线性表
线性表
线性表是具有n个相同类型元素的有限序列(n>=0)
数组
数组是一种顺序存储的线性表,所有元素的内存地址是连续的
int[] array = new int[]{11,22,33};
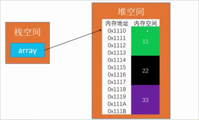
数组的特点
- 无法动态修改数组大小
动态数组
本章只包含了我认为重要的内容:)
动态数组是什么?
可以随着元素的添加,自动扩充容量的数组
接口
int size(); //元素的数量
boolean isEmpty(); //是否为空
boolean contains(E element); //是否包含某个元素
void add(E element); //添加元素到最后面
E get(int index); //返回index位置对应的元素
E set(int index, E element); //设置index位置的元素
void add(int index, E element); //往index位置添加元素
E remove(int index); //删除index位置对应的元素
int indexOf(E element); //查看元素的位置
void clear(); //清除所有元素
实现
package com.lannister;
public class ArrayList<E> extends AbstractList<E>{
private E[] elements;
//动态数组的默认大小
private static final int DEFAULT_CAPACITY = 10;
public ArrayList(int capacity){
//默认容量为10
capacity = (capacity < DEFAULT_CAPACITY) ? DEFAULT_CAPACITY : capacity;
elements = (E[]) new Object[capacity];
//这里是不能直接new <E>[capacity]的
}
public ArrayList(){
this(DEFAULT_CAPACITY);
}
private void ensureCapacity(int capacity){
int oldCapacity = elements.length;
if(oldCapacity >= capacity) {
return;
}
//这里扩容为之前的1.5倍,没有直接写*1.5,因为
//浮点数运算比位运算符慢
int newCapacity = oldCapacity + (oldCapacity >> 1);
E[] newElements = (E[]) new Object[newCapacity];
for(int i = 0; i< size; i++){
newElements[i] = elements[i];
}
elements = newElements;
System.out.println(oldCapacity + "扩容为:" + newCapacity);
}
@Override
public int size(){
return size;
}
@Override
public boolean isEmpty(){
if(size == 0){
return true;
}
else{
return false;
}
// return size == 0
}
@Override
public boolean contains(E element){
return indexOf(element) != ELEMENT_NOT_FOUND;
}
//添加元素到尾部,即索引为size的位置
@Override
public void add(E element){
add(size,element);
}
@Override
public void clear(){
//clear的功能是清空数组中存放的数据,而不是把数组也销毁了
//不用清空数组,让逻辑上数组的大小为0就是清空了
//size = 0; //如果存放的是基本数据类型,那可以这样清空数组
//如果存放引用数据类型数据,只是size=0的话,堆空间的对象还存在
//所以需要清空数组中存放的地址值
for(int i = 0; i < size; i++) {
elements[i] = null;
}
size = 0;
}
@Override
public E get(int index) {
rangeCheck(index);
return elements[index];
}
@Override
public void set(int index, E element){
rangeCheck(index);
elements[index] = element;
}
@Override
public void add(int index, E element){
//是可以插入到数组最大容量的下一个位置的
rangeCheckForAdd(index);
ensureCapacity(size+1);
for(int i = size-1; i >= index; i--){
elements[i+1] = elements[i];
}
elements[index] = element;
size++;
}
@Override
public void remove(int index){
rangeCheck(index);
for(int i = index; i < size-1; i++){
elements[i] = elements[i+1];
}
size--;
elements[size-1] = null;
}
@Override
public int indexOf(E element){
//基本数据类型
/* for(int i = 0; i < elements.length; i++){
if(element == elements[i]){
return i;
}
}*/
for(int i = 0; i < elements.length; i++) {
//不重新equals的话,默认是比较内存地址
if(elements[i].equals(element)) {
return i;
}
}
return ELEMENT_NOT_FOUND;
}
//toString默认是输出全类名,这里自己实现一下想要的效果
@Override
public String toString(){
StringBuilder myString = new StringBuilder();
myString.append("size=").append(size).append(",[");
for(int i = 0; i < size; i++){
myString.append(elements[i]);
if(i == size-1){
myString.append("]");
return myString.toString();
}
myString.append(",");
}
myString.append("]");
//这是啥
return myString.toString();
}
}
对象数组
动态数组改为泛型后,多了对象的内存管理的问题
因为动态数组从原来的存储基本数据类型变成存放对象了,以前是直接把基本数据存放在数组开辟的内存中,而存放对象的话实际上是存放的对象的地址值
数组中存放的是堆空间中对象的内存地址,而不是实际的对象。
-
可以节省空间,因为你不用一开始就创建一个非常大的数组,而只是创建存放地址值的数组,而且此时往数组中存放的对象都还没有被创建
-
因为object数组并不一定能容纳下其它对象。
clear的问题
数组中存放基本数据类型和引用数据类型数据的处理策略是不一样的
存放基本数据类型只用让size = 0, 让外部无法访问,而不用清空数组中的数据。
存放引用数据类型则需要清除掉数组中的数组,因为只是size = 0, 数组中的空间依然会被占用。
关于官方版本的说明
官方版本的ArrayList是能存入null值的
ArrayList复杂度分析
O(n) n是数据规模
get和set都是O(1)
public void add(int index, E element)
最好:O(1)
最坏:O(n)
平均:O(n)
public void remove(int index)
最好:O(1)
最坏:O(n)
平均:O(n)
最好情况时间复杂度
最坏情况时间复杂度
平均时间复杂度
均摊复杂度
add扩容时候的复杂度分析
链表
动态数组有个明显的缺点
无法做到需要多少就申请多少内存,可能会造成内存空间的大量浪费
链表是什么?
链表的内存地址不是连续的
链表的设计
链表的大部分接口和动态数组一样的
可能有人会想那能不能让链表直接继承ArrayList或者坐一个公共的父类,让它们去继承。
但实际上链表和ArrayList的接口虽然很像,但实现方法完全不同,所以公共代码很少
但是可以抽象一个公共的List接口出来
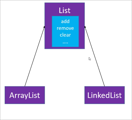
注意
在ArrayList、LinkedList和List接口之间还有一层AbstractList抽象类这一层,但这一层只是作为抽取了一些公共的代码以达到复用的目的,对于使用者来说,他不会去关心AbstractList这一层,他只会去看List接口和使用的ArrayList、LinkedList这两个类。
所以对外界可见的一些东西,就不应该放在AbstractList里面了
clear
add
我最开始是这样写的:
@Override
public void add(int index, E element) {
rangeCheckForAdd(index);
//对index = 0 的情况进行特殊处理,因为下面0-1会等于-1,因为头节点没有index
if (index == 0) {
firstNode.next = new Node<E>(element,getNode(index));
} else {
Node<E> newNode = new Node<E>(element,getNode(index));
//让前一个节点的next指向newNode
getNode(index-1).next = newNode;
}
size++;
}
但是连编译都无法通过,我自己感觉这个add的逻辑应该挺简单,应该不太会出问题,但是我仔细想了一下发现:
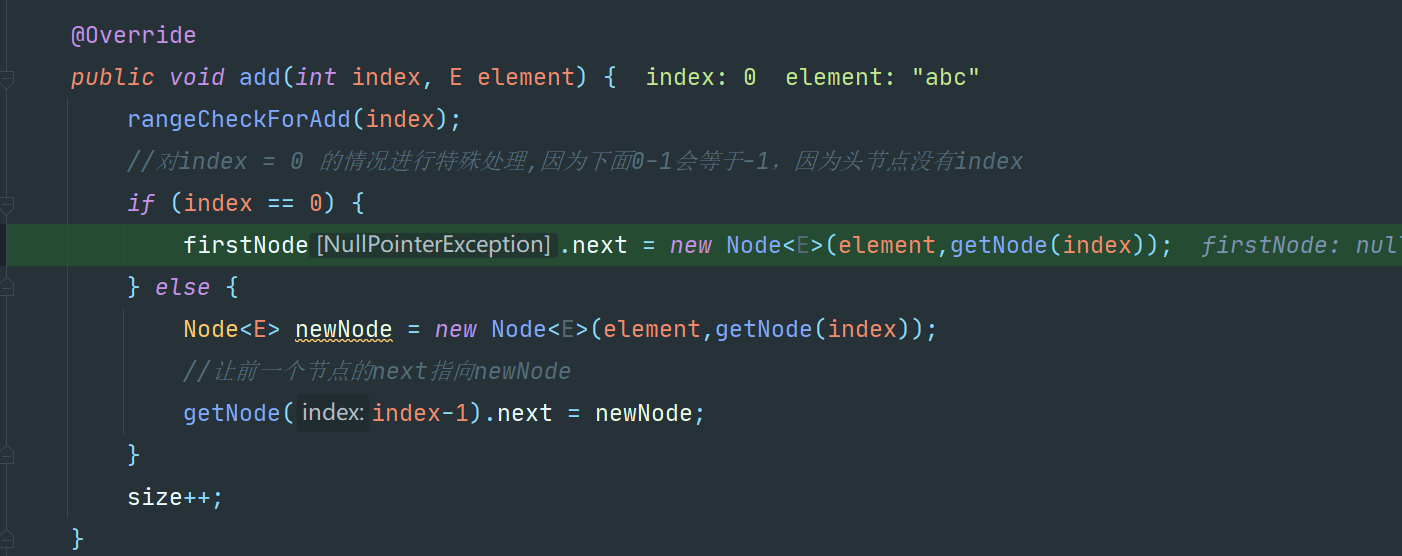
通过Debug工具可以明显看到是有空指针的问题
逻辑上的问题在于:
- firstNode并不是一个节点只是一个指向第一个节点的引用,所以这里如果把firstNode当成一个节点去用的话,就会出现空指针,因为firstNode是初始化为null的
- 还有一个问题是下面else里面getNode(index)的结点还是不存在的所以当然无法通过rangeCheck会出越界异常,当然有的情况是可以的,但是在add的位置是链表的最后一个节点的时候,是不行的
所以短短的一个add方法就有两个致命错误,我好菜:)
remove
indexOf
可能有的问题
- 为什么LinkedList没有构造函数?
- 引申出来的问题:假如java类里的成员变量是自身的对象:https://www.cnblogs.com/xiarongjin/p/8306380.html
为什么类的成员变量是自身类型时只可以声明:https://www.cnblogs.com/wendao/archive/2011/06/17/2609151.html
虚拟头节点
为了统一所有节点的处理逻辑,在最前面增加一个虚拟的头结点,不存储数据,这样就不用对index=0的节点进行特殊处理了。
但是会占用更多内存。
时间复杂度
增删改查都一样
最好:O(1)
最坏:O(n)
平均:O(n)
复杂度震荡
如果扩容倍数、缩容时机设计不当可能造成复杂度震荡
//TODO
双向链表
优点:
- 能提高链表的综合性能
- 链表有两个指针first, last 分别指向开头和结尾的节点
- 每个节点新增加了一个prev指针指向前面的节点
- 查找节点能先根据索引判断从左边开始查找还是从右边开始,这样就不用遍历整个链表,而是最多遍历一半的链表
getNode
clear
add
remove
对比总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号