论文翻译:Conv-TasNet: Surpassing Ideal Time–Frequency Magnitude Masking for Speech Separation
我醉了呀,当我花一天翻译完后,发现已经网上已经有现成的了,而且翻译的比我好,哎,造孽呀,但是他写的是论文笔记,而我是纯翻译,能给读者更多的思想和理解空间,并且还有参考文献,也不错哈,反正翻译是写给自己看的
文章方向:语音分离,
论文地址:Conv-TasNet:超越理想的语音分离时频幅度掩蔽
博客地址:https://www.cnblogs.com/LXP-Never/p/14769751.html
论文代码:https://github.com/naplab/Conv-TasNet | https://github.com/JusperLee/Conv-TasNet | https://github.com/kaituoxu/Conv-TasNet
摘要
单通道、与说话人无关的语音分离方法近年来取得了很大的进展。然而,这些方法的准确性、延迟和计算代价仍然不够。之前的大部分方法都是通过混合信号的时频表示来解决分离问题,这存在以下几个缺点,比如信号相位和幅度的解耦,语音分离时频表示的次优性,以及计算谱图时的长时间延迟。为了解决这些缺点,我们提出了一种全卷积时域音频分离网络(Conv-TasNet),这是一种端到端时域语音分离的深度学习框架。Conv-TasNet使用一个线性编码器来生成语音波形,优化的语音波形可以分离单独的说话人声音。说话人声音分离是通过对编码器输出应用一组加权函数(mask)来实现的。然后使用线性解码器将修改的编码器表示反转回波形。使用由堆叠的一维扩张卷积块组成的时间卷积网络计算mask,这使得网络可以对语音信号的长期依赖性进行建模,同时保持较小的模型尺寸。本文所提出的Conv-TasNet系统在分离两个和三个说话人混合语音时显着优于先前的时频掩蔽方法。此外,从客观失真测量和听者主观质量评价来看,Conv-TasNet在双说话人语音分离中优于几种理想的时频幅度掩模。最后,Conv-TasNet具有更小的模型尺寸和更短的最小延迟,使其成为离线和实时语音分离应用的合适解决方案。因此,本研究为实现真实语音处理技术的语音分离系统迈出了重要的一步。
索引术语:源分离,单通道,时域,深度学习,实时
1 引言
在真实的声学环境中,稳健的语音处理通常需要自动语音分离。由于这个研究课题对语音处理技术的重要性,已经有许多方法被提出来解决这个问题。然而,语音分离的准确性,特别是对新说话者,仍然不够。
大多数之前的语音分离方法都是在基于混合信号的时频(T-F,或谱图)表示,这些时频表示是使用短时傅立叶变换(STFT)从波形中估计出来的。 在T-F域的语音分离方法旨在从混合频谱中近似出单个源的干净频谱。可以通过使用非线性回归技术直接将混合频谱中的每个源的频谱近似表示出来,其中将干净频谱作为训练目标[2]-[4]。或者,可以对每个源估计一个加权函数(也就是掩码,或称掩膜,mask)来乘以混合频谱中的每个T-F bin来恢复单个源。近年来,深度学习通过提高掩码估计[5]-[12]的精度,大大提高了时频mask方法的性能。在直接法和mask估计法中,每个声源的波形都是利用估计的每个声源的幅值谱,再加上混合语音的相位或修正相位 经过短时傅里叶反变换(iSTFT)来计算的。
虽然时频掩蔽仍然是最常用的语音分离方法,但该方法存在一些缺点。
- 第一:短时傅里叶变换是一种通用的信号变换,对于语音分离未必是最优的。
- 第二:精确重建纯净声源的相位是一个非常重要的问题,错误的相位估计会给重建音频的精度带来一个上界。这一问题很明显,因为即使将理想的纯净幅度谱应用于混合物,源的不完全重建精度。虽然相位重建方法可以缓解[11],[13],[14]的问题,但该方法的性能仍然不是最优的。
- 第三:成功地从时频表示中分离源信号,需要对混合信号进行高分辨率的频率分解,这需要一个较长的时间窗口来计算短时傅里叶变换。这一措施会增加系统的最小延迟,这限制了它在实时、低延迟应用程序(如电信和可听设备)中的适用性。例如,在大多数语音分离系统中,STFT的窗口长度至少为32 ms[5],[7],[8],而在音乐分离应用中,STFT的窗口长度甚至更大,这需要更高分辨率的频谱(高于90 ms)[15],[16]。
由于这些问题都是在时频域内表述分离问题时产生的,因此一个合理的方法是通过直接在时域内表述分离来避免对声音的幅度和相位进行解耦。以往的研究通过独立分量分析(ICA)[17]和时域非负矩阵分解(NMF)[18]等方法探索了时域语音分离的可行性。然而,这些系统的性能无法与时频方法的性能相比,特别是在扩展和推广到大数据的能力方面。另一方面,一些最近的研究探索了深度学习的时域音频分离[19]-[21]。所有这些系统的共同想法是用数据驱动的表示来取代特征提取的STFT步骤,该表示与端到端训练范式共同优化。这些表示和它们的逆变换设计来显式地代替STFT和iSTFT。或者,特征提取和分离可以隐式地合并到网络架构中,例如使用端到端卷积神经网络(CNN)[22],[23]。这些方法在如何从波形中提取特征和分离模块的设计方面是不同的。[19]的前端采用离散余弦变换(DCT)驱动的卷积编码器。然后通过将编码器特征传递给多层感知器(MLP)来执行分离。波形的重建是通过反向编码器操作实现的。在[20]中,分离被合并到U-Net 1-D CNN架构[24]中,而没有明确地将输入转换为类似光频谱的表示。然而,这些方法在大型语音语料库(如[25]中引入的基准)上的性能还没有经过测试。另一种方法是时域音频分离网络(TasNet)[21],[26]。在TasNet中,混合波形采用卷积编码器-解码器架构建模,该架构包括一个对其输出具有非负约束的编码器和一个用于将编码器输出反化为声音波形的线性解码器。这种框架类似于ICA方法,当使用非负混合矩阵[27]时,半非负矩阵分解方法(semi-NMF)[28],其中基信号是解码器的参数。TasNet中的分离步骤是通过为每个时间步的编码器输出找到每个源的加权函数(类似时间频率掩藏)来完成的。研究表明,TasNet已经取得了比以往各种T-F域系统更好或更接近的性能,显示了它的有效性和潜力。
虽然TasNet在因果和非因果实现中都优于以前的时频语音分离方法,但在原始TasNet中使用深度长短期记忆(LSTM)网络作为分离模块,极大地限制了其适用性。首先,在编码器中选择较小的内核大小(即语音帧长),增加了编码器输出的长度,这使得LSTM的训练难以管理。其次,深度LSTM网络中大量的参数显著增加了其计算成本,限制了其在可穿戴听力设备等低资源、低功耗平台上的适用性。我们将在本文中说明的第三个问题是由LSTM网络的长时间依赖性引起的,这常常导致分离精度不一致,例如,当改变混合的起始点时。为了减轻以前TasNet的局限性,我们提出了全卷积TasNet (Convc -TasNet),该TasNet在处理的所有阶段都只使用卷积层。由于时序卷积网络(TCN)模型[29]-[31]的成功,Conv-TasNet使用堆叠的膨胀一维卷积块来替代深度LSTM网络的分离步骤。卷积的使用允许对连续帧或片段进行并行处理,从而大大加快分离过程,也显著减少了模型的大小。为了进一步减少参数的数量和计算量,我们用深度可分离卷积[32],[33]代替原有的卷积运算。我们表明,通过这些修改,在因果和非因果实现中,Conv-TasNet比以前的LSTM-TasNet显著提高了分离精度。此外,无论是在信号失真比(SDR)还是主观评价(mean opinion score, MOS)指标上,Conv-TasNet的分离精度都超过了理想时频幅掩模(包括理想二进制掩模(IBM[34])、理想比例掩模(IRM[35],[36])和类Winener滤波掩模(WFM[37])的性能。
本文的其余部分组织如下。我们在第二节介绍了所提出的Conv-TasNet,在第三节描述了实验过程,在第四节展示了实验结果和分析。
2 卷积时域音频分离网络
全卷积时域音频分离网络(Conv-TasNet)由三个处理阶段组成,如图1(A)所示:编码器、分离和解码器。首先,利用编码器模块将混合波形的短片段转换为中间特征空间中的相应表示。然后,使用该表示用于在每个时间步中估计每个源的乘法函数(mask)。最后,解码器模块通过转换掩蔽之后的编码器特征来重建源波形。我们将在本节中详细描述每个阶段。
A 时域语音分离
单通道语音分离的问题可以通过从给定混合的离散波形$x(t)\in R^{1*T}$中估计C个源信号$s_1(t),...,s_c(t)\in R^{1*T}$来公式化:
$$公式1:x(t)=\sum_{i=1}^Cs_i(t)$$
在时域音频分离中,我们的目标是从$x(t)$中直接估计$s_i(t),\ i=1,...,C$。
B 卷积编码器-解码器
输入混合声音可以被分成长度为$L$的重叠帧,由$x_k\in R^{1*L}$表示,其中$k=1,...,\hat{T}$表示帧索引,$T$表示输入中帧的总数。通过一维卷积运算,$x_k$被转换成二维表示$w \in R^{1*N}$,可以使用矩阵乘法表示(从现在开始去掉索引$k$):
$$公式2:w=H(xU)$$
其中$U\in R^{N*L}$包含N个向量(编码器基函数),每个向量长度为$L$,$H(·)$是可选的激活函数。在[21][26]中,$H(·)$是ReLU,用来确保输出非负。解码器使用一维转置卷积运算生成重构波形,该运算可以被重新表述为另一个矩阵乘法:
$$公式3:\hat{x}=wV$$
其中,$\hat{x}\in R^{1*L}$为$x$的重构,$V \in R^{N*L}$中的行是解码器基函数,每一行的长度为$L$。将重构的重叠部分累加在一起生成最终波形。
尽管我们将编码器/解码器操作重新表述为矩阵乘法,但使用术语“卷积自动编码器”,因为在实际模型实现中,卷积和转置卷积层可以更容易地处理段之间的重叠,从而实现更快的训练和更好的收敛(对于我们的Pytorch实现,这可能是由于全连接层和一维(转置)卷积层中的不同auto-grad机制)。
C 估计分离掩模
每一帧的分离是通过估计C个掩码来实现的$m_i \in R^{1*n},\ i=1,...,C$,其中$C$是混合中的说话人数量。掩模向量$m_i$的约束条件是$m_i \in [0,1]$。然后将对应的掩模$m_i$乘以混合表示$w$,得到每个声源的表示$d_i \in R^{1*N}$:
$$公式4:d_i=w\odot m_i$$
其中$\odot $表示逐元素乘法。每个声源$\hat{s}_i,\ i=1,...,C$的波形由解码器重建:
$$公式5:\hat{s}_i=d_iV$$
基于编码器—解码器体系结构可以完美地重构输入的混合信号这一假设,有些文献应用了[21],[26]中的单位求和约束$\sum_{i=1}^C m_i= 1$。在第IV-A节中,我们将考察放松这种统一求和约束对分离精度的影响。
D 卷积分离模块
受时间卷积网络(TCN)[29]–[31]的启发,我们提出了一个全卷积分离模块,它由堆叠的一维扩张卷积块组成,如图1(B)所示。TCN在各种序列建模任务中替代了RNNs。TCN中的每一层都由具有递增扩张因子的一维卷积块组成。扩张因子以指数方式增加,以确保足够大的时间上下文感受野,从而利用语音信号的长距离相关性,如图1(B)中不同颜色所示。在Conv-TasNet中,$M$个扩张因子分别为$1,2,4,...,2^{M-1}$的卷积块重复$R$次。每个块的输入都进行了相应地零填充,以确保输出长度与输入长度相同。TCN的输出被传递到一个核大小为1的卷积块(1×1 Conv块,也称为逐点卷积),用于估计掩码。1×1 Conv模块和一个激活函数一起估计$C$个目标源的$C$掩码向量。
图1(C)展示了每个一维卷积块的设计。一维卷积块的设计遵循[38],其中应用了residual path和 skip-connection path:一个块的residual path用作下一个块的输入,所有块的 skip-connection path相加,作为TCN的输出。为了进一步减少参数的数量,在每个卷积块中使用depthwise separable Convolution(深度可分离卷积)($S-Conv(·)$)来代替标准卷积。深度可分离卷积(也称为可分离卷积)已被证明在图像处理任务[32]、[33]和神经机器翻译任务[39]中是有效的。深度可分离卷积算子将标准卷积运算分解为两个连续运算,深度卷积($D-Conv(·)$)后接点卷积($1×1\ Conv(·)$):
$$公式6:D-\operatorname{Conv}(\mathbf{Y}, \mathbf{K})=\operatorname{concat}\left(\mathbf{y}_{j} \circledast \mathbf{k}_{j}\right), j=1, \ldots, N$$
$$公式7:S-\operatorname{con} v(\mathbf{Y}, \mathbf{K}, \mathbf{L})=D-\operatorname{Conv}(\mathbf{Y}, \mathbf{K}) \circledast \mathbf{L}$$
其中$Y \in R^{G*M}$是$S-Conv(·)$的输入,$K \in R^{G*P}$是大小为$P$的卷积核,$y_j \in R^{1*M}$和$k_j \in R^{1*P}$分别是矩阵$Y$和$K$的行,$L \in R^{G*H*1}$是大小为1的卷积核,和$\circledast$表示卷积运算。换言之,D-Conv(·)运算将输入$Y$的每一行与矩阵$K$的对应行和1× 1−Conv块线性变换特征空间。与核大小为$\hat{K} \in R^{G*H*P}$的标准卷积相比,深度可分离卷积只包含$G*P+G*H$个参数,当$H>>P$时,模型尺寸减小了$\frac{H*P}{H+P}\approx P$的因子。
在第一个1×1 Conv和D-Conv块之后分别加入激活函数和归一化操作。激活函数使用是参数校正线性单位(PReLU) [40]:
$$公式8:P R e L U(x)=\left\{\begin{array}{ll}
x, & \text { if } x \geq 0 \\
\alpha x, & \text { otherwise }
\end{array}\right.$$
其中$\alpha \in R$是控制整流器负斜率的可训练标量。网络中归一化方法的选择取决于因果关系要求。对于非因果配置,我们根据经验发现全局层归一化(gLN)优于所有其他归一化方法。在gLN中,特征在通道和时间维度上都被归一化:
$$公式9:g L N(\mathbf{F})=\frac{\mathbf{F}-E[\mathbf{F}]}{\sqrt{\operatorname{Var}[\mathbf{F}]+\epsilon}} \odot \gamma+\beta$$
$$公式10:E[\mathbf{F}]=\frac{1}{N T} \sum_{N T} \mathbf{F}$$
$$公式11:\operatorname{Var}[\mathbf{F}]=\frac{1}{N T} \sum_{N T}(\mathbf{F}-E[\mathbf{F}])^{2}$$
其中$f_k \in R^{N*1}$是整个特征$F$的第k帧,$f_{t\leq k} \in R^{N*k}$对应于$k$帧的特征$[f_1,…,f_k]$,并且$\gamma ,\beta \in R^{N*1}$是可训练的参数。为了确保分离模块对于输入的缩放不敏感,先将选择的归一化方法应用到编码器的输出$w$上,然后再将该结果馈送到分离模块。
在分离模块的开头,添加了一个线性1×1 Conv块作为瓶颈层。 该块决定了后续卷积块的输入路径和剩余路径中的通道数。 例如,如果线性瓶颈层具有B通道,则对于具有H通道且内核大小为P的一维卷积块,第一个1×1-Conv块和第一个D-Conv块中的内核大小应为 分别为$O \in R^{B*H*1}$和$K \in R^{H*P} $,剩余路径中的内核大小应为$L_{Rs} \in R^{H*B*1}$。跳过连接路径中的输出通道数可以与$B$不同,我们将该路径中的内核大小表示为$L_{Sc}\in R^{H*Sc*1}$。
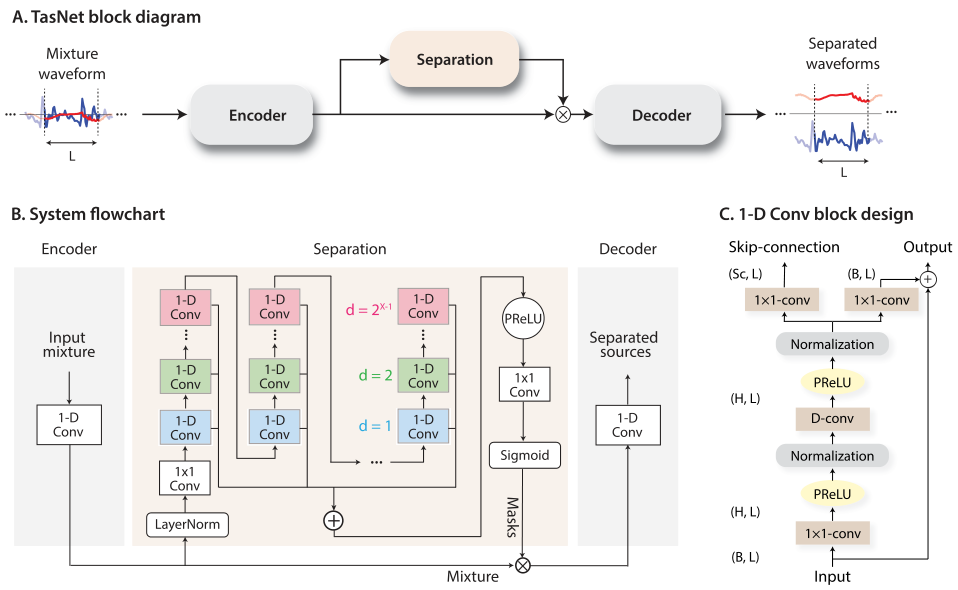
图1.(A)TasNet系统的框图。 编码器将混合语音波形的一部分映射为高维表示,分离模块为每个目标语音源计算掩码。 解码器从被掩盖的特征中重建源波形。
(B)我们提出系统的流程图。 一维卷积自动编码器对波形建模,时间卷积网络(TCN)分离模块根据编码器输出估算掩码。 TCN中的一维卷积块中的不同颜色表示不同的扩张因子。
(C)一维卷积块的设计。 每个块由一个1×1-Conv和一个深度卷积(D-Conv)组成,在每个两个卷积运算之间添加了激活函数和归一化。 两个线性1×1-Conv块分别用剩余路径和跳过连接路径。
3 实验程序
A 数据集
我们使用WSJ0-2mix和WSJ03mix数据集评估了我们的系统在两人和三人语音分离问题上的性能[25]。从数据集的si_tr_s中的说话人中生成30个小时的训练数据和10个小时的验证数据。通过从“华尔街日报”数据集(WSJ0)中的不同说话人中随机选择语音并以介于-5 dB和5 dB之间的随机信噪比(SNR)进行混合来生成混合语音。 以相同的方式生成5小时的测试集, 所有波形均重采样到8 kHz。创建数据集的脚本可以在[42]中找到。
B 实验配置
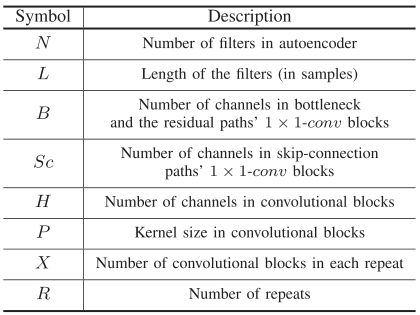
这些网络在4秒的帧长上训练了100个epoch。初始学习速率设置为1e-3。如果连续三个epoch验证集的准确性没有提高,学习率将减半。adam[43]被用作优化器。卷积自动编码器中使用50%的步长(即连续帧之间50%的重叠)。训练期间应用最大L2范数为5的渐变裁剪。。网络的超参数如表1所示。Conv-TasNet网络模型的Pytorch实现可在链接中找到。
表1:网络的超参数
C 训练目标
训练端到端系统的目标是最大化尺度不变的源噪声比(SI-SNR),它通常被用作源分离的评估指标,取代标准的源失真比(SDR) [5],[9],[44]。信噪比定义为:
$$公式15:\left\{\begin{array}{l}
\mathbf{s}_{\text {target }}:=\frac{\langle\hat{\mathbf{s}}, \mathbf{s}\rangle \mathbf{s}}{\|\mathbf{s}\|^{2}} \\
\mathbf{e}_{\text {noise }}:=\hat{\mathbf{s}}-\mathbf{s}_{\text {target }} \\
\text { SI-SNR }:=10 \log _{10} \frac{\| \mathbf{s}_{\text {target } \|^{2}}}{\left\|\mathbf{e}_{\text {noise }}\right\|^{2}}
\end{array}\right.$$
其中$\hat{s} \in R^{1*T}$和$s \in R^{1*T}$分别是估计的和原始的干净源,并$||s||^2=<s,s>$表示信号功率。通过在计算之前将$\hat{s}$和$s$归一化为零均值来确保尺度不变性。训练期间应用话语级置换不变训练(Utterance-level permutation invariant training,uPIT)来解决源置换问题[7]。
D 评估指标
我们将尺度不变信噪比改善(scale-invariant signal-to-noise ratio improvement,SI-SNRi)和信号失真比改善(signal-to-distortion ratio improvement, SDRi)作为分离精度的客观衡量标准。SI-SNR在等式15中定义。表3至表5中报告的改进表明了原始混合物的附加值。除了失真度量,我们还使用主观质量的感知评估(PESQ[45])和平均意见得分(MOS[46])来评估分离混合物的质量,方法是让40名正常听力受试者对分离混合物的质量进行评分。纽约市哥伦比亚大学的当地机构审查委员会批准了所有人体测试程序。
E 与理想时频掩码的比较
遵循[5]、[7]、[9]中的常见配置,使用窗口大小为32毫秒、帧移为8毫秒的汉宁窗STFT来计算大量时间-频率掩码。理想掩码包括理想二进制掩码(IBM)、理想比率掩码(IRM)和类似维纳滤波器的掩码(WFM),它们对源$i$的定义如下:
$$公式16:I B M_{i}(f, t)=\left\{\begin{array}{l}
1,\left|\mathcal{S}_{i}(f, t)\right|>\left|\mathcal{S}_{j \neq i}(f, t)\right| \\
0, \text { otherwise }
\end{array}\right.$$:
$$公式17:\operatorname{IRM}_{i}(f, t)=\frac{\left|\mathcal{S}_{i}(f, t)\right|}{\sum_{j=1}^{C}\left|\mathcal{S}_{j}(f, t)\right|}$$
$$公式18:W F M_{i}(f, t)=\frac{\left|\mathcal{S}_{i}(f, t)\right|^{2}}{\sum_{j=1}^{C}\left|\mathcal{S}_{j}(f, t)\right|^{2}}$$
其中$S_i(f,t)\in C^{F*T}$是纯净源$i=1,...,C$的复值频谱。
4 结果
图2可视化了Conv-TasNet的所有内部变量,其中包含两个重叠的说话人(以红色和蓝色表示)的一种示例混合声音。编码器和解码器的基函数按照使用无加权对群法与算术平均值(UPGMA)方法发现的基函数的欧几里得距离的相似性进行排序[47]。基函数显示了出频率和相位调谐的多样性。根据每个说话人在每个时间点在相应基准输出处的功率,对编码器的表示进行着色,这说明了编码器表示的稀疏性。如图2所示,两个说话人的估计掩码与它们的编码器表示非常相似,这可以抑制与干扰说话人相对应的编码器输出,并提取每个掩码中的目标说话人。线性解码器估计两个说话人的分离波形,其基函数如图2所示。分离的波形显示在右侧。

图2 编码器和解码器基本功能、编码器表示和两个说话人混合样本的源屏蔽的可视化。说话人以红色和蓝色显示。编码器表示根据每个基本功能和时间点上每个说话人的功率进行着色。基函数根据它们的欧几里德相似性进行排序,并且在频率和相位调谐方面表现出多样性。
A 编码器输出的非消极性
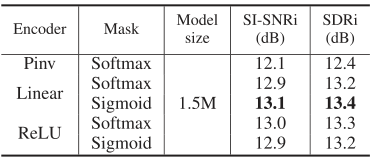
使用整流线性非线性(ReLU)函数在[21],[26]中强制了编码器输出的非负性。该约束基于这样的假设:仅当可以用基函数的非负组合表示混合波形和说话人波形时,才对编码器输出进行屏蔽操作,因为无边界的编码器表示可能会导致无边界的屏蔽。但是,通过消除非线性函数H,可以做出另一个假设:对于混合物的无界但高度不完全表示,仍然可以找到一组非负掩码来重构干净的源。在这种情况下,表示的不完整至关重要。如果对于混合物以及对于光源仅存在唯一的重量特征,则不能保证掩码的非负性。还要注意,在两个假设中,我们都没有对编码器和解码器基函数U和V之间的关系施加任何约束,这意味着它们没有被迫完美地重构混合信号。明确确保自动编码器属性的一种方法是通过选择V作为U的伪逆(即最小二乘重构)。编码器/解码器设计的选择会影响掩码估计:对于自动编码器,必须满足单位求和约束;否则,不严格要求单位求和约束。为了说明这一点,我们比较了五种不同的编码器-解码器配置:
1)具有伪逆(Pinv)作为解码器的线性编码器,即$w=x(V^TV)^{-1}V^T$和$\hat{x}=wV$,具有用于掩码估计的Softmax函数。
2)线性编码器和解码器,其中$w = xU$和$\hat{x}= wV$,具有Softmax或Sigmoid函数,用于掩码估计。
3)具有ReLU激活功能的编码器和线性解码器,其中$w = ReLU(xU)$和$\hat{x}= wV$,具有Softmax或Sigmoid函数用于掩码估计。
表3中不同配置的分离精度表明,伪逆自动编码器导致最差的性能,表明显式自动编码器配置不一定提高该框架中的分离分数。所有其他配置的性能相当。因为具有Sigmoid功能的线性编码器和解码器获得了比其他方法稍好的精度,所以我们在以下所有实验中使用了这种配置。
表3 不同系统配置的分离分数
B 优化网络参数
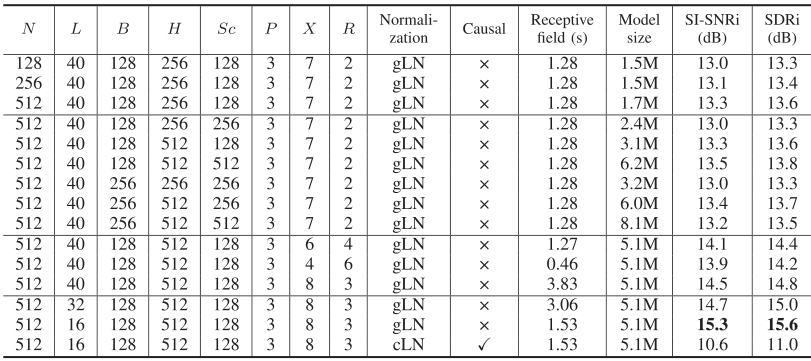
我们根据不同的网络参数,评估了Conv-TasNet在两个说话人分离任务上的性能。 表2显示了具有不同参数的系统的性能,从中可以得出以下结论:
- i)编码器/解码器:增加编码器/解码器中基本信号的数量会增加基本信号的不完全性并提高性能。
- ii)一维卷积块中的超参数:可能的配置由小瓶颈B和卷积块H中的大量通道组成。这与[48]中的观察结果相符,其中发现卷积块和瓶颈H / B之比最好在5附近。增加跳过连接块中的通道数可改善性能,同时极大地增加模型尺寸。因此,我们选择了一个小的跳过连接块作为性能和模型大小之间的折衷方案。
- iii)一维卷积块的数量:当接收场相同时,更深的网络可能会导致更好的性能,这可能是由于模型容量增加了。
- iv)接收场的大小:增加接收场的大小会导致更好的性能,这表明对语音信号中的时间相关性进行建模的重要性。
- v)每个段的长度:较短的段长度始终可以提高性能。 请注意,最佳系统使用的滤波器长度仅为2 ms$(\frac{L}{f_s}=\frac{16}{8000}=0.002s)$,由于编码器中的时间步长很大,因此很难训练具有相同L的深LSTM网络 输出。
- vi)因果关系:使用因果配置会导致性能显着下降。 该下降可能是由于因果卷积和/或层归一化操作引起的。
表2:不同配置在Conv-TasNet中的效果
C Conv-TasNet与以往方法的比较
我们比较了Conv-TasNet与以前使用软件无线电接口和软件无线电接口的方法的分离精度。表4比较了Conv-TasNet和其他先进方法在同一个WSJ0-2mix数据集上的性能。对于所有系统,我们列出了文献中报道的最佳结果。不同方法中的参数数量基于我们的实现,除了作者提供的[12]。表中缺失的值是因为研究中没有报告这些数字,或者因为结果是用不同的STFT配置计算的。[26]中的前一个TasNet用(B)LSTM-TasNet表示。虽然BLSTMTasNet的性能已经超过了IRM和IBM,但与所有以前的方法相比,非因果的Conv-TasNet以显著更小的模型大小,极大地提高了所有三种理想T-F掩码的性能。
表4:与WSJ0-2MIX数据的其他方法的比较
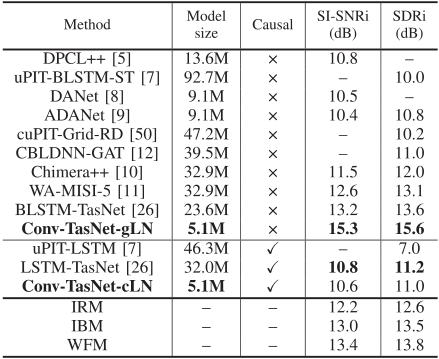
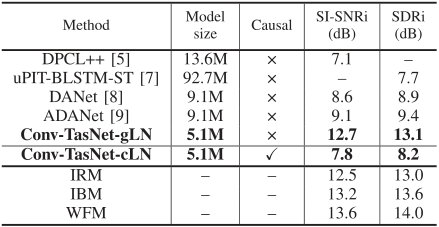
表5比较了Conv-TasNet与其他系统在三人语音分离任务中的性能,该任务涉及WSJ0-3mix数据集。在软件无线电领域,非因果Conv-TasNet系统明显优于以前所有基于STFT的系统。虽然没有关于三说话人分离因果算法的先验结果,但因果Conv-TasNet甚至显著优于其他两个基于非因果短时傅立叶变换的系统[5],[7]。在线提供了两个和三个说话人混合的Conv-TasNet因果和非因果实现的分离音频示例[49]。
表5:与WSJ0-3MIX数据的其他系统比较
D Conv-TasNet主客观质量评价
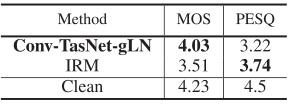
除了特别提款权和信噪比,我们还评估了分离语音的主观和客观质量,并与三种理想的时频幅度掩码进行了比较。表六显示了Conv-TsaNet和IRM、IBM和WFM的PESQ得分,其中IRM的WSJ0-2mix和WSJ0-3mix数据集得分最高。然而,由于PESQ的目的是预测语音的主观质量,因此人类质量评估可以被认为是基本事实。因此,我们进行了一项心理物理学实验,在该实验中,我们要求40名正常听力受试者听并评价分离出的语音的质量。由于人类心理物理学实验的实际局限性,我们将Conv-TasNet的主观比较局限于三种理想面罩中PESQ评分最高的理想比率面罩(IRM)(表6)。我们从双说话人测试集(WSJ0-2mix)中随机选择了25种双说话人混合声音。我们通过确保所选的25个样本的IRM和Conv-TasNet分离声音的平均PESQ分数等于整个测试集的平均PESQ分数来避免可能的选择偏差(表六和表七的比较)。每个话语的长度被限制在整个测试集平均值的0.5标准偏差之内。受试者被要求对干净的话语、IRM分离的话语和Conv-TasNet分离的话语的质量进行评分,评分范围为1到5 (1:差,2:差,3:一般,4:好,5:优秀)。首先给出干净的话语作为最高可能得分(即5)的参考。然后,干净的、IRM的和Conv-TasNet的样本以随机顺序呈现给受试者。然后对40名受试者的25个话语的平均意见得分进行平均。
表6:PESQ在整个WSJ0-2MIX和WSJ0-3MIX测试集上的理想T-F蒙版和Conv-Tasnet的分数
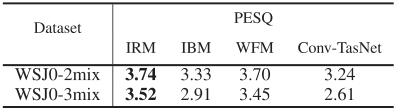
图3和表7显示了人的主观质量测试的结果,其中Conv-TsaNet的金属氧化物半导体明显高于IRM的金属氧化物半导体(p < 1e-16,t-test)。此外,如图3(C)所示,在25个测试话语的大部分中,Conv-TasNet优于IRM的主观质量是一致的。这一观察结果表明,对于Conv-塔斯克网络分离的话语,佩斯克一直低估了最大似然比,这可能是由于佩斯克依赖于语音的幅度频谱[45],这可能会产生较低的时域方法的分数。
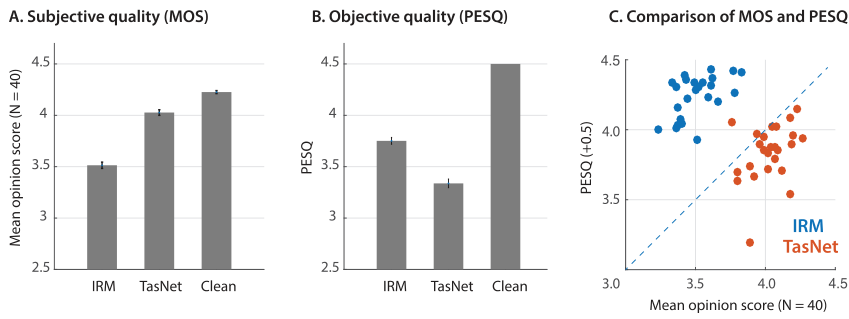
图3. WSJ0-2mix中分离话语的主观和客观质量评估。 (A)IRM,Conv-TasNet和纯净言语的平均意见得分(MOS,N = 40)。 Conv-TasNet明显优于IRM(p <1e − 16,t检验)。 (B)与Conv-TasNet相比,IRM的PESQ得分更高(p <1e-16,t检验)。 误差线表示单个言语的标准误差(STE)(C)MOS对PESQ。 每个点表示一个混合语音,使用IRM(蓝色)或Conv-TasNet(红色)分隔。 Conv-TasNet的几乎所有话语的主观评分都高于其相应的PESQ分数。
表7:平均意见分数(MOS,N = 40)和PESQ对于来自WSJ0-2MIX测试集的25个选定的话语
E 处理速度比较
表8比较了LSTM-TasNet和因果Conv-TasNet的处理速度。速度被评估为系统分离混合物中每帧的平均处理时间,我们称之为每帧时间(TPF)。TPF确定系统是否可以实时实现,这需要小于帧长度的TPF。
表8:因果LSTM-TASNet和CONV-TASNet的处理时间。速度是EV Alua TED作为SECTA SECTA A帧所需的平均时间(每帧的时间,TPF)
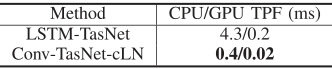
对于CPU配置,我们在英特尔酷睿i7-5820K CPU上测试了一个处理器的系统。对于GPU配置,我们将系统和数据预加载到Nvidia Titan Xp GPU中。具有中央处理器配置的LSTM-TasNet具有接近其帧长度(5毫秒)的TPF,这在只有较慢的中央处理器可用的应用中仅是勉强可接受的。此外,在LSTM-TsaNet中的处理是顺序完成的,这意味着每个时间帧的处理必须等待前一个时间帧的完成,进一步增加了整个话语的总处理时间。由于Conv-TsaNet解耦了连续帧的处理,后续帧的处理不必等到当前帧完成,并允许并行计算的可能性。这个过程导致TPF比我们的中央处理器配置中的帧长度(2毫秒)小5倍。因此,即使使用速度较慢的CPU,Conv-TasNet仍然可以执行实时分离。
F LSTM-Tasnet对混合物起始点的敏感性
与语言处理任务不同,在语言处理任务中,句子决定了起始词,因此很难为语音分离和增强任务定义一个通用的起始样本或帧。因此,一个健壮的音频处理系统应该对混音的起点不敏感。然而,我们根据经验发现,因果LSTM-TasNet的性能对混合物的确切起点非常敏感,这意味着将输入混合物移动几个样本可能会对分离精度产生不利影响。我们通过评估WSJ0-2mix测试集中每种混合物在不同输入样本移位情况下的分离精度,系统地检验了LSTM-TasNet和因果Conv-TasNet对混合物起始点的稳健性。s样品的移动对应于在样品s而不是第一个样品开始分离。图4(A)示出了两个系统在具有不同输入偏移值的相同混合示例上的性能。我们观察到,不同于LSTM-TasNet,因果Conv-TasNet对输入混合物的所有偏移值表现一致。我们进一步测试了整个测试集的整体稳健性,方法是计算每个混合物的标准差,并使用类似于图4(A)的移动混合物输入。图4(B)中WSJ0-2mix试验组中所有混合物的箱线图显示,因果Conv-TasNet在整个试验组中的表现始终更好,这证实了Conv-TasNet对混合物起点变化的鲁棒性。对这种不一致性的一种解释可能是由于LSTM-TasNet中的顺序处理限制,这意味着先前帧中的故障会累积并影响所有后续帧中的分离性能,而Conv-TasNet中连续帧的解耦处理减轻了偶然误差的影响。
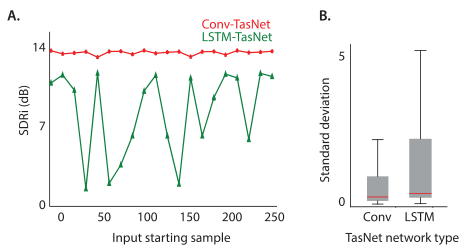
图4.(A)作为混合物起点的函数,使用LSTM-TasNet和因果Conv-TasNet分离的示例混合物的SDRi。 Conv-TasNet的性能相对于起点更加一致且不敏感。 (B)WSJ0-2mix测试集中所有混合物中SDRi的标准偏差,起点不同。
G 基函数的性质
在TasNet中用卷积编码器代替混合信号的STFT表示的动机之一是构建一个为语音分离而优化的音频表示。为了阐明编码器和解码器表示的属性,我们检查了编码器和解码器的基函数(矩阵U和V的行)。图5中示出了最佳非因果Conv-TasNet的基函数,其排序方式与图2相同。每个滤波器的快速傅立叶变换幅度也以相同的顺序显示。如图所示,大多数滤波器被调谐到较低的频率。此外,它显示了具有相同频率调谐的滤波器表示该频率的不同相位值。这种观察可以通过低频基函数的循环移位看出。这一结果表明,语音的低频特征(如音调)以及相位信息的显式编码对于实现卓越的语音分离性能具有重要作用。

图5.编码器和解码器基本函数及其FFT幅度的可视化。 基函数基于它们的成对欧几里得相似度进行排序。
5 总结
在这篇文章中,我们介绍了全卷积时域音频分离网络(Conv-TsaNet),一个深入的时域语音分离学习框架。该框架解决了STFT域中语音分离的缺点,包括相位和幅度的解耦、用于分离的混合音频的次优表示以及计算STFT的高延迟。这些改进是通过用卷积编码器-解码器结构代替STFT来实现的。Conv-TasNet中的分离是使用时间卷积网络(TCN)架构以及深度可分离卷积运算来完成的,以解决深度LSTM网络的挑战。 我们的评估表明,即使使用目标说话人的理想时频掩码,Conv-TasNet的性能也远胜于STFT语音分离系统。 此外,Conv-TasNet具有更小的模型尺寸和更短的最小延迟,这使其适用于低资源,低延迟的应用程序。
与定义明确的逆变换可以完美重建输入的STFT不同,所提出的模型中的最佳性能是通过过完全线性卷积编码器-解码器框架实现的,而不保证输入的完美重建。这一发现促使人们重新思考自动编码器和源分离问题中的过完备性,这可能与过完备字典和稀疏编码的研究有相似之处[51],[52]。此外,在第四章中对编码器/解码器基函数的分析揭示了两个有趣的性质。首先,大多数滤波器被调谐到低声学频率(超过60%被调谐到低于1千赫的频率)。我们使用数据驱动的方法发现,这种频率表示模式大致类似于众所周知的mel-frequency scale [53]以及哺乳动物听觉系统中频率的听觉组织[54],[55]。此外,较低频率的过度表达可能表明准确的音调跟踪在语音分离中的重要性,类似于人类多音调感知研究中的报告[56]。此外,我们发现具有相同频率调谐的滤波器明确地表达各种相位信息。相反,这一信息隐含在STFT运算中,其中实部和虚部分别只表示对称(余弦)和不对称(正弦)相位。信号相位值的这种显式编码可能是TasNet优于基于STFT的分离方法的关键原因。
高精度,短延迟和小尺寸的组合使Conv-TasNet成为离线和实时,低延迟语音处理应用(例如嵌入式系统,可穿戴式听力和电信设备)的合适选择。 Conv-TasNet还可以在其他音频处理任务(例如多方通话者语音识别[57]-[60]和说话人识别[61],[62])中用作串联系统的前端模块。另一方面,Conv-TasNet的一些局限性必须加以解决,然后才能实现,包括对说话人的长期跟踪以及对嘈杂和混响环境的泛化。由于Conv-TasNet使用固定的时间上下文长度,因此对单个说话人的长期跟踪可能会失败,尤其是在混合音频中有较长的停顿时。另外,Conv-TasNet在嘈杂和混响条件下的泛化还必须进一步测试[26],因为时域方法更容易出现时间失真,这在混响声学环境中尤其严重。在这种情况下,如果有多个麦克风可用,扩展Conv-TasNet框架以合并多个输入音频通道可能会证明是有利的。先前的研究表明,将语音分离扩展到多通道输入[63]-[65]的好处,特别是在不利的声学条件下以及当干扰说话人的数量很大(例如,超过3个)时。
总之,Conv-TasNet代表了实现语音分离算法的重要一步,并开辟了许多未来的研究方向,将进一步提高其准确性、速度和计算成本,最终使自动语音分离成为为现实世界应用而设计的每一种语音处理技术的共同和必要特征。
参考文献
[1] D. Wang and J. Chen, “Supervised speech separation based on deep learning: An overview,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 26, no. 1, pp. 1702–1726, Oct. 2018.
[2] X. Lu, Y . Tsao, S. Matsuda, and C. Hori, “Speech enhancement based on deep denoising autoencoder.” in Proc. Interspeech, 2013, pp. 436–440.
[3] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “An experimental study on speech enhancement based on deep neural networks,” IEEE Signal Process. Lett., vol. 21, no. 1, pp. 65–68, Jan. 2014.
[4] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “A regression approach to speech enhancement based on deep neural networks,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 23, no. 1, pp. 7–19, Jan. 2015.
[5] Y . Isik, J. Le Roux, Z. Chen, S. Watanabe, and J. R. Hershey, “Singlechannel multi-speaker separation using deep clustering,” in Proc. Interspeech, 2016, pp. 545–549.
[6] D. Y u, M. Kolbæk, Z.-H. Tan, and J. Jensen, “Permutation invariant training of deep models for speaker-independent multi-talker speech separation,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2017, pp. 241–245.
[7] M. Kolbæk, D. Y u, Z.-H. Tan, and J. Jensen, “Multitalker speech separation with utterance-level permutation invariant training of deep recurrent neural networks,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25, no. 10, pp. 1901–1913, Oct. 2017.
[8] Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for singlemicrophone speaker separation,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2017, pp. 246–250.
[9] Y . Luo, Z. Chen, and N. Mesgarani, “Speaker-independent speech separation with deep attractor network,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 26, no. 4, pp. 787–796, Apr. 2018. [Online]. Available: http://dx.doi.org/10.1109/TASLP .2018.2795749
[10] Z.-Q. Wang, J. Le Roux, and J. R. Hershey, “Alternative objective functions for deep clustering,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2018, pp. 686–690.
[11] Z.-Q. Wang, J. L. Roux, D. Wang, and J. R. Hershey, “End-to-end speech separation with unfolded iterative phase reconstruction,” Interspeech, pp. 2708–2712, 2017.
[12] C. Li, L. Zhu, S. Xu, P . Gao, and B. Xu, “CBLDNN-based speakerindependent speech separation via generative adversarial training,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2018, pp. 711– 715.
[13] D. Griffin and J. Lim, “Signal estimation from modified short-time fourier transform,” IEEE Trans. Acoust., Speech, Signal Process., vol. ASSP-32, no. 2, pp. 236–243, Apr. 1984.
[14] J. Le Roux, N. Ono, and S. Sagayama, “Explicit consistency constraints for STFT spectrograms and their application to phase reconstruction.” in Proc. INTERSPEECH, 2008, pp. 23–28.
[15] Y . Luo, Z. Chen, J. R. Hershey, J. Le Roux, and N. Mesgarani, “Deep clustering and Conventional networks for music separation: Stronger together,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2017, pp. 61–65.
[16] A. Jansson, E. Humphrey, N. Montecchio, R. Bittner, A. Kumar, and T. Weyde, “Singing voice separation with deep u-net Convolutional networks,” in Proc. 18th Int. Soc. Music Inf. Retrieval Conf., 2017, pp. 23–27.
[17] S. Choi, A. Cichocki, H.-M. Park, and S.-Y . Lee, “Blind source separation and independent component analysis: A review,” Neural Inf. Process.— Lett. Rev., vol. 6, no. 1, pp. 1–57, 2005. 1266 IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING, VOL. 27, NO. 8, AUGUST 2019
[18] K. Y oshii, R. Tomioka, D. Mochihashi, and M. Goto, “Beyond NMF: Time-domain audio source separation without phase reconstruction,” in Proc. Int. Soc. Music Inf. Retrieval, 2013, pp. 369–374.
[19] S. V enkataramani, J. Casebeer, and P . Smaragdis, “End-to-end source separation with adaptive front-ends,” in Proc. IEEE 52nd Asilomar Conf. Signals, Syst., Comput., 2018, pp. 684–688.
[20] D. Stoller, S. Ewert, and S. Dixon, “Wave-u-net: A multi-scale neural network for end-to-end audio source separation,” in Proc. Int. Soc. Music Inf. Retrieval, 2018, pp. 334–340.
[21] Y . Luo and N. Mesgarani, “TasNet: Time-domain audio separation network for real-time, single-channel speech separation,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2018, pp. 696–700.
[22] S.-W. Fu, T.-W. Wang, Y . Tsao, X. Lu, and H. Kawai, “End-to-end waveform utterance enhancement for direct evaluation metrics optimization by fully Convolutional neural networks,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 26, no. 9, pp. 1570–1584, Sep. 2018.
[23] S. Pascual, A. Bonafonte, and J. Serrà, “SEGAN: Speech enhancement generative adversarial network,” in Proc. Interspeech, 2017, pp. 3642– 3646.
[24] O. Ronneberger, P . Fischer, and T. Brox, “U-net: Convolutional networks for biomedical image segmentation,” in Proc. Int. Conf. Med. Image Comput. Comput.-Assisted Intervention, 2015, pp. 234–241.
[25] J. R. Hershey, Z. Chen, J. Le Roux, and S. Watanabe, “Deep clustering: Discriminative embeddings for segmentation and separation,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2016, pp. 31– 35.
[26] Y . Luo and N. Mesgarani, “Real-time single-channel dereverberation and separation with time-domain audio separation network,” in Proc. Interspeech, 2018, pp. 342–346.
[27] F.-Y . Wang, C.-Y . Chi, T.-H. Chan, and Y . Wang, “Nonnegative leastcorrelated component analysis for separation of dependent sources by volume maximization,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 5, pp. 875–888, May 2010.
[28] C. H. Ding, T. Li, and M. I. Jordan, “Convex and semi-nonnegative matrix factorizations,” IEEE Trans. Pattern Anal. Mach. Intell., vol. 32, no. 1, pp. 45–55, Jan. 2010.
[29] C. Lea, R. Vidal, A. Reiter, and G. D. Hager, “Temporal Convolutional networks: A unified approach to action segmentation,” in Proc. Eur . Conf. Comput. Vis., 2016, pp. 47–54.
[30] C. Lea, M. D. Flynn, R. Vidal, A. Reiter, and G. D. Hager, “Temporal Convolutional networks for action segmentation and detection,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 156– 165.
[31] S. Bai, J. Z. Kolter, and V . Koltun, “An empirical evaluation of generic Convolutional and recurrent networks for sequence modeling,” 2018, arXiv:1803.01271.
[32] F. Chollet, “Xception: Deep learning with depthwise separable Convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 1251–1258.
[33] A. G. Howard et al., “Mobilenets: EfficientConvolutionalneuralnetworks for mobile vision applications,” 2017, arXiv:1704.04861.
[34] D. Wang, “On ideal binary mask as the computational goal of auditory scene analysis,” in Speech Separation by Humans and Machines. Boston, MA, USA: Springer, 2005, pp. 181–197.
[35] Y . Li and D. Wang, “On the optimality of ideal binary time–frequency masks,” Speech Commun., vol. 51, no. 3, pp. 230–239, 2009.
[36] Y . Wang, A. Narayanan, and D. Wang, “On training targets for supervised speech separation,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 22, no. 12, pp. 1849–1858, Dec. 2014.
[37] H. Erdogan, J. R. Hershey, S. Watanabe, and J. Le Roux, “Phase-sensitive and recognition-boosted speech separation using deep recurrent neural networks,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2015, pp. 708–712.
[38] A. V an Den Oord et al., “Wavenet: A generative model for raw audio,” in Proc. 9th ISCA Speech Syn. Workshop, 2016, p. 125. [39] F. Chollet, “Xception: Deep learning with depthwise separable Convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit., 2017, pp. 1251–1258. [40] K. He, X. Zhang, S. Ren, and J. Sun, “Delving deep into rectifiers:Surpassing human-level performance on imagenet classification,” in Proc. IEEE Int. Conf. Comput. Vis., 2015, pp. 1026–1034.
[41] J. L. Ba, J. R. Kiros, and G. E. Hinton, “Layer normalization,” 2016, arXiv:1607.06450.
[42] “Script to generate the multi-speaker dataset using wsj0,” 2016. [Online]. Available: http://www.merl.com/demos/deep-clustering
[43] D. Kingma and J. Ba, “Adam: A method for stochastic optimization,” in Proc. Int. Conf. Lear . Represent., 2014. [Online]. Available: http://arxiv.org/abs/1412.6980
[44] E. Vincent, R. Gribonval, and C. Févotte, “Performance measurement in blind audio source separation,”IEEE Trans. Audio, Speech, Lang. Process., vol. 14, no. 4, pp. 1462–1469, Jul. 2006.
[45] A. W. Rix, J. G. Beerends, M. P . Hollier, and A. P . Hekstra, “Perceptual evaluation of speech quality (PESQ)—A new method for speech quality assessment of telephone networks and codecs,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2001, vol. 2, pp. 749–752.
[46] V ocabulary for Performance and Quality of Service, International Telecommunication Union (ITU), Geneva, Switzerland, ITU-T Rec. P .10, 2006.
[47] R. R. Sokal, “A statistical method for evaluating systematic relationship,” Univ. Kansas Sci. Bull., vol. 28, pp. 1409–1438, 1958.
[48] M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted residuals and linear bottlenecks,” inProc. IEEE Conf. Comput. Vision Pattern Recognit., 2018, pp. 4510–4520.
[49] “Audio samples for Conv-TasNet,” 2018. [Online]. Available: http://naplab.ee.columbia.edu/TasNet.html
[50] C. Xu, X. Xiao, and H. Li, “Single channel speech separation with constrained utterance level permutation invariant training using grid LSTM,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2018, pp. 6–10.
[51] T.-W. Lee, M. S. Lewicki, M. Girolami, and T. J. Sejnowski, “Blind source separation of more sources than mixtures using overcomplete representations,” IEEE Signal Process. Lett., vol. 6, no. 4, pp. 87–90, Apr. 1999.
[52] M. Zibulevsky and B. A. Pearlmutter, “Blind source separation by sparse decomposition in a signal dictionary,” Neural Comput., vol. 13, no. 4, pp. 863–882, 2001.
[53] S. Imai, “Cepstral analysis synthesis on the mel frequency scale,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 1983, vol. 8, pp. 93–96.
[54] G. L. Romani, S. J. Williamson, and L. Kaufman, “Tonotopic organization of the human auditory cortex,”Science, vol. 216, no. 4552, pp. 1339–1340, 1982.
[55] C. Pantev, M. Hoke, B. Lutkenhoner, and K. Lehnertz, “Tonotopic organization of the auditory cortex: Pitch versus frequency representation,” Science, vol. 246, no. 4929, pp. 486–488, 1989.
[56] C. J. Darwin, D. S. Brungart, and B. D. Simpson, “Effects of fundamental frequency and vocal-tract length changes on attention to one of two simultaneous talkers,” J. Acoustical Soc. Amer ., vol. 114, no. 5, pp. 2913–2922, 2003.
[57] J. R. Hershey, S. J. Rennie, P . A. Olsen, and T. T. Kristjansson, “Superhuman multi-talker speech recognition: A graphical modeling approach,” Comput. Speech Lang., vol. 24, no. 1, pp. 45–66, 2010.
[58] C. Weng, D. Y u, M. L. Seltzer, and J. Droppo, “Deep neural networks for single-channel multi-talker speech recognition,”IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 23, no. 10, pp. 1670–1679, Oct. 2015.
[59] Y . Qian, X. Chang, and D. Y u, “Single-channel multi-talker speech recognition with permutation invariant training,” Speech Commun., vol. 104, pp. 1–11, 2018.
[60] K. Ochi, N. Ono, S. Miyabe, and S. Makino, “Multi-talker speech recognition based on blind source separation with ad hoc microphone array using smartphones and cloud storage,” in Proc. INTERSPEECH, 2016, pp. 3369–3373.
[61] Y . Lei, N. Scheffer, L. Ferrer, and M. McLaren, “A novel scheme for speaker recognition using a phonetically-aware deep neural network,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2014, pp. 1695– 1699.
[62] M. McLaren, Y . Lei, and L. Ferrer, “Advances in deep neural network approaches to speaker recognition,” inProc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2015, pp. 4814–4818.
[63] S. Gannot et al., “A consolidated perspective on multimicrophone speech enhancement and source separation,” IEEE/ACM Trans. Audio, Speech, Lang. Process., vol. 25, no. 4, pp. 692–730, Apr. 2017.
[64] Z. Chen et al., “Cracking the cocktail party problem by multi-beam deep attractor network,” inProc. IEEE Autom. Speech Recognit. Understanding Workshop, 2017, pp. 437–444.
[65] Z.-Q. Wang, J. Le Roux, and J. R. Hershey, “Multi-channel deep clustering: Discriminative spectral and spatial embeddings for speaker-independent speech separation,” in Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2018, pp. 1–5.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号