论文翻译:2021_Low-Delay Speech Enhancement Using Perceptually Motivated Target and Loss
论文地址:使用感知动机目标和损失的低延迟语音增强
引用格式:Zhang X, Ren X, Zheng X, et al. Low-Delay Speech Enhancement Using Perceptually Motivated Target and Loss[J]. Proc. Interspeech 2021, 2021: 2826-2830.
摘要
基于深度神经网络的语音增强方法优于传统的信号处理方法。我们提出了一种利用新的感知激励训练目标和损失函数的低延迟语音增强方法。该方法可以获得与现有方法相似的语音增强性能,但显著降低了延迟和计算复杂度。通过INTERSPEECH 2021深度噪声抑制挑战组织者进行的MOS测试,该方法在背景噪声MOS中排名第二,在整体MOS中排名第六。
关键词:语音增强、时频掩蔽、深度神经网络、单通道
1 引言
单通道语音增强的目的是将纯净语音从带噪语音中分离出来。传统的基于信号处理的方法旨在对噪声频谱建模以执行谱减法[1]或维纳滤波[2]。近年来,基于深度神经网络(DNNs)的方法性能优于传统方法。这些方法通常以有监督的方式进行训练,可以分为时域方法和时频域方法。文献[3]、[4]中提出的时域方法直接输入带噪语音波形来估计纯净语音。虽然时域方法可以实现端到端处理,但折衷是放弃了语音和噪声信号在时频域中的稀疏性,如[5]中所述。文献[6]、[7]和[8]、[9]中提出的时频域方法分别采用DNN对纯净语音的幅值和复谱进行建模。虽然将训练目标设置为复数谱可以达到比幅度谱更高的预测上界,但也带来了复杂度的增加,这可能不适合实际的实时应用。此外,在去年的DNS挑战赛[10]中,使用这两个训练目标的方法可以达到相对的感知质量[11]。本文以感知最优幅度谱为训练目标,在时频域内对低时延、低复杂度的单通道语音增强进行了研究。
本文提出了一种预处理方法,以产生感知上最优的幅度谱作为训练目标。当纯净语音的幅谱与输入有噪信号的相位相结合时,目标语音信号的上界下降,特别是在低信噪比(SNR)条件下。这是因为对于低信噪比的时频瞬时,噪声相位与理想语音相位有很大的不同。在应用所提出的预处理方法之前,研究了常用的理想掩模产生的训练目标的上界。类似的研究可以在文献[12]中找到,其中比较了不同理想掩模产生的训练目标的信噪比(SAR),本文直接比较了经典维纳掩模[14]、理想比掩模(IRM)[15]和理想幅度掩模(IAM)[12]得到的训练目标的PESQ[13]。研究发现,IAM在不同的信噪比条件下都能获得最高的PESQ得分。使用所提出的预处理方法进一步压缩IAM。在信噪比为-10dB~25dB的情况下,对于可达到的训练目标,所提出的预处理方案可以获得平均0.11PESQ的改善。具体地说,对于5dB到15dB的条件,PESQ改善在0.15以上。
在预处理方案的基础上,提出了一种新的损失函数,将压缩后的IAM与幅度谱损失计算相结合。所提出的损失函数引入IAM加权因子来均衡对数压缩幅度的重要性。其目的是在低振幅和高振幅的时频瞬间之间提供更好的平衡。
使用PESQ[13]和STOI[16]对所提出的方法进行了评估。如第6节所示,与不使用预处理的相同配置相比,所提出的预处理方案可以获得0.04 PESQ和0.11 STOI的改善。在损失函数中提出的IAM加权因子可以达到0.13的PESQ和0.02的STOI改善。当预处理和损失函数一起使用时,与现有方法相比,该方法可以获得与现有方法相似的PESQ性能,并且具有更小的系统延迟和复杂度。
所提出的方法还进入了2021年DNS挑战赛[17]。在480点FFT(对应于16 kHz输入信号30ms)和160点帧移(对应于16 kHz输入信号对应10ms),系统总延迟为30ms+10ms=40ms,满足本次挑战的延迟要求。该模型具有3.393M个参数,756.868M个FLOP。在英特尔酷睿i7(2.6 GHz)CPU上的一帧推理时间为0.386毫秒。该方法在背景噪声MOS方面排名第2位,在整体MOS方面排名第6位。
2 信号模型
噪声混响混合信号$y$在时域通过以下公式建模:
$$y(t)=h(t)*x(t)+n(t)$$
其中$x(t)$是语音信号,$h(t)$是从说话者到麦克风的传递函数,*表示卷积,$n(t)$是噪声。该系统的目的是从$y(t)$估计$x(t)$,包括从捕获的信号中去除噪声和混响。
训练过程的概述如图1所示。先对带噪语音和纯净语音进行短时傅立叶变换(STFT),以获得时频域的幅值和相位信号。对纯净语音的幅值进行预处理,得到感知上最优的训练目标。输入噪声信号的幅度谱馈送到基于DNN的编解码器,以估计纯净语音的幅度谱。基于信号处理的后处理也被用来产生最终的幅值估计,将估计幅值与噪声相位相结合,使用短时傅立叶逆变换(ISTFT)形成时域输出。
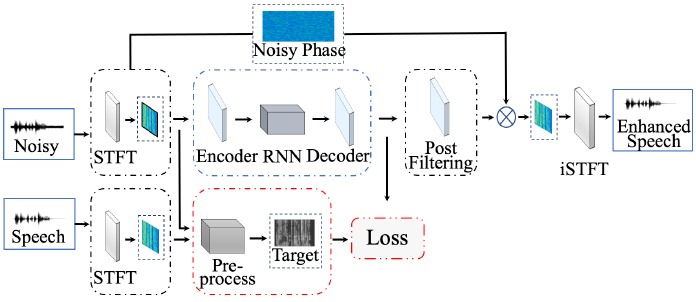
图1 拟议系统的架构
3 训练目标
将纯净语音复数谱图作为训练目标,可以实现完美的重构,而仅预测纯净语音的幅度谱被广泛应用于实时通信系统,以显著降低其复杂度。在此工作中,我们直接比较了不同训练目标在大信噪比范围内的PESQ分数。此外,还提出了一种预处理方法,以进一步提高训练目标的感知质量。
首先推导出三种常用掩模生成的训练目标
$$公式2:x_{IRM} =i \operatorname{STFT}(|Y| \cdot \frac{|X|}{|\mathrm{X}|+|\mathrm{N}|} \cdot \angle(Y))$$
$$公式3:x_{Wiener} =\operatorname{iSTFT}(|Y| \cdot \frac{X^{2}}{X^{2}+N^{2}} \cdot \angle(Y))$$
$$公式4:x_{IAM} =\operatorname{iSTFT}(|Y| * \frac{|X|}{|Y|} * \angle(Y))$$
其中$|·|$和$\angle (·)$表示复数谱的幅值和相位计算。
使用VCTK语音数据集[19]和稳定噪声,包括while、pink、babble、street等,针对信噪比(-10 ~ 25dB)和理想掩码条件生成2000个训练目标。PESQ结果如图2所示,其中错误条表示95%置信区间。如图所示,与IRM(蓝色)和Wiener-like mask(灰色)相比,IAM(绿色)获得了最高的PESQ分数。
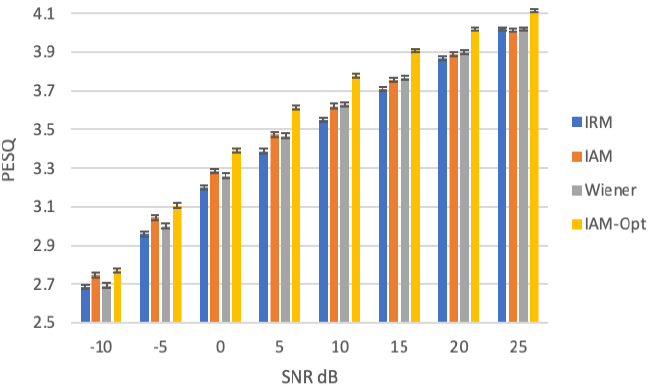
图2:不同训练目标之间的比较
此外,提出了一种掩码压缩方案,将IAM从标准设置中压缩出来,以显著提高IAM 训练目标的感知质量
$$公式5:x_{IAM \gamma}=iSTFT(|Y| *\frac{|X|}{|Y|})^\gamma * \angle(Y))$$
其中,$\gamma $表示压缩比,$\gamma=1$是IAM的标准设置。$\gamma $从0.2到1.4的不同选择下的实验结果如图3所示。

图3:不同压缩比的比较($\gamma $)
如图 3 所示,为每个$\gamma $选项生成了 2000 个使用(5)的 训练目标,以与使用 PESQ 的纯净参考进行比较。 误差条表示 95% 的置信区间。 与 ($\gamma $= 1.0) IAM 训练目标相比,$\gamma $= 0.8 实现了 0.116(平均)和超过 0.15(对于 5dB、10dB、15dB 和 20dB SNR 条件)的 PESQ 改进。
4 DNN模型
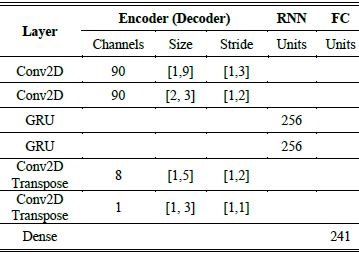
如图 1 所示,这项工作中的 DNN 模型基于卷积循环网络 (CRN) [20],该网络将循环神经网络 (RNN) 模块嵌套在基于卷积神经网络 (CNN) 的编码器-解码器结构中。在采用 480 点STFT(16kHz 输入为 30ms)和 160 点帧移(16kHz 输入为 10ms)后,STFT 域幅度表示$Y\in R^{F*T}$(F= 241,T= 2 帧)输入信号$L_c\in N(L_c=2)$输入卷积编码器以对时频域局部互连进行建模。最后一个卷积编码器层的特征图reshape成维度[batch, frame, frequency, channel] ,[batch, frame, frequency*channel]输入循环层,循环层的输出再reshape回去,以形成$L_d\in N(L_d=2)$卷积解码器的输入。最终的输出张量是通过具有 sigmoid 激活函数的前馈层使用最后一个卷积解码器层的输出产生的。
对于每个卷积层,采用了ReLU激活函数和Batch Norm。在卷积层的末端还采用了Dropout机制,以进一步防止过拟合。dropout参数设置为0.3。在卷积层之后,输出是一个张量$L\in R^{M*F'*T'}$,其中$M$是最后一个编码器层的输出特征映射的数量,$F'$和$T'$是剩余的频率和时间索引的数量。该递归网络由门递归单元(GRU)实现,以模拟输入信号的序列性质。将输出特征映射叠加到频率轴上后,GRU的输入是一个张量$H\in R^{(M·F')*T'}$。循环层的输出被重塑回$\tau \in R^{(M·F'')*T''}$,以形成卷积解码器的输入。超参数的详细信息如表1所示。
表1 卷积循环神经网络的设计
针对低信噪比和幅值时频区域,设计了一种新的IAM加权损失。对于每个时频瞬间,损失可以用:
$$L o s s=W_{I A M} *\left|\ln \left(X_{m a g}^{\prime}+1\right)-\ln \left(X_{m a g}+1\right)\right|$$
其中:
$$公式7:W_{I A M}=e^{\left(\frac{a}{b+I A M}\right)}$$
$$公式8:I A M=Y_{\text {mag }} *\left(\frac{X_{\text {mag }}}{Y_{\text {mag }}}\right)^{\gamma} * \angle(Y)$$
在此工作中,$\gamma $被设置为1,$a$被设置为2,$b$被设置为1。所提出的IAM权值旨在平衡语音占主导地位和噪声占主导地位时频实例的重要性,其中值越小的IAM在总损失中的权重越高。对数压缩部分的目的是减少低幅值和高幅值时频瞬间之间的水平差。如评价部分所述,利用所提出的损失可以提高噪声抑制性能。其中$X'_{mag}$为预测纯净振幅谱,$X_{mag}$为目标振幅谱,A为噪声振幅谱。$\angle (·)$表示复杂时频谱的幅值和相位计算。
5 后置滤波
为了进一步提高主观质量,采用包络后置过滤[18]对DNN估计的IAM ($IAM_{dnn}$)进行细化,得到最终的IAM ($IAM_{pf}$):
$$公式9:IAM_{pf}=\frac{(1+\tau) \cdot IAM_{dnn}}{(1+\frac{\tau \cdot IAM_{dnn}^2}{IAM_{sin}^2})}$$
其中
$$公式10:IAM_{\sin}=IAM_{dnn} \cdot \sin (\frac{\pi \cdot IAM_{dnn}}{2})$$
$t$被设置为0.02。最后估计的振幅(magnitude)是
$$公式11:X_{p f}^{\prime}=Y \cdot I A M_{p f}$$
6 实验和结果
6.1 数据集
实验的纯净语音数据集为DNS Challenge(INTERSPEECH 2021)纯净语音数据集,包含英语、中文、法语等多种语言。噪声数据为DNS Challenge(INTERSPEECH 2021)噪声集。 我们将训练数据与从 {-5, 0, 5, 10, 15, 20, 25, 30} dB 中随机选择的 SNR 合成。 还包括沉默、纯净语音和纯噪声样本。 为了进一步提高混响环境中的鲁棒性,噪声和目标信号与测量或模拟的房间脉冲响应进行卷积。 Varies EQ 滤波器也用于模拟各种麦克风的频率响应曲线。 为避免去混响引起的语音失真,采用 75ms 早期反射的语音作为训练目标。 音频信号的采样率为16kHz。
6.2 结果
首先,为了评估所提出的预处理方法和损失函数,将不同配置的模型进行如下比较。
- NoPP_MALE:未进行预处理的模型,具有平均绝对对数误差(MALE)损失函数。
- PP_MALE:带有预处理和MALE loss函数的模型。
- NoPP_WO-MALE:无预处理,且具有IAM加权优化MALE (WO-MALE)损失函数。
- PP_WO-MALE:模型预处理和WOMALE损失函数。
所有模型都用 500 小时的数据进行训练,并且还对 PP_WO-MALE 模型用 2000 小时的数据进行训练,以形成提交给 DNS 挑战赛 (INTERSPEECH 2021) 的模型。 短期客观清晰度(STOI)和语音质量感知评估(PESQ)被用作评估指标。 表 2 展示了 DNS Challenge (INTERSPEECH 2020) 综合测试集的结果。
表2:在INTERSPEECH DNS挑战综合测试集上得到PESQ和STOI结果
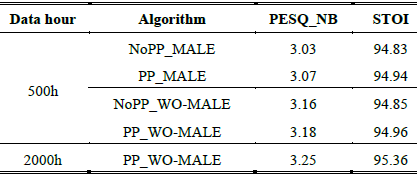
从表 2 可以看出,带有预处理的模型比没有预处理的模型可以获得更高的 PESQ 和 STOI 分数。 应该注意的是,PESQ 的改进小于第 3 节中讨论的 目标语音。这主要是由两个原因造成的。 首先,网络可能无法充分利用有预处理和没有预处理的 目标之间的差异。 其次,合成测试集的 SNR 分布与第 3 节中进行的实验不同。 还可以观察到,WO-MALE 模型可以实现比 MALE 条件更高的 PESQ 和 STOI 分数。 最后,所提出的 PP_WO-MALE 模型获得了最高的 PESQ 和 STOI 分数。 用 2000 小时数据集训练的 PP_WOMALE 进一步提高了 PESQ 和 STOI 分数。
图 4 中语谱图对比,其中纯净语音是在句子开头存在背景竞争说话者并且背景噪声恒定的情况下。 如图所示,提出的 PP_WO-MALE 可以在去除非目标说话人声音的同时抑制更稳定的背景噪声。
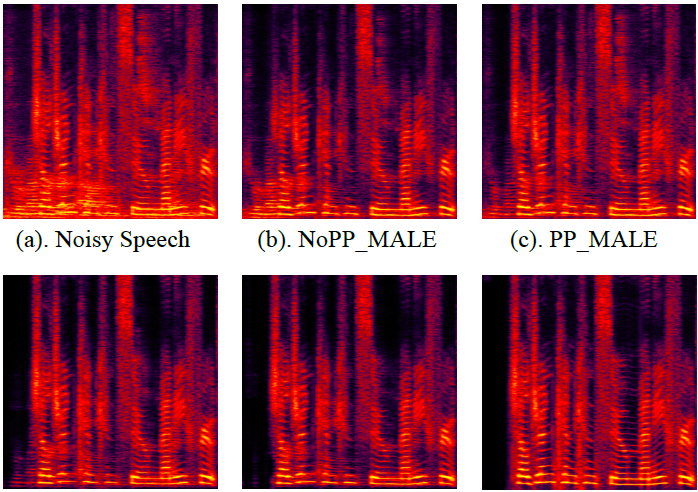
图4:语谱图结果对比
将此 2000 小时 PP_WO-MALE 模型与最先进的方法进行比较,包括使用相同测试集的去年 INTERSPEECH DNS 挑战赛中排名靠前的方法。 NSNet [10] 是 INTERSPEECH DNS 2020 Challenge 的官方基线方法。 DTLN [21] 是一种具有单帧输入、单帧输出方式的低复杂度模型,而 DCCRN [22] 是 INTERSPEECH DNS 2020 挑战赛主观听力测试中排名最高的方法。 FullSubNet [23] 是 ICASSP DNS 2021 挑战赛的顶级方法。
如表 3 中所列,与具有相同(40 毫秒)延迟的方法相比,所提出的方法可以实现 0.20 以上的 PESQ 改进。 并且比较 DCCRN 和 FullSubNet 都具有大约 50% 的延迟和更大的模型尺寸,所提出的低延迟和低复杂度方法仍然实现了具有竞争力的 PESQ 性能。
表3:DNS挑战(INTERSPEECH 2020)综合测试数据集上的PESQ和STOI结果

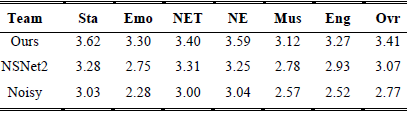
DNS挑战赛(INTERSPEECH2021)主办方提供了官方主观评价结果,如表4和表5所示。最后总结了P.808实时深噪声抑制轨道主观评价结果。表4(背景噪声MOS)和V(总体MOS)的缩写列出如下:静止(Sta),情绪语言(Emo),非英语音调(NET),非英语(NE),音乐乐器(Mus),英语(Eng),总体(Ovr)。虽然显著优于基线系统,但所提出的方法在背景噪声MOS结果中排名第二,在Overall MOS结果中排名第六(微软的排名在比赛中被忽略)。
表4 DNS挑战(INTERSPEECH2021)背景噪声MOS
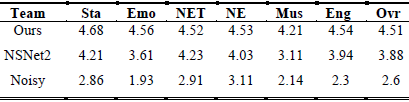
表5 DNS挑战(INTERSPEECH2021)整体MOS
7 复杂度
采用480点FFT(对应16kHz输入信号30ms)和160点步幅(对应16kHz输入信号10ms),总系统延迟为30ms + 10ms = 40ms,满足本次挑战的时延要求。 所提出的模型有 3.393M 参数,756.868M FLOPs。 Intel Core i7 (2.6GHz) CPU 上的一帧推理时间为 0.386ms。
8 结论
在这项研究中,提出了一种低延迟低复杂度的语音增强系统。 我们证明了带有预处理和新设计的 WO_MALE 损失函数的模型可以达到最佳性能。 我们还将性能与 DNS2020 中的一些最先进的方法进行了比较,所提出的系统以更少的系统延迟和复杂性实现了类似的 PESQ 性能。 在挑战组织者提供的 DNS 挑战赛(INTERSPEECH 2021)结果中,所提出的系统在背景噪声 MOS 成绩中获得第 2 名,在总体 MOS 成绩中获得第 6 名(本次比赛忽略了微软的排名)。
参考文献
[1] S. Boll, Suppression of acoustic noise in speech using spectral subtraction, IEEE Trans. Acoust. Speech Signal Process. , vol. 27, no. 2, pp. 113 120, Apr. 1979.
[2] N. Madhu, A. Spriet, S. Jansen, R. Koning, and J. Wouters, The Potential for Speech Intelligibility Improvement Using the Ideal Binary Mask and the Ideal Wiener Filter in Single Channel Noise Reduction Systems: Application to Auditory Prostheses, IEEE Trans. Audio Speech Lang. Process. , vol. 21, no. 1, pp. 63 72, Jan.
[3] Y. Luo and N. Mesgarani, Conv-TasNet: Surpassing Ideal Time Frequency Magnitude Masking for Speech Separation, IEEEACM Trans. Audio Speech Lang. Process. , vol. 27, no. 8, pp. 1256 1266, Aug. 2019
[4] R. Giri, U. Isik, and A. Krishnaswamy, Attention Wave-U-Net for Speech Enhancement, in 2019 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Oct. 2019, pp. 249 253
[5] O. Yilmaz and S. Rickard, Blind separation of speech mixtures via time-frequency masking, IEEE Trans. Signal Process. , vol. 52, no. 7, pp. 1830 1847, Jul. 2004
[6] Y. Wang, A. Narayanan, and D. Wang, On Training Targets for Supervised Speech Separation, IEEEACM Trans. Audio Speech Lang. Process. , vol. 22, no. 12, pp. 1849 1858, Dec. 2014
[7] T. Grzywalski and S. Drgas, Using Recurrences in Time and Frequency within U-net Architecture for Speech Enhancement, in ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), May 2019, pp. 6970 6974.
[8] D. S. Williamson and D. Wang, Time-Frequency Masking in the Complex Domain for Speech Dereverberation and Denoising, IEEEACM Trans. Audio Speech Lang. Process. , vol. 25, no. 7, pp. 1492 1501, Jul. 2017,
[9] D. Yin, C. Luo, Z. Xiong, and W. Zeng, PHASEN: A Phaseand- Harmonics-Aware Speech Enhancement Network, presented at the AAAI, Nov. 2019.
[10] C. K. A. Reddy et al., The INTERSPEECH 2020 Deep Noise Suppression Challenge: Datasets, Subjective Testing Framework, and Challenge Results, ArXiv200513981 Cs Eess, Oct. 2020, Accessed: Apr. 03, 2021.
[11] Deep Noise Suppression Challenge - INTERSPEECH 2020 - Microsoft Research. https://www.microsoft.com/enus/ research/academic-program/deep-noise-suppressionchallenge- interspeech-2020/#! results (accessed Mar. 26, 2021).
[12] H. Erdogan, J. R. Hershey, S. Watanabe, and J. L. Roux, Phasesensitive and recognition-boosted speech separation using deep recurrent neural networks, in 2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Apr. 2015, pp. 708 712
[13] ITU, P.862: Perceptual evaluation of speech quality (PESQ): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs. 2001.
[14] M. Parviainen, P. Pertilä, T. Virtanen, and P. Grosche, Time- Frequency Masking Strategies for Single-Channel Low-Latency Speech Enhancement Using Neural Networks, in 2018 16th International Workshop on Acoustic Signal Enhancement (IWAENC), Sep. 2018, pp. 51 55
[15] A. Narayanan and D. Wang, Ideal ratio mask estimation using deep neural networks for robust speech recognition, in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, May 2013, pp. 7092 7096
[16] C. H. Taal, R. C. Hendriks, R. Heusdens, and J. Jensen, An Algorithm for Intelligibility Prediction of Time Frequency Weighted Noisy Speech, IEEE Trans. Audio Speech Lang. Process. , vol. 19, no. 7, pp. 2125 2136, Sep. 2011
[17] C. K. A. Reddy et al., Interspeech 2021 Deep Noise Suppression Challenge. 2021.
[18] J.-M. Valin, U. Isik, N. Phansalkar, R. Giri, K. Helwani, and A. Krishnaswamy, A Perceptually-Motivated Approach for Low- Complexity, Real-Time Enhancement of Fullband Speech, in Proc. Interspeech 2020, 2020, pp. 2482 2486
[19] J. Yamagishi, C. Veaux, and K. MacDonald, CSTR VCTK Corpus: English Multi-speaker Corpus for CSTR Voice Cloning Toolkit (version 0.92), Nov. 2019,
[20] K. Tan and D. Wang, A Convolutional Recurrent Neural Network for Real-Time Speech Enhancement, in Proc. Interspeech 2018, 2018, pp. 3229 3233
[21] N. L. Westhausen and B. T. Meyer, Dual-Signal Transformation LSTM Network for Real-Time Noise Suppression, in Proc. Interspeech 2020, 2020
[22] Y. Hu et al., DCCRN: Deep Complex Convolution Recurrent Network for Phase-Aware Speech Enhancement, in Proc. Interspeech 2020, 2020
[23] X. Hao, X. Su, R. Horaud, and X. Li, FullSubNet: A Full-Band and Sub-Band Fusion Model for Real-Time Single-Channel Speech Enhancement, in Proc. ICASSP 2021, 2021

 浙公网安备 33010602011771号
浙公网安备 33010602011771号