

李文浩learning---redis压测 服务端基本信息命令 redis基本数据类型 Redis conf配置信息 持久化配置
Redis压力测试准备:
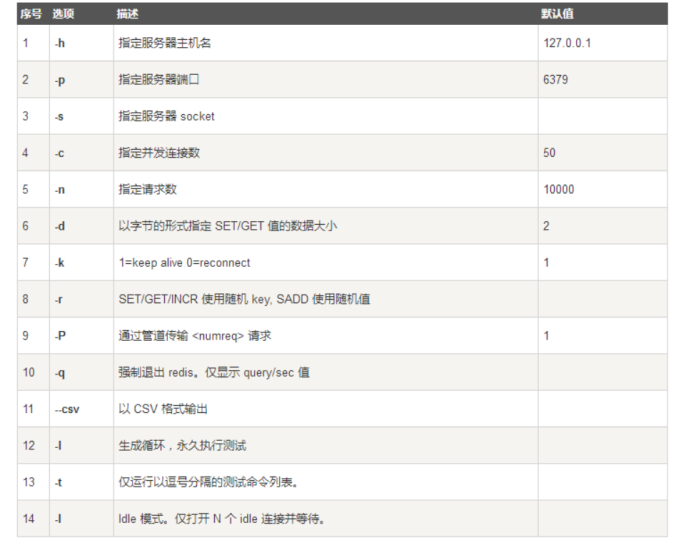
Redis压测工具 redis-benchmark
$ redis-benchmark -n 10000 -q
以上实例中主机为 127.0.0.1,端口号为 6379,执行的命令为 set,lpush,请求数为 10000,通过 -q 参数让结果只显示每秒执行的请求数。
(1) PING_INLINE
(2) PING_BULK
(3) SET:将字符串值value关联到key;
(4) GET:返回key所关联的字符串值,如果key存储的值不是字符串类型,返回一个错误;
(5) INCR:将key中存储的数字值增一。不能转换为数字则报错;
(6) LPUSH:将一个或多个值value插入到列表key的表头;
(7) RPUSH:将一个或多个值value插入到列表key的表尾;
(8) LPOP:移除并返回列表key的头元素;
(9) RPOP:移除并返回列表key的尾元素;
(10) SADD:将一个或多个member元素加入到集合set当中,已经存在于集合的member元素将被忽略;
(11) SPOP:移除并返回集合中的一个随机元素;
(12) LPUSH:将一个或多个value插入到列表key的表头;
(13) LRANGE_100:返回列表key中指定区间内的元素,前100条元素;
(14) LRANGE_300:返回列表key中指定区间内的元素,前300条元素;
(15) LRANGE_500:返回列表key中指定区间内的元素,前500条元素;
(16) LRANGE_600:返回列表key中指定区间内的元素,前600条元素;
(17) MSET:同时设置一个或多个key-value对,value为字符串。
redis数据分布和槽信息:
分布式数据库首先解决数据集按照分区的规则划分到多节点,每个节点负责整体数据的一个子集。
全量数据--------分区规则------------分区子集-----1 2 3-----N
划分规则: 顺序分区 哈希分区
顺序分区 分布于业务相关 可顺序访问 但是离散度倾斜
哈希分区 :节点取余 一致性哈希 虚拟槽
节点取余分区:对于键值key和节点数量N 利用公式hash(key)%N计算出一个位于[0,N-1]区间的值用来决定放在哪个节点上
一致性哈希:所有节点和数据节点放在哈希环上,除了需要计算存储的key的hash之外,还要计算节点的hash,然后存储,选择一个与key的hash最接近的hash存储进去。
虚拟槽分区:解决一致性哈希分区的不足而创建
槽:redis cluster有一个长度为16384槽概念 编号0-16384作为哈希槽使用。槽是集群内数据管理和迁移的基本单位 采用大范围槽主要是为了方便数据拆分和集群扩展。
数据类型 5 3
5 :string set hash zset list
3: geo 地理位置 hyperloglog bitmap
服务端常用命令:
查看当前数据库的key数量 dbsize
后台重写aof bgrewriteaof
后台保存rdb快照 save
后台进程重写 AOF Bgrewriteaof
查看上次保存时间 lastsave
清空服务器 flushdb
获取服务器信息 info info clients info stats
节点配置:
手工修改master服务器
Info replication 查看配置
Slaveof no one 修改为master
Config set slave-read-only-no 可写
修改其他slave服务器配置
Slaveof localhast 6380 前一个置为master
Redis conf配置:
Memory Management
1.Maxmemory:设置redis的最大内存 如果为零 表示不做限制,通常配和下面介绍的maxmemory-policy参数使用。
2.maxmemory-policy: 当内存使用设置达到最大时,redis使用的内存清楚策略有如下选择:
Volatile-lu
Allkeys-lru 利用lru算法移除任何key
Append only mode 持久化策略
1. 默认rdb持久化
2.Appendfilename:aof文件名,默认appendonly.aof
3.appendfsync:aof持久化策略;no不执行fsync,操作系统保证数据同步到磁盘,速度最快;appendfsync:always表示每次写入都执行fsync,以保证数据同步到磁盘;everysec表示每秒执行一次fsync,可能会导致丢失这1s数据
4.、auto-aof-rewrite-percentage:默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。
5.auto-aof-rewrite-min-size:64mb。设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。
Redis cluster
Cluster-enabled:集群开关 默认不开启
Cluter-config-file:集群配置文件的名称 每个redis集群节点都有一个单独的节点。
Cluster-node-timeout:可以配置值为15000。节点互联超时的毫秒数
Cluster-slava-validity-factor:判断slave节点与manster短线时间是否过长
Cluter-mingration-barrier: 可以配置为1 master 的slave的数量大于该值,slave才能转移到其他孤立master上,如果参数设置为2,
Clients: maxclients:设置客户端最大并发连接数,默认无限制
Redis可以同时打开的客户端连接数为redis进程可以打开的最大文件
如果设置mixclients为0.表示不做限制。当客户端连接数到连接数达到限制时,redis会关闭1新的连接向客户端返回max number of clients reached错误信息
Snapshootting:
配置持久化操作
save:这里用来配置触发redis的持久化条件。
Save 900 1:表示900秒内如果至少有1个key的值变化
dbfilename :设置快照的文件名,默认是 dump.rdb
rdbcompression ;默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果是的话,redis会采用LZF算法进行压缩。如果你不想消耗CPU来进行压缩的话,可以设置为关闭此功能,但是存储在磁盘上的快照会比较大。
stop-writes-on-bgsave-error :默认值为yes。当启用了RDB且最后一次后台保存数据失败,Redis是否停止接收数据。这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号