不影响已安装的低版本cuda8及其环境工具条件下安装新版本cuda9
根据参考链接,心中熟悉流程
- 参考1确定了【高版本gpu driver 可以兼容 低版本】,所以放心卸载仅支持cuda8.0的旧版,安装支持cuda9.0的新版gpu driver。因为driver与硬件相关,暂时我找不到可以隔离的方案
- 至于隔离cuda,至少有两种方案:
- 基于ubuntu的多用户的隔离:每个用户的cuda安装在自己的home下面,不会影响原有的系统根目录下的cuda8.0的文件。然后修改每个用户自己的bashrc文件,将自己的cuda系统变量设置为指向自己home下面的cuda
- 基于docker的隔离:基于docker-gpu,可以把cuda安装在每一个docker中,各个docker彼此隔离,并且与主机无关
- 创建新的cuda环境:
采取某个作者的方案,使用anaconda建立虚拟环境,定制cuda、tensorflow,与其他用户的【深度学习环境】隔离开来
我的实际操作过程:
- 现状及目标:
机器上已运行了基于旧版本的driver,cuda8.0及一系列application,需要在保证原有环境能正常运行的条件下安装新cuda9.0,并实现各用户的cuda环境隔离
0. 我的软硬件环境:
| object | value |
|---|---|
| nvidia-gpu-brand & type | Tesla-->K 80 |
| OS | Centos7 |
| 服务器是否有图形界面 | No |
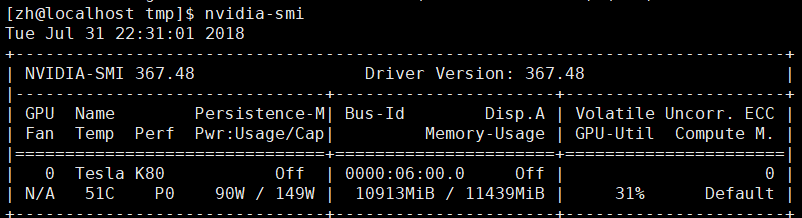
| 原driver | 367.48 |
| 即将安装的driver | 384.145 |
1. 安装gpu driver:
- 卸载cuda8.0所用的旧驱动,安装cuda9.0需要的新驱动,并立刻测试是否兼容cuda8.0 [记住之前的cuda8.0所用的驱动版本,以防出错后的恢复原来的驱动环境]
- 基于上述显卡及操作系统信息,处理显卡驱动:卸载旧的,安装新的:对照着官方tutorial,开始【检查环境】并【下载需要的组件】:
https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#handle-uninstallation (官方tutorial)
https://ywnz.com/linuxjc/1754.html (一个较好的中文对照tutorial)
https://bluesmilery.github.io/blogs/a687003b/#2、安装CUDA-9-0-amp-cuDNN-7-1 (中文对照2)
【下面查出的信息应该与nvida官方tutorial前面的适配表格保持一致,否则就要找解决方案】
确保【环境适配官方的tutorial非常重要!!!】
lspci | grep -i nvidia

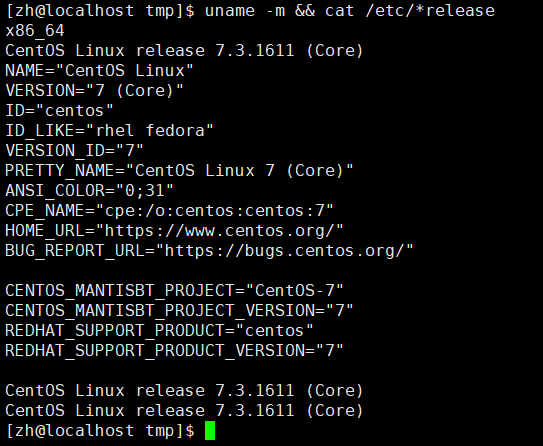
uname -m && cat /etc/*release
gcc --version

uname -r

cat /proc/driver/nvidia/version (检查当前的显卡驱动版本,如果更新driver出错,需要还原)

官网下面的step 3及之后的若干步骤
繁琐且非必须了,所以下面参考这篇博客进行显卡驱动安装:https://bluesmilery.github.io/blogs/a687003b/#2、安装CUDA-9-0-amp-cuDNN-7-1 (根据上述链接,去下载合适的driver)


- 下面有两步非常非常重要:
关闭 nouveau (无论是否有图形界面,建议都关闭掉)
vim /lib/modprobe.d/dist-blacklist.conf
#blacklist nvidiafb # 屏蔽掉这句
# 然后添加下面两句:
blacklist nouveau
options nouveau modeset=0
# 驱动安装好之后也可以不用改回来
lsmod | grep nouveau 【没有输出即图形界面已关闭】

卸载原有显卡驱动
这里与原有安装方式有关,分为dpg和runfile两种,实验室服务器之前的安装方式是dpg,系统是centos7,但根据查的参考博客,最好是用runfile、
// 如果是旧驱动是runfile安装方式,试一下下面的命令就知道了
sudo /usr/bin/nvidia-uninstall
// 如果上述命令失败,说明之前是非runfile方式装的,就转下面的方法:
yum remove nvidia* // 干掉和nvidia有关的所有驱动文件
关闭 X Server
//注意,我在centos下面的命令,
//主要常规有几种命令:
init 3
systemctl stop gdm.service
// 安装完后就:systemctl start gdm.service
//但是也会有意外,
//比如我这次就遇到上述命令无法关闭X //server的问题:
// 最后在一个国外小论坛上找到一个可行方案:
rm /tmp/ .X0-lock
// 还有可能有 .X1-lock .X2-lock .etc
// 一个个试过去,我是 .X2-lock, .X3-lock .X4-lock
// 后来我猜测是【之前有啥应用锁住了X server,无法释放】
进入安装界面后一路选yes,注意不要 no
我的问题是:这一步发现 X server没有真正完全关闭,所以又回头找方案关闭
X server
给new drtiver file 设置x执行权限并安装
chmod u+x NVIDIA-Linux-x86_64-xxx.yyy.run
./NVIDIA-Linux-x86_64-xxx.yyy.run
测试是否兼容cuda 8.0
cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery
make clean
make
./deviceQuery
// Result = PASS 即表示OK
之后建议重启下服务器,能减少各种错误。
比如我就遇到:
An NVIDIA kernel module ‘nvidia-uvm’
appears to already be loaded in your kernel
nvidia-smi查看占用进程pid
kill 掉
但是最简单的方法就是:重启服务器
至此,最麻烦也最容易出问题的driver部分就OK了。
2. 安装CUDA-9.0 & cuDNN-7.1:
-
注:强烈建议之前就下载好driver,cuda,cudnnn,下载方法见前面的说明,并且做sha校验,确保文件完整性,我就犯了这个低级错误:下错了文件
-
安装cuda:
chmod u+x cuda_9.0.176_384.81_linux.run
./cuda_9.0.176_384.81_linux.run
- 接下来就是安装过程:
接下来会有一系列选择
是否安装显卡驱动:选no,因为已经装了最新的驱动
是否安装CUDA 9.0:选yes
输入安装位置:默认即可,因为默认位置就区分开了不同的CUDA版本
是否创建软链:选no,因为要实现多版本CUDA共存。待会儿手动建一个自己需要的软链接。
是否安装sample:选yes
不同系统可能会有 opengl选项,如果有,选择no
- 安装几个补丁:
chmod u+x cuda_9.0.176.1_linux.run
./cuda_9.0.176_384.81_linux.run
chmod u+x cuda_9.0.176.2_linux.run
./cuda_9.0.176_384.81_linux.run
chmod u+x cuda_9.0.176.3_linux.run
./cuda_9.0.176_384.81_linux.run
- CUDA测试:
cd /usr/local/cuda-9.0/samples/1_Utilities/deviceQuery
make
./deviceQuery
// Result = PASS 即表示OK
- Cudnn安装:
tar zxvf cudnn-9.0-linux-x64-v7.1.tgz
// 默认解压为一个cuda目录,cd进去
cp cuda/include/cudnn.h /usr/local/cuda-9.0/include/
cp cuda/lib64/libcudnn* /usr/local/cuda-9.0/lib64/
chmod a+r /usr/local/cuda-9.0/include/cudnn.h
chmod a+r /usr/local/cuda-9.0/lib64/libcudnn*
3. 配置自己用户的环境变量,隔离cuda
- 之前的root 下面的 ~/.bashrc千万不能动
- 为cuda-9.0建立属于自己用户zh的软链接:
ln -s /usr/local/cuda-9.0 /usr/local/cuda_zh
- 修改自己的 .bashrc
export PATH="/usr/local/cuda_zh/bin:$PATH"
export LD_LIBRARY_PATH="/usr/local/cuda_zh/lib64/:$LD_LIBRARY_PATH"
export LIBRARY_PATH="/usr/local/cuda_zh/lib64:$LIBRARY_PATH"
// 注意:一定要确保自己的cuda_zh优先级
//比系统变量的优先级高,所以自己路径写在最前面
- source ~/.bashrc
- 在不同用户下,分别执行 nvcc --version,查看各自的cuda版本。【我的情况是:一个8.0,一个9.0】
4. 配置下tensorflow-gpu环境:
- 切换国内源,安装 Anaconda:
- 切换国内源,安装tensorflow-gpu
- 测试tensorflow-gpu可用性
import tensorflow as tf
hello = tf.constant('Hello, TensorFlow!')
sess = tf.Session()
print(sess.run(hello))
- 切换其他用户,检测其他用户之前的tensorflow-gpu是否能正常运行
- 注:上述安装具体过程参见我自己的一篇博客:ubuntu常见软件的安装
5. 遇到的最有印象的问题总结:
- sudoers文件被修改后需要恢复为read only 才能后续执行sudo 命令
- ubuntu带图形界面的测试机上的驱动安装前必须要禁用图形界面相关的noveau及X server,否则会出现循环登录的问题,出现了最简单的办法是【卸载了重装nvidia驱动】
- 驱动卸载的remove命令,只能后接nvidia*,否则会出问题
- centos上面 X server有时候会因为各种问题而不能【真正完全】关闭,我找到了一种方案:rm .X2-lock。可能还有其他可能
- 遇到一些异常bug,先google,并且试着重启下服务器
- 利用linux多用户的天然隔离效果+自己的bashrc用户变量可以做【某些软件的多版本共存】
参考链接:
-
https://bluesmilery.github.io/blogs/a687003b/
https://bluesmilery.github.io/blogs/a687003b/#2、安装CUDA-9-0-amp-cuDNN-7-1
(先测试高版本显卡可以兼容低版本) -
https://blog.csdn.net/tunhuzhuang1836/article/details/79545625
https://blog.csdn.net/ksws0292756/article/details/80120561
(基于多用户的cuda隔离,只是影响当前用户,也不影响之前的主机环境) -
(基于docker的cuda级别隔离,可以拿来多用户共享某cuda且不干扰原来的主机环境)
https://blog.skyaid-service.org/2017/11/16/nvidia-docker/
https://blog.csdn.net/zh_jessica/article/details/79644544
https://blog.opskumu.com/docker-gpu.html
https://github.com/NVIDIA/nvidia-docker (官方tutorial)
https://github.com/NVIDIA/nvidia-docker/wiki/Docker-Hub (官方tutorial)
https://blog.csdn.net/sinat_26917383/article/details/78728215 -
深入理解整个安装流程进行所参考的:
- https://bluesmilery.github.io/blogs/a687003b/#CUDA下载
- https://zhuanlan.zhihu.com/p/35834028
- https://blog.csdn.net/tunhuzhuang1836/article/details/79545625
- https://blog.csdn.net/ksws0292756/article/details/80120561
- https://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html#handle-uninstallation (官方tutorial,是必须要参考,且作为最最主要参考对象,其他中英文博客只是辅助理解的)
- https://zhuanlan.zhihu.com/p/35834028
- https://ywnz.com/linuxjc/1754.html (虽然不是ubuntu16.04,但是参考性很大)
- https://blog.csdn.net/FIELDOFFIER/article/details/50354607
- https://blog.csdn.net/qq_34564947/article/details/78360198
- https://blog.csdn.net/u012759136/article/details/53355781
- https://blog.csdn.net/zqinstarking/article/details/80713338
- https://www.cnblogs.com/linyx/p/8594040.html (质量高)
- https://blog.csdn.net/lovebyz/article/details/80704800
- http://uixdk.com/tensorflow/2018/06/21/CentOS7-CUDA9.0-CUDNN-Tensorflow.html (质量高)
- https://blog.csdn.net/tunhuzhuang1836/article/details/79545625 (cuda多版本共存)
- https://blog.csdn.net/ksws0292756/article/details/80120561 (cuda多版本共存)
- 实际操作后,出各种错后参考的一些链接
- https://blog.csdn.net/qq_34564947/article/details/78360198
- https://blog.csdn.net/u012759136/article/details/53355781
- https://unix.stackexchange.com/questions/329892/cannot-remove-module-nvidia-nvidia-uvm-in-order-to-install-drivers
- https://github.com/neutrinolabs/xrdp/issues/778
- https://www.zybuluo.com/upuil/note/922035
- https://blog.csdn.net/rznice/article/details/53386436
- https://blog.csdn.net/zyllong/article/details/38387739
- centos 7下面的实际操作的参考:
- https://www.cnblogs.com/linyx/p/8594040.html
- http://uixdk.com/tensorflow/2018/06/21/CentOS7-CUDA9.0-CUDNN-Tensorflow.html
- 我自己的ubuntu下面的常用软件安装连接:
xxx

 浙公网安备 33010602011771号
浙公网安备 33010602011771号