论文翻译:2020_Demucs:Real Time Speech Enhancement in the Waveform Domain
论文地址:在波形域的实时语音增强
论文作者:facebook AI 研究所
论文代码:https://github.com/facebookresearch/denoiser
摘要
我们提出了一个基于原始波形的因果语音增强模型,该模型在笔记本电脑CPU上实时运行。所提出的模型是基于一个带有跳跃连接的编码器-解码器架构。利用多个损耗函数,在时域和频域上都得到了优化。实验结果表明,该方法能够去除各种背景噪声,包括平稳噪声和非平稳噪声,以及室内混响。此外,我们建议一套直接应用于原始波形的数据增强技术,进一步提高模型的性能和泛化能力。我们在几个标准基准上进行评估,使用客观指标和人的判断。提出的模型匹配最先进的性能的因果和非因果方法,同时直接工作在原始波形。
关键词:语音增强,语音去噪,神经网络,原始波形
1 引言
语音增强的目的是最大限度地提高语音信号的感知质量,特别是去除背景噪声。大多数被记录的会话语音信号都含有一些妨碍清晰度的噪音,如街道噪音、狗叫声、键盘打字等。因此,语音增强本身就是一项特别重要的任务,无论是音视频通话[1],助听器[2],还是自动语音识别(ASR)系统[3]。对于许多这样的应用程序,语音增强系统的一个关键特性是实时运行,并且尽可能少的延迟(在线),在通信设备上,最好是在商用硬件上。
数十年的语音增强工作表明了可行的解决方案,估计噪声模型,并使用它来恢复去除噪声的语音[4,5]。尽管这些方法可以很好地跨领域推广,但它们仍然难以处理常见的噪声,如非平稳噪声或一群人同时说话时遇到的喋喋不休的噪声。这种噪音类型的存在大大降低了人类语言的听力可理解性。近年来,基于深度神经网络(DNN)的模型在处理非平稳噪声和babble噪声时表现明显优于传统方法,同时在客观和主观评价中产生更高质量的语音[7,8]。此外,基于深度学习的方法在单通道源分离相关任务中也表现出优于传统方法[9,10,11]。
受这些最新进展的启发,我们提出了一个实时版本的DEMUCS[11]架构,适合语音增强。它由一个基于卷积和LSTMs的因果模型组成,帧大小为40ms,步幅为16ms,运行速度比在单一笔记本电脑CPU核上的实时运行速度快。为了提高音频质量,我们的模型通过分层生成(使用U-Net[12],就像跳过连接)从一个波形到另一个波形。我们对模型进行优化,以直接输出语音信号的干净版本,同时最小化回归损失函数(L1损失),辅以谱图域损失[13,14]。此外,我们还提出了一套简单有效的数据增强技术:频带掩蔽和信号混响。尽管对模型运行时施加了重要的实时约束,我们的模型通过客观和主观的度量产生了与最先进的模型相当的性能。
尽管有多种指标可以衡量语音增强系统,但这些指标与人类的判断[1]并不相关。因此,我们报告客观指标和人类评价的结果。此外,我们进行了消融研究的损失和增强功能,以更好地突出每个部分的贡献。最后,我们利用自动语音识别(ASR)模型产生的单词错误率(WERs)分析了增强过程中的伪影。
结果表明,当直接在原始波形上工作时,所提出的方法在所有指标上都可与当前最先进的模型相媲美。此外,增强的样本对噪声条件下ASR模型的改进也有帮助。
2 方法
2.1 符号和问题设置
我们专注于可以在实时应用程序中操作的单耳(单麦克风)语音增强。具体来说,给定一个音频信号$x$,由一个干净的语音$y$组成,它被一个附加的背景信号$n$损坏,因此$x = y + n$。长度$T$在样本中不是一个固定的值,因为输入的语音可以有不同的持续时间。我们的目标是找到一个增强函数$f$使$f(x) \approx y$。
在本研究中,我们将$f$设为DEMUCS架构[11],该架构最初是为音乐源分离而开发的,并将其适应于因果语音增强任务,对该模型的视觉描述如图1a所示。
2.2 DEMUCS架构
DEMUCS包含一个多层卷积编码器和解码器,带有U-net[12] skip connections,以及一个用于编码器输出的序列建模网络。特点是其层数$L$,隐藏通道的初始数$H$,层内kernel size $K$和stride $S$以及重采样因子U,编码器和解码器层从1到L编号(对于解码器,顺序相反,因此层 在相同scale下具有相同索引)。 当我们专注于单声道语音增强时,模型的输入和输出仅为单通道。
形式上,编码器网络$E$获得原始波形作为输入,并输出一个潜在表示$E(x)=z$。 每层都包含一个卷积层,其内核大小为$K$,步幅为$S$,具有$2^{i-1}H$输出通道,然后是ReLU激活函数,具有$2^iH$输出通道的1x1卷积,最后是GLU [15]激活函数,它将通道数转换回 到$w^{i-1}H$,请参见图1b的直观说明。
接下来,序列模型$R$网络将潜在表示$z$作为输入,并输出相同大小的非线性变换$R(z)= LSTM(z)+ z$,表示为$\hat{z}$。 LSTM网络由2层和$2^{L-1}H$隐藏单元组成。 对于因果关系预测,我们使用单向LSTM,而对于非因果关系模型,我们使用双向LSTM,然后使用线性层将两个输出合并。
最后,解码器网络$D$将$\hat{z}$作为输入并输出估计的干净信号$D(\hat{z})=\hat{y}$。 解码器的第$i$层将$2^{i-1}H$通道作为输入,并应用$2^iH$个通道进行1x1卷积,然后是输出$2^{i-1}H$通道的GLU激活函数,最后是kernel size为8,stride为4的转置卷积,以及带有ReLU激活函数的$2^{i-2}H$输出通道。 对于最后一层,输出是单个通道,没有ReLU。 跳过连接将编码器的第$i$层的输出与解码器的第$i$层的输入相连,请参见图1a。
我们使用[16]提出的方案初始化所有模型参数。 最后,我们注意到在将音频feed到编码器之前对音频进行上采样$U$倍可以提高精度。 我们以相同的数量对模型的输出进行下采样。 作为端到端训练的一部分,使用Sinc插值滤波器[17]进行重采样,而不是执行预处理步骤。
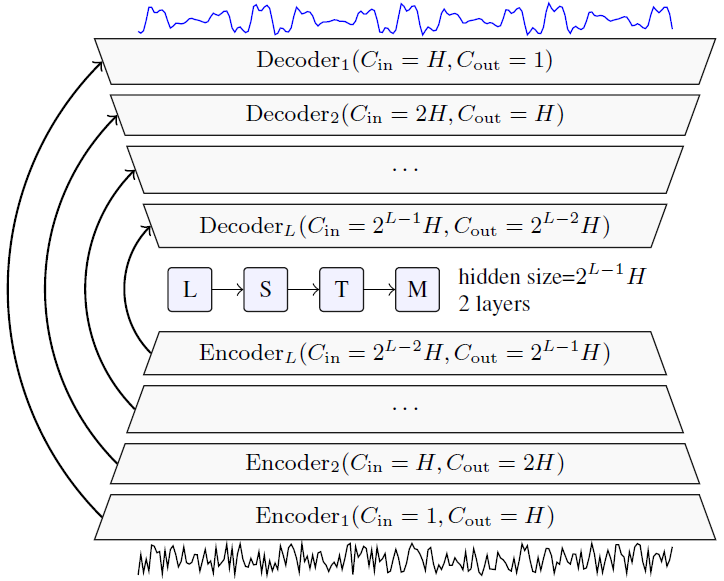
(a) 因果Demucs,嘈杂的语音作为输入在底部,干净的语音作为输出在顶部。
箭头表示UNet skip connections。$H$控制模型中通道的数量,$L$控制它的深度。

(b) 每个编码器层(底部)和解码器层(顶部)的视图。箭头是与模型其他部分的连接。
$C_{in}(resp. C_{out})$是输入通道的数量$(resp. output)$,$K$为内核大小,$S$为步数。
图1:左边是因果DEMUCS架构,右边是编码器和解码器层的详细表示。不表示对输入/输出的动态重采样,重采样倍数为U。
2.3 目标
我们在波形上使用$L1$损失,在频谱图幅度上使用多分辨率STFT损失,类似于在[13,14]中提出的。 形式上,给定$y$和$\hat{y}$分别是干净信号和增强信号。 我们将STFT损失定义为频谱会聚(spectral convergence,sc)损失和幅度损失之和,如下所示:
$$公式1:L_{stft}(y,\hat{y})=L_{sc}(y,\hat{y})+L_{mag}(y,\hat(y))\\
L_{sc}(y,\hat{y})=\frac{|||STFT(y)|-|STFT(\hat{y})|||_F}{||STFT(y)||_F}\\
L_{mag}(y,\hat{y})=\frac{1}{T}||log|STFT(y)|-log|STFT(\hat{y})|||_1$$
其中$||·||_F$和$||·||_1$分别是Frobenius $L_1$范数。 我们将多分辨率STFT损耗定义为使用不同STFT参数的所有STFT损耗函数的总和。 总的来说,我们希望将以下内容减至最少:
$$公式2:\frac{1}{T}[||y-\hat{y}||_1+\sum_{i=1}^ML_{stft}^{(i)}(y,\hat{y})]$$
其中$M$是STFT损耗的数量,每个$L_{stft}^{(i)}$都以不同分辨率使用STFT损耗,其中FFT bins的数量为{512,1024,2048},帧移为{50,120,240},最后是窗口长度 {240,600,1200}。
3 实验
我们进行了几个实验来评估提出的方法与几个高度竞争的模型。我们报道了关于Valentini等人的[18]和深度噪声抑制(DNS)[19]基准的客观和主观测量。此外,我们对增强和损失功能进行了消融研究。最后,我们评估了增强样本的可用性,以改善噪声条件下的ASR性能。代码和示例可以在下面的链接中找到:https://github.com/facebookresearch/denoiser。
3.1 复现细节
评价方法我们采用客观和主观两种方法来评价增强语音的质量。对于客观测量,我们使用:(i) PESQ:语音质量的感知评估,使用ITU-T P.862.2[24](从0.5到4.5)推荐的宽带版本(ii)短时客观清晰度(STOI)[25](从0到100)(iii) CSIG:平均意见评分(MOS)预测仅对语音信号[26]的信号失真(从1到5)。(iv) CBAK:对背景噪声[26]的干扰的MOS预测(从1到5)。(v) COVL:对整体效果[26]的MOS预测(从1到5)。
对于主观测量,我们进行了ITU-T P.835[27]推荐的MOS研究。为此,我们使用CrowdMOS包[28]进行了众包评估。我们随机抽取100个话语,每一个都由15个不同的评分者沿着三个轴进行评分:扭曲程度,背景噪音干扰程度和整体质量。对所有注释器和查询的平均结果给出最终分数。
训练 我们在 Valentini [18] 数据集上训练 DEMUCS 模型 400 个时期,在 DNS [19] 数据集上训练 250 个时期。 我们使用预测和真实干净语音波形之间的 L1 损失,并且对于 Valentini 数据集,还添加了第 2.3 节中描述的 STFT 损失,权重为 0.5。 我们使用 Adam 优化器,步长为 3e−4,动量 B1 = 0.9,分母动量 B2 = 0.999。 对于 Valentini 数据集,我们使用原始验证集并保留最佳模型,对于 DNS 数据集,我们在没有验证集的情况下训练并保留最后一个模型。 音频以 16 kHz 采样。
模型 我们使用第 2 节中描述的 DEMUCS 架构的三个变体。对于非因果 DEMUCS,我们取 U=2、S=2、K=8、L=5 和 H=64。 对于因果 DEMUCS,我们取 U=4、S=4、K=8 和 L=5,以及 H=48 或 H=64。 在将输入输入模型之前,我们通过其标准差对输入进行归一化,并按相同的因子缩小输出。 对于因果模型的评估,我们使用标准偏差的在线估计。 使用此设置,因果 DEMUCS 处理音频的帧大小为 37 毫秒,步长为 16 毫秒。
数据增强 我们总是在 0 到 S 秒之间应用随机移位。
Remix 增强将一batch中的噪音打乱以形成新的带噪语音。
Band-Mask 是一种带阻滤波器,其阻带介于 $f_0$ 和 $f_1$ 之间,采样以在梅尔标度中均匀去除 20% 的频率。 在波形域中,这等效于用于 ASR 训练的 SpecAug 增强 [29]。
Revecho:给定初始增益 $\lambda$、早期延迟 $\tau$ 和 RT60,它将一系列 N 个干净语音和噪声的衰减回声添加到带噪语音中。 第 $n$个回波具有 $n\tau+$ 抖动的延迟和 $\lambda$ 的增益。 选择$N$和$\rho$以便当总延迟达到 RT60 时,我们有$\rho^N\leq 1e-3$。 $\lambda$、$\tau$ 和 RT60 分别在 [0, 0.3]、[10, 30] ms、[0.3, 1.3] 秒内均匀采样。
我们对所有数据集使用随机移位,对Valentini[18]使用Remix和Banmask,而对DNS[19]使用Revecho。
因果流评估 为了在真实条件下测试我们的因果模型,我们在测试时使用特定的流实现。 我们不使用音频的标准偏差进行标准化,而是使用直到当前位置的标准偏差(即我们使用累积标准偏差)。我们保留过去输入/输出的小缓冲区,以限制正弦重采样滤波器的副作用。 对于输入上采样,我们还使用了 3ms 的前瞻,这使模型的总帧大小达到 40 ms。 当将模型应用于信号的给定帧时,输出的最右边部分无效,因为需要未来的音频来正确计算转置卷积的输出。 尽管如此,我们注意到使用这个无效部分作为流下采样的填充大大提高了 PESQ。 流实现是纯 PyTorch。 由于帧之间的重叠,需要注意缓存不同层的输出。
3.2 结果
3.3 消融
3.4 实时评估
3.5 对ASR模型的影响
4 相关工作
传统的语音增强方法要么生成幅度谱的增强版本,要么生成理想二进制掩码(IBM)的估计数,然后用于增强幅度谱[5,33]。
在过去的几年里,人们对基于DNN的语音增强方法越来越感兴趣[34,35,36,37,20,38,39,22,40,7,41,8,42,21,37]。在[34]中,一个深度前馈神经网络被用来产生一个频率域二进制掩码,使用波形域的代价函数。[43]的作者建议使用多目标损失函数来进一步改善语音质量。另外,作者在[44,35]中使用递归神经网络(RNN)进行语音增强。在[7]中,作者提出了一种端到端的方法,即语音增强生成对抗网络(SEGAN)直接从原始波形进行增强。作者在[41,8,42,21]中进一步改进了这种优化。在[37]中,作者建议使用一个WaveNet[45]模型,通过学习一个函数来将噪声映射到干净的信号中去噪。
在考虑因果方法的同时,[46] 中的作者提出了一种频谱级别的卷积循环网络用于实时语音增强,而 Xia、Yangyang 等人则提出了 [30] 建议去除卷积层并应用加权损失函数以进一步改善实时设置的结果。 最近,[23] 中的作者使用最小均方误差噪声功率谱密度跟踪器为因果模型和非因果模型提供了令人印象深刻的结果,该跟踪器采用了时间卷积网络 (TCN) 先验 SNR 估计器。
5 讨论
我们已经展示了DEMUCS,一个在波形域为音乐源分离而开发的最先进的架构,如何变成一个因果语音增强器,在消费级CPU上实时处理音频。我们在标准的Valentini基准上测试了demacs,并在不使用额外训练数据的情况下获得了最先进的结果。我们还使用DNS数据集在真实混响条件下测试我们的模型。我们以经验证明增强技术(两源混响,局部去混响)如何在主观评价中产生显著的改善。最后,我们证明了我们的模型可以提高ASR模型在噪声条件下的性能,甚至不需要对模型进行再训练。
6 参考文献
[1] C. K. Reddy et al., A scalable noisy speech dataset and online subjective test framework, preprint arXiv:1909.08050, 2019.
[2] C. K. A. Reddy et al., An individualized super-gaussian single microphone speech enhancement for hearing aid users with smartphone as an assistive device, IEEE signal processing letters, vol. 24, no. 11, pp. 1601 1605, 2017.
[3] C. Zorila, C. Boeddeker, R. Doddipatla, and R. Haeb-Umbach, An investigation into the effectiveness of enhancement in asr training and test for chime-5 dinner party transcription, preprint arXiv:1909.12208, 2019.
[4] J. S. Lim and A. V. Oppenheim, Enhancement and bandwidth compression of noisy speech, Proceedings of the IEEE, vol. 67, no. 12, pp. 1586 1604, 1979.
[5] Y. Ephraim and D. Malah, Speech enhancement using a minimum-mean square error short-time spectral amplitude estimator, IEEE Transactions on acoustics, speech, and signal processing, vol. 32, no. 6, pp. 1109 1121, 1984.
[6] N. Krishnamurthy and J. H. Hansen, Babble noise: modeling, analysis, and applications, IEEE transactions on audio, speech, and language processing, vol. 17, no. 7, pp. 1394 1407, 2009.
[7] S. Pascual, A. Bonafonte, and J. Serra, Segan: Speech enhancement generative adversarial network, preprint arXiv:1703.09452, 2017.
[8] H. Phan et al., Improving gans for speech enhancement, preprint arXiv:2001.05532, 2020.
[9] Y. Luo and N. Mesgarani, Conv-TASnet: Surpassing ideal time frequency magnitude masking for speech separation, IEEE/ACM transactions on audio, speech, and language processing, vol. 27, no. 8, pp. 1256 1266, 2019.
[10] E. Nachmani, Y. Adi, and L. Wolf, Voice separation with an unknown number of multiple speakers, arXiv:2003.01531, 2020.
[11] A. Dfossez et al., Music source separation in the waveform domain, 2019, preprint arXiv:1911.13254.
[12] O. Ronneberger, P. Fischer, and T. Brox, U-net: Convolutional networks for biomedical image segmentation, in International Conference on Medical image computing and computer-assisted intervention, 2015.
[13] R. Yamamoto, E. Song, and J.-M. Kim, Parallel wavegan: A fast waveform generation model based on generative adversarial networks with multi-resolution spectrogram, preprint arXiv:1910.11480, 2019.
[14] , Probability density distillation with generative adversarial networks for high-quality parallel waveform generation, preprint arXiv:1904.04472, 2019.
[15] Y. N. Dauphin et al., Language modeling with gated convolutional networks, in ICML, 2017.
[16] K. He, X. Zhang, S. Ren, and J. Sun, Delving deep into rectifiers: Surpassing human-level performance on imagenet classification, in ICCV, 2015.
[17] J. Smith and P. Gossett, A flexible sampling-rate conversion method, in ICASSP, vol. 9. IEEE, 1984, pp. 112 115.
[18] C. Valentini-Botinhao, Noisy speech database for training speech enhancement algorithms and tts models, 2017.
[19] C. K. A. Reddy et al., The interspeech 2020 deep noise suppression challenge: Datasets, subjective speech quality and testing framework, 2020.
[20] C.Macartney and T.Weyde, Improved speech enhancement with the wave-u-net, preprint arXiv:1811.11307, 2018.
[21] M. H. Soni, N. Shah, and H. A. Patil, Time-frequency maskingbased speech enhancement using generative adversarial network, in ICASSP. IEEE, 2018, pp. 5039 5043.
[22] S.-W. Fu et al., Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement, in ICML, 2019.
[23] Q. Zhang et al., Deepmmse: A deep learning approach to mmsebased noise power spectral density estimation, IEEE/ACMTransactions on Audio, Speech, and Language Processing, 2020.
[24] I.-T. Recommendation, Perceptual evaluation of speech quality (pesq): An objective method for end-to-end speech quality assessment of narrow-band telephone networks and speech codecs, Rec. ITU-T P. 862, 2001.
[25] C. H. Taal et al., An algorithm for intelligibility prediction of time frequency weighted noisy speech, IEEE Transactions on Audio, Speech, and Language Processing, vol. 19, no. 7, pp. 2125 2136, 2011.
[26] Y. Hu and P. C. Loizou, Evaluation of objective quality measures for speech enhancement, IEEE Transactions on audio, speech, and language processing, vol. 16, no. 1, pp. 229 238, 2007.
[27] I. Recommendation, Subjective test methodology for evaluating speech communication systems that include noise suppression algorithm, ITU-T recommendation, p. 835, 2003.
[28] F. Protasio Ribeiro et al., Crowdmos: An approach for crowdsourcing mean opinion score studies, in ICASSP. IEEE, 2011.
[29] D. S. Park et al., Specaugment: A simple data augmentation method for automatic speech recognition, in Interspeech, 2019.
[30] Y. Xia et al., Weighted speech distortion losses for neuralnetwork- based real-time speech enhancement, preprint arXiv:2001.10601, 2020.
[31] V. Panayotov et al., Librispeech: an asr corpus based on public domain audio books, in ICASSP. IEEE, 2015, pp. 5206 5210.
[32] G. Synnaeve et al., End-to-end asr: from supervised to semi-supervised learning with modern architectures, preprint arXiv:1911.08460, 2019.
[33] Y. Hu and P. C. Loizou, Subjective comparison of speech enhancement algorithms, in ICASSP, vol. 1. IEEE, 2006, pp. I I.
[34] Y. Wang and D. Wang, A deep neural network for time-domain signal reconstruction, in ICASSP. IEEE, 2015, pp. 4390 4394.
[35] F. Weninger, H. Erdogan, S. Watanabe, E. Vincent, J. Le Roux, J. R. Hershey, and B. Schuller, Speech enhancement with lstm recurrent neural networks and its application to noise-robust asr, in International Conference on Latent Variable Analysis and Signal Separation. Springer, 2015, pp. 91 99.
[36] Y. Xu et al., A regression approach to speech enhancement based on deep neural networks, IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 1, pp. 7 19, 2014.
[37] D. Rethage, J. Pons, and X. Serra, A wavenet for speech denoising, in ICASSP. IEEE, 2018, pp. 5069 5073.
[38] A. Nicolson and K. K. Paliwal, Deep learning for minimum mean-square error approaches to speech enhancement, Speech Communication, vol. 111, pp. 44 55, 2019.
[39] F. G. Germain, Q. Chen, and V. Koltun, Speech denoising with deep feature losses, preprint arXiv:1806.10522, 2018.
[40] M. Nikzad, A. Nicolson, Y. Gao, J. Zhou, K. K. Paliwal, and F. Shang, Deep residual-dense lattice network for speech enhancement, preprint arXiv:2002.12794, 2020.
[41] K. Wang, J. Zhang, S. Sun, Y. Wang, F. Xiang, and L. Xie, Investigating generative adversarial networks based speech dereverberation for robust speech recognition, arXiv:1803.10132, 2018.
[42] D. Baby and S. Verhulst, Sergan: Speech enhancement using relativistic generative adversarial networks with gradient penalty, in ICASSP. IEEE, 2019, pp. 106 110.
[43] Y. Xu et al., Multi-objective learning and mask-based postprocessing for deep neural network based speech enhancement, preprint arXiv:1703.07172, 2017.
[44] F. Weninger et al., Discriminatively trained recurrent neural networks for single-channel speech separation, in GlobalSIP. IEEE, 2014, pp. 577 581.
[45] A. v. d. Oord et al., Wavenet: A generative model for raw audio, preprint arXiv:1609.03499, 2016.
[46] K. Tan and D. Wang, A convolutional recurrent neural network for real-time speech enhancement. in Interspeech, vol. 2018, 2018, pp. 3229 3233.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号