如何自己实现一个RPC框架?
开源的RPC框架,大家都用过Dubbo,底层源码大部分人为了面试也都看过了,服务暴露过程和服务引用过程,服务调用流程等,但那都是多多少少不那么纯粹,就算是自己学习,也终究是站在巨人的肩膀上,你的思路在你看Dubbo源码的那一刻就被Dubbo的路子限制住了,让你觉得,RPC框架,就只能这么干,如果你自己实现,你要怎么实现?
首先
RPC框架和微服务框架:个人认为,RPC框架强调的是远程过程调用这一功能的实现,但是像网关/服务降级/限流/熔断等,只是RPC框架的衍生品,属于生态周边。比如Dubbo,在熔断方面很弱,但是专业事情交给专业人,hystrix和sentinel不就是专门做限流熔断的吗?而SpringCloud,则是一整套解决方案,不仅仅局限于RPC框架了,人家从前到后都有单独的模块,网关zool,熔断器hystrix,客户端feign,注册中心eureka等,SpringCloud更像一个微服务框架,强调的是微服务一整套解决方案,不仅仅RPC。
正题
RPC框架的基本是什么?是通讯,基于TCP传输的模型有什么:BIO和NIO,成熟的框架有Netty和Mina。

通讯只是基本手段,那么下一步要考虑的问题就是,数据传输怎么做?要传输什么样的数据?
我们初学都学过BIO,写过聊天室,传输的数据都是个String,输入字符串,输出字符串,简单。
如果我们要传输对象呢?可以用ObjectInputStream和ObjectOutputStream + ByteArrayInputStream和ByteArrayOutputStream来实现对象的序列化和反序列化。
如果我们要求,在客户端传递的任何对象比如User,到了服务端都能自动变成对象类型User,而不是Object呢?那么我们是不是可以传递对象的Class信息,到了服务端,利用获取到的Class信息,把Object加工成User对象。
如果我们要求,客户端拿着一份接口,调用里面的方法,就能拿到服务端那边接口的实现类返回的数据,就像本地调用一样丝滑呢?那么这就是RPC调用的需求。
1. 客户端和服务端建立好通讯,保证道路畅通
2. 客户端这边调用接口的方法的时候,我们要收集好接口+方法信息+参数信息,打包好(收集数据+序列化)并发送。
3. 服务端这边呢,接收到客户端的数据,拆包(反序列化),拿到接口信息,找到该接口的实现类;拿到方法信息,找到实现类中对应的方法;拿到参数信息,传入具体的参数值,调用实现类中的方法;实现类返回数据,服务端将返回数据和返回类型打包(序列化),发送给客户端。
4. 客户端拿到服务端返回的数据,展示给用户。
这只是个简单的思路,实际上里面还有很多细节,比如:
1. 并发情况下,数据传输会乱序。
2. 如何知道,服务端返回的数据,是给哪一个方法的?
3. 客户端的接口是无法实例化的,接口怎样调用?调用之后如何与客户端搭上关系?
4. 如何确定客户端要调用服务端的哪一个方法,确定之后,用反射调用吗?
5. 客户端超时了怎么办?
数据传输做好之后,客户端和服务端接口提供与消费的同步怎么做?也就是服务注册与发现,因为现实中,不可能单客户端和单服务端。
这部分还是很好理解的,服务注册与发现需要一个注册中心,注册中心就是一个第三方。类似于买家/买家/中间商的关系,买家和卖家不直接接触,完全靠中间商互通有无。
这里可以说一下CAP:
CAP分别是(数据)一致性,(服务器)可用性和分区容错性(分布式系统中在部分断网的情况下仍然可以完全正常的工作)。那么一个分布式系统中,P是必须的,剩下就在CA中选一个。
Zookeeper只能保证CP,一致性和分区容错性:不能保证可用性(A)是因为Master选举的过程中,整个集群是不可用的。
Eureka可以保证AP,可用性和分区容错性:当单个服务器挂掉的情况下,我还可以请求其它服务器(可用性),只是当前服务器的数据可能不是最新的(一致性)
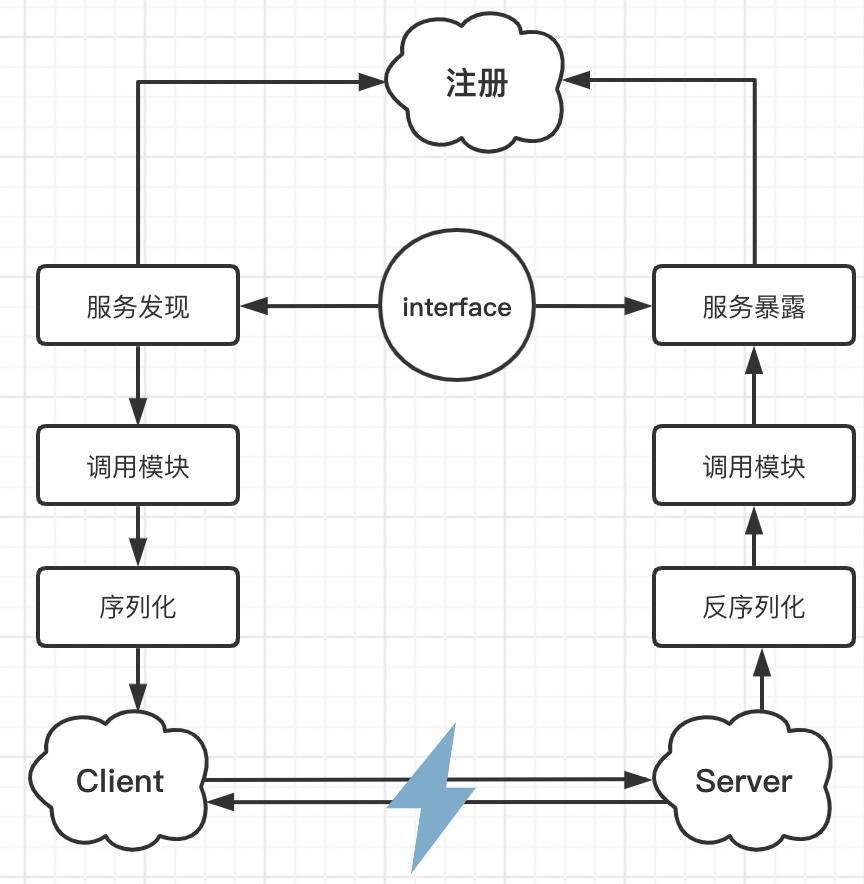
我觉得一个最基本,最纯粹的RPC流程是这样的:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号