基于深度学习的图像识别模型发展
简介
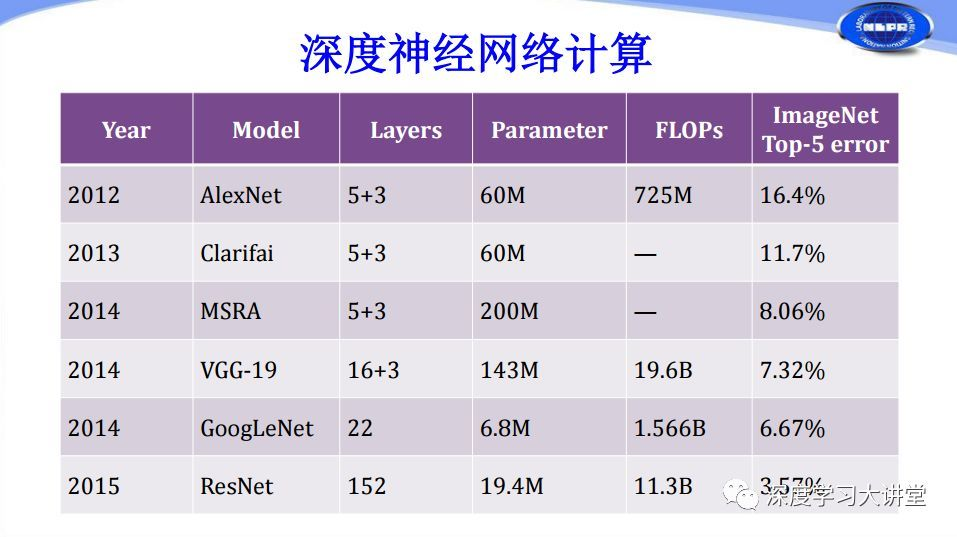
AlexNet:(2012)主要贡献扩展 LeNet 的深度,并应用一些 ReLU、Dropout 等技巧。AlexNet 有 5 个卷积层和 3 个最大池化层,它可分为上下两个完全相同的分支,这两个分支在第三个卷积层和全连接层上可以相互交换信息。它是开启了卷积神经网络做图像处理的先河。
VGG-Net:2014年。该网络使用3×3卷积核的卷积层堆叠并交替最大池化层,有两个4096维的全连接层,然后是softmax分类器。16和19分别代表网络中权重层的数量。相比于 AlexNet 有更小的卷积核和更深的层级。VGG 最大的问题就在于参数数量,VGG-19 基本上是参数量最多的卷积网络架构。
ResNet:2015年。该网络使用残差模块来组成更复杂的网络(网络中的网络),使用标准随机梯度下降法训练。与VGG相比,ResNet更深,但是由于使用全局平均池操作而不是全连接密集层,所以模型的尺寸更小。
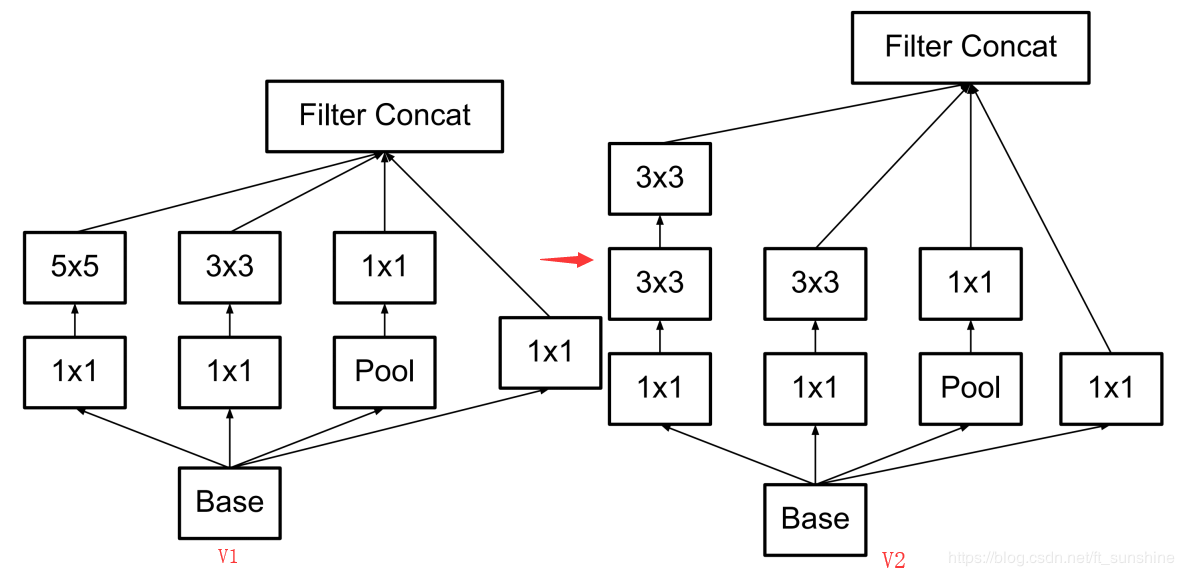
Inception:2015年。它没有如同 VGG-Net 那样大量使用全连接网络,因此参数量非常小。增加了网络的深度的同时也增加了网络的宽度,该网络使用不同大小的卷积核提取特征,同时计算1×1、3×3、5×5卷积,然后分别把他们的结果concatenate(不同卷积操作输出的feature map的大小要相同),然后将这些滤波器的输出沿通道维度堆叠并传递到下一层。因为 1*1、3*3 或 5*5 等不同的卷积运算与池化操作可以获得输入图像的不同信息,并行处理这些运算并结合所有结果将获得更好的图像表征。问题是计算量太大。
Inception v1:论文:Going deeper with convolutions,
Inception v2
Inception v3
Inception v4
Inception-v4编写于2016年
Inception-ResNet
Xception:2016年。该网络是Inception网络的扩展,使用了深度可分离卷积运算。其参数数量与Inception-v3相同,由于更高效地利用模型参数,该网络性能获得提升并在大型图像分类数据集胜过Inception-v3。
AlexNet
《ImageNet Classification with Deep Convolutional Neural Networks》
AlexNet:2012年产生,将错误率从原来的25%降到16%,
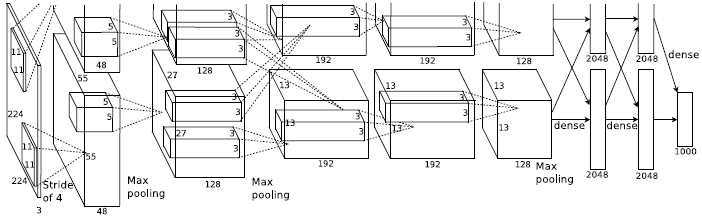
这个网络由上下两部分组成。输入的图像会经过5层卷积层(依次是11*11卷积、5*5卷积,3个3*3卷积),有些卷积层后面还使用了池化层。5层卷积之后连接了3层全连接层。由于该网络是由Alex 设计完成的,所以现在一般将此网络简称为AlexNet 。
AlexNet的成功得益于以下几个方面:
- 训练了较深层的卷积神经网络。
- ImageNet 提供了大量训练样本,此外还使用了数据增强技术,因此神经网络的过拟合现象不严重。
- 使用了dropout 等技术,进一步降低了过拟合。
VGG
《Very Deep Convolutional Networks for Large-Scale Image Recognition》
详解:一文读懂VGG网络
homepage:Visual Geometry Group Home Page
2014年产生,将错误率降到了7%,在原始的论文中,作者共训练了6 个网络,分别命名为VGG-A 、VGG-A-LRN 、VGG-B 、VGG-C 、VGG-D 幸日VGG-E ,在实际应用中,由于VGG-D和VGG-E效果最好,而且VGG-D有16层,VGG-E有19层,所以他们又被分别简称为VGG16和VGG19。VGG19 比VGG16 准确率更高,但相应地计算量更大。

简单解释表中符号表示的含义。conv3-512 表示使用了3 × 3 的卷积,卷积之后的通道数为512 。而conv3-256 表示使用了3 × 3 的卷积,通道数为256,依此类推。
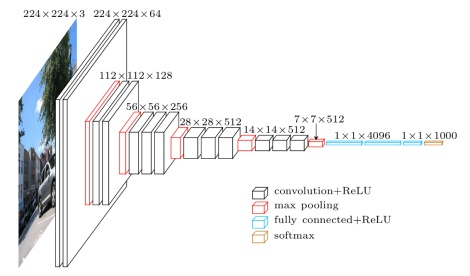
vgg的最主要的思想就是增加网络深度,减小卷积核尺寸(3*3)。减少卷积核的好处就是可以减少参数和计算量,比如,论文中举了一个例子,把一个7*7的卷积层替换成3个3*3的卷积层,参数上可以减少81%,因为3*3*3 = 27, 7*7 = 49.
文中还提到了1*1的卷积层,比如说下图的configC的conv1层,这样做的目的主要是增加卷积层的非线性表达,同时影响卷积层的感受野,这个思想在google的inception系列网络中有了很好的应用,具体可以参考Network in Network这篇论文。
vgg的参数还是很多的,可以看出vgg-16有138百万个参数。
incception系列
[v1] Going Deeper with Convolutions, 6.67% test error
[v2] Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, 4.8% test error
[v3] Rethinking the Inception Architecture for Computer Vision, 3.5% test error
[v4] Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning, 3.08% test error
GoogLeNet:2014年产生,将错误率降到了6%,GoogLeNet的创新在于它提出了一种“Inception”结构,它把原来的单个节点又拆成一个神经网络,形成了“网中网”,
在 Inception 出现之前,大部分流行 CNN 仅仅是把卷积层堆叠得越来越多,使网络越来越深,以此希望能够得到更好的性能。
inception-v1
这个就是GoogleNet,本文的主要工作,就是研究怎么设计一种网络,更加有效地利用计算资源。
- 由于信息位置的巨大差异,为卷积操作选择合适的卷积核大小就比较困难。信息分布更全局性的图像偏好较大的卷积核,信息分布比较局部的图像偏好较小的卷积核。
- 非常深的网络意味着巨量的参数,同时更容易过拟合。将梯度更新传输到整个网络是很困难的。
- 简单地堆叠较大的卷积层非常消耗计算资源。因此inception-v1并没有在网络的深度上做文章而是在网络的宽度上。
文章认为解决上述两个缺点的根本方法是将全连接甚至一般的卷积都转化为稀疏连接。一方面现实生物神经系统的连接也是稀疏的,另一方面有文献表明:对于大规模稀疏的神经网络,可以通过分析激活值的统计特性和对高度相关的输出进行聚类来逐层构建出一个最优网络。这点表明臃肿的稀疏网络可能被不失性能地简化。
早些的时候,为了打破网络对称性和提高学习能力,传统的网络都使用了随机稀疏连接。但是,计算机软硬件对非均匀稀疏数据的计算效率很差,所以在AlexNet中又重新启用了全连接层,目的是为了更好地优化并行运算。
所以,现在的问题是有没有一种方法,既能保持网络结构的稀疏性,又能利用密集矩阵的高计算性能。大量的文献表明可以将稀疏矩阵聚类为较为密集的子矩阵来提高计算性能,据此论文提出了名为Inception 的结构来实现此目的。
inception module
主要就是把稀疏结构近似成几个密集的子矩阵,从而在减少参数的同时,更加有效地利用计算资源。
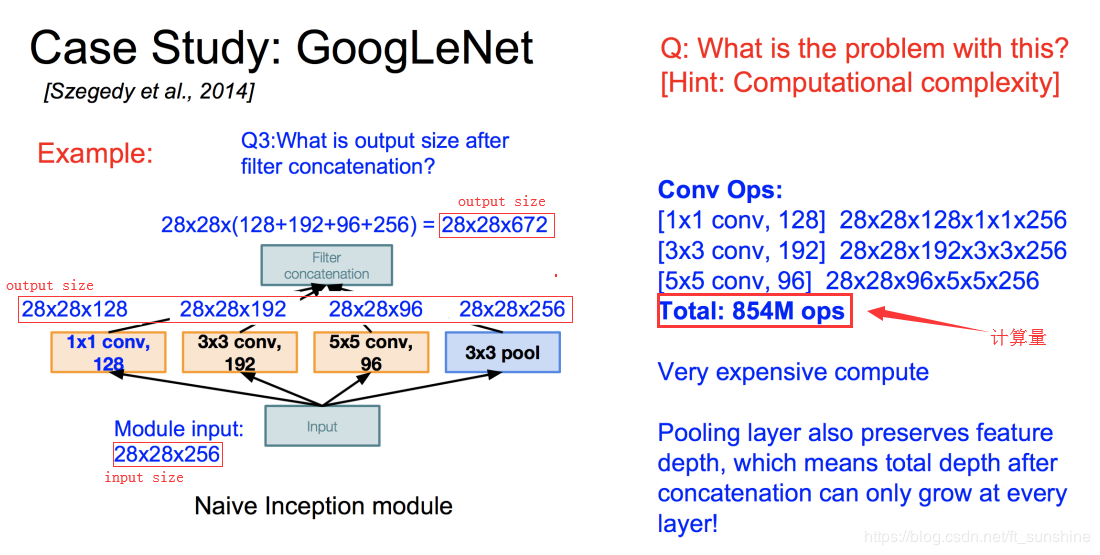
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
- 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
- 文章说很多地方都表明pooling挺有效,所以Inception里面也嵌入了。
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也更大了,因此随着层数的增加,3x3和5x5卷积的比例也要增加。
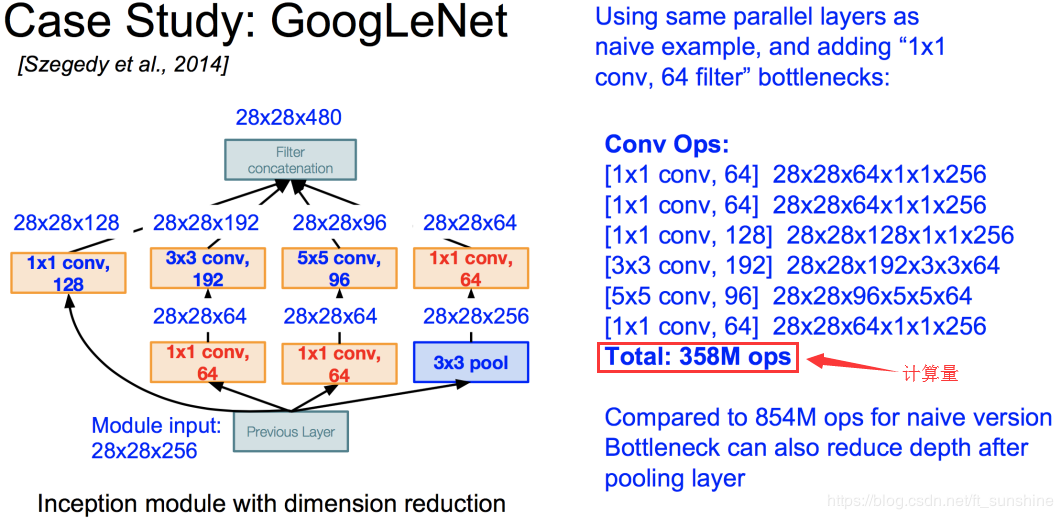
但是,这种naive的inception 并不实用,因为不同的feature map拼到一起之后传递到下一层inception 的5*5卷积层,计算量仍然是非常巨大的,为了降低算力成本,作者在 3x3 和 5x5 卷积层之前添加额外的1*1的卷积层(bottleneck)做降维操作,下面是改进之后的inception。注意,1x1 卷积是在最大池化层之后。
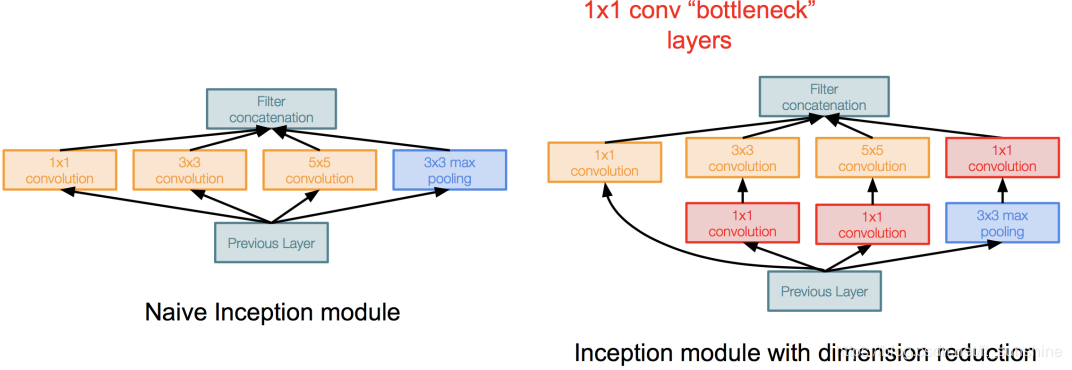
降维Inception模块
此时这一个Inception module的计算量为358M ops,相比之前的854M ops,使用“bottleneck”的Inception module的计算量降低了一半多!
到这里,Inception module的结构就介绍完了,而GoogLeNet的架构就是多个Inception module一层一层地stack(堆叠)出来的,下面是GoogLeNet的整体架构的介绍。
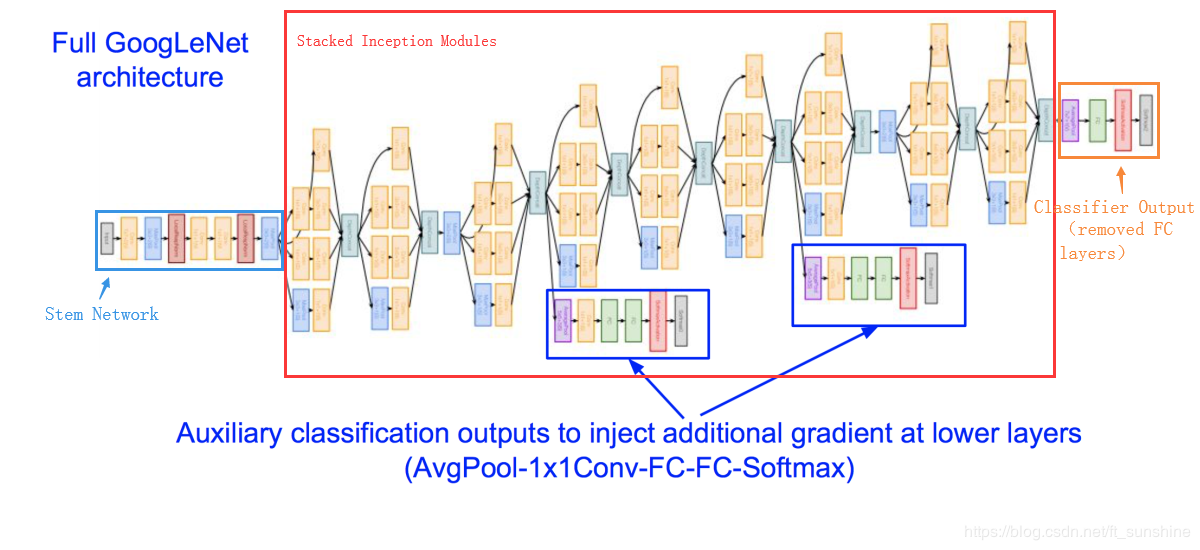
注:浅蓝色部分Stem Network是一些初始卷积,深蓝色部分有三个辅助分类器,为什么要用三个classifier呢?结合GoogLeNet的论文,我个人认为有以下几点原因:
- 一般认为深度越深,越有可能产生梯度消失的问题。这里深度不同的三个classifier可以有效缓解梯度消失问题,即浅层的classifier的输出也执行 softmax 操作,然后在同样的标签上计算辅助损失。总损失即辅助损失和真实损失的加权和。该论文中对每个辅助损失使用的权重值是 0.3。可见辅助分类器也可以回传误差,缓解梯度消失问题。辅助损失只是用于训练,在推断过程中并不使用。
- CNN深度越深的层,提取的特征语义信息越丰富,深度越浅的层提取的特征更基础,包含更多的位置信息,所以并不是深度越深的层提取的特征一定好于较浅层提取的特征。这里在不同深度的层上面都加了一个output layer,可以做一个模型的ensemble,这可能会提升模型的效果。
Network in Network
NIN有两个特性,是它对CNN的贡献:
- MLP代替GLM
- Global Average Pooling
MLPconv
普通的卷积可以看做输入feature map 和kernel 矩阵相乘的过程,是一个线性变换。MLP是指多层感知机,由于是多层的,f(x) = w*g(x)+b, g(x) = w*x +b,输出f和输入x自然是非线性关系,mlpconv的意思就是用mlp代替普通卷积,可以增加网络的抽象表达能力。
所以,基于如上,可以认为,在抽特征的时候直接做了非线性变换,可以有效的对图像特征进行更好的抽象。
从而,Linear convolution layer就变成了Mlpconv layer。
值得一提的是,Mlpconv相当于在激活函数后面,再添加一个1×1的卷积层。
当然,1*1卷积层在本文中的最重要的作用还是进行降维。
Global Average Pooling
Global Average Pooling的做法是将全连接层去掉。
全连接层的存在有两个缺点:
全连接层是传统的神经网络形式,使用了全连接层以为着卷积层只是作为特征提取器来提取图像的特征,而全连接层是不可解释的,从而CNN也不可解释了
全连接层中的参数往往占据CNN整个网络参数的一大部分,从而使用全连接层容易导致过拟合。
而Global Average Pooling则是在最后一层,将卷积层设为与类别数目一致,然后全局pooling,从而输出类别个数个结果。
但是本文中,在average pooling 后面还跟了一个linear layer,加这个层主要是为了方便起见,能够更容易扩展到其他的数据集上。
做后的结构如图所示:
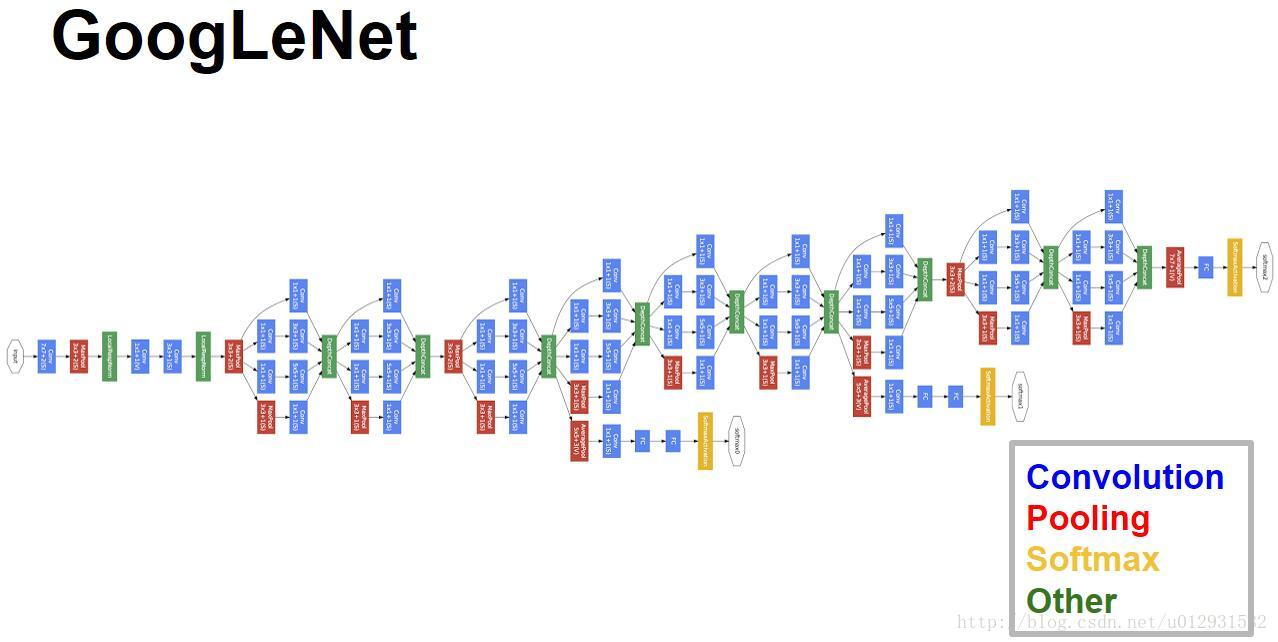
网络在训练的时候还加了两个额外的分类器,目的是为了防止梯度消失,最后测试的时候可以把这两个分类器去掉。
最后的参数相比于alexnet少了12倍,相比于vgg-16来说少了3倍。
值得一提的是, GoogLeNet 又被称为Inception Vl 模型, Google 又对该模型做了后续研究,相继提出了Inception V2, Inception V3, Inception V 4模型,每一代模型的性能都高提升。Inception v2 和 Inception v3 来自同一篇论文《Rethinking the Inception Architecture for Computer Vision》,作者提出了一系列能增加准确度和减少计算复杂度的修正方法。
inception-v2
问题:
- 减少特征的表征性瓶颈。直观上来说,当卷积不会大幅度改变输入维度时,神经网络可能会执行地更好。过多地减少维度可能会造成信息的损失,这也称为「表征性瓶颈」。
- 使用更优秀的因子分解方法,卷积才能在计算复杂度上更加高效。
解决方案:
- 将7*7和 5×5 的卷积分解为两个 3×3 的卷积运算以提升计算速度。尽管这有点违反直觉,但一个 5×5 的卷积在计算成本上是一个 3×3 卷积的 2.78 倍。所以叠加两个 3×3 卷积实际上在性能上会有所提升
- 在 Inception-V1的基础上增加了 Batch Normalization
主要贡献:提出了batch normalization,主要在于加快训练速度。数据归一化方法很简单,就是要让数据具有0均值和1方差
网络训练的过程参数不断的改变导致后续每一层输入的的分布也发生改变,而学习的过程又要使每一层适应输入的分布,因此我们不得不降低学习率、小心地初始化。作者将分布发生变化称之为internal covariate shift。
关于BN层,这一篇博客讲得很好,http://blog.csdn.net/app_12062011/article/details/57083447我在这里转一下。
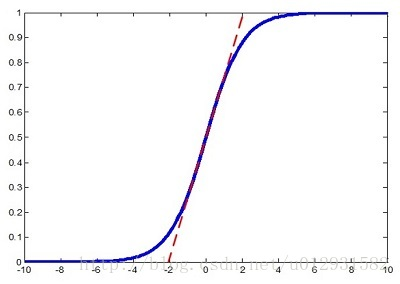
但是作者又说如果简单的这么干,会降低层的表达能力。比如下图,在使用sigmoid激活函数的时候,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。为此,作者又为BN增加了2个参数,
用来保持模型的表达能力把BN放在激活函数之前,这是因为Wx+b具有更加一致和非稀疏的分布。
inception-v3
- n∗n的卷积核都可以通过1∗n一维卷积后接n∗1一维卷积来代替。例如,一个 3×3 的卷积等价于首先执行一个 1×3 的卷积再执行一个 3×1 的卷积。他们还发现这种方法在成本上要比单个 3×3 的卷积降低 33%,这种非对称的卷积结构拆分,节省了大量的参数,其结果对比将一个大卷积核拆分为几个相同的小卷积核 ,效果更明显。这一结构如下图所示:
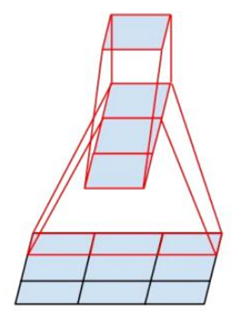
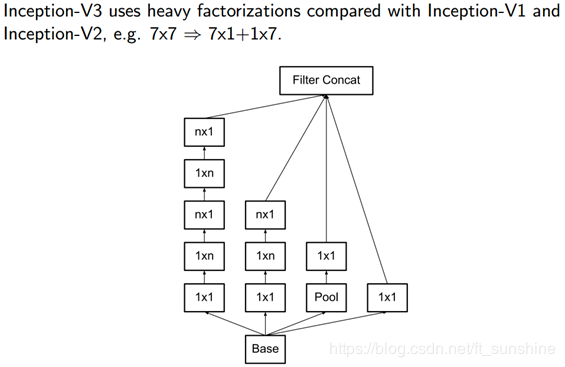
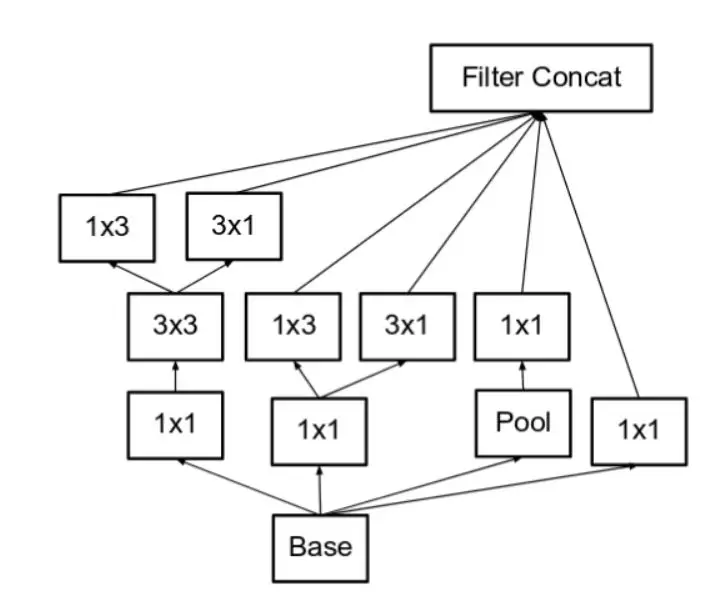
此处如果 n=3,则与上一张图像一致。最左侧的 5x5 卷积可被表示为两个 3x3 卷积,它们又可以被表示为 1x3 和 3x1 卷积。
本文的主要目的是研究如何在增加网络规模的同时,能够保证计算的高效率。
Rethinking这篇论文中提出了一些CNN调参的经验型规则,暂列如下:
- 避免特征表征的瓶颈。特征表征就是指图像在CNN某层的激活值,特征表征的大小在CNN中应该是缓慢的减小的。
- 高维的特征更容易处理,在高维特征上训练更快,更容易收敛
- 低维嵌入空间上进行空间汇聚,损失并不是很大。这个的解释是相邻的神经单元之间具有很强的相关性,信息具有冗余。
- 平衡的网络的深度和宽度。宽度和深度适宜的话可以让网络应用到分布式上时具有比较平衡的computational budget。
更小的卷积核
Inception Net v3 整合了前面 Inception v2 中提到的所有升级,还使用了:
-
RMSProp 优化器;
-
Factorized 7x7 卷积;
-
辅助分类器使用了 BatchNorm;
-
标签平滑(添加到损失公式的一种正则化项,旨在阻止网络对某一类别过分自信,即阻止过拟合)。
简而言之,就是将尺寸比较大的卷积,变成一系列3×3的卷积的叠加,这样既具有相同的视野,还具有更少的参数。
实验表明,这样做不会导致性能的损失。
Grid Size Reduction
Grid就是图像在某一层的激活值,即feature_map,一般情况下,如果想让图像缩小,可以有如下两种方式:
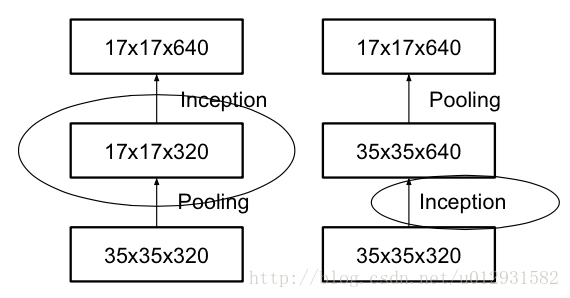
右图是正常的缩小,但计算量很大。左图先pooling会导致特征表征遇到瓶颈,违反上面所说的第一个规则,为了同时达到不违反规则且降低计算量的作用,将网络改为下图:
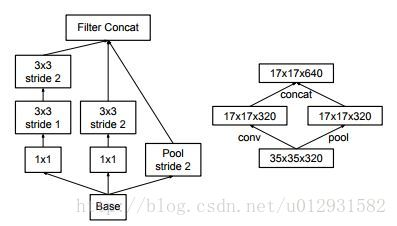
结构如左图表示,左边两个代表的是右图中的左边分支。
label smoothing
除了上述的模型结构的改进以外,Rethinking那篇论文还改进了目标函数。
原来的目标函数,在单类情况下,如果某一类概率接近1,其他的概率接近0,那么会导致交叉熵取log后变得很大很大。从而导致两个问题:
- 过拟合
- 导致样本属于某个类别的概率非常的大,模型太过于自信自己的判断。
所以,使用了一种平滑方法,可以使得类别概率之间的差别没有那么大.
Inception v4 和 Inception -ResNet 在同一篇论文《Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning》中介绍。为清晰起见,我们分成两个部分来介绍。
inception-v4:Inception with skip connections
论文:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
问题:某些模块有不必要的复杂性。我们应该添加更多一致的模块来提高性能。
方法:Inception v4 的 stem 被修改了。这里的 stem 参考了在引入 Inception 块之前执行的初始运算集。
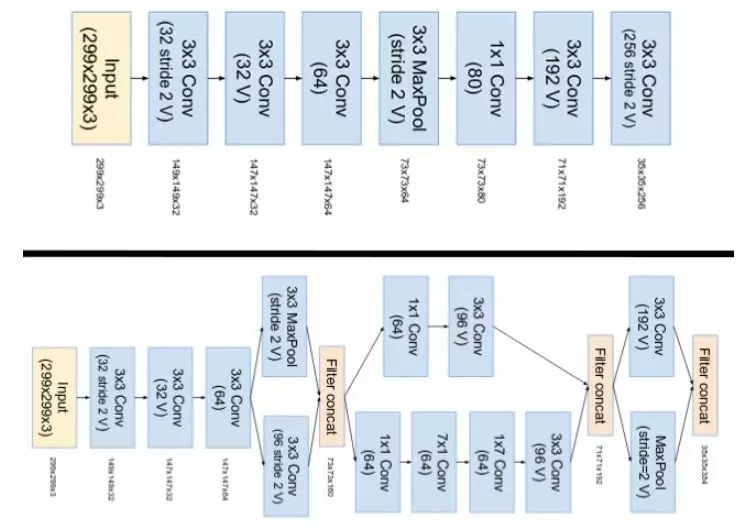
图上部是 Inception-ResNet v1 的 stem。图下部是 Inception v4 和 Inception-ResNet v2 的 stem
它们有三个主要的 Inception 模块,称为 A、B 和 C(和 Inception v2 不同,这些模块确实被命名为 A、B 和 C)。它们看起来和 Inception v2(或 v3)变体非常相似。
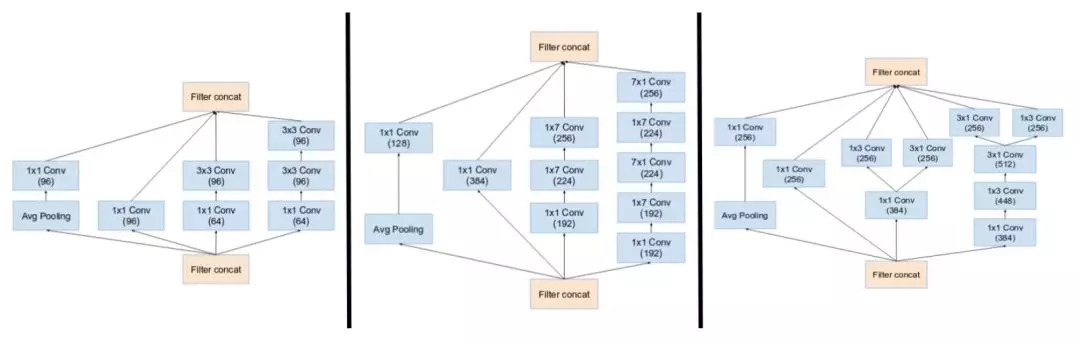
Inception v4 引入了专用的「缩减块」(reduction block),它被用于改变网格的宽度和高度。早期的版本并没有明确使用缩减块,但也实现了其功能。
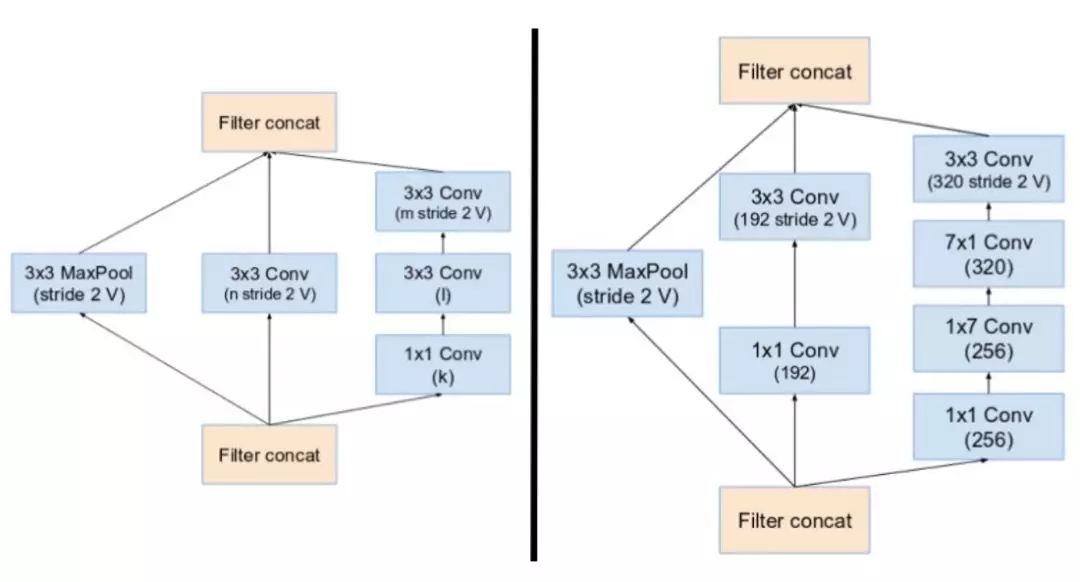
缩减块 A(从 35x35 到 17x17 的尺寸缩减)和缩减块 B(从 17x17 到 8x8 的尺寸缩减)。这里参考了论文中的相同超参数设置(V,I,k)。
inception-v4 是通过提出了更多新的inception module扩展网络结构,能够达到和inception-resnet-v2相媲美的效果,这个有时间再研究一下。
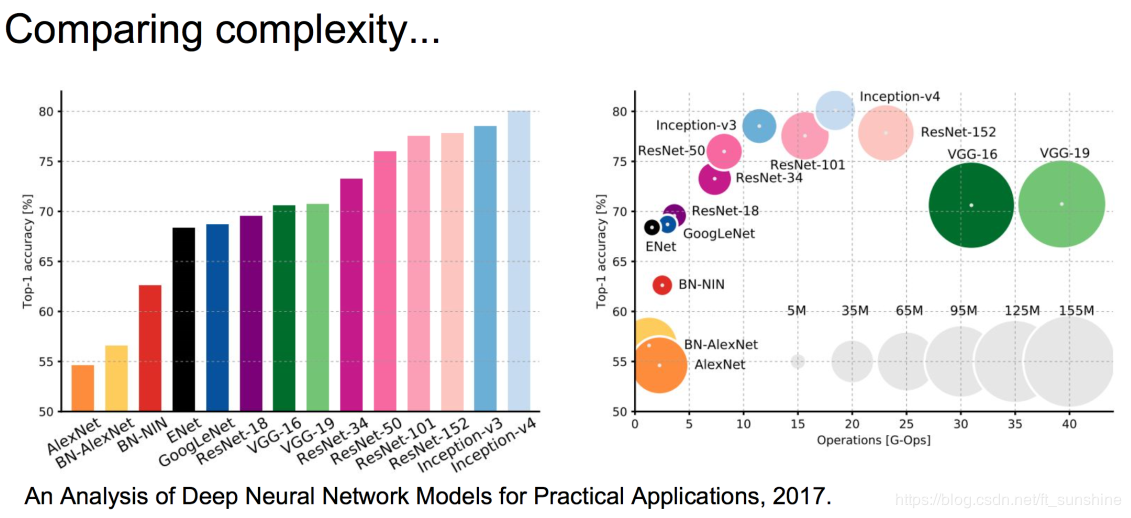
网络的性能分析图
Inception-ResNet v1 和 v2
受 ResNet 的优越性能启发,研究者提出了一种混合 inception 模块。Inception ResNet 有两个子版本:v1 和 v2。在我们分析其显著特征之前,先看看这两个子版本之间的微小差异。
-
Inception-ResNet v1 的计算成本和 Inception v3 的接近
-
Inception-ResNetv2 的计算成本和 Inception v4 的接近
-
它们有不同的 stem,正如 Inception v4 部分所展示的
-
两个子版本都有相同的模块 A、B、C 和缩减块结构。唯一的不同在于超参数设置。在这一部分,我们将聚焦于结构,并参考论文中的相同超参数设置(图像是关于 Inception-ResNet v1 的)
问题:引入残差连接,它将 inception 模块的卷积运算输出添加到输入上。
方法:为了使残差加运算可行,卷积之后的输入和输出必须有相同的维度。因此,我们在初始卷积之后使用 1x1 卷积来匹配深度(深度在卷积之后会增加)。
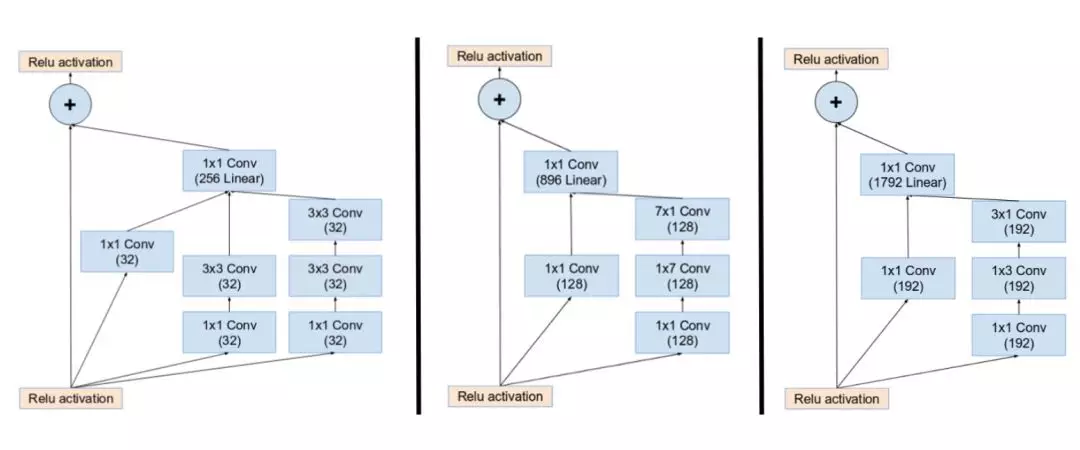
Inception ResNet 中的 Inception 模块 A、B、C。注意池化层被残差连接所替代,并在残差加运算之前有额外的 1x1 卷积。
主要 inception 模块的池化运算由残差连接替代。然而,你仍然可以在缩减块中找到这些运算。缩减块 A 和 Inception v4 中的缩减块相同。
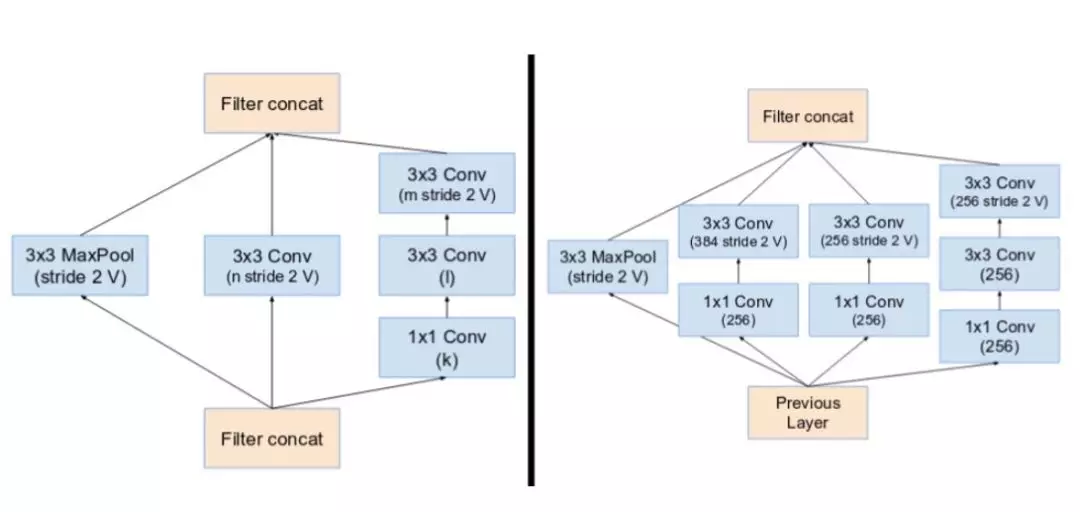
(左起)缩减块 A(从 35x35 到 17x17 的尺寸缩减)和缩减块 B(从 17x17 到 8x8 的尺寸缩减)。这里参考了论文中的相同超参数设置(V,I,K)
如果卷积核的数量超过 1000,则网络架构更深层的残差单元将导致网络崩溃。因此,为了增加稳定性,作者通过 0.1 到 0.3 的比例缩放残差激活值。
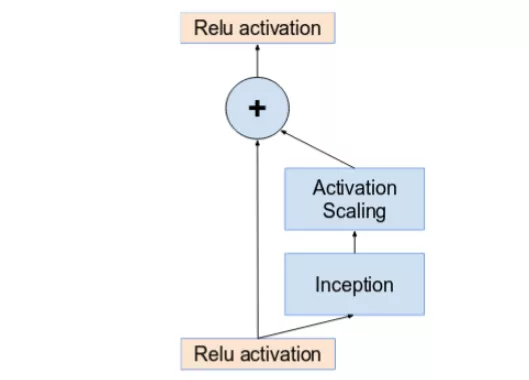
激活值通过一个常数进行比例缩放,以防止网络崩溃。
-
原始论文并没有在求和之后使用批归一化,以在单个 GPU 上训练模型(在单个 GPU 上拟合整个模型)。
-
研究发现 Inception-ResNet 模型可以在更少的 epoch 内达到更高的准确率。
-
Inception v4 和 Inception-ResNet 的网络完整架构如下图所示:
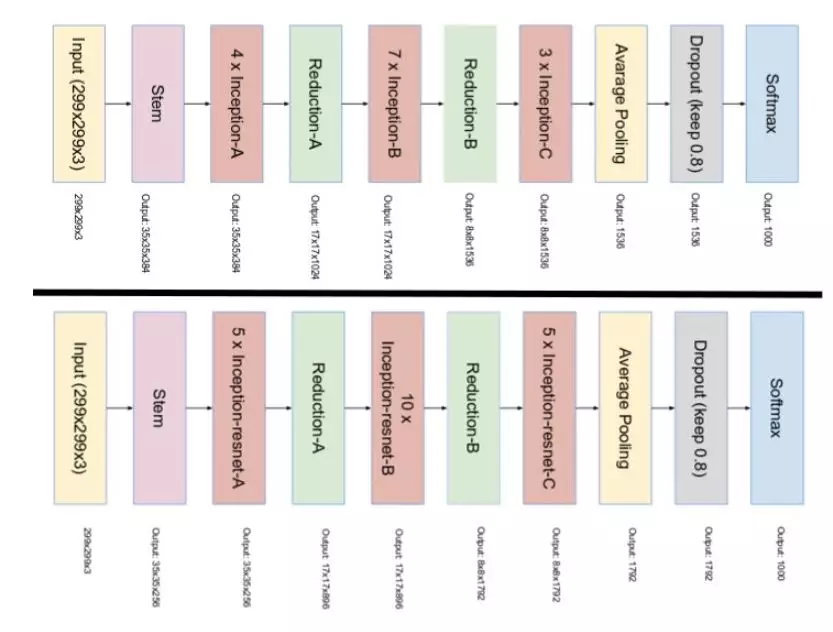
这篇论文里,作者借鉴了resnet的残差网络的思想,将其应用到了inception-v3当中,结构如下:
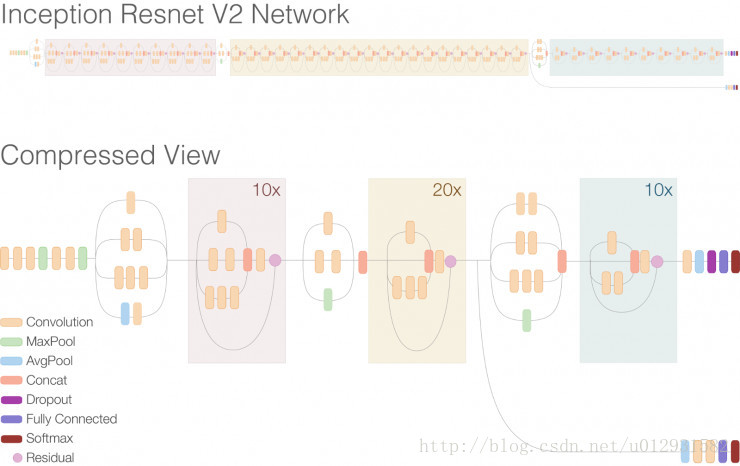
Xception
Xception 是 Google 继 Inception 后提出的对 Inception-v3 的另一种改进。
作者认为,通道之间的相关性 与 空间相关性 最好要分开处理。采用 Separable Convolution(极致的 Inception 模块)来替换原来 Inception-v3中的卷积操作。
在 Inception 中,特征可以通过 1×1卷积,3×3卷积,5×5 卷积,pooling 等进行提取,Inception 结构将特征类型的选择留给网络自己训练,也就是将一个输入同时输给几种提取特征方式,然后做 concat 。Inception-v3的结构图如下:
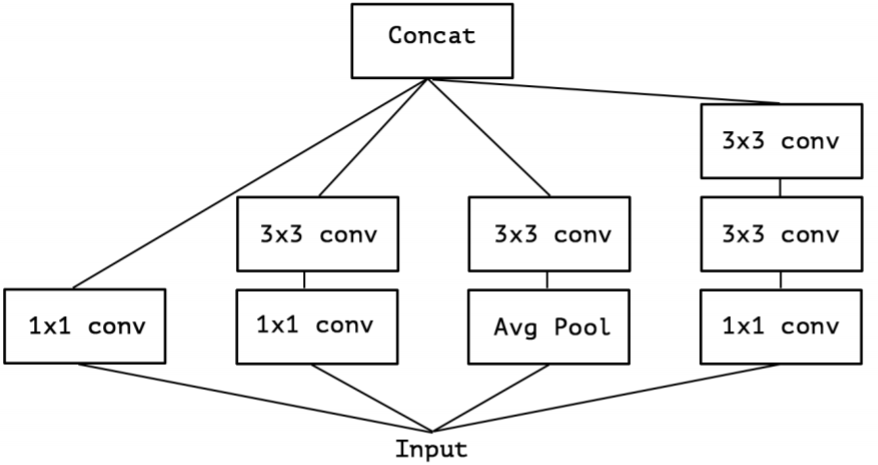
对 Inception-v3 进行简化,去除 Inception-v3 中的 avg pool 后,输入的下一步操作就都是 1×1卷积:
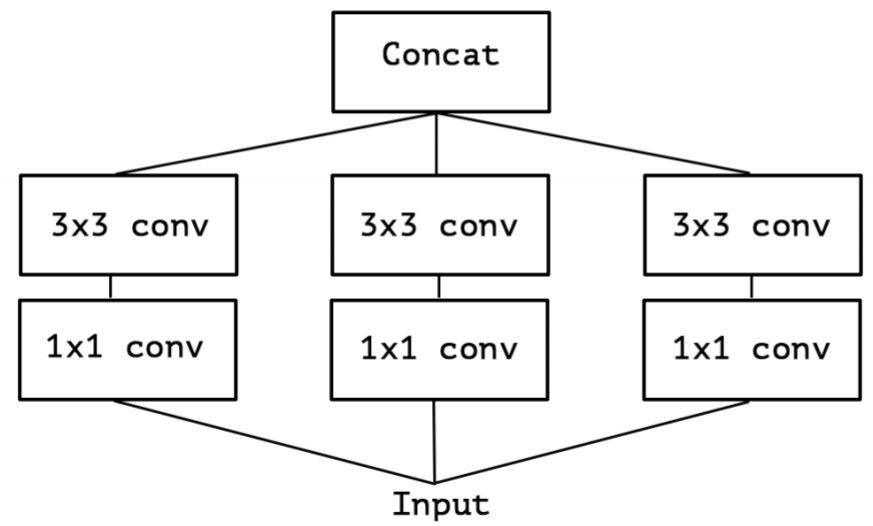
提取 1×11×11×1 卷积的公共部分:
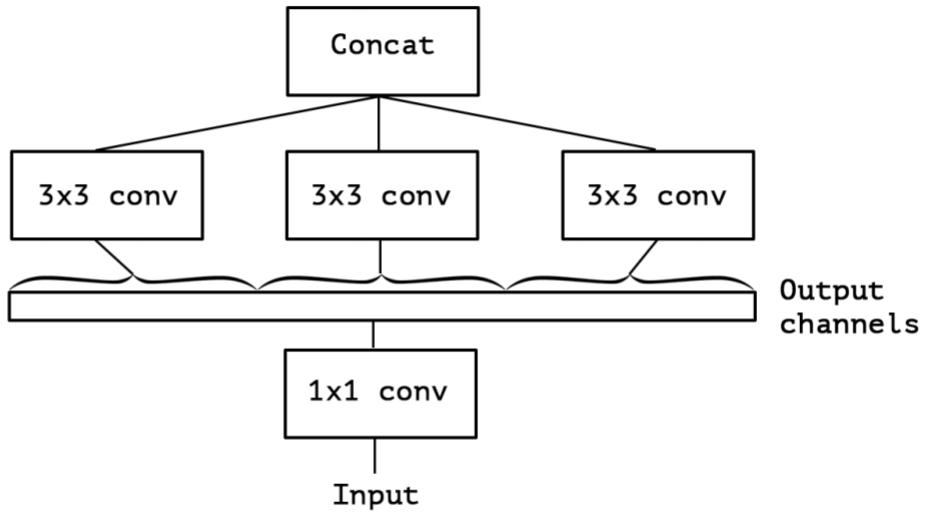
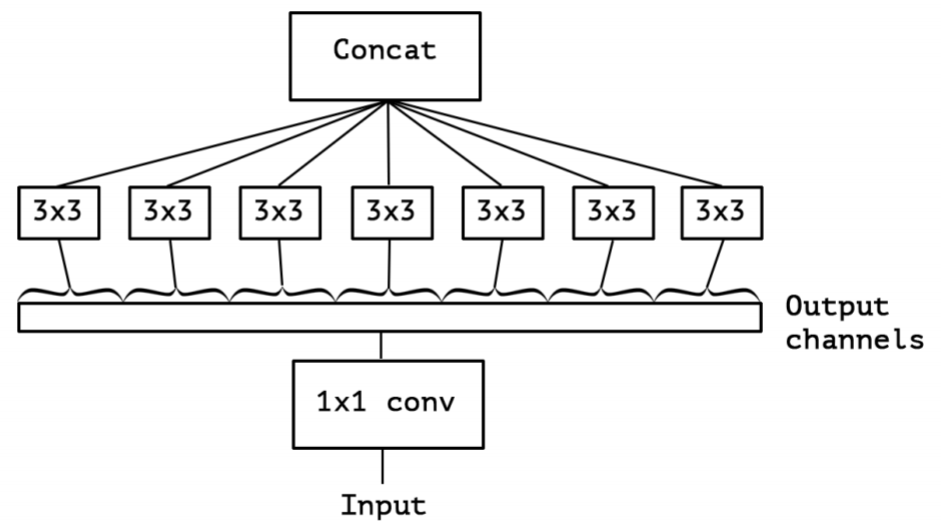
Xception(极致的 Inception):先进行普通卷积操作,再对 1×11×11×1 卷积后的每个channel分别进行 3×33×33×3 卷积操作,最后将结果 concat:
Resnet和ResNeXt
《Deep Residual Learning for Image Recognition》
《Identity Mappings in Deep Residual Networks》
解决深度网络的退化问题,常规的网络的堆叠(plain network)在网络很深的时候,效果却越来越差了。其中的原因之一即是网络越深,梯度消失的现象就越来越明显,网络的训练效果也不会很好。但是现在浅层的网络(shallower network)又无法明显提升网络的识别效果了,所以现在要解决的问题就是怎样在加深网络的情况下又解决梯度消失的问题。
作者提出了Residual的结构:
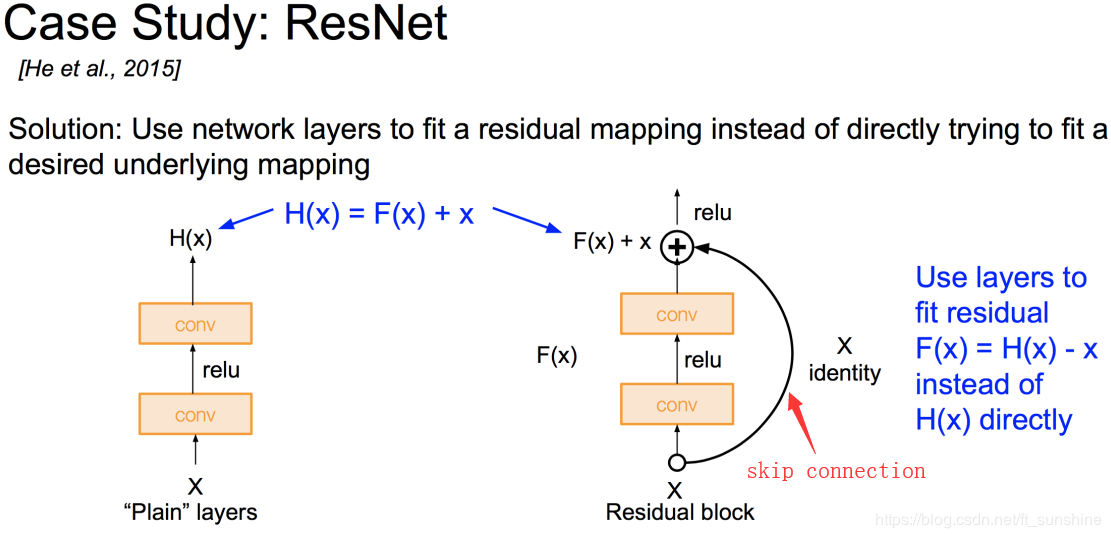
即增加一个identity mapping(恒等映射),将原始所需要学的函数H(x)转换成F(x)+x,而作者认为这两种表达的效果相同,但是优化的难度却并不相同,作者假设F(x)的优化 会比H(x)简单的多。这一想法也是源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
这个Residual block通过shortcut connection实现,通过shortcut将这个block的输入和输出进行一个element-wise的加叠,这个简单的加法并不会给网络增加额外的参数和计算量,同时却可以大大增加模型的训练速度、提高训练效果,并且当模型的层数加深时,这个简单的结构能够很好的解决退化问题。
接下来,作者就设计实验来证明自己的观点。
首先构建了一个18层和一个34层的plain网络,即将所有层进行简单的铺叠,然后构建了一个18层和一个34层的residual网络,仅仅是在plain上插入了shortcut,而且这两个网络的参数量、计算量相同,并且和之前有很好效果的VGG-19相比,计算量要小很多。这也是作者反复强调的地方,也是这个模型最大的优势所在。
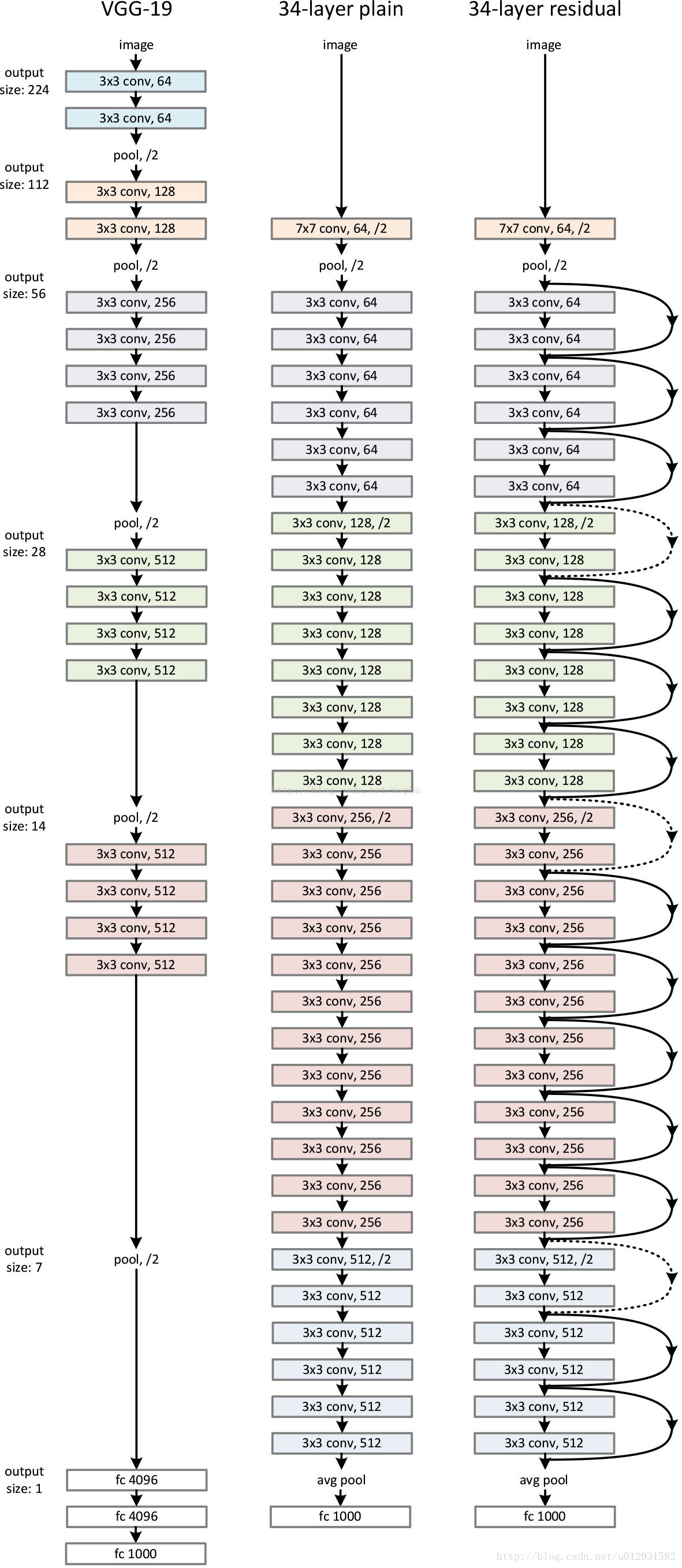
模型构建好后进行实验,在plain上观测到明显的退化现象,而且ResNet上不仅没有退化,34层网络的效果反而比18层的更好,而且不仅如此,ResNet的收敛速度比plain的要快得多。
对于shortcut的方式,作者提出了三个选项:
- 使用恒等映射,如果residual block的输入输出维度不一致,对增加的维度用0来填充;
- 在block输入输出维度一致时使用恒等映射,不一致时使用线性投影以保证维度一致;
- 对于所有的block均使用线性投影。
对这三个选项都进行了实验,发现虽然3的效果好于2的效果好于1的效果,但是差距很小,因此线性投影并不是必需的,而使用0填充时,可以保证模型的复杂度最低,这对于更深的网络是更加有利的。另外,shortcut过程中,stride是2可以保证feature map的大小一致。
进一步实验,作者又提出了deeper的residual block:
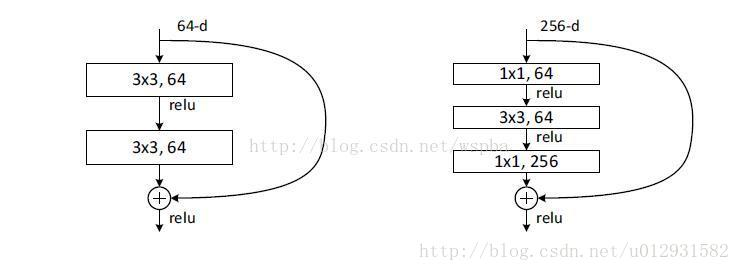
这相当于对于相同数量的层又减少了参数量,因此可以拓展成更深的模型。于是作者提出了50、101、152层的ResNet,而且不仅没有出现退化问题,错误率也大大降低,同时计算复杂度也保持在很低的程度。
这个时候ResNet的错误率已经把其他网络落下几条街了,但是似乎还并不满足,于是又搭建了更加变态的1202层的网络,对于这么深的网络,优化依然并不困难,但是出现了过拟合的问题,并且也很容易出现梯度消失或者梯度爆炸问题,这是很正常的,作者也说了以后会对这个1202层的模型进行进一步的改进。
resnet v1与v2的残差结构不同:
resnet v1 采用conv BN Relu结构,图(a)
resnet v2 采用BN Relu conv 结构,图(e)
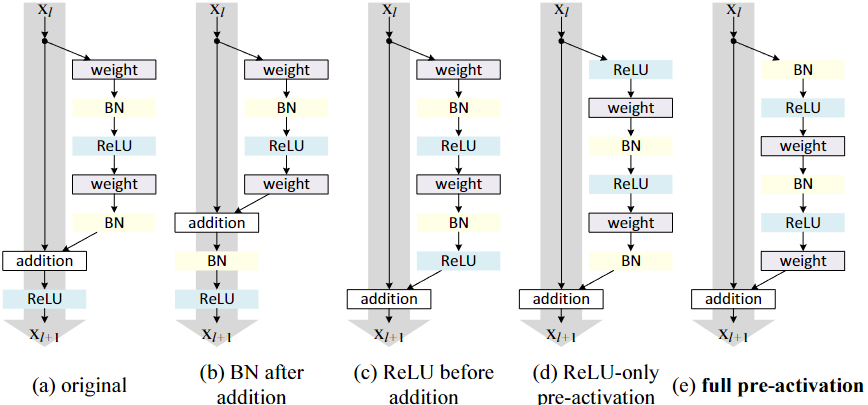
V2较V1的优势,使用预激活可以加强对模型的正则化,在模型深度没有改变的情况下,收敛速度更快
又一个 ResNet 改进版来了!IResNet:可训练超 3000 层网络!
ResNet最强改进版来了!ResNeSt:Split-Attention Networks
深度可分离卷积 Depthwise Separable Convolution
传统的卷积实现过程---->Depthwise Separable Convolution 的实现过程:
 --->
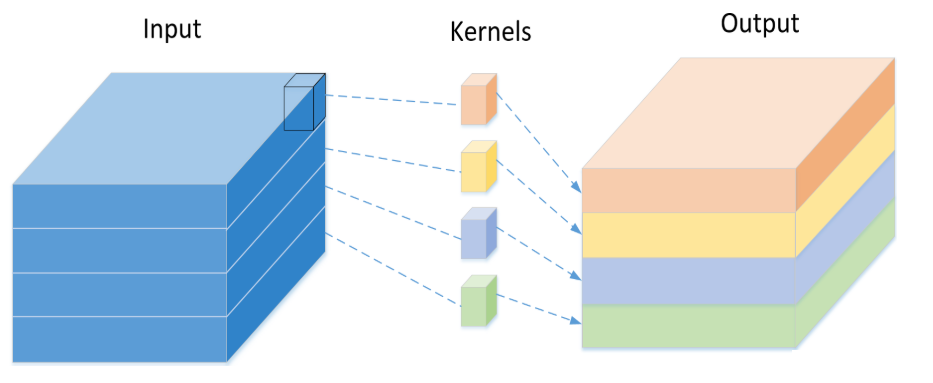
--->
Depthwise Separable Convolution 与 极致的 Inception 区别:
极致的 Inception:
第一步:普通 1×11×11×1 卷积。
第二步:对 1×11×11×1 卷积结果的每个 channel,分别进行 3×33×33×3 卷积操作,并将结果 concat。
Depthwise Separable Convolution:
第一步:Depthwise 卷积,对输入的每个channel,分别进行 3×33×33×3 卷积操作,并将结果 concat。
第二步:Pointwise 卷积,对 Depthwise 卷积中的 concat 结果,进行 1×11×11×1 卷积操作。
两种操作的循序不一致:Inception 先进行 1×11×11×1 卷积,再进行 3×33×33×3 卷积;Depthwise Separable Convolution 先进行 3×33×33×3 卷积,再进行 1×11×11×1 卷积。(作者认为这个差异并没有大的影响)
作者发现,在“极致的 Inception”模块中,用于学习空间相关性的 3×33×33×3 的卷积,和用于学习通道间相关性的 1×11×11×1 卷积之间,不使用非线性激活函数时,收敛过程更快、准确率更高:
DenseNet
现在我们有三种方式来处理不同卷积层之间的特征图:
- Standard Connectivity
- Residual/Skip Connectivity
- Densenet: Dense Connectivity
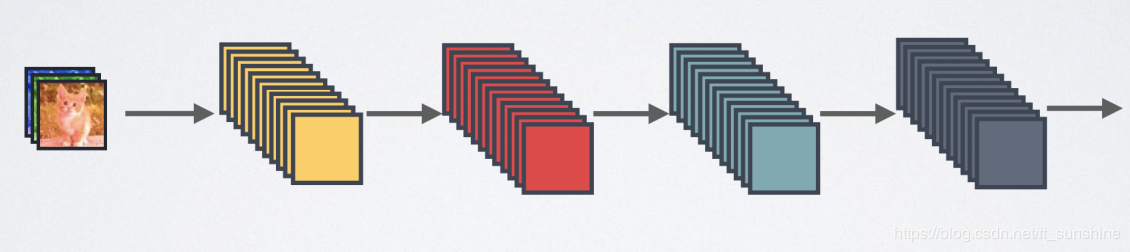
标准连接
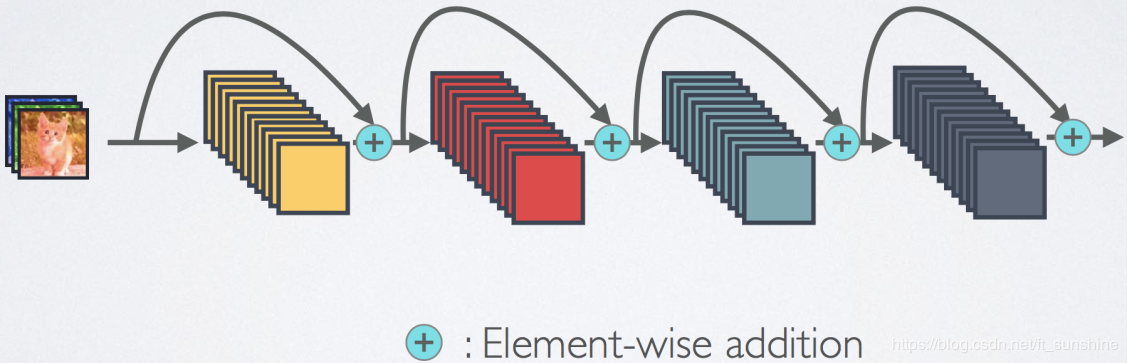
Residual/Skip 连接
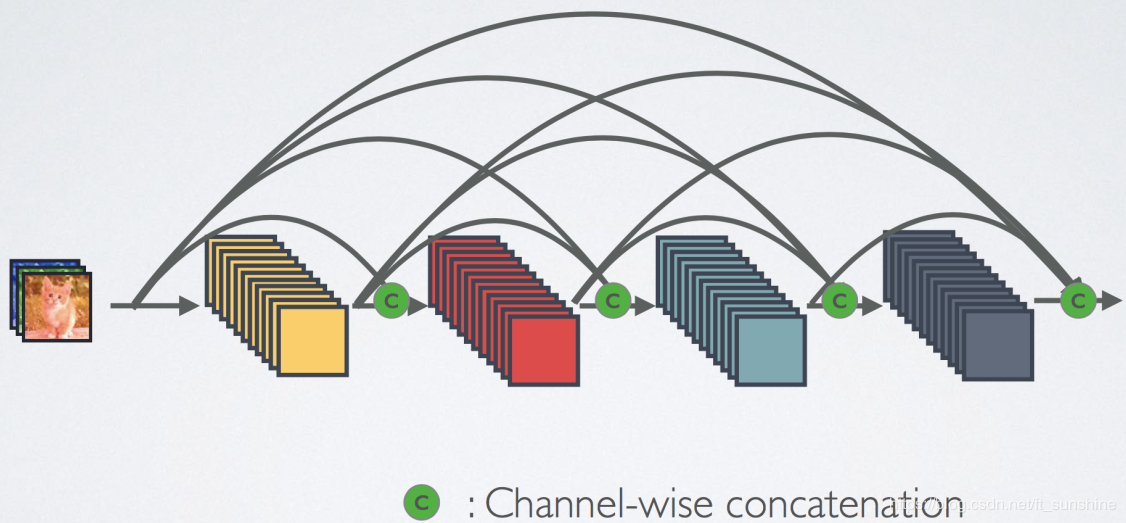
DenseNet:密集连接性
DenseNet的思想是某一层的输入是其前面每一层的输出,即将不同层得到的特征图进行融合作为某一层的输入,这样CNN的每一层就可以得到前面不同层提取的特征(浅层位置等基础信息,深层语义信息),这样网络的表达能力会更好。图示如下:
如果仅仅如之前那么设计的话,很容易出现梯度爆炸,所以:用之前提到的1∗11*11∗1卷积!bottleneck降维
下图是Dense Blocks的结构图,在每个Dense Blocks内部,每层的feature map的大小是一致的(方便特征融合),不同Dense Blocks之间有Pooling层用于减小feature map的大小。
总结
基础框架:Lenet、Alexnet、VGG、Prelu
Inception系列(宽网络):从Inception v1 到v4 以及Inception-Resnet系列
Resnet系列 (长网络):从Resnet被提出后,许许多多该架构被相应提出,Desnet表现出其良好的优越性,残差网络使网络能够更好的处理梯度消失问题。PreActResNet将bn和relu放在前面,得到了很好的效果。还有Resnetx等,这里不多介绍了。
轻型模型 (轻网络):受限移动端的设备,主要思想是将卷积核分离,SqueezeNet 大量采用1x1的网络。mobilenet将3x3的网络分离为n个3x3的卷积核和1x1的卷积核。Shufflenet系列考不同channel之间的关联,提出group1x1,然后再进行混洗。
attention模型(重网络):类似与文本的attention,主要针对不同channel的权重和每个channel不同区域的权重。Residual Attention Network和Senet为典型。
参考
XreCis CSDN博客:https://blog.csdn.net/lly1122334/article/details/88717074
SENets-Residual Attention Networks
其中两个你没写道:SegNet、SqueezeNet、YOLO、ResNeXt
ResNet, AlexNet, VGGNet, Inception: Understanding various architectures of Convolutional Networks
【AI算法工程师手册】CNN:图像分类(和本文一样的巨长文)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号