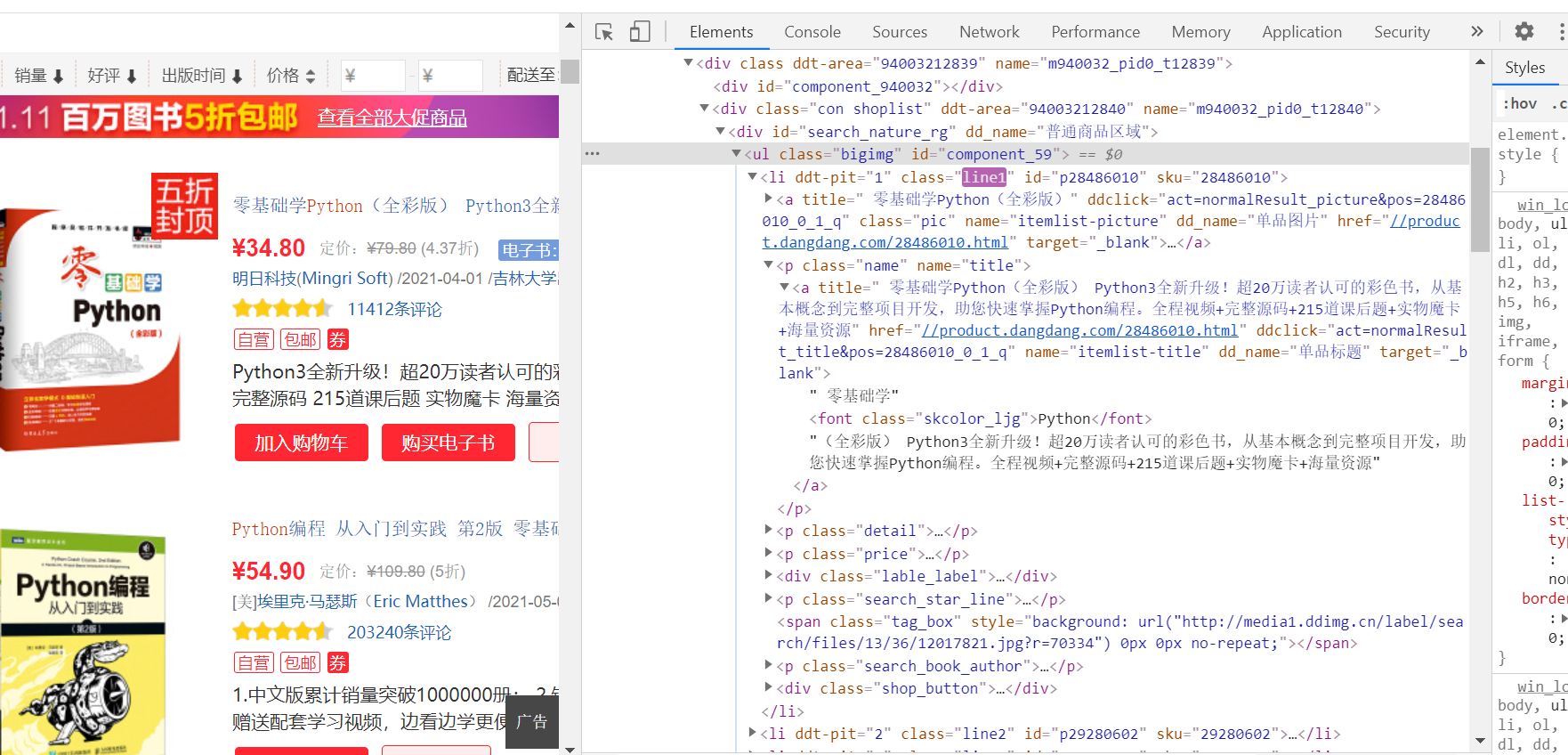
之后观察网页结构
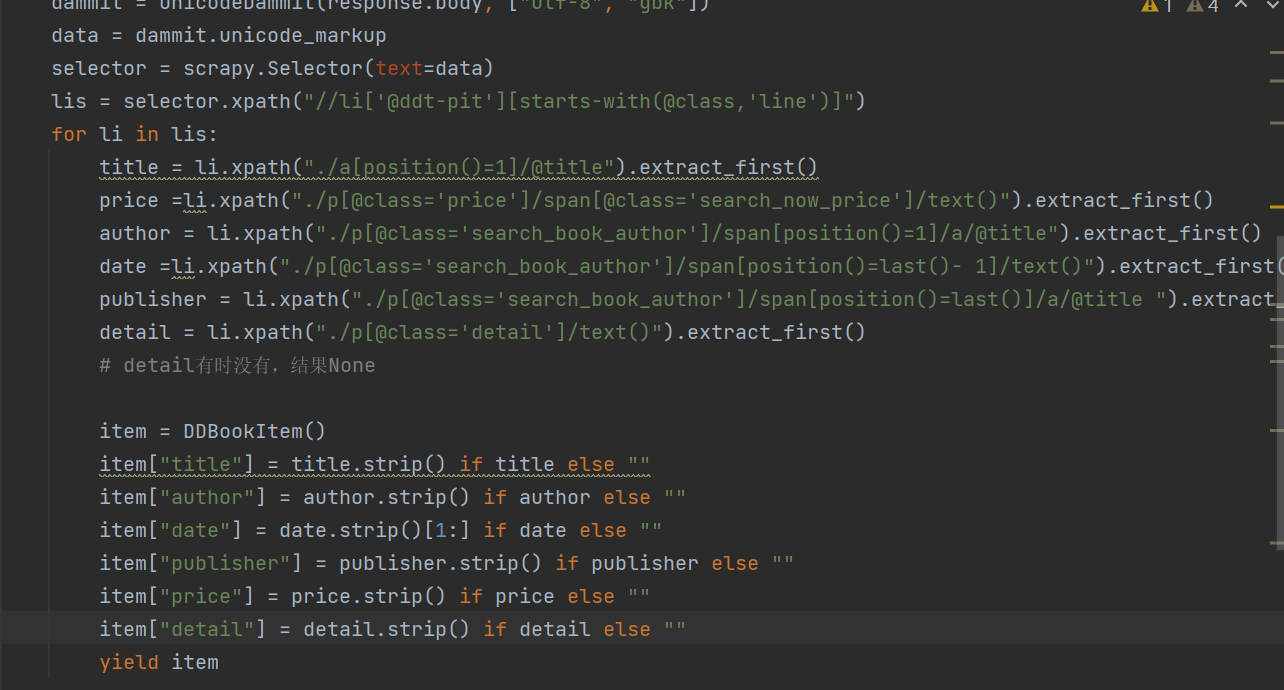
因此,编写myspider中爬取核心代码如下
之后涉及到数据库的存取,经过老师的纠错过程,了解到我的电脑在插入时需要逐条插入逐条提交,因此改出pipelines文件中涉及写入数据库部分如下

③代码链接
Items: https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/1/items.py
myspider: https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/1/myspider.py
Pipelines: https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/1/pipelines.py
Run:https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/1/run.py
④运行结果
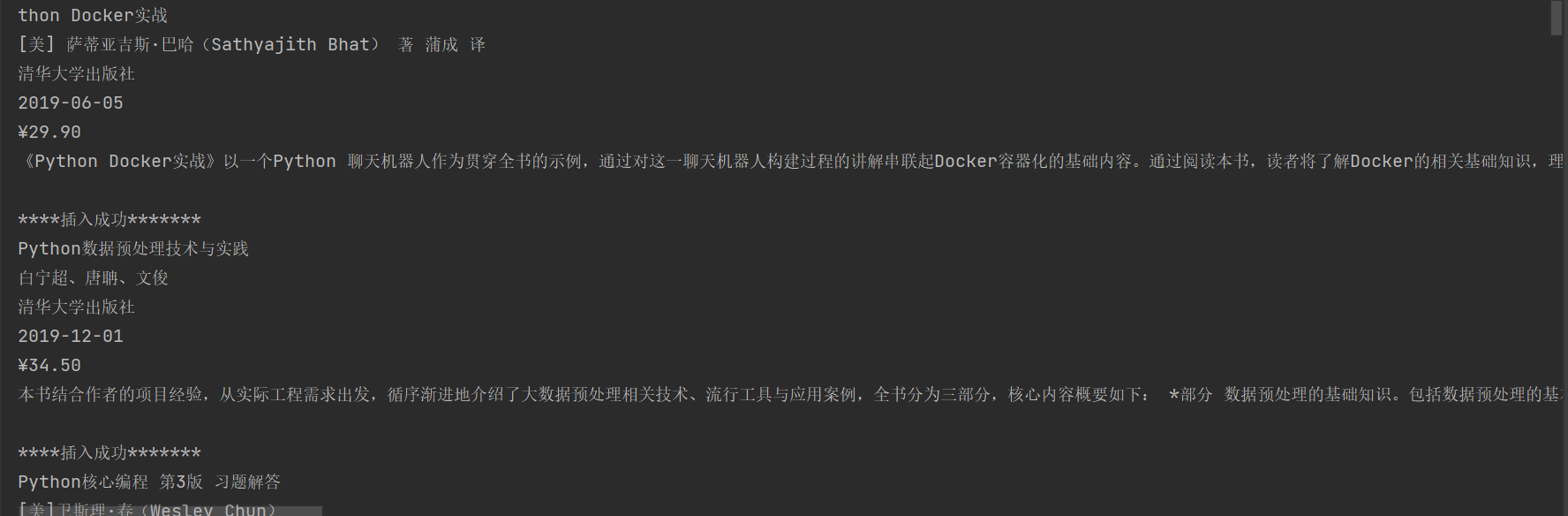
数据库中结果:
2)心得体会
在作业①系统的学习了基本的使用scrapy框架爬取数据方法,xpath爬取信息的方法以及MySQL数据库的连接与写入,我在这一实验中一一体会,了解到一些解决无法写入数据库的方法,受益颇多。
作业②
1)实验内容及结果
①实验内容
要求:熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;使用scrapy框架+Xpath+MySQL数据库存储技术路线爬取外汇网站数据。
候选网站:招商银行网:http://fx.cmbchina.com/hq/
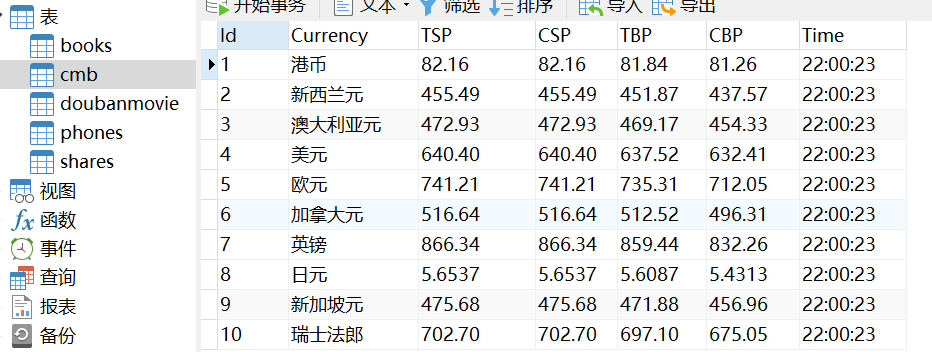
输出信息:MySQL数据库存储和输出格式
Id Currency TSP CSP TBP CBP Time
1 港币 86.60 86.60 86.26 85.65 15:36:30
2......
②实验步骤
首先,题目需要爬取上述项目,因此编写item如下

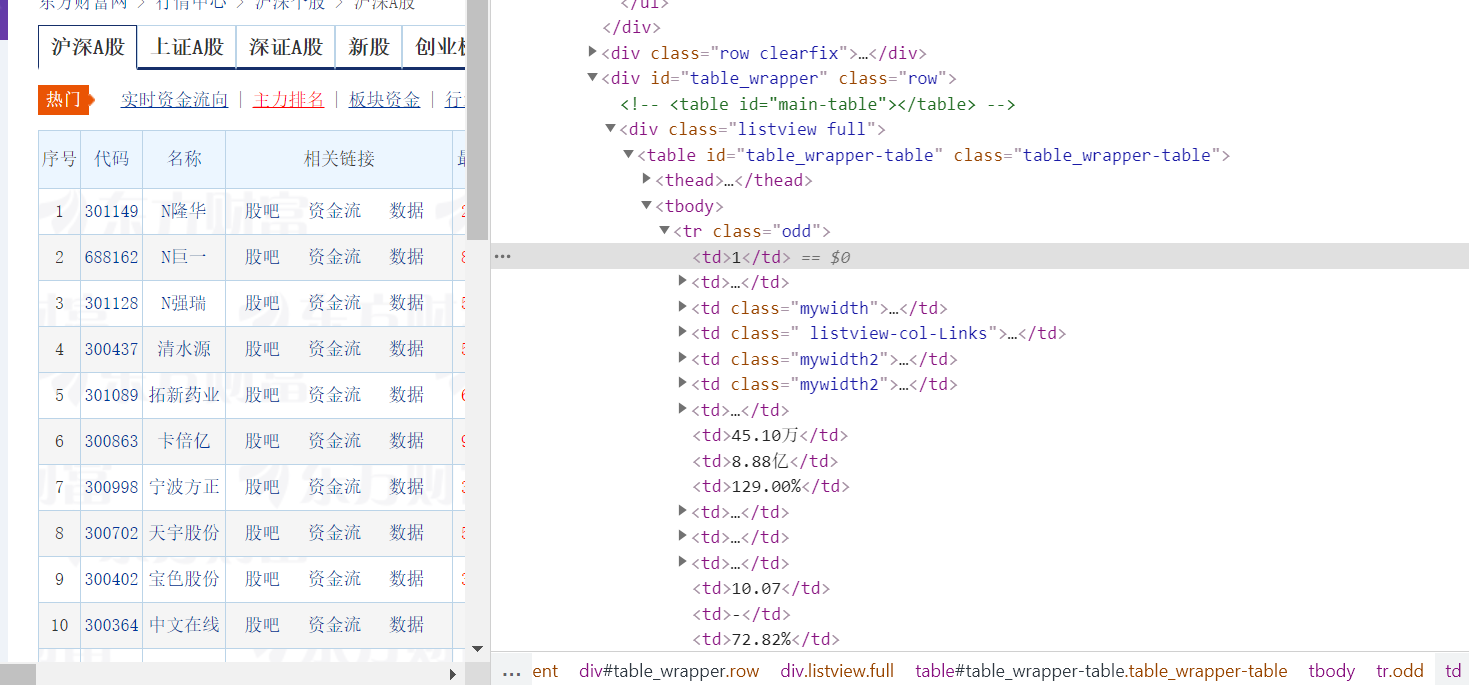
之后观察网页结构
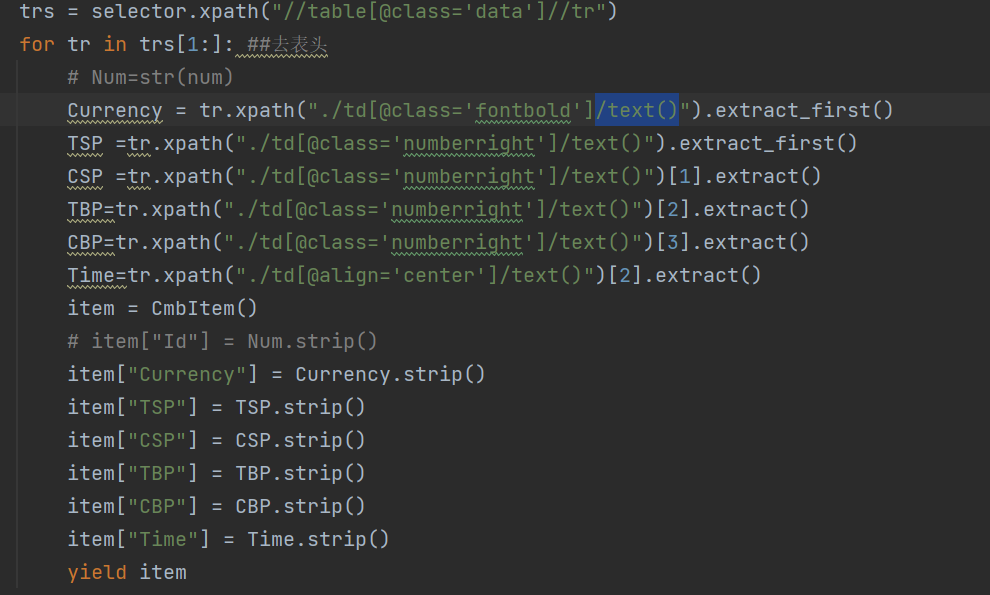
因此,编写爬取信息部分代码如下
之后涉及到数据库的存取,吸取作业①中的经验,改出pipelines文件中涉及写入数据库部分如下
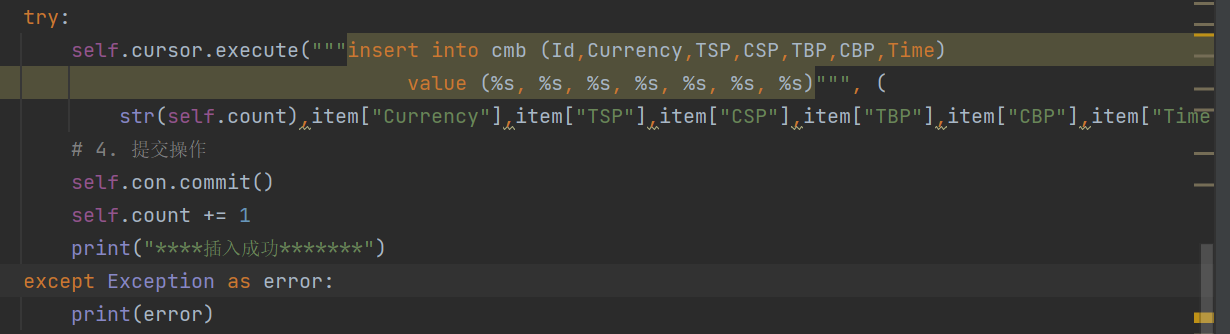
③代码链接
Items: https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/2/items.py
myspider: https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/2/myspider.py
Pipelines: https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/2/pipelines.py
Run:https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/2/run.py
④运行结果:
数据库中结果
2)心得体会
在作业②系统的进一步学习了使用scrapy框架爬取数据的基本方法,xpath爬取信息的方法以及MySQL数据库的连接与写入,我在这一实验中吸取上作业的经验教训,受益颇多。
作业③
1)实验内容及结果
①实验内容
要求:熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容;使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MySQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55
2......
②实验步骤
首先,检查页面结构

因此,可编写爬取部分如下
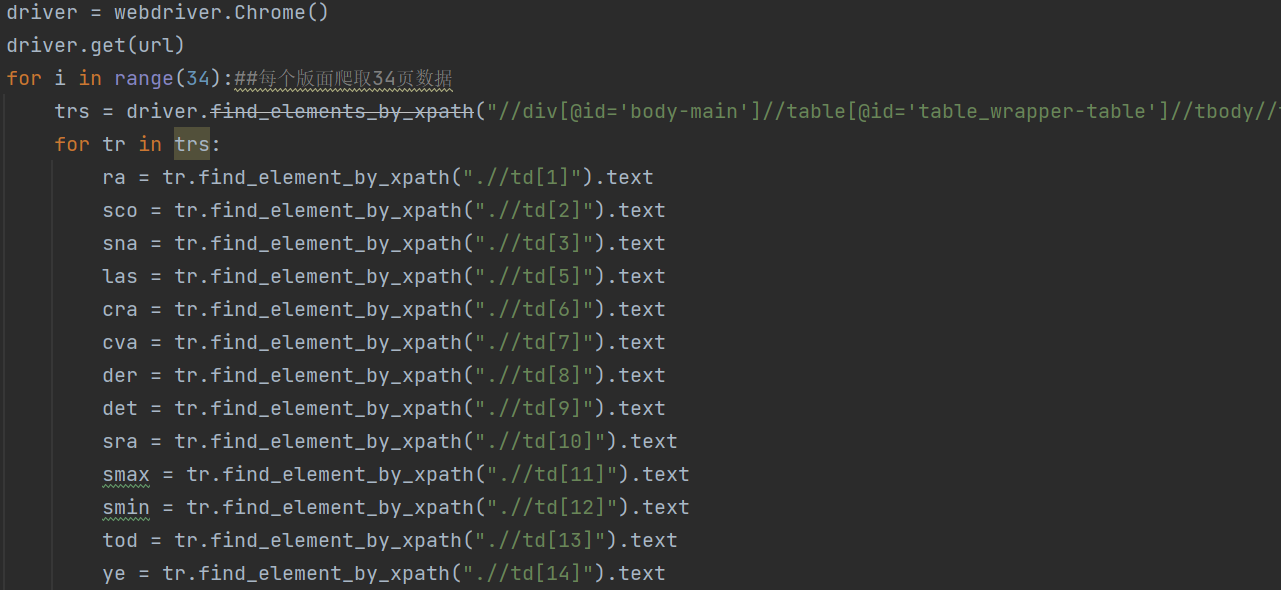
随后,查看沪深A股”、“上证A股”、“深证A股”3个板块的url,
http://quote.eastmoney.com/center/gridlist.html#hs_a_board
http://quote.eastmoney.com/center/gridlist.html#sh_a_board
http://quote.eastmoney.com/center/gridlist.html#sz_a_board
可发现他们都是由http://quote.eastmoney.com/center/gridlist.html#加上一个标记模块组成,因此可以通过如下代码实现三个板块的股票数据信息的爬取:

之后,处理翻页,查看网站中下一页结构可得:
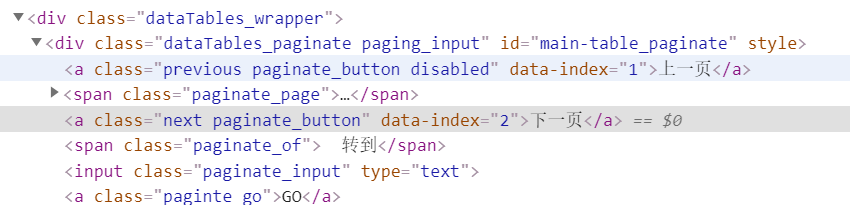
因此,可以编写click“下一页”的步骤完成翻页

最后是数据库的写入,由于采用之前的insert方法无法成功写入(报sql语句有语法问题,但我和我室友两个人实在是找不出来…)最后在网上找了一种全新的方法成功写入了数据库。

③代码链接
https://gitee.com/lyinkoy/crawl_project/blob/master/作业4/3.py
④运行结果:
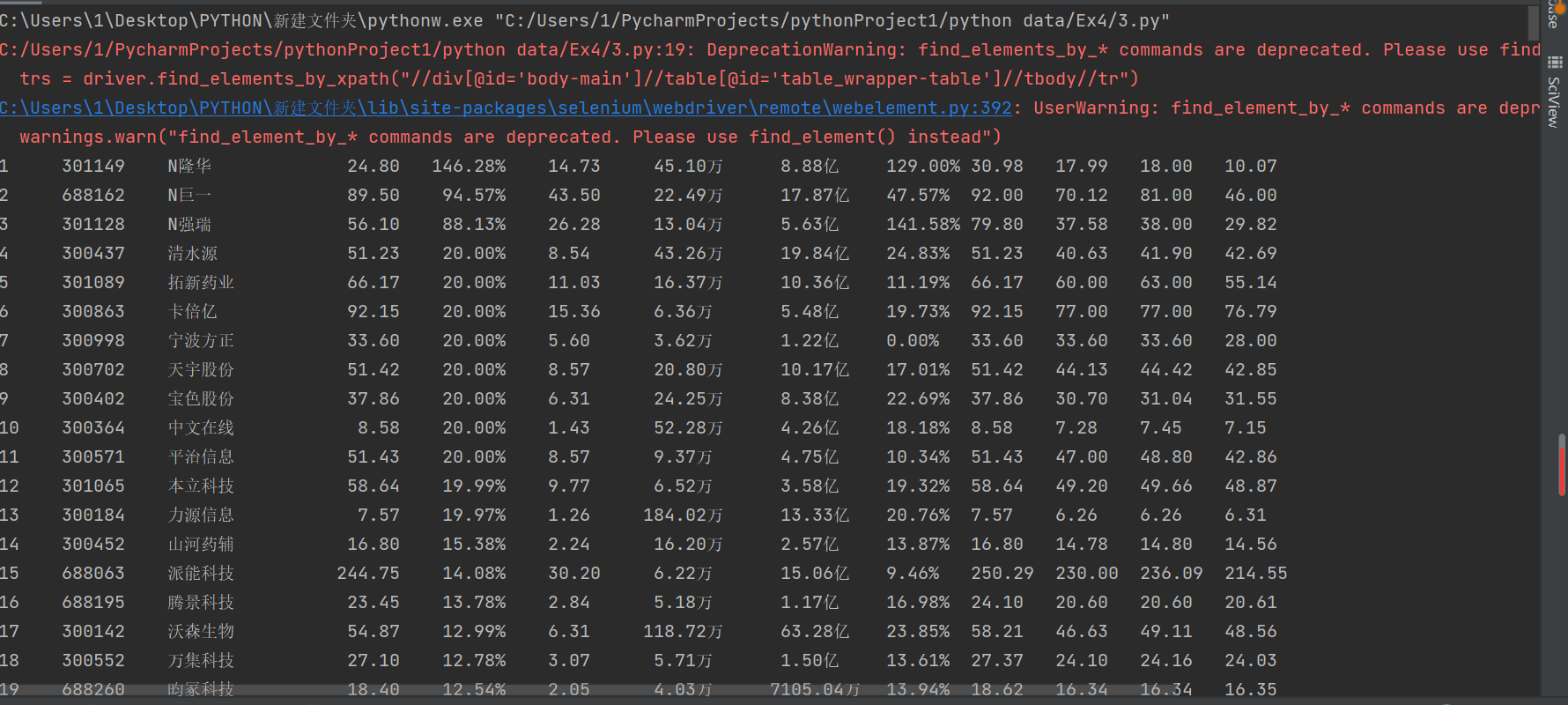
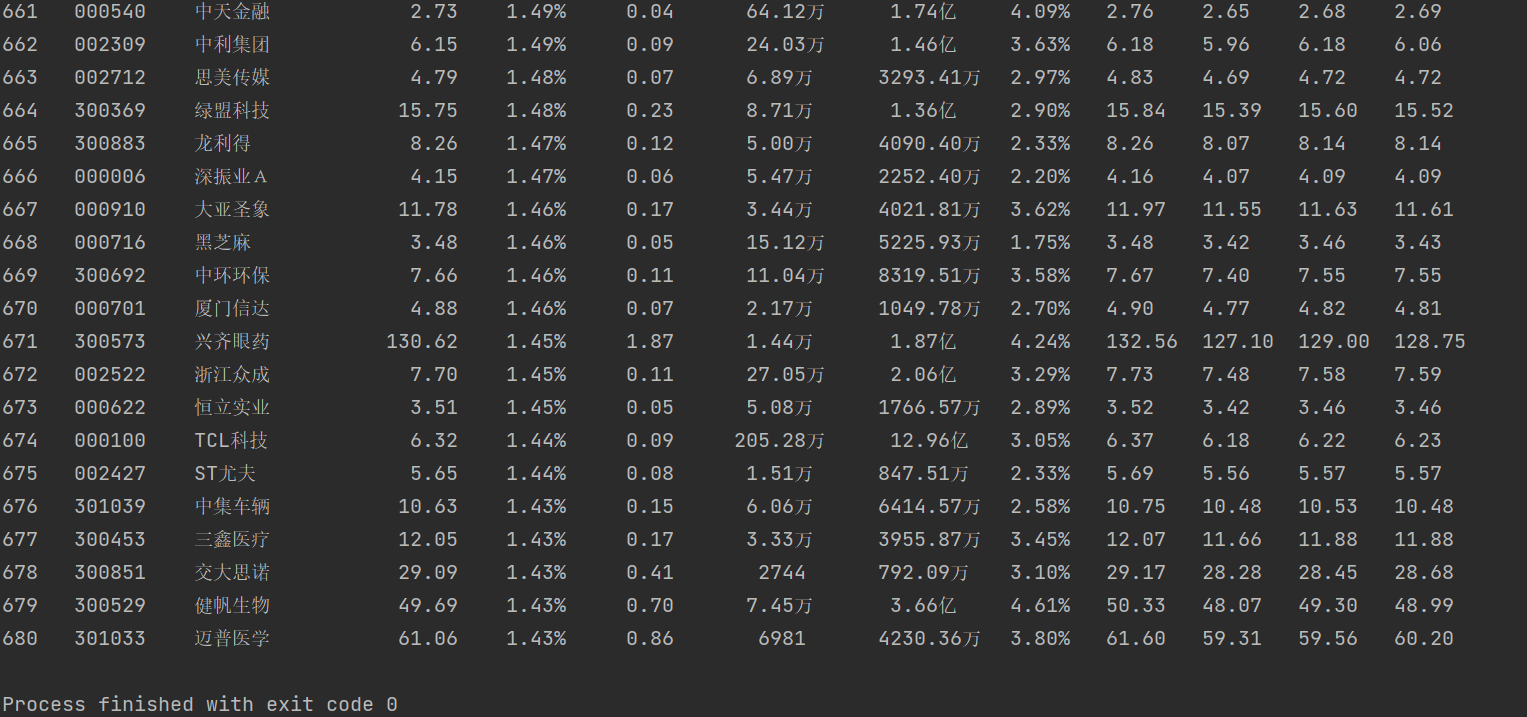
数据库中结果:
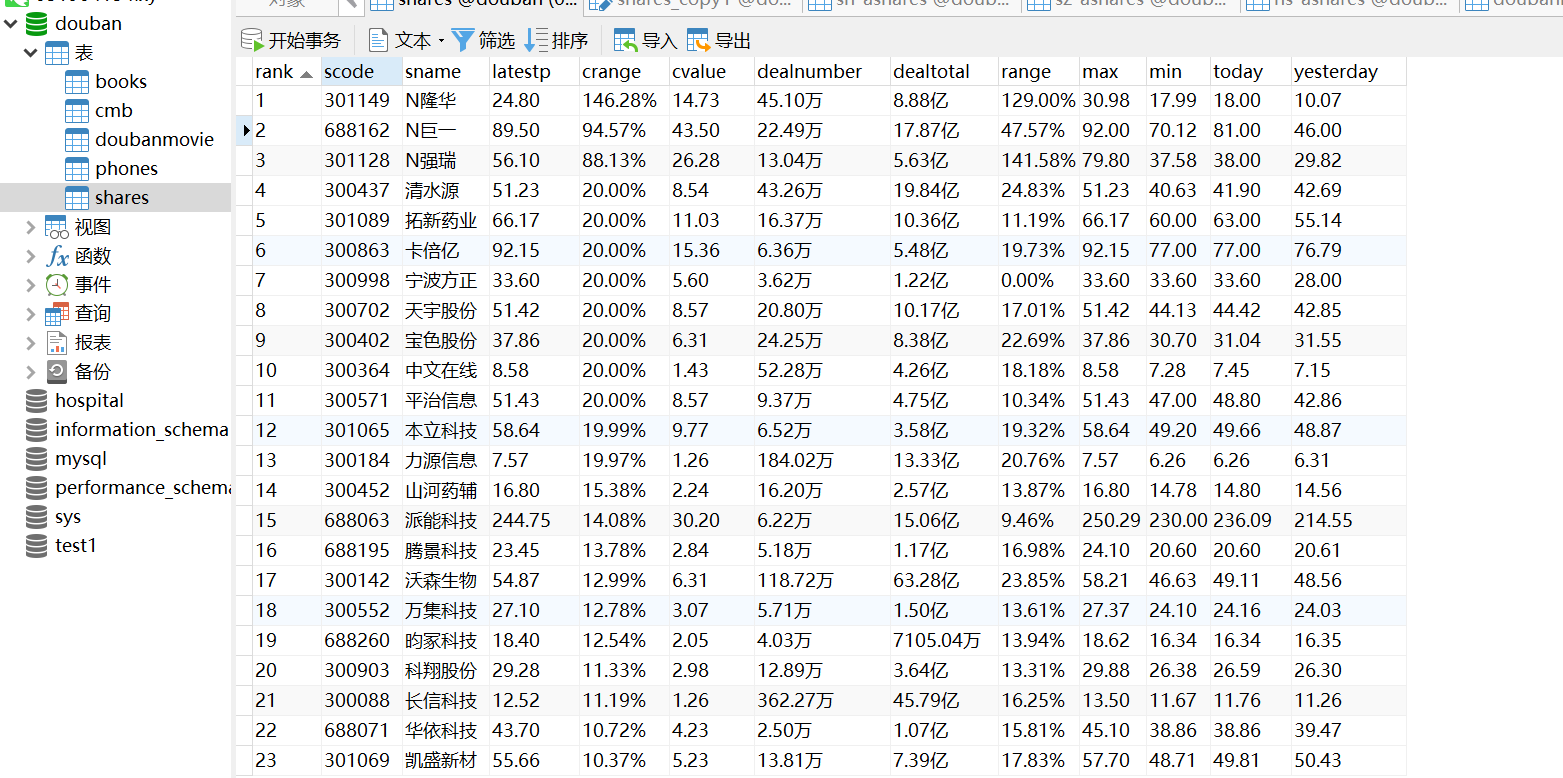
2)心得体会
在作业③中系统学习了使用Selenium 查找HTML元素,xpath爬取信息的方法以及MySQL数据库的连接与写入,我在这一实验中在网上查找了许多资料,了解了许多之前被自己忽略的细节,受益颇多。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号