声学回声消除(Acoustic Echo Cancellation)原理与实现
文章作者:凌逆战
文章地址:https://www.cnblogs.com/LXP-Never/p/11703440.html
回声就是声音信号经过一系列反射之后,又听到了自己讲话的声音,这就是回声。一些回声是必要的,比如剧院里的音乐回声以及延迟时间较短的房间回声;而大多数回声会造成负面影响,比如在有线或者无线通信时重复听到自己讲话的声音(回想那些年我们开黑打游戏时,如果其中有个人开了外放,他的声音就会回荡来回荡去,直至产生啸叫)。因此消除回声的负面影响对通信系统是十分必要的。
针对回声消除(Acoustic Echo Cancellation,AEC )问题,现如今最流行的算法就是基于自适应滤波的回声消除算法。本文从回声信号的两种分类以及 AEC 的基本原理出发,介绍几种经典的 AEC 算法并对其性能进行阐释。
回声的产生
在麦克风与扬声器互相作用影响的双工通信系统中极易产生声学回声。如下图所示
远端讲话者-->远端麦克风-->通话网络---->近端扬声器--->近端麦克风-->通话网络-->远端扬声器--->远端麦克风--->远端电话-->近端电话---->......就这样无限循环,
详细讲解:远端讲话者的声音被远端麦克风采集并传入通信设备,经过通信传输之后达到近端的通信设备,并通过近端扬声器播放,这个声音又会被近端麦克风采集形成声学回声,经传输又返回到远端的通信设备,并通过远端扬声器播放出来,从而远端讲话者就听到了自己的回声。
我们期望:远端讲话者-->远端麦克风-->通话网络---->近端扬声器--->近端麦克风-->AEC(把远端声音滤除,不要再传回远端了)
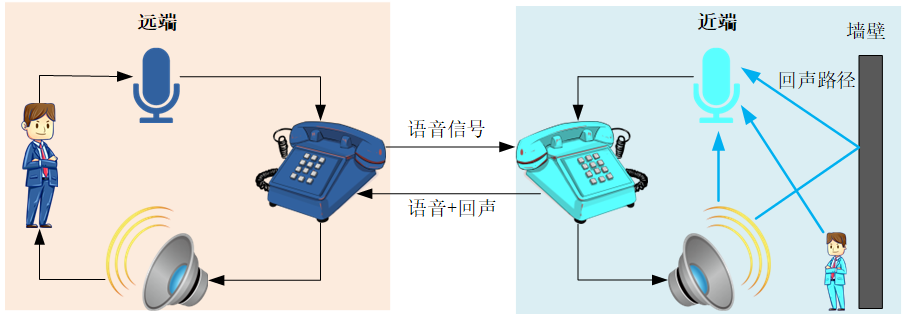
声学回声产生原理
远端语音信号:被远端麦克风采集的信号(说话人语音),也等于近端扬声器播放的语音,也称为参考语音
近端语音信号:近端说话人语音信号
近端麦克风接收的语音信号:近端扬声器播放的声音+在房间多径反射的语音+近端说话人的语音
远端混合回声信号:整个对话过程中,近端麦克风接收到的信号有近端说话人语音信号和近端扬声器播放的远端说话人语音,这样叠加的语音信号通过传输线路传到远端扬声器播放导致远端人听到自己刚刚检测出的语音信号,即所谓的回声。
声学回声信号根据传输途径的差别可以分为直接回声信号和间接回声信号。
- 线性回声:声音经过直接和间接反射,其频率成分和原始信号的频率成分保持一致,只是幅度和相位发生了变化,与原始信号之间存在线性关系。
- 非线性回声:通常由于设备(扬声器、麦克风频响)导致信号失真以及复杂的声学耦合(声波的多径传播、物品摆放以及墙面吸引系数等等因素)造成。回声信号与原始信号之间存在非线性关系的情况。
回声消除技术主要用于在免提电话、电话会议系统等情形中。

一个完整的回声消除系统,包含以下几个模块:
- 时延估计(Time Delay Estimation, TDE) 模块
- 线性回声消除(Linear Acoustic Echo Cancellation, AEC) 模块
- 双讲检测(Double-Talk Detect, DTD) 模块
- 非线性残余声学回声抑制(Residual Acoustic Echo Suppression, RAES) 模块,也常称为非线性处理技术(Nonlinear Processing, NLP)

滤波器有两种状态:
- 滤波:$\hat{y}(n)=x(n)*\hat{w}(n)$,$e(n)=d(n)-\hat{y}(n)$
- 自适应滤波器系数更新(NLMS):$\hat{w}(n+1)=\hat{w}(n)+\mu e(n)\frac{x(n)}{x^T(n)x(n)}$
自适应滤波器有三种工作模式(通过DTD双讲检测):
- 远端语音存在,近端语音不存在(单讲):滤波、自适应滤波器系数更新
- 远端语音存在,近端语音存在(双讲):滤波,滤波器系数不更新
- 远端语音不存在:什么都不用做
AEC的基本原理
回声消除常用方法
声场环境材料处理
- 墙壁、天花板换成吸音材料,有效的较少声音的反射,
- 优缺点:可以较为直接的抑制间接噪声,但是直接噪声无法抑制;成本较高
回声抑制器
- 通过一个电平对比单元 轮流打开和关闭扬声器和麦克风
- 优缺点:导致功放设备的输出信号不连续,总体效果不好
自适应回声抵消(用的最多)
通过自适应算法来调整滤波器的迭代更新系数,估计出一个期望信号,逼近经过实际回声路径的回声信号,也就是去模拟回声信号,然后从麦克风采集的混合信号中减去这个模拟回声,达到回声抵消的功能
如今解决 AEC 问题最常用的方法,就是
使用自适应滤波算法调整滤波器的权值向量,估计一个近似的回声路径来逼近真实回声路径,从而得到估计的回声信号,并在近端语音和远端回声的混合信号中除去此信号来实现回声的消除。
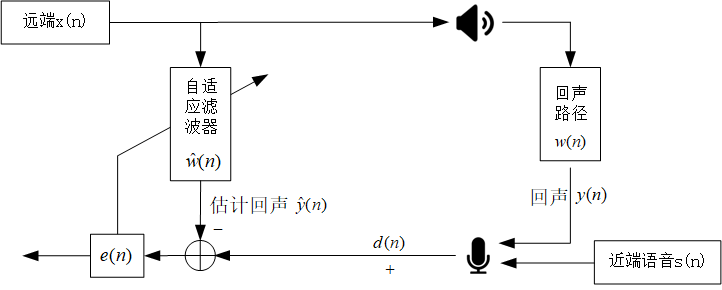
AEC的基本原理
$x(n)$为远端语音,$s(n)$为近端语音,近端说话的时候,远端经过未知的回声路径$w(n)$,会产生回声信号$y(n)=x(n)*w(n)$,那么近端麦克风接受的信号为 $d(n)= y(n) + s(n)$。近端的自适应滤波器$\hat{w}(n)$就会参考远端信号$x(n)$估计回声$\hat{y}(n)$,并与近端麦克风信号$d(n)$相减得到误差信号$e(n)=d(n)-\hat{y}(n)$,$e(n)$应该接近于近端语音$s(n)$;在不考虑近端语音的情况下(单讲),误差信号的值越小说明自适应滤波估计的回声路径就越接近真实的回声路径。
滤波器采用特定的自适应算法不停地调整权值向量,使估计的回声路径$\hat{w}(n)$逐渐趋近于真实回声路径$w(n)$。显然,在 AEC 问题中,自适应滤波器的选择对回声消除的性能好坏起着十分关键的作用。接下来将介绍几种解决 AEC 问题的经典自适应滤波算法。
回声消除常用算法
LSM算法
通过上面AEC的基本原理我们知道了误差信号$e(n)$等于近端麦克风信号$d(n)$减去滤波器估计信号$\hat{y}$:
$$e(n)=d(n)-\hat{w}(n)x(n)$$
运用最小均方误差准则,通过对其求导并令其等于0,求$|e(n)|^2$最小时的$\hat{w}$(因为$|e(n)|$在最小点不可导,所以使用的是$|e(n)|^2$),对于LMS算法,其滤波器系数迭代公式为
$$\begin{aligned}
w(n+1) &=w(n)-\mu \frac{\partial e(n)^{2}}{\partial w} \\
&=w(n)-2 \mu e(n) \frac{\partial(d(n)-\hat{w} * x(n))}{\partial w} \\
&=w(n)+2 \mu e(n) x(n)
\end{aligned}$$
式中,$\mu$为固定步长因子,$\mu$的大小很大程度上决定了算法的收敛与稳态性能。$\mu$越大,算法收敛越快,但稳态误差也越大;$\mu$越小,算法收敛越慢,但稳态误差也越小。为保证算法稳态收敛,应使$\mu$在以下范围取值:
$$0 < \mu < \frac{2}{{\sum\limits_{i = 1}^N {x(i)_{}^2} }}$$
LMS算法实现
LMS算法的每次迭代都需要三个不同的步骤,顺序如下
1、滤波器输出$\hat{y}(n)$
$$\hat{y}(n)=\sum_{i=1}^{N}\hat{w}(n)x(n-i)=\hat{w}(n)x(n)$$
2、估计误差
$$e(n)=d(n)-\hat{y}(n)$$
3、FIR向量权值更新,以准备下一次迭代
$$\hat{w}(n+1)=\hat{w}(n)+2\mu e(n)x(n)$$
def lms(x, d, N=4, mu=0.02): """ e(n)=d(n)-\hat{w}(n)x(n)^T :param x: 远端参考语音 :param d: 近端麦克风信号(近端语音+远端回声) :param N: 滤波器阶数 :param mu: 步长 :return: 估计的近端语音 """ nIters = min(len(x), len(d)) - N # 迭代点数 u = np.zeros(N) # 远端参考语音 w = np.zeros(N) # 滤波器权重 e = np.zeros(nIters) for n in range(nIters): u[1:] = u[:-1] u[0] = x[n] e[n] = d[n] - np.dot(u, w) # 近端麦克风信号减去估计的回声,期望等于近端语音 w = w + 2 * mu * e[n] * u return e
LMS算法在自适应滤波中流行的主要原因是其计算简单,易于实现。对于每次迭代,LMS算法只需要2N加法和2N+1乘法。但是总体而言,LMS 算法复杂性低,它的收敛速度还是慢。而且是固定步长,这就需要在开始自适应滤波操作之前了解输入信号的统计信息。实际上,这是很难实现的。有许多因素如信号输入功率和振幅会影响其性能,为改善 LMS 这个不足之处,科研人员提出一系列改进算法,NLMS 算法就是其中一种。
NLMS算法
归一化最小均方(NLMS)算法是LMS算法的一个扩展,利用可变的步长因子代替固定的步长因子,就得到了NLMS算法,它通过计算最大步长值$\mu$绕过了这个问题。
$$\mu=\frac{1}{x^T(n)x(n)}$$
这个步长与输入向量$x(n)$能量的倒数成正比。
NLMS算法迭代方程为
$$\hat{w}(n+1)=\hat{w}(n)+\mu(n)e(n)x(n)=\hat{w}(n)+\frac{1}{x^T(n)x(n)}e(n)x(n)$$
NLMS算法实现
由于步长$\mu$是根据当前的输入值来选择的,因此NLMS算法在未知信号下具有更大的稳定性。该算法具有良好的收敛速度和相对简单的计算能力,是实时自适应回波抵消系统的理想算法。
NLMS算法的每次迭代都需要按照以下顺序执行这些步骤。
1、计算了自适应滤波器的输出
$$y(n)=\sum_{i=1}^{N}\hat{w}(n)x(n-i)=\hat{w}^T(n)x(n)$$
2、计算误差信号:期望信号和滤波器输出之间的差值
$$e(n)=d(n)-\hat{y}(n)$$
3、计算输入向量的步长值
$$\mu(n)=\frac{1}{x^T(n)x(n)}$$
4、更新滤波器抽头权重,为下一次迭代做准备
$$\hat{w}(n+1)=\hat{w}(n)+\mu (n)e(n)x(n)$$
def nlms(x, d, N=4, mu=0.1): nIters = min(len(x), len(d)) - N u = np.zeros(N) w = np.zeros(N) e = np.zeros(nIters) for n in range(nIters): u[1:] = u[:-1] u[0] = x[n] e_n = d[n] - np.dot(u, w) w = w + mu * e_n * u / (np.dot(u, u) + 1e-3) e[n] = e_n return e
NLMS算法的每次迭代需要3N+1个乘法,仅比标准LMS算法多N个。考虑到所获得的稳定性和回波衰减增益,这是一个可接受的增加。有的时候会对NLMS进行改进,设$\mu(n)=\frac{\alpha}{\beta +x^T(n)x(n)}$,$0 <\alpha< 2$,$\beta $为一个较小的整数,防止输入数据矢量$x(n)$的内积过小使得$\mu(n)$过大而引起稳定性能下降,一般取0.0001。
MATLAB代码实现
这段是MATLAB官方提供的AEC代码。
当需要同时进行语音通信(或全双工传输)时,回声消除对于音频电话会议非常重要。在回声消除中,测得的麦克风信号$d(n)$包含两个信号:
-
近端语音信号
-
远端回声信号
目的是从麦克风信号中去除远端回声信号,从而仅发送近端语音信号。本示例包含一些声音片段,因此您可能现在要调整计算机的音量。
房间脉冲响应
首先,您需要对扬声器所在的扬声器到麦克风的信号路径的声学建模。使用长有限冲激响应滤波器来描述房间的特征。下面的代码生成一个随机的脉冲响应,该响应与会议室的显示相同。假设系统采样率为16000 Hz。
fs = 16000; M = fs / 2 + 1; frameSize = 2048; [B,A] = cheby2(4,20,[0.1 0.7]); impulseResponseGenerator = dsp.IIRFilter(' Numerator ',[zeros(1,6)B],... 'Denominator',A); FVT = fvtool(impulseResponseGenerator); %分析过滤器 FVT.Color = [1 1 1];
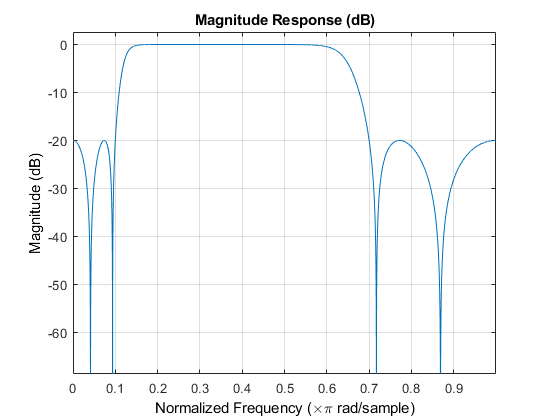
roomImpulseResponse = impulseResponseGenerator( ... (log(0.99*rand(1,M)+0.01).*sign(randn(1,M)).*exp(-0.002*(1:M)))'); roomImpulseResponse = roomImpulseResponse/norm(roomImpulseResponse)*4; room = dsp.FIRFilter('Numerator', roomImpulseResponse'); fig = figure; plot(0:1/fs:0.5, roomImpulseResponse); xlabel('Time (s)'); ylabel('Amplitude'); title('Room Impulse Response'); fig.Color = [1 1 1];

近端语音信号
电话会议系统的用户通常位于系统麦克风附近。这是麦克风上男性讲话的声音。
load nearspeech player = audioDeviceWriter('SupportVariableSizeInput', true, ... 'BufferSize', 512, 'SampleRate', fs); nearSpeechSrc = dsp.SignalSource('Signal',v,'SamplesPerFrame',frameSize); nearSpeechScope = dsp.TimeScope('SampleRate', fs, ... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll', ... 'YLimits', [-1.5 1.5], ... 'BufferLength', length(v), ... 'Title', 'Near-End Speech Signal', ... 'ShowGrid', true); % Stream processing loop while(~isDone(nearSpeechSrc)) % Extract the speech samples from the input signal nearSpeech = nearSpeechSrc(); % Send the speech samples to the output audio device player(nearSpeech); % Plot the signal nearSpeechScope(nearSpeech); end release(nearSpeechScope);

远端语音信号
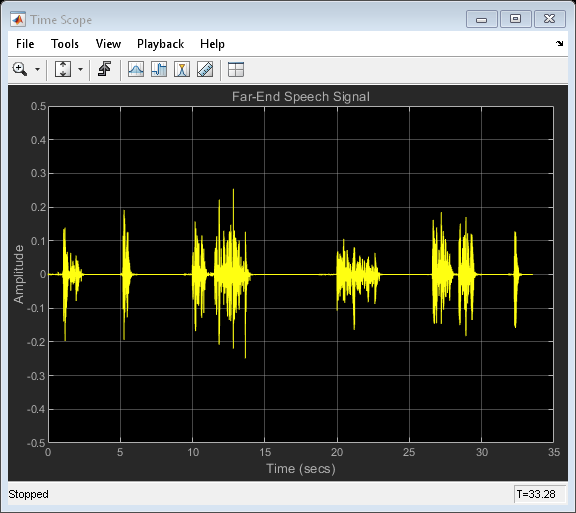
在电话会议系统中,语音从扬声器中传播出去,在房间里弹跳,然后被系统的麦克风拾取。聆听在没有近端语音的情况下在麦克风处拾起语音时的声音。
load farspeech farSpeechSrc = dsp.SignalSource('Signal',x,'SamplesPerFrame',frameSize); farSpeechSink = dsp.SignalSink; farSpeechScope = dsp.TimeScope('SampleRate', fs, ... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll', ... 'YLimits', [-0.5 0.5], ... 'BufferLength', length(x), ... 'Title', 'Far-End Speech Signal', ... 'ShowGrid', true); % Stream processing loop while(~isDone(farSpeechSrc)) % Extract the speech samples from the input signal farSpeech = farSpeechSrc(); % Add the room effect to the far-end speech signal farSpeechEcho = room(farSpeech); % Send the speech samples to the output audio device player(farSpeechEcho); % Plot the signal farSpeechScope(farSpeech); % Log the signal for further processing farSpeechSink(farSpeechEcho); end release(farSpeechScope);
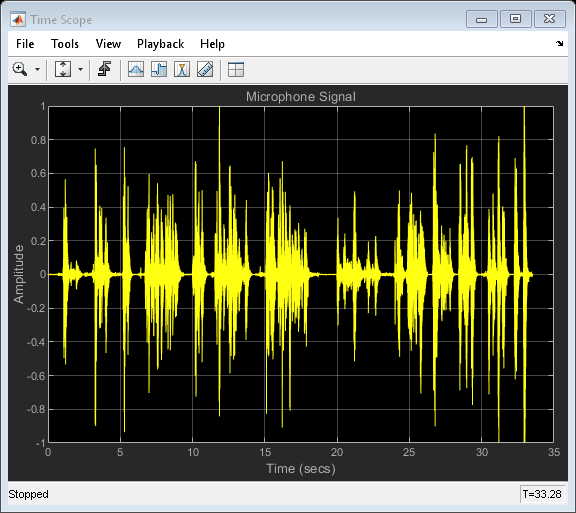
麦克风信号
麦克风处的信号既包含近端语音,也包含在整个房间中回声的远端语音。回声消除器的目的是消除远端语音,从而仅将近端语音发送回远端听众。
reset(nearSpeechSrc); farSpeechEchoSrc = dsp.SignalSource('Signal', farSpeechSink.Buffer, ... 'SamplesPerFrame', frameSize); micSink = dsp.SignalSink; micScope = dsp.TimeScope('SampleRate', fs,... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll',... 'YLimits', [-1 1], ... 'BufferLength', length(x), ... 'Title', 'Microphone Signal', ... 'ShowGrid', true); % Stream processing loop while(~isDone(farSpeechEchoSrc)) % Microphone signal = echoed far-end + near-end + noise micSignal = farSpeechEchoSrc() + nearSpeechSrc() + ... 0.001*randn(frameSize,1); % Send the speech samples to the output audio device player(micSignal); % Plot the signal micScope(micSignal); % Log the signal micSink(micSignal); end release(micScope);
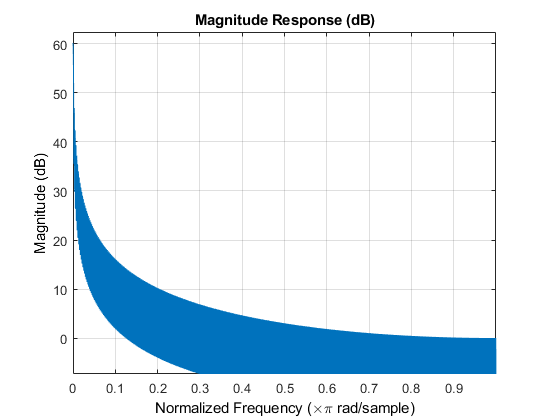
频域自适应滤波器(FDAF)
该示例中的算法是频域自适应滤波器(FDAF)。当待识别系统的脉冲响应较长时,此算法非常有用。FDAF使用快速卷积技术来计算输出信号和过滤器更新。该计算可在MATLAB®中快速执行。通过频点步长归一化,它还具有快速收敛性能。为滤波器选择一些初始参数,并查看远端语音在误差信号中的消除程度。
% Construct the Frequency-Domain Adaptive Filter echoCanceller = dsp.FrequencyDomainAdaptiveFilter('Length', 2048, ... 'StepSize', 0.025, ... 'InitialPower', 0.01, ... 'AveragingFactor', 0.98, ... 'Method', 'Unconstrained FDAF'); AECScope1 = dsp.TimeScope(4, fs, ... 'LayoutDimensions', [4,1], ... 'TimeSpan', 35, 'TimeSpanOverrunAction', 'Scroll', ... 'BufferLength', length(x)); AECScope1.ActiveDisplay = 1; AECScope1.ShowGrid = true; AECScope1.YLimits = [-1.5 1.5]; AECScope1.Title = 'Near-End Speech Signal'; AECScope1.ActiveDisplay = 2; AECScope1.ShowGrid = true; AECScope1.YLimits = [-1.5 1.5]; AECScope1.Title = 'Microphone Signal'; AECScope1.ActiveDisplay = 3; AECScope1.ShowGrid = true; AECScope1.YLimits = [-1.5 1.5]; AECScope1.Title = 'Output of Acoustic Echo Canceller mu=0.025'; AECScope1.ActiveDisplay = 4; AECScope1.ShowGrid = true; AECScope1.YLimits = [0 50]; AECScope1.YLabel = 'ERLE (dB)'; AECScope1.Title = 'Echo Return Loss Enhancement mu=0.025'; % Near-end speech signal release(nearSpeechSrc); nearSpeechSrc.SamplesPerFrame = frameSize; % Far-end speech signal release(farSpeechSrc); farSpeechSrc.SamplesPerFrame = frameSize; % Far-end speech signal echoed by the room release(farSpeechEchoSrc); farSpeechEchoSrc.SamplesPerFrame = frameSize;
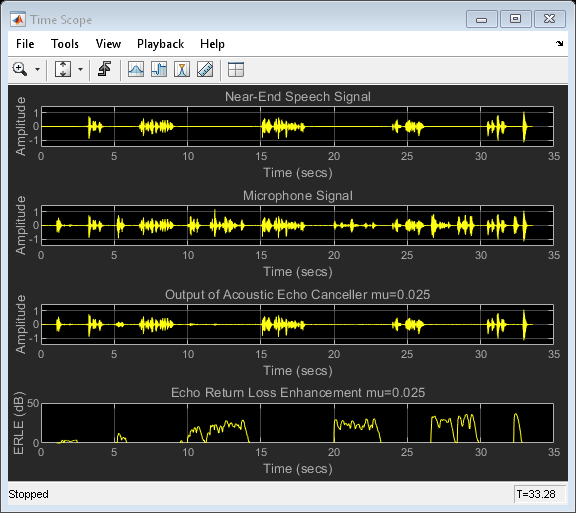
回波回波增强(ERLE)
由于您可以访问近端和远端语音信号,因此可以计算回声回波损耗增强(ERLE),这是对回声衰减量的平滑度量(以dB为单位)。从图中可以看出,在收敛周期结束时您获得了大约35 dB的ERLE。
diffAverager = dsp.FIRFilter('Numerator', ones(1,1024)); farEchoAverager = clone(diffAverager); setfilter(FVT,diffAverager); micSrc = dsp.SignalSource('Signal', micSink.Buffer, ... 'SamplesPerFrame', frameSize); % Stream processing loop - adaptive filter step size = 0.025 while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Send the speech samples to the output audio device player(e); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./ farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope1(nearSpeech, micSignal, e, erledB); end release(AECScope1);
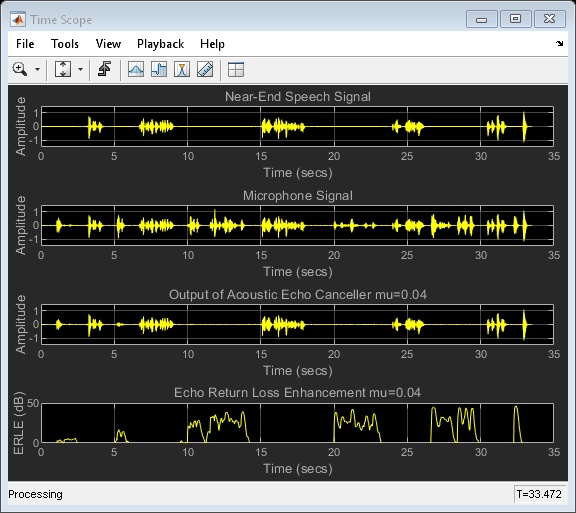
不同步长值的影响
为了获得更快的收敛速度,可以尝试使用更大的步长值。但是,这种增加会产生另一种效果:当近端扬声器讲话时,自适应滤波器“调整不当”。聆听您选择的步长比以前大60%时会发生什么。
% Change the step size value in FDAF reset(echoCanceller); echoCanceller.StepSize = 0.04; AECScope2 = clone(AECScope1); AECScope2.ActiveDisplay = 3; AECScope2.Title = 'Output of Acoustic Echo Canceller mu=0.04'; AECScope2.ActiveDisplay = 4; AECScope2.Title = 'Echo Return Loss Enhancement mu=0.04'; reset(nearSpeechSrc); reset(farSpeechSrc); reset(farSpeechEchoSrc); reset(micSrc); reset(diffAverager); reset(farEchoAverager); % Stream processing loop - adaptive filter step size = 0.04 while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Send the speech samples to the output audio device player(e); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./ farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope2(nearSpeech, micSignal, e, erledB); end release(nearSpeechSrc); release(farSpeechSrc); release(farSpeechEchoSrc); release(micSrc); release(diffAverager); release(farEchoAverager); release(echoCanceller); release(AECScope2);

回声回波损耗增强比较
步长较大时,由于近端语音引入的错误调整,导致ERLE性能不佳。为了解决此性能难题,声学回声消除器包括一种检测方案,可告知何时存在近端语音并在这些时间段内降低步长值。没有这种检测方案,从ERLE图可以看出,具有较大步长的系统的性能不如前者。
使用分区减少延迟
对于长脉冲响应,传统FDAF在数值上比时域自适应滤波更有效,但是由于输入帧大小必须是指定滤波器长度的倍数,因此它具有高延迟。对于许多实际应用程序来说,这可能是不可接受的。通过使用分区的FDAF可以减少延迟,该方法将过滤器脉冲响应分为较短的部分,将FDAF应用于每个部分,然后合并中间结果。在这种情况下,帧大小必须是分区(块)长度的倍数,从而大大减少了长脉冲响应的等待时间。
% Reduce the frame size from 2048 to 256 frameSize = 256; nearSpeechSrc.SamplesPerFrame = frameSize; farSpeechSrc.SamplesPerFrame = frameSize; farSpeechEchoSrc.SamplesPerFrame = frameSize; micSrc.SamplesPerFrame = frameSize; % Switch the echo canceller to Partitioned constrained FDAF echoCanceller.Method = 'Partitioned constrained FDAF'; % Set the block length to frameSize echoCanceller.BlockLength = frameSize; % Stream processing loop while(~isDone(nearSpeechSrc)) nearSpeech = nearSpeechSrc(); farSpeech = farSpeechSrc(); farSpeechEcho = farSpeechEchoSrc(); micSignal = micSrc(); % Apply FDAF [y,e] = echoCanceller(farSpeech, micSignal); % Send the speech samples to the output audio device player(e); % Compute ERLE erle = diffAverager((e-nearSpeech).^2)./ farEchoAverager(farSpeechEcho.^2); erledB = -10*log10(erle); % Plot near-end, far-end, microphone, AEC output and ERLE AECScope2(nearSpeech, micSignal, e, erledB); end
开源的音频处理库
基于码激励线性预测编码的 Speex 平台来进行回音消除,两者都是将多媒体通信的模块集成在浏览器中,彻底屏蔽掉其它方案存在的操作系统和底层硬件间的差异,能够用于所有操作系统和浏览器。
专为语音设计的无专利音频压缩格式。Speex项目旨在通过提供免费替代昂贵的专有语音编解码器的方法来降低语音应用程序的进入门槛。此外,Speex非常适合Internet应用程序,并提供了大多数其他编解码器中没有的有用功能。
Speex基于CELP ,旨在以2到44 kbps的比特率压缩语音。Speex的一些功能包括:
- 同一位流中的窄带(8 kHz),宽带(16 kHz)和超宽带(32 kHz)压缩
- 强度立体声编码
- 丢包隐藏
- 可变比特率操作(VBR)
- 语音活动检测(VAD)
- 不连续传输(DTX)
- 定点端口
- 回声消除器
- 噪声抑制
Speex编解码器已被Opus淘汰。它会继续可用,但是由于Opus在各个方面都比Speex更好,因此建议用户切换Opus,
Opus是一款完全开放,免版税,功能广泛的音频编解码器。Opus在互联网上的交互式语音和音乐传输方面无可匹敌,但也适用于存储和流媒体应用程序。
Opus可以处理各种音频应用程序,包括IP语音,视频会议,游戏内聊天,甚至是远程现场音乐表演。它可以从低比特率的窄带语音扩展到高质量的立体声音乐。支持的功能有:
- 比特率从6 kb / s到510 kb / s
- 采样率从8 kHz(窄带)到48 kHz(全带)
- 帧大小从2.5毫秒到60毫秒
- 支持恒定比特率(CBR)和可变比特率(VBR)
- 音频带宽从窄带到全带
- 支持语音和音乐
- 支持单声道和立体声
- 最多支持255个通道(多流帧)
- 动态可调的比特率,音频带宽和帧大小
- 良好的丢失健壮性和数据包丢失隐藏(PLC)
- 浮点和定点实现
WebRTC(实时通信):谷歌公司在 2010 年收购了 Global IP Solutions 后逐步开源的音视频解决方案 WebRTC。该方案中的 AEC 模块是实现自适应滤波算法的优秀平台,它集成了声学回声消除所需要的所有结构。用户可以通过简单API为浏览器和移动应用程序提供实时通信(RTC)功能
回声消除需要时候的技术:双讲检测技术(语音活动检测,区分希腊佛中是否存在双端讲话)、自适应滤波技术(主要性能指标:跟踪性能、抗冲激性、鲁棒性和计算复杂性)、后处理(消除自适应滤波器的输出误差)
参考
《基于自适应滤波器的声学回声消除研究——冯江浩》
MATLAB官网audio_Examples_Acoustic Echo Cancellation
Hand Book of Speech Enhancement and Recognition
黄翔. 基于麦克风阵列的回声抵消系统研究[D]. 湖北工业大学, 2018.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号