
数据采集与融合技术实验报告二
数据采集与融合技术-实验报告二
姓名:刘心怡 学号:031904134 班级:2019级大数据一班
作业①
1)实验内容及结果
①实验内容
要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
输出信息:
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
|---|---|---|---|---|
| 1 | 北京 | 7日(今天) | 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 | 31℃/17℃ |
| 2 | 北京 | 8日(明天) | 多云转晴,北部地区有分散阵雨或雷阵雨转晴 | 34℃/20℃ |
| 3 | 北京 | 9日(后台) | 晴转多云 | 36℃/22℃ |
| 4 | 北京 | 10日(周六) | 阴转阵雨 | 30℃/19℃ |
| 5 | 北京 | 11日(周日) | 阵雨 | 27℃/18℃ |
| 6...... |
②实验思路
实验涉及数据库的读写,而这就必须预先设计一个代码以完成数据库的建立与insert等相关内容
代码:
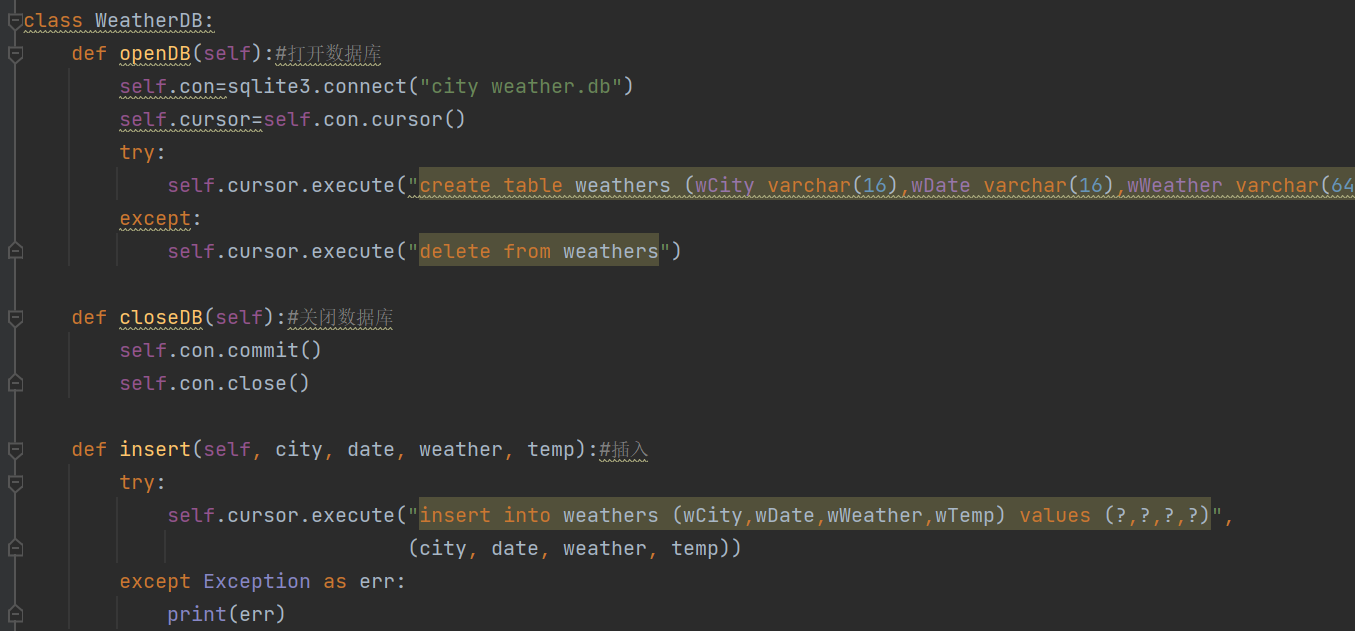
而除此之外,涉及到不同地区的天气数据读取,需要设计一个函数实现url的转换
代码:

③实验代码链接
代码链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业2/1.py
数据库链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业2/1.city weather.db
④运行结果
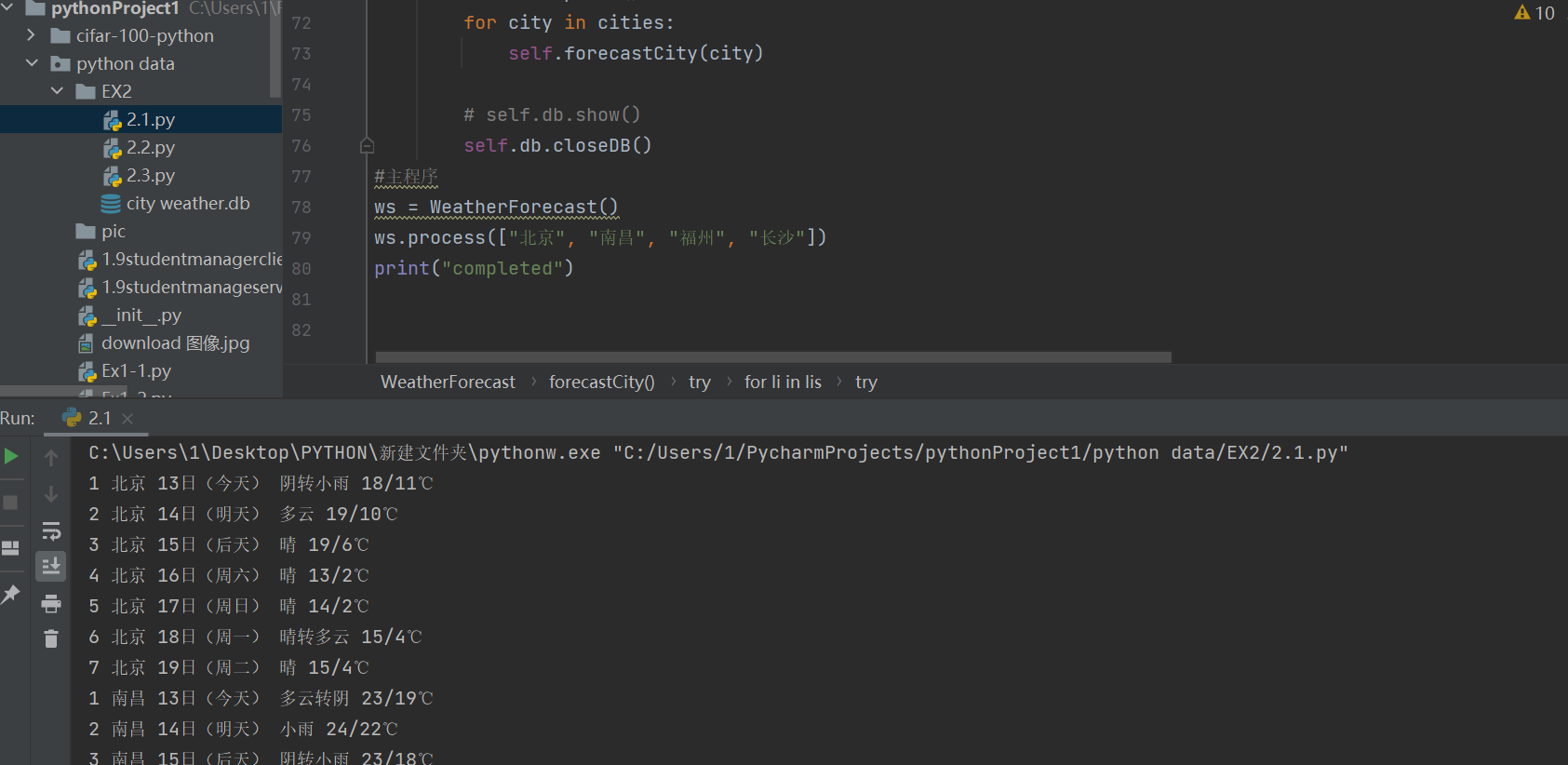
2)心得体会
本次实验作业①涉及网页数据的爬取与数据库的写入,而在最开始通过先前的学习内容就能发现,数据爬取内容与先前无二,而数据库相关的操作知识我却十分欠缺,因此,借鉴书中的例题2.6.4,我凭借书上的代码修改出了能跑出我所求的数据的代码,但在爬取天气信息过程中我因为忘记结构本身是一个大的循环而且原代码内部由于爬取不同城市天气因此也涉及天气码的选择而在其中花费了不少时间,其中,代码本身是定义了一个process函数,输入内容包含一个字符串列表,通过逐一扫描列表中各项内容,通过转换为对应的天气码而构造完整url,根据其对各城市逐一爬取。综上,我在本次实验的该项作业中获益颇丰。
作业②
1)实验内容及结果
①实验内容
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:
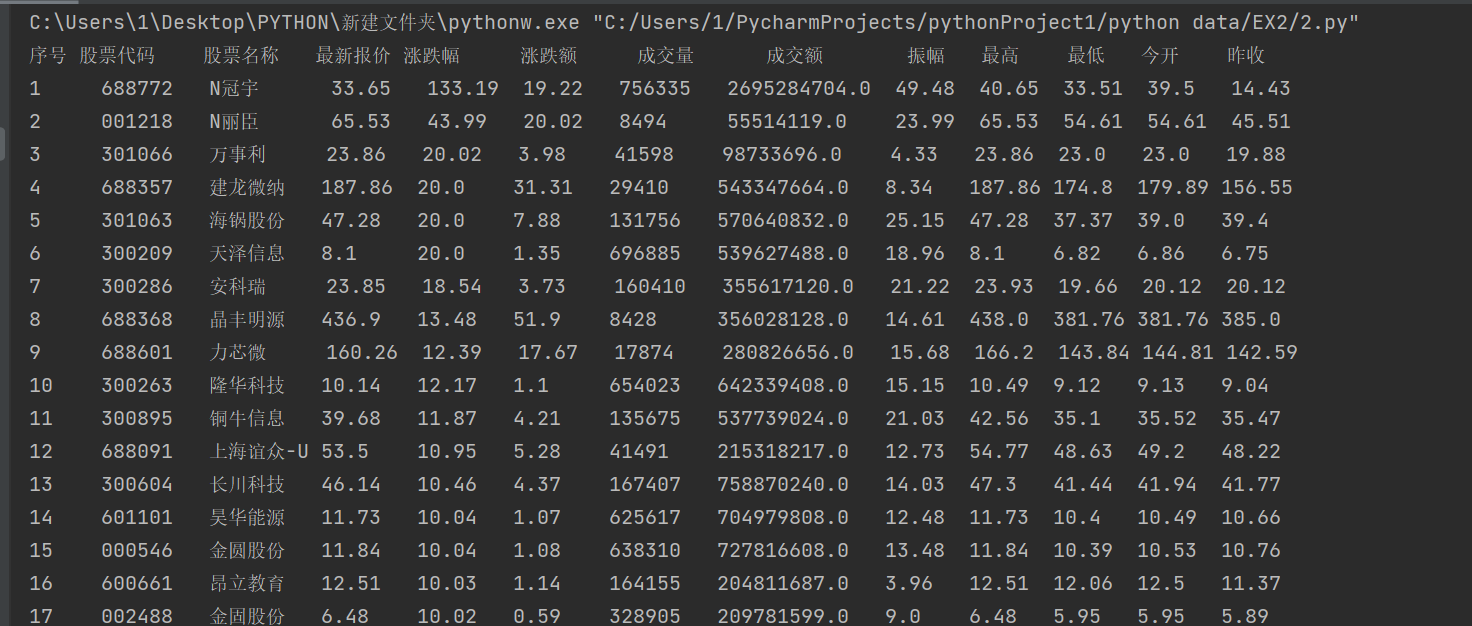
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收
1 688093 N世华 28.47 62.22% 10.92 26.13万 7.6亿 22.34 32.0 28.08 30.2 17.55
2......
②实验思路
实验涉及数据库的读写,而这就必须预先设计一个代码以完成数据库的建立与insert等相关内容
代码:
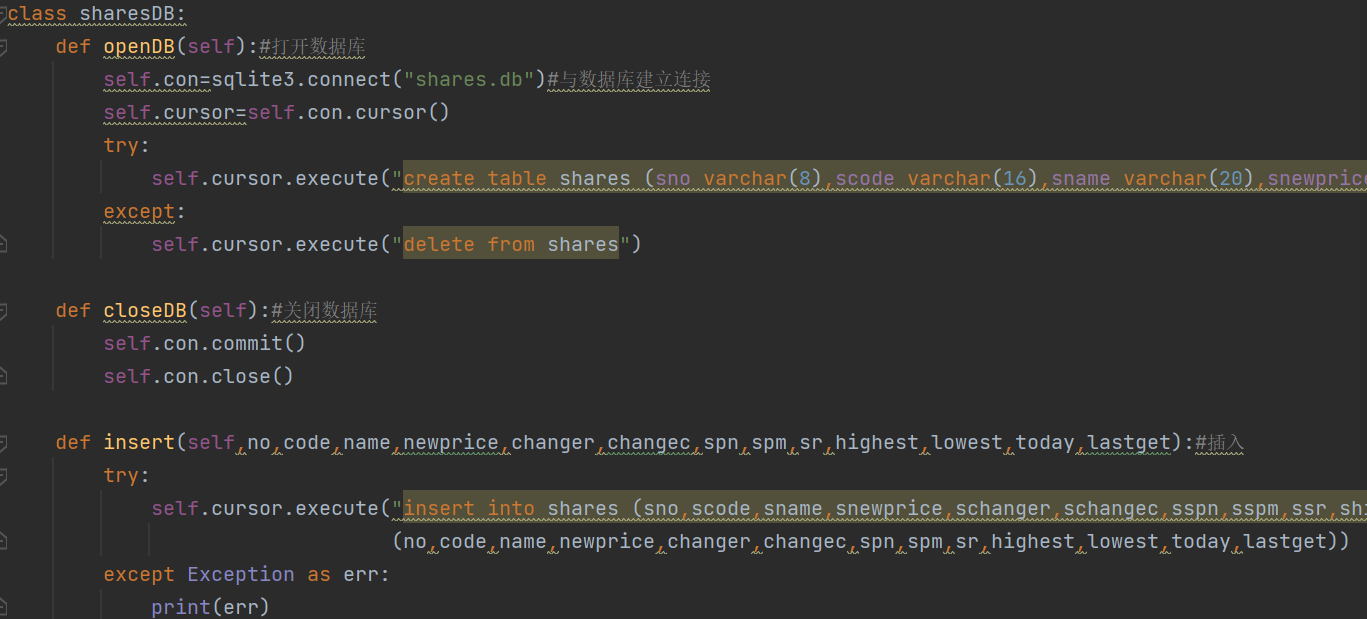
通过观察网站的信息可发现所需爬取的各项数据对应‘fi’因此可以设计数据爬取部分如下:
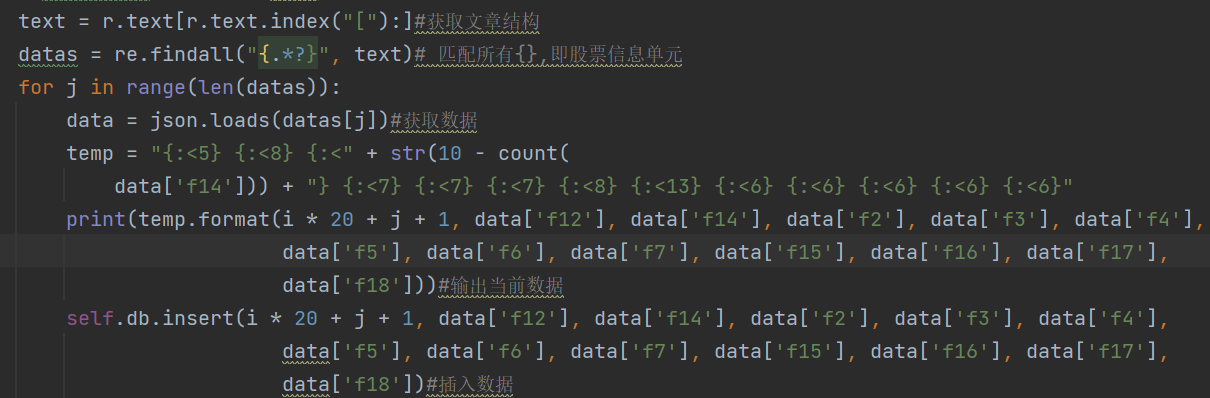
③实验代码链接
代码链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业2/2.py
数据库链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业2/2.shares.db
④运行结果

2)心得体会
本次实验作业②涉及的内容仍旧是网页数据的爬取与数据库的写入,我在候选网站中选择了东方财富网:https://www.eastmoney.com/,根据作业①中的代码可以按照其思路修改出作业②的代码,而在具体的实施过程中,由于实在是涉及太多项数据,因此规范的格式输出就成为了非常重要的一项内容,在通过查阅网络上的资料之后,我发现除了tplt,format(,chr(12288))方式之外的另外一种对齐方式”{:<x}”.format(),其中(><^)分别表示右对齐,左对齐与居中对齐,而x代表具体格数,通过该方式能将数据整齐的输出,而在数据爬取方面,我参考网上的资料尝试使用json来进行,而这与beautifulsoup有略微差别,在学习之后我也能较好的使用,我在本次实验的该项作业中获益颇丰。
作业③
1)实验内容及结果
①实验内容
要求: 爬取中国大学2021主榜 https://www.shanghairanking.cn/rankings/bcur/2021
所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
输出信息:
排名 学校 总分
1 清华大学 969.2
②实验思路
网页抓包过程如下:
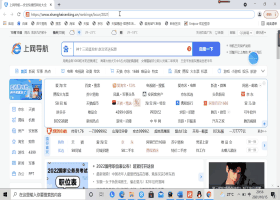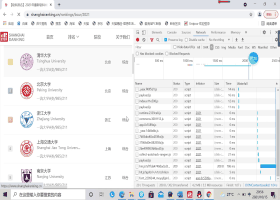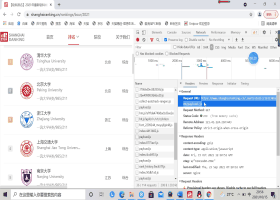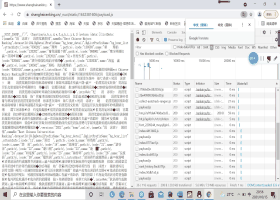
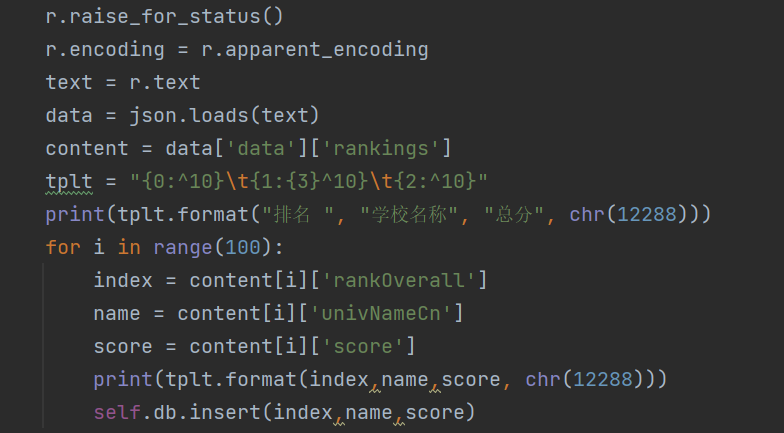
通过观察网站的信息可发现所需爬取的各项数据对应内容因此可以设计数据爬取部分如下:
③实验代码链接
代码链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业2/3.py
数据库链接:https://gitee.com/lyinkoy/crawl_project/blob/master/作业2/3.University.db
④运行结果
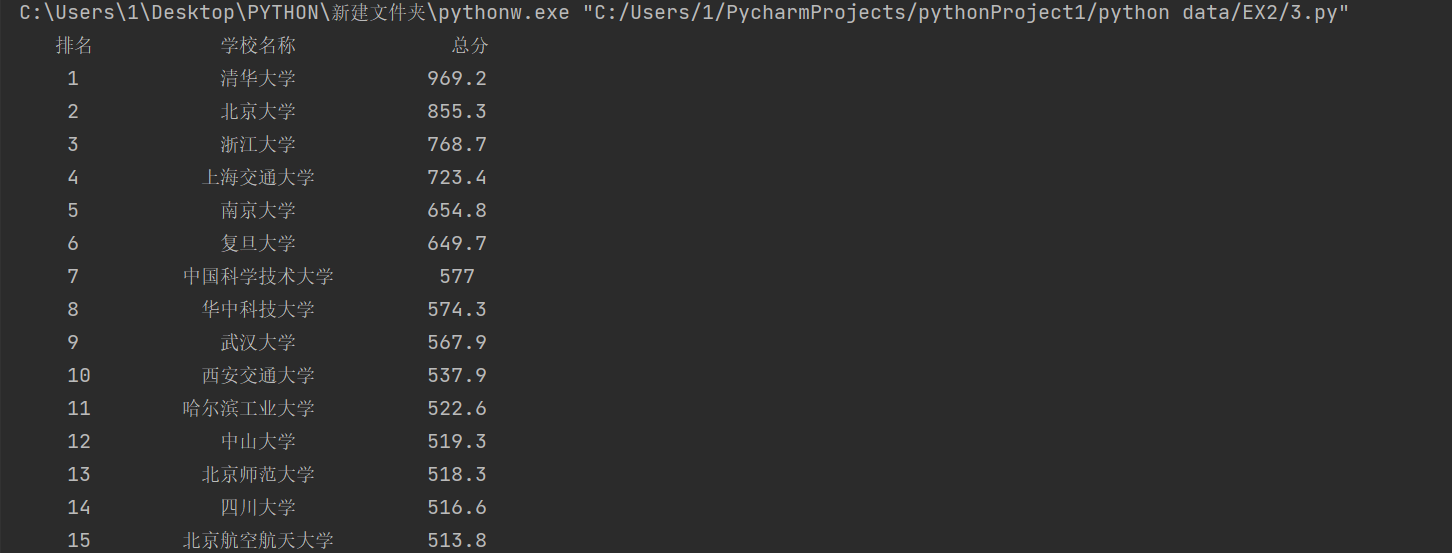
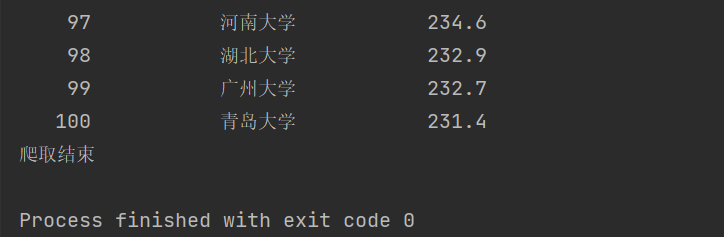
2)心得体会
本次实验作业③涉及的内容仍旧是网页数据的爬取与数据库的写入,根据作业①中的代码可以按照其思路修改出作业③的代码,而在具体的实施过程中,由于涉及数据项较少,因此仍旧使用tplt,format(,chr(12288))方式,通过该方式能将数据整齐的输出。而在数据爬取方面,我参考网上的资料尝试使用json来进行,而这与beautifulsoup有略微差别,在学习过程中,我通过网上资料发现网页数据的获取方法,在运行阶段,在先前未设计一个数据库作为主函数中的主体,因此在初次尝试时总会报缺少self对象的错误,通过询问助教后发现是该项错误改正后程序即可正常运行。我在本次实验的该项作业中获益颇丰。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号