程序故障排查
完善的监控和报警机制
监控大盘
1.接口监控
2.jvm监控
3.tomcat监控
链路追踪
arms、skwalking

告警机制
针对无效的error降级为info或者警告,针对error通过企业微信感知
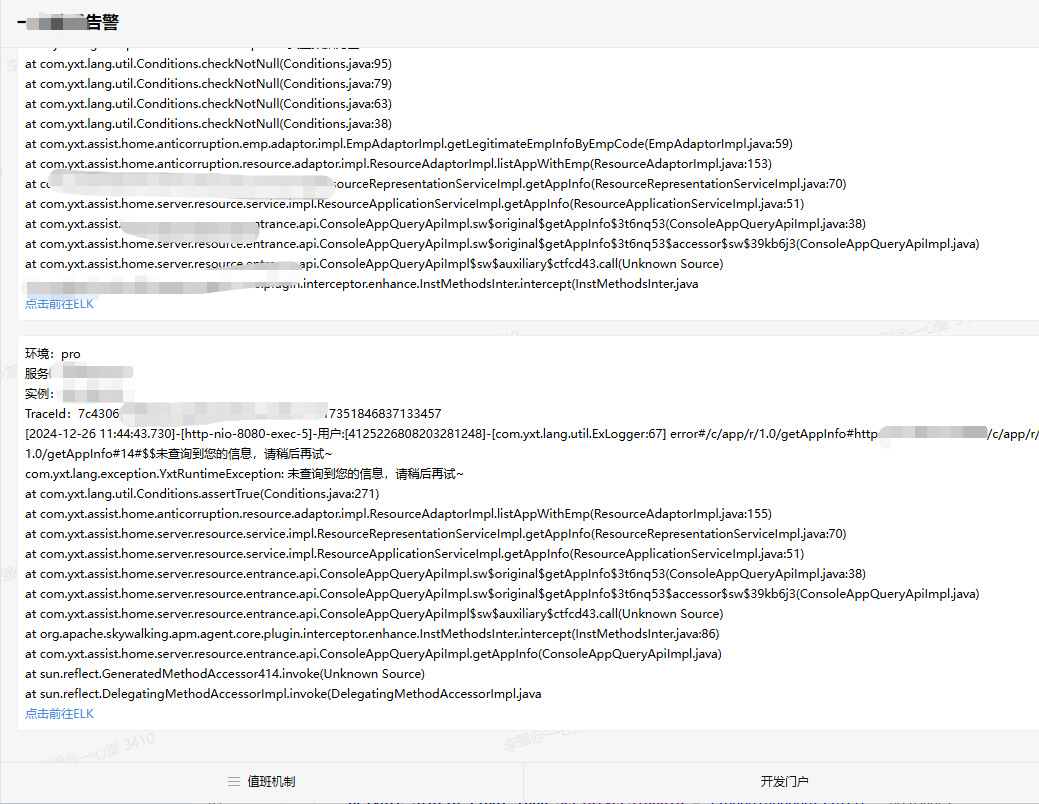
案例一
1.接收到大量告警
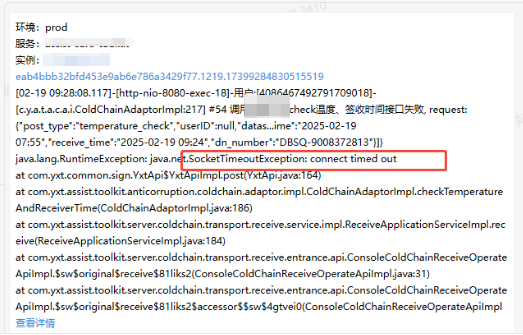

2.分析

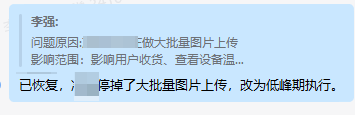
3.解决恢复
系统异常出现缓慢
1.第一时间去监控数据库阻塞的链接 是不是慢sql导致长时间占用链接/or慢sql(一般云产品都有)
https://www.cnblogs.com/LQBlog/p/12208891.html
2.如果是update相关,排查是否有异常的所长时间占用
https://www.cnblogs.com/LQBlog/p/10133758.html#autoid-6-0-0
4.查看链路追踪中的超时链接
5.查看jvm内存和线程信息,是否有大量run中的线程
6.如果数据库没有问题,可以dump线程堆栈信息查看正在执行的线程
https://www.cnblogs.com/LQBlog/p/15267950.html
建议:
建议使用中间件之类的都增加连接池活跃链接的监控,比如 redis es mq http连接池等,最好是再加上监控报警,比如活跃链接长时间在80%或者90% 则触发告警
7.监控大盘查看tomcat的线程统计
Cur持续增长最终导致请求线程打满 请求堆积

5.排查JVM回收时间 是否是因为全局暂停导致。
比如调下游API 通过链路最终查看到耗时8s,但是下游看到最大好是才100ms。得排查一下是否是因为jvm请求耗时导致
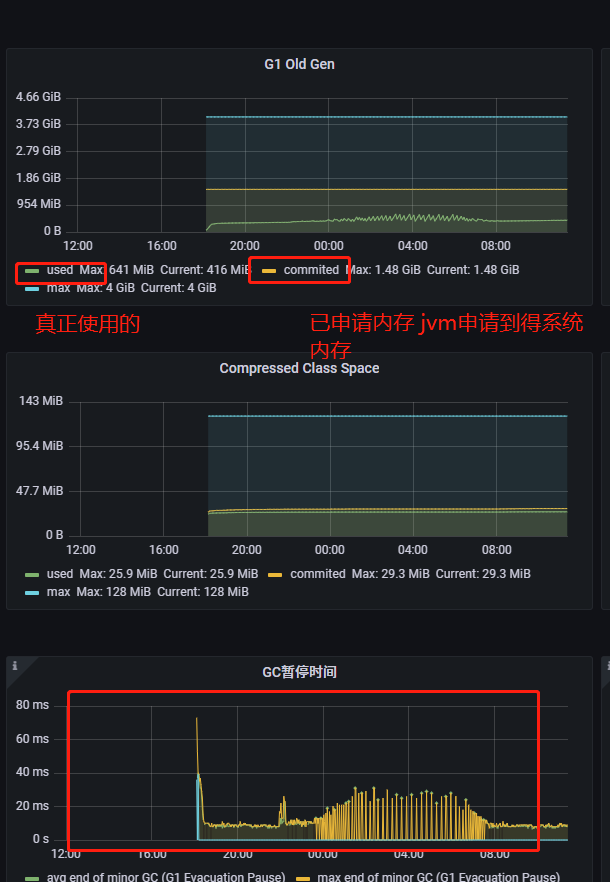
案例1连接池占满
用户反馈程序大规模出错,根据日志排查发现错误,发现是dubbo线程池满了
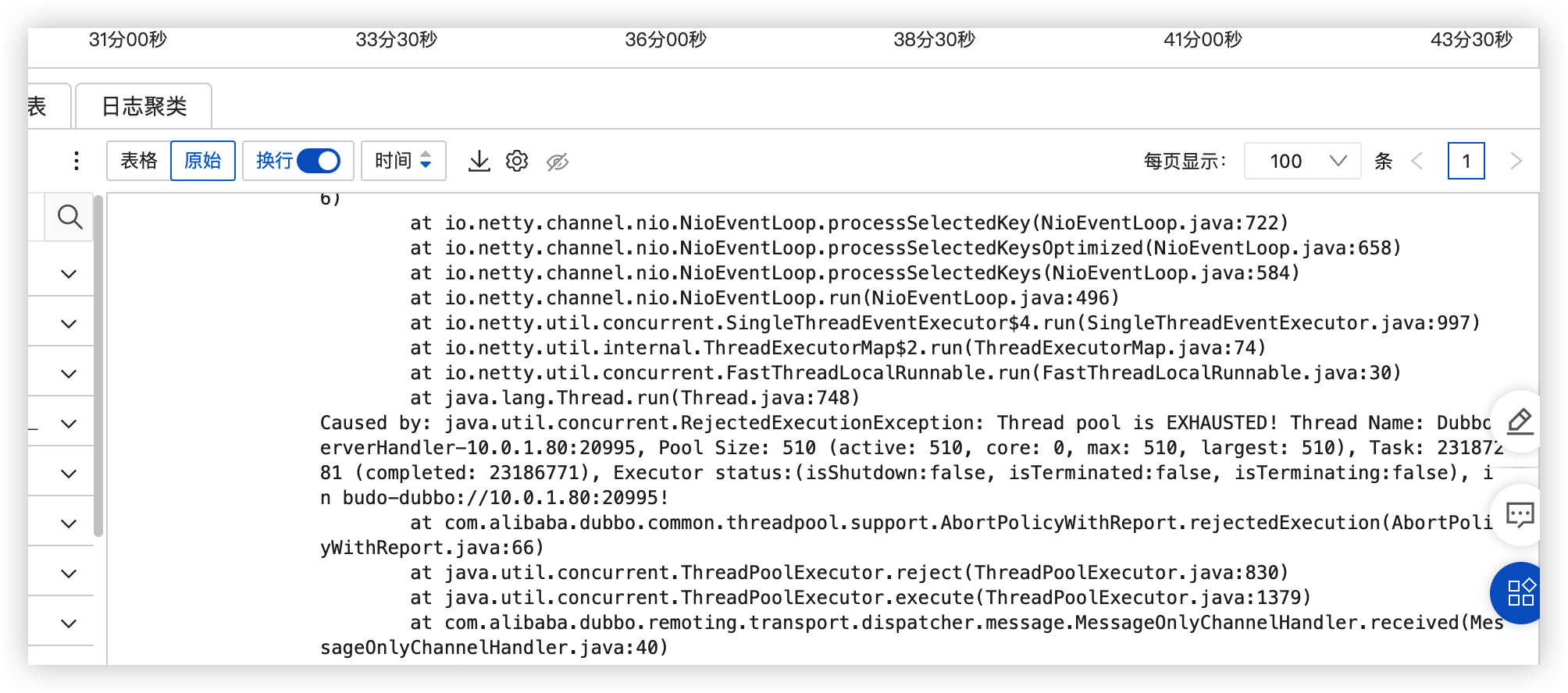
结合当时error日志发现此异常
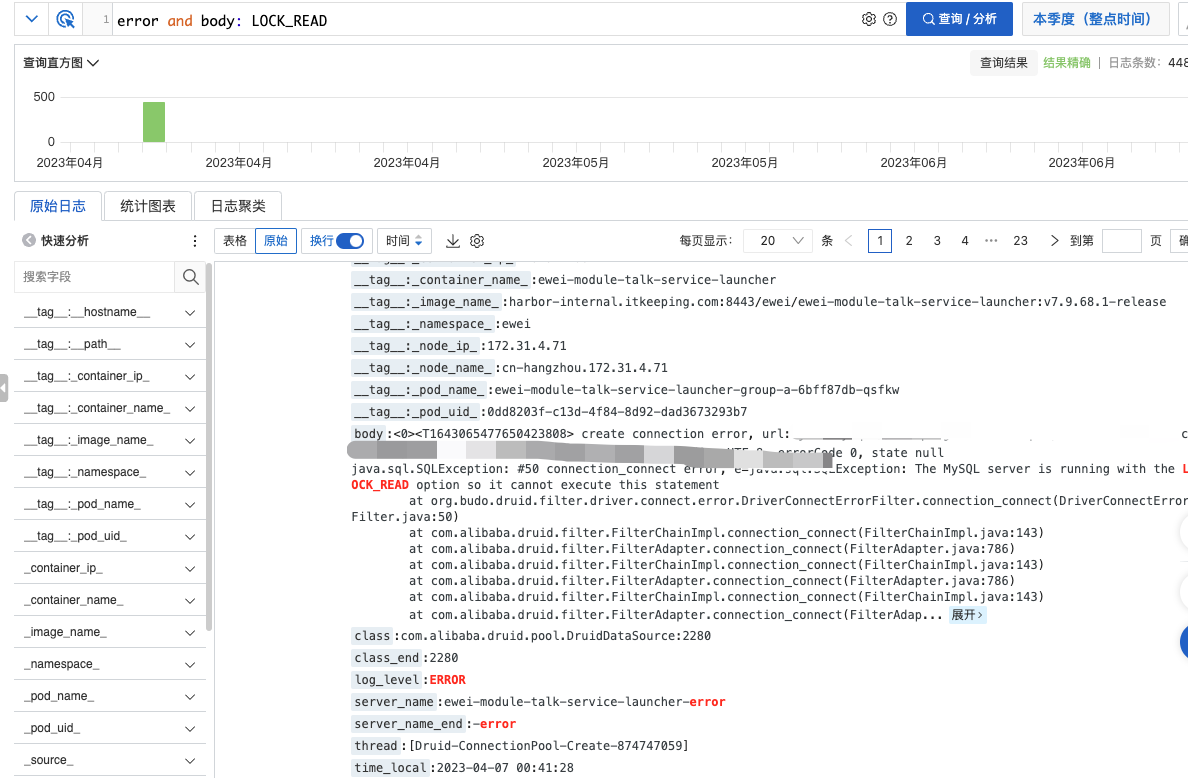
1.数据库运维反馈是因为从库没续费导致
总结
1.出现异常先排查数据库是否正常 可以一下sql或者锁相关排查
https://www.cnblogs.com/LQBlog/p/12208891.html#autoid-1-0-0
2.数据库正常的情况下再通过dump整个线程 看running的是哪些线程大量阻塞了 根据堆栈分析原因
案例二(FullGc)
https://www.cnblogs.com/LQBlog/p/18490319
案例三
此案例体现了微服务下 告警、链路追踪的重要性
1.告警

2.skywalking定位是IO还是非IO问题
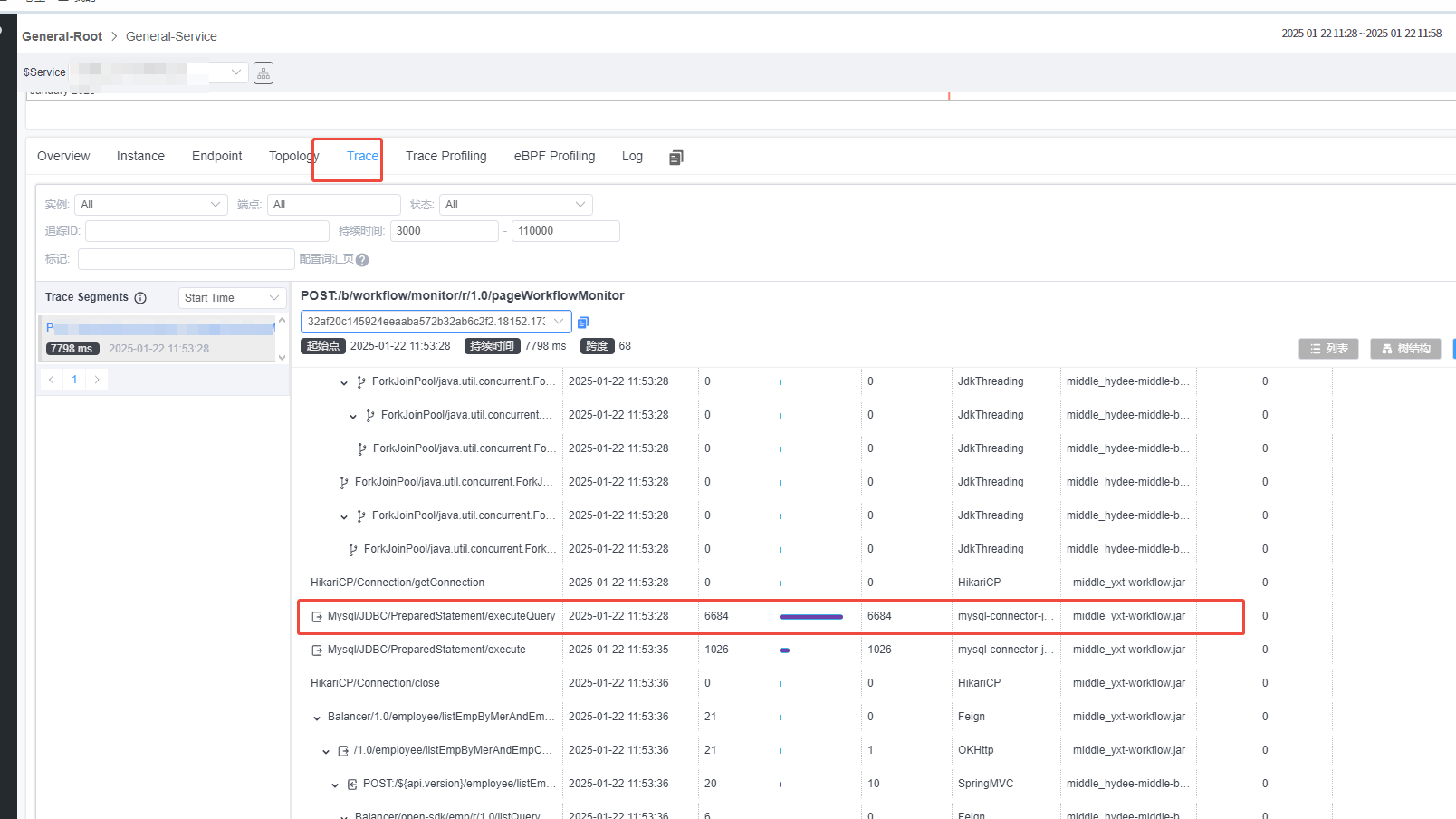
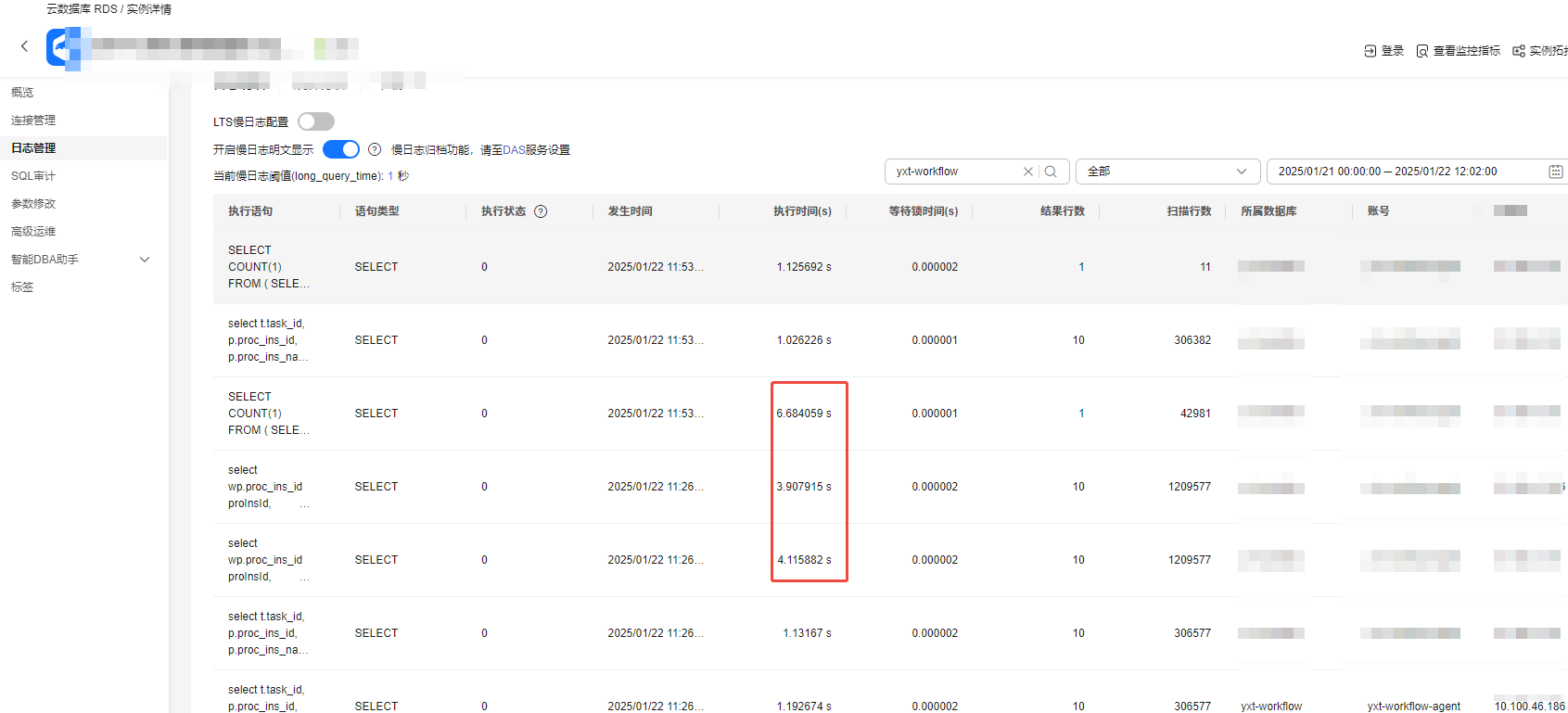
3.查看慢SQL日志

 浙公网安备 33010602011771号
浙公网安备 33010602011771号