
24.文件管理补充
目录
文件管理补充
一. x模式
x模式:只写模式,不可以进行读操作
当文件存在时:报错
当文件不存在:创建新文件
with open('a',mode='x',encoding='utf-8') as f:
pass
#(a已存在报错)
'''
Traceback (most recent call last):
File "E:/2020正式上课/day12/01.x模式.py", line 1, in <module>
with open('a',mode='x',encoding='utf-8') as f:
FileExistsError: [Errno 17] File exists: 'a'
'''
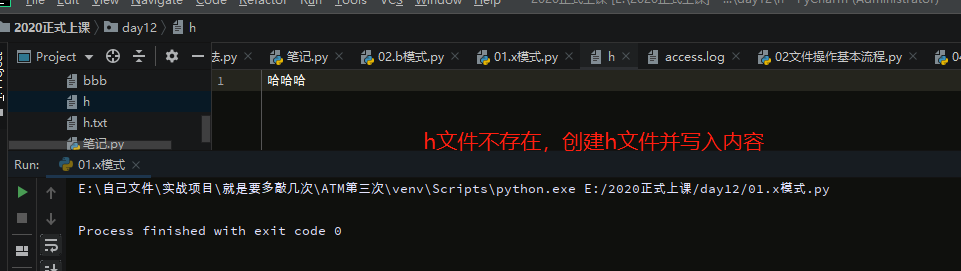
with open('d.txt',mode='x',encoding='utf-8') as f:
f.write('哈哈哈\n')
#h文件不存在,先创建文件h,然后写入内容
二. b模式
我们之前学习了t模式:
t模式:
-
读写都是以字符串(Unicode)为单位的
-
只针对文本文件
-
必须指定字符编码encoding
b模式(binary模式):
- 读写都是以bytes为单位的
- 适用于任何格式的文件
- 一定不可以指定字符编码encoding
总结:
- 当我们对文本文件进行操作时,使用t模式较为方便,他已经帮我们完成了解码的工作,而b模式需要我们自己做
- 针对非文本文件我们只能用b模式
with open('d.mp4',mode='rt',encoding='utf-8') as f:
三. 循环读文件
- 方式一:自己控制每次读取数据的数据量
with open(r'a.txt',mode='rb') as f:
while True:
res=f.read(1024)
#每次读1024个字节
#注意每行之间还有一个换行符
if len(res) == 0:
break
print(len(res))
- 方式二:以行为单位读文件,当一行的内容过长时,会导致一次读入的数据量过大
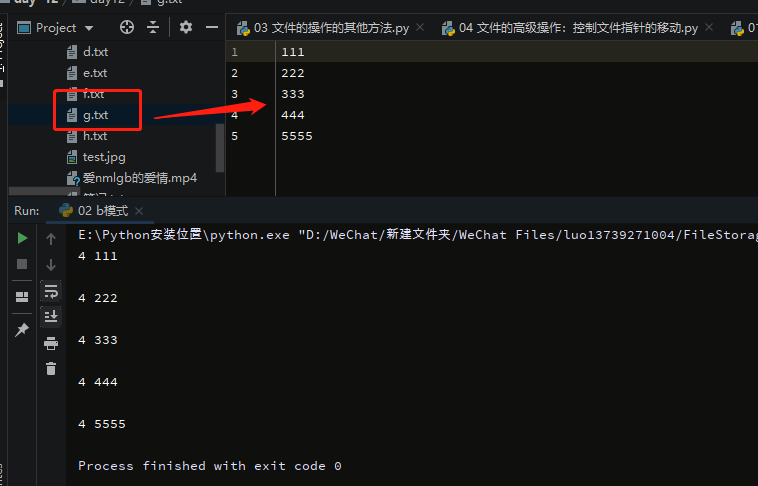
with open(r'g.txt',mode='rt',encoding='utf-8') as f:
for line in f:
print(len(line),line)
四. 文件操作的其他方法
4.1相关读操作
4.1.1 readline
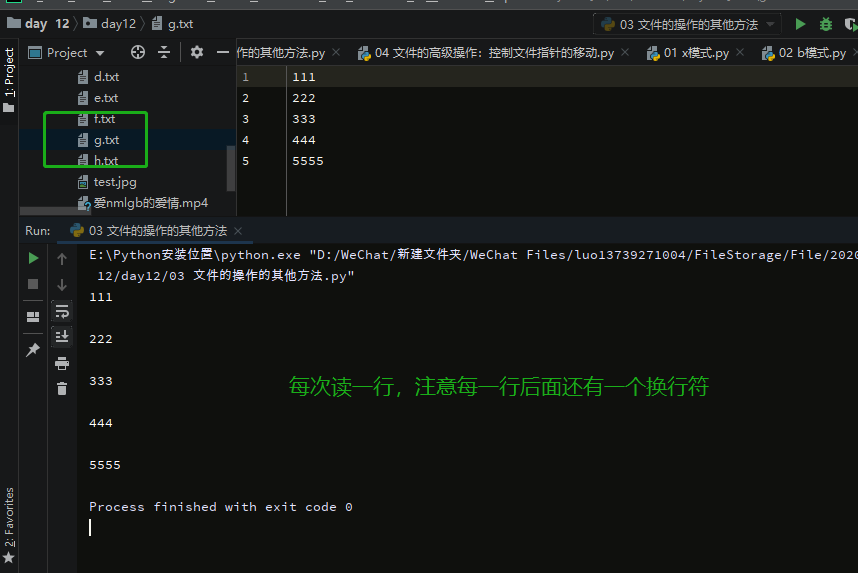
readline:一次读一行
with open(r'g.txt',mode='rt',encoding='utf-8') as f:
# res1=f.readline()
# res2=f.readline()
# print(res2)
while True:
line=f.readline()
if len(line) == 0:
break
print(line)
4.1.2 readlines
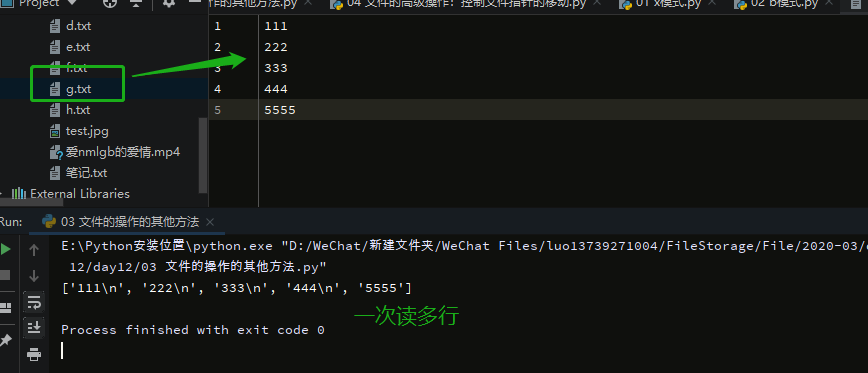
readlines:一次读所有行,每行的结果在列表中存为一个一个字符串
with open(r'g.txt',mode='rt',encoding='utf-8') as f:
res=f.readlines()
print(res)
注意:f.read()与f.readlines()都是将内容一次性读入内存,如果内容过大会导致内存溢出
4.2相关写操作
4.2.1 writelines
清空后,可以写入列表中的内容
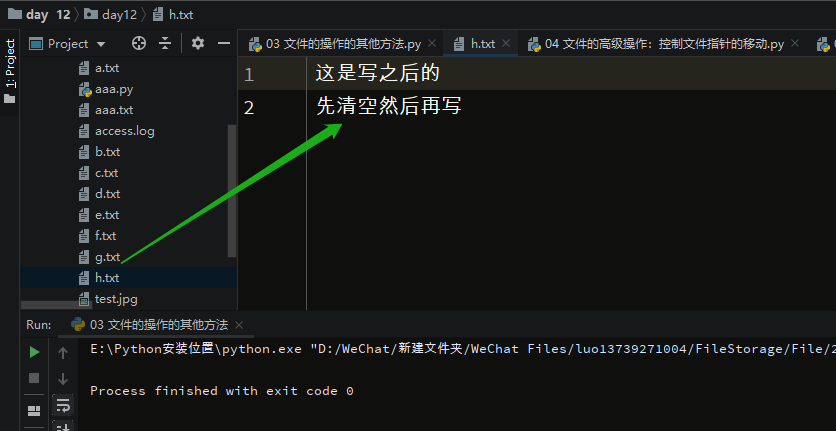
with open('h.txt',mode='wt',encoding='utf-8') as f:
l=['这是写之后的\n','先清空','然后再写']
f.writelines(l)
执行前原来的内容:
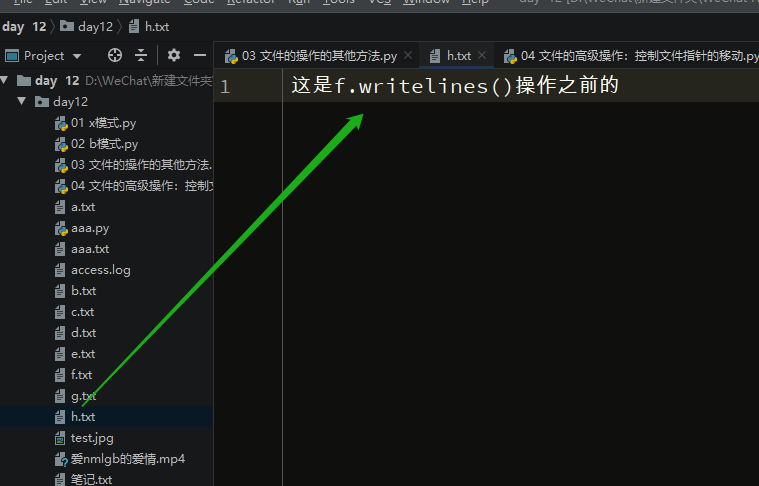
执行之后,内容被清空,然后写入内容:
补充1:'上'.encode('utf-8') 等同于bytes('上',encoding='utf-8')
l = [bytes('上啊', encoding='utf-8'),
bytes('冲呀', encoding='utf-8'),
bytes('小垃圾们', encoding='utf-8'),
]
补充2:如果是纯英文字符,可以直接加前缀b得到bytes类型
l = [b'1111aaa1\n',
b'222bb2',
b'33eee33']
4.3 flush
flush()方法是用来刷新缓冲区的,即将缓冲区中的数据立刻写入文件,同时清空缓冲区,不需要是被动的等待输出缓冲区写入。
一般情况下,文件关闭后会自动刷新缓冲区,但有时你需要在关闭前刷新它,这时就可以使用 flush() 方法。
with open('h.txt', mode='wt',encoding='utf-8') as f:
f.write('快速刷入到硬盘')
f.flush()
4.4 其它
with open('h.txt', mode='wt',encoding='utf-8') as f:
print(f.readable()) #判断是否可读
print(f.writable()) #判断是否可写
print(f.encoding) #得到它的编码格式
print(f.name) #得到它的文件名
# False
# True
# utf-8
# h.txt
五.控制文件指针的移动
5.1 seek()引入及注意点
假设我们需要在文件内容中间的某一行增加内容,如果使用基础的r/w/a模式实现是非常困难的,因此我们需要对文件内的指针进行移动
with open('a.txt', 'r+t', encoding='utf-8') as fr:
fr.readline()
fr.write('写在了最后一行') # 写在文件的最后一行
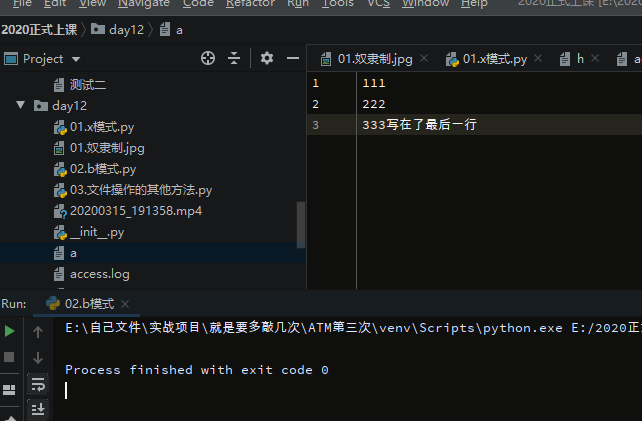
注意:硬盘上没有修改一说,只有覆盖,即:新写的内容覆盖了以前旧的内容
这时候我们引入了指针移动的概念,通过移动指针位置,让我们可以在指定的位置进行内容的写入,Python中使用seek()方法控制指针的移动
注意:指针的移动基本都是以bytes/字节为单位的
特殊情况:t模式下的read(n),n代表的是字符个数
5.2 使用方法
f.seek(n,模式)
-
n:移动字节的个数
-
模式:参照物是文件开头的位置
- 模式1:seek(9,1)参照物是指针当前的位置
- 模式2:seek(-9,2)参照物是文件的尾部,此时应该倒着移动
注意:只有0模式可以在t模式下使用,1和2必须在b模式中使用

 浙公网安备 33010602011771号
浙公网安备 33010602011771号