
数据采集与融合技术第三次作业
作业① 气象网页爬取实验
1.1 实验要求
指定一个网站,爬取该网站中的所有图片,本次选择的目标站点为 中国气象网(http://www.weather.com.cn)。
要求分别使用 单线程 和 多线程 的方式完成图片下载,将所有图片保存到本地 images 子文件夹中。
1.2 实验思路
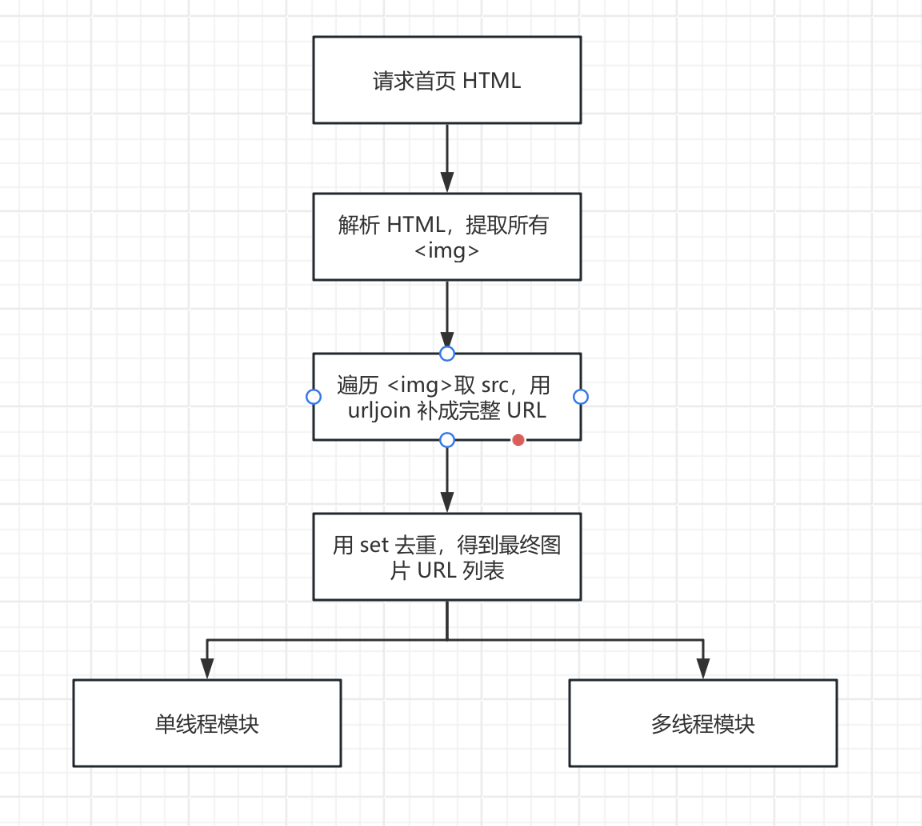
从图中可以看出,图片地址在 src 中,这是非常常见的写法,所以对于此次实验,我们可以直接解析 HTML 拿 src 就行,不需要做更多特殊处理。当然,为了以防有相对路径的存在,我们也可以使用 urljoin 来补齐,这样会更稳妥。
主要流程如下:
- 发送请求,获取网页 HTML 源码;
- 解析页面,提取所有
<img>标签; - 从每个
<img>标签中取出src属性,使用urljoin得到完整图片 URL; - 分别用单线程和多线程两种方式下载图片,对比效率。
1.3 关键代码实现
1.3.1 图片 URL 的获取
这部分的代码实现如下
website = "http://www.weather.com.cn"
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(website, headers=headers, timeout=10)# 请求网页,获取 HTML 源码
response.encoding = response.apparent_encoding
soup = BeautifulSoup(response.text, 'lxml') # 用 lxml 解析器解析 HTML
img_tags = soup.find_all('img')#提取所有 <img> 标签
img_urls = []
# 从每个 <img> 中拿到 src 属性,并拼接成完整的图片 URL
for img in img_tags:
src = img.get('src')
img_url = urljoin(website, src) # 处理相对路径,补成绝对路径
img_urls.append(img_url)
# 使用 set 去重,再转回列表
img_urls = list(set(img_urls))
1.3.2在实现爬取方式上,我设计了单线程和多线程两种方法,实现不同速度的爬取。
对于单线程,代码实现如下
for img_url in img_urls:
# 从 URL 中取出文件名
filename = os.path.basename(urlparse(img_url).path)
img_path = os.path.join('images', filename)
# 请求图片数据
r = requests.get(img_url, headers=headers, timeout=10)
# 二进制写入本地文件
with open(img_path, 'wb') as f:
f.write(r.content)
print(f"下载完成: {img_url}")
单线程就是简单的按顺序一个一个请求图片。
而对于多线程,代码如下:
threads = []
# 为每一张图片创建一个下载线程
for img_url in img_urls:
# 使用默认参数 u=img_url,避免闭包里 img_url 被后续循环修改
def task(u=img_url):
filename = os.path.basename(urlparse(u).path)
img_path = os.path.join('images', filename)
r = requests.get(u, headers=headers, timeout=10)
with open(img_path, 'wb') as f:
f.write(r.content)
print(f"下载完成: {u}")
t = threading.Thread(target=task)
threads.append(t)
t.start() # 启动线程
# 等待所有线程执行完毕
for t in threads:
t.join()
在多线程中,我定义了task函数,该函数负责下载一张图片并保存到本地,但我为每一张图片都创建了一个,这样就不再是等待一个图片下载好再去下载另外一个,而是转变成了好几个图片开始一起下载,实现多张图片一起发请求。多线程比单线程快速的地方就在于,他不需要花大量时间去等待网络,这会使得资源利用更高效。
1.4实验结果
1.5心得体会
通过这次实验,我第一次比较系统地体验了单线程和多线程在网络爬取场景下的差异。
单线程版本的逻辑非常直观:一张图片下载完成之后才会去请求下一张,代码简单,但整体耗时会比较长。
多线程版本中,把每一张图片的下载操作都交给一个独立的线程去执行,多个请求可以同时在网络中执行,大大减少了等待网络传输的时间。
在实现过程中,有两个小点印象比较深:
1.有些 src 是相对路径,如果不使用 urljoin 补全成绝对路径,会导致请求失败,这让我对 URL 拼接 有了更直观的认识。
2.在线程循环里,如果不小心写成 def task(): ... 而没有用默认参数保存 img_url,所有线程可能会拿到同一个 URL,会出问题。
总体来说,这个实验让我更熟悉了 requests + BeautifulSoup 的基础爬虫流程,也对多线程在爬虫中的加速效果有了更具体的体会。
作业②
2. 股票信息定向爬虫实验
2.1 实验要求
- 熟练掌握 Scrapy 框架中 Item、Pipeline 数据的序列化与持久化输出方法;
- 掌握 Scrapy + 动态 API 分析 + SQLite 数据库存储 的技术路线,爬取股票相关信息;
- 爬取 东方财富网的股票列表信息,存入本地
stocks.db数据库; - 输出信息:数据库存储格式符合实验要求,表头使用英文命名(如 bStockNo)。
2.2 实验思路
一开始我本来打算像平常那样去扒网页表格,用 XPath 或者 CSS 选器 去解析 table,结果打开 F12 才发现东方财富的页面背后其实有一个专门的 JSON 接口。
后来我就换了思路,不再去“抠 HTML”,而是直接在 Scrapy 里面请求这个接口。这样拿到的是结构化好的数据,用 json.loads() 一解析,就能从 data.diff 里直接遍历每一只股票,感觉比在一堆标签里翻来翻去要清爽很多。

在代码中,我依次构造了第 1、2、3 页的请求,代码里这些看起来乱七八糟的参数(fs、fid、ut 等)都是东方财富 API 规定的,直接从 Network 里复制过来即可。
整个流程可以概括为:
- 在
start_requests中按页构造 API 请求 URL,并发起请求; - 在
parse_api中解析 JSON 响应,从data.diff取出股票列表; - 将每条股票记录封装成
StockdemoItem,并yield给 Pipeline; - 在 Pipeline 中将 Item 写入本地
stocks.db数据库。
2.3 关键代码实现
2.3.1 Scrapy 爬虫(请求 + 解析)
class EastmoneyStockSpider(scrapy.Spider):
# 爬虫名称(运行:scrapy crawl eastmoney_stock)
name = "eastmoney_stock"
# 限制访问的域名
allowed_domains = ["eastmoney.com", "push2.eastmoney.com", "48.push2.eastmoney.com"]
def start_requests(self):
max_page = 3 # 爬取页数
page_size = 50 # 每页条数
for pn in range(1, max_page + 1):
# 东方财富股票列表接口(分页)
url = (
"http://48.push2.eastmoney.com/api/qt/clist/get"
"?pn={pn}&pz={pz}&po=1&np=1"
"&ut=bd1d9ddb04089700cf9c27f6f7426281"
"&fltt=2&invt=2&wbp2u=|0|0|0|web"
"&fid=f3"
"&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048"
"&fields=f2,f3,f4,f5,f6,f7,"
"f12,f14,f15,f16,f17,f18"
).format(pn=pn, pz=page_size)
print("请求第", pn, "页 API:", url)
# 发送请求,响应交给 parse_api 处理,并把页码 pn 传过去
yield scrapy.Request(url=url, callback=self.parse_api, meta={'pn': pn})
def parse_api(self, response):
pn = response.meta.get("pn") # 取出当前页码
text = response.text.strip()
# 判断是否为 JSON 格式
if text.startswith("{") or text.startswith("["):
data = json.loads(text)
# diff 是接口里存放股票列表的字段
diff_list = data.get("data", {}).get("diff", [])
self.logger.info("第 %s 页返回 %s 条股票记录", pn, len(diff_list))
遍历每一只股票,封装为 Item
for record in diff_list:
item = StockdemoItem()
item["stock_code"] = record.get("f12", "") # 股票代码
item["stock_name"] = record.get("f14", "") # 股票名称
item["latest_price"] = record.get("f2", "") # 最新价
item["change_pct"] = record.get("f3", "") # 涨跌幅
item["change_amt"] = record.get("f4", "") # 涨跌额
item["volume"] = record.get("f5", "") # 成交量
item["turnover"] = record.get("f6", "") # 成交额
item["amplitude"] = record.get("f7", "") # 振幅
item["high_price"] = record.get("f15", "") # 最高
item["low_price"] = record.get("f16", "") # 最低
item["open_price"] = record.get("f17", "") # 今开
item["pre_close"] = record.get("f18", "") # 昨收
# 交给 pipelines 后续处理
yield item
2.3.2 连接数据库代码,把数据写入数据库
import sqlite3
class SqlitePipeline(object):
def open_spider(self, spider):
"""爬虫启动时:连接数据库并建表"""
self.conn = sqlite3.connect("stocks.db")
self.cursor = self.conn.cursor()
create_table_sql = """
CREATE TABLE IF NOT EXISTS stock_info (
id INTEGER PRIMARY KEY AUTOINCREMENT, -- 序号 id
stock_code TEXT, -- 股票代码
stock_name TEXT, -- 股票名称
latest_price TEXT, -- 最新报价
change_pct TEXT, -- 涨跌幅
change_amt TEXT, -- 涨跌额
volume TEXT, -- 成交量
turnover TEXT, -- 成交额
amplitude TEXT, -- 振幅
high_price TEXT, -- 最高
low_price TEXT, -- 最低
open_price TEXT, -- 今开
pre_close TEXT -- 昨收
);
"""
self.cursor.execute(create_table_sql)
self.conn.commit()
def close_spider(self, spider):
"""爬虫结束时:关闭连接"""
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
"""每拿到一个 item,就插入数据库一行"""
insert_sql = """
INSERT INTO stock_info(
stock_code, stock_name, latest_price,
change_pct, change_amt, volume, turnover,
amplitude, high_price, low_price,
open_price, pre_close
) VALUES (
?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?
)
"""
data = (
item.get("stock_code"),
item.get("stock_name"),
item.get("latest_price"),
item.get("change_pct"),
item.get("change_amt"),
item.get("volume"),
item.get("turnover"),
item.get("amplitude"),
item.get("high_price"),
item.get("low_price"),
item.get("open_price"),
item.get("pre_close"),
)
print(">>> SqlitePipeline 插入一条记录:", data) # 调试用
self.cursor.execute(insert_sql, data)
self.conn.commit()
return item
2.4实验结果
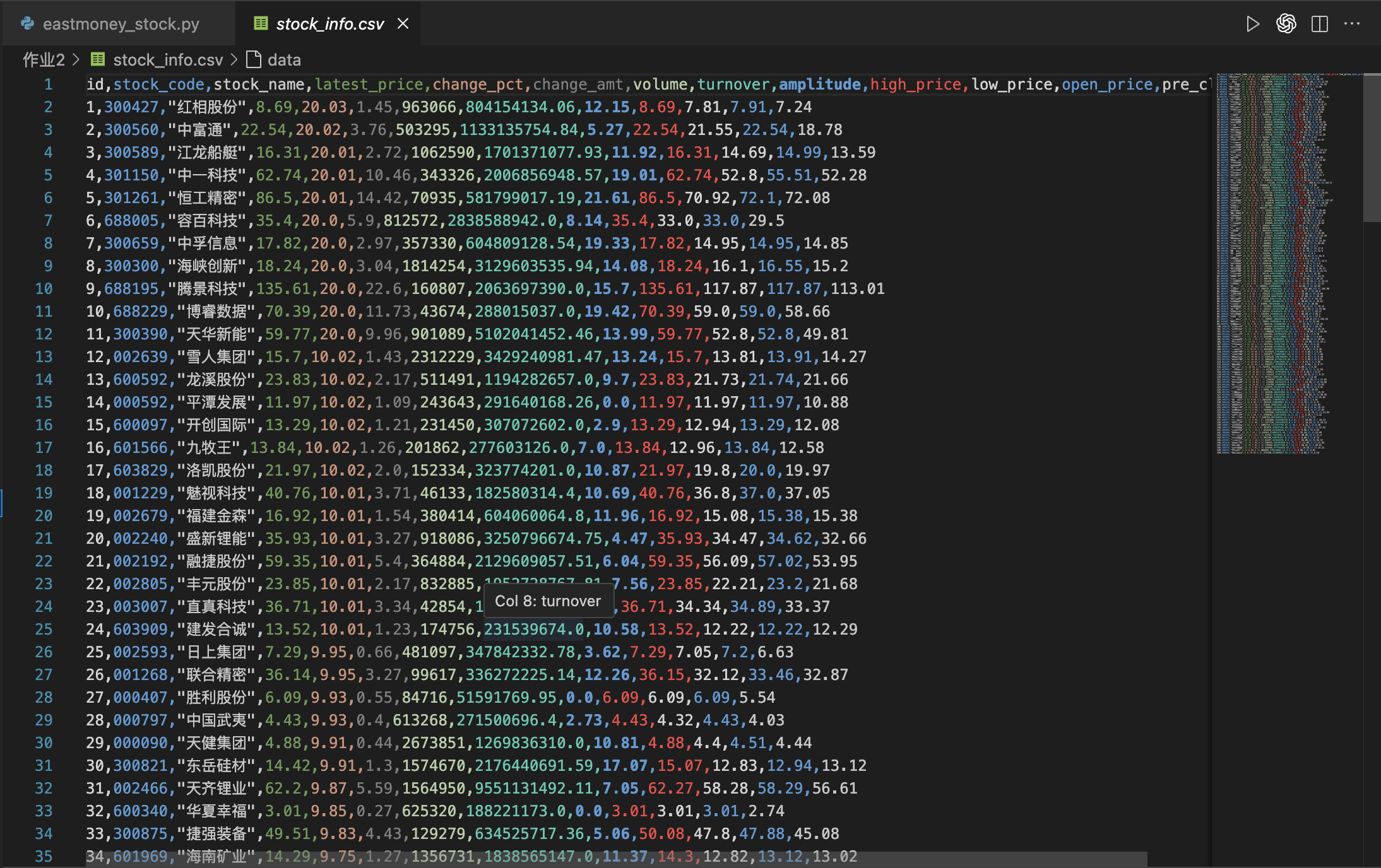
导出csv文件如图所示
2.5 心得体会
在此次任务,我用 Scrapy 去爬取接口数据,而不是老老实实扒网页表格。刚开始看到接口返回的一堆 f2、f3、f4还挺懵的,只能一边打印数据,一边对照网页上的“最新价、涨跌幅、成交量”等字段,慢慢把这些代码字段和真实含义对应起来。这个过程虽然有点枯燥,但是对接口理解更深了一些。
这次还让我真正体会到了 Scrapy 的“内涵”:start_requests是负责统一发分页请求,parse_api专门解析 JSON,再把每只股票封装成 Item 交给 pipelines 处理。这样一来,抓数据和存数据是分开的,逻辑也更清晰。
作业③
3. 爬取外汇数据网站
3.1 实验要求
- 熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法;
- 使用 Scrapy 框架 + XPath + 数据库存储(SQLite) 的技术路线,爬取中国银行外汇牌价网站数据;
- 候选网站:中国银行外汇牌价(https://www.boc.cn/sourcedb/whpj/);
- 输出信息:将爬取的数据存储在数据库中,表头包含:
Currency(货币名称)TBP(现汇买入价)CBP(现钞买入价)TSP(现汇卖出价)CSP(现钞卖出价)Time(发布时间)
3.2 实验思路
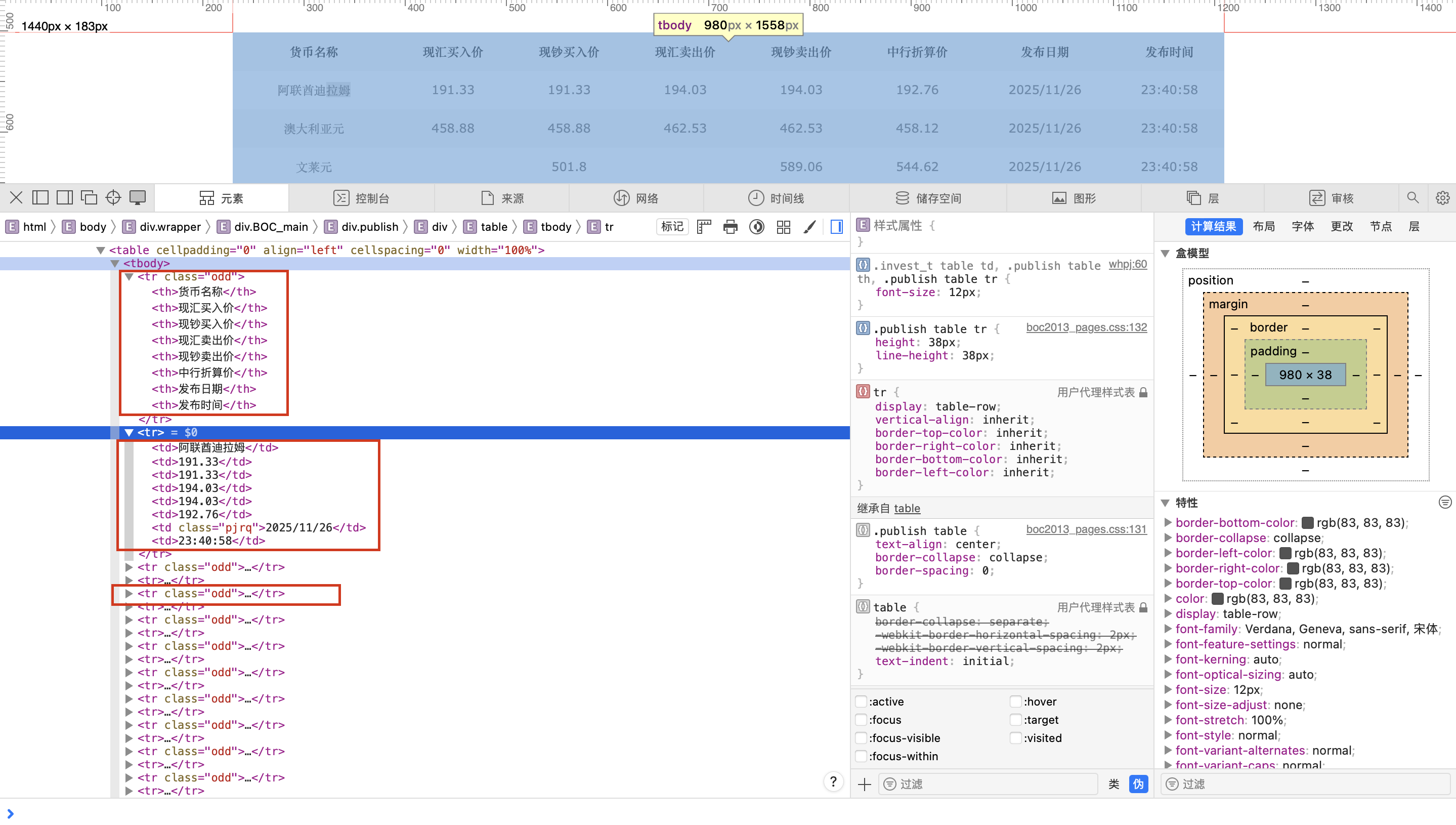
通过浏览器审查元素可以看到,外汇牌价数据是以 表格(table) 的形式展示的,核心数据集中在 div.BOC_main 下面的第一张表里:
- 第一行
<tr>为表头(<th>),包含“货币名称、现汇买入价、现钞买入价、现汇卖出价、现钞卖出价、发布日期、发布时间”等; - 从第二行开始,每一行
<tr>里包含多个<td>,对应一条完整的外汇记录; - 部分行可能是空行或无效行,需要在解析时进行过滤。
整体步骤可以概括为:
- 找到主内容区域的第一张表;
- 从表中拿到所有“数据行”
<tr>,并跳过第一行表头; - 对每一行取出所有
<td>文本,并去掉空白字符; - 过滤掉空行 / 不完整的行(例如列数不足 8 个的行);
- 按照列下标,把每行数据映射到
WhpjItem中对应字段; - 通过 Pipeline 将 Item 写入 SQLite 数据库。
3.3 代码实现
3.3.1爬虫代码实现(BocRateSpider)
class BocRateSpider(scrapy.Spider):
name = "boc_rate"
allowed_domains = ["boc.cn"]
start_urls = ["https://www.boc.cn/sourcedb/whpj/"]
def parse(self, response):
# 找到主内容区域里的第一张表
table = response.xpath('//div[contains(@class,"BOC_main")]//table[1]')
# 跳过第一行表头,从第二行开始都是数据
rows = table.xpath('.//tr[position()>1]')
self.logger.info("共解析到 %s 行外汇记录", len(rows))
for tr in rows:
# 当前行所有单元格文本(XPath)
tds = tr.xpath('./td//text()').getall()
# 去掉空白
tds = [t.strip() for t in tds if t.strip()]
if len(tds) < 8:
continue
item = WhpjItem()
item["currency"] = tds[0]
item["tbp"] = tds[1]
item["cbp"] = tds[2]
item["tsp"] = tds[3]
item["csp"] = tds[4]
item["time"] = tds[7]
print(">>> item:", item["currency"], item["tbp"], item["cbp"],
item["tsp"], item["csp"], item["time"])
yield item
3.3.2入库代码
import sqlite3
class SqlitePipeline(object):
def open_spider(self, spider):
"""爬虫启动时:连接/创建数据库,并建表"""
self.conn = sqlite3.connect("whpj.db")
self.cursor = self.conn.cursor()
create_sql = """
CREATE TABLE IF NOT EXISTS fx_rate (
id INTEGER PRIMARY KEY AUTOINCREMENT,
currency TEXT,
tbp TEXT,
cbp TEXT,
tsp TEXT,
csp TEXT,
time TEXT
);
"""
self.cursor.execute(create_sql)
self.conn.commit()
def close_spider(self, spider):
"""爬虫结束:关闭连接"""
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
"""每次来一个 item 就写库"""
insert_sql = """
INSERT INTO fx_rate(currency, tbp, cbp, tsp, csp, time)
VALUES (?, ?, ?, ?, ?, ?)
"""
data = (
item.get("currency"),
item.get("tbp"),
item.get("cbp"),
item.get("tsp"),
item.get("csp"),
item.get("time"),
)
print(">>> 插入记录:", data) # 调试输出
self.cursor.execute(insert_sql, data)
self.conn.commit()
return item
3.3.2对数据进行处理以及存储
import sqlite3
class SqlitePipeline(object):
def open_spider(self, spider):
"""爬虫启动时:连接/创建数据库,并建表"""
self.conn = sqlite3.connect("whpj.db")
self.cursor = self.conn.cursor()
create_sql = """
CREATE TABLE IF NOT EXISTS fx_rate (
id INTEGER PRIMARY KEY AUTOINCREMENT,
currency TEXT,
tbp TEXT,
cbp TEXT,
tsp TEXT,
csp TEXT,
time TEXT
);
"""
self.cursor.execute(create_sql)
self.conn.commit()
def close_spider(self, spider):
"""爬虫结束:关闭连接"""
self.cursor.close()
self.conn.close()
def process_item(self, item, spider):
"""每次来一个 item 就写库"""
insert_sql = """
INSERT INTO fx_rate(currency, tbp, cbp, tsp, csp, time)
VALUES (?, ?, ?, ?, ?, ?)
"""
data = (
item.get("currency"),
item.get("tbp"),
item.get("cbp"),
item.get("tsp"),
item.get("csp"),
item.get("time"),
)
print(">>> 插入记录:", data) # 调试输出
self.cursor.execute(insert_sql, data)
self.conn.commit()
return item
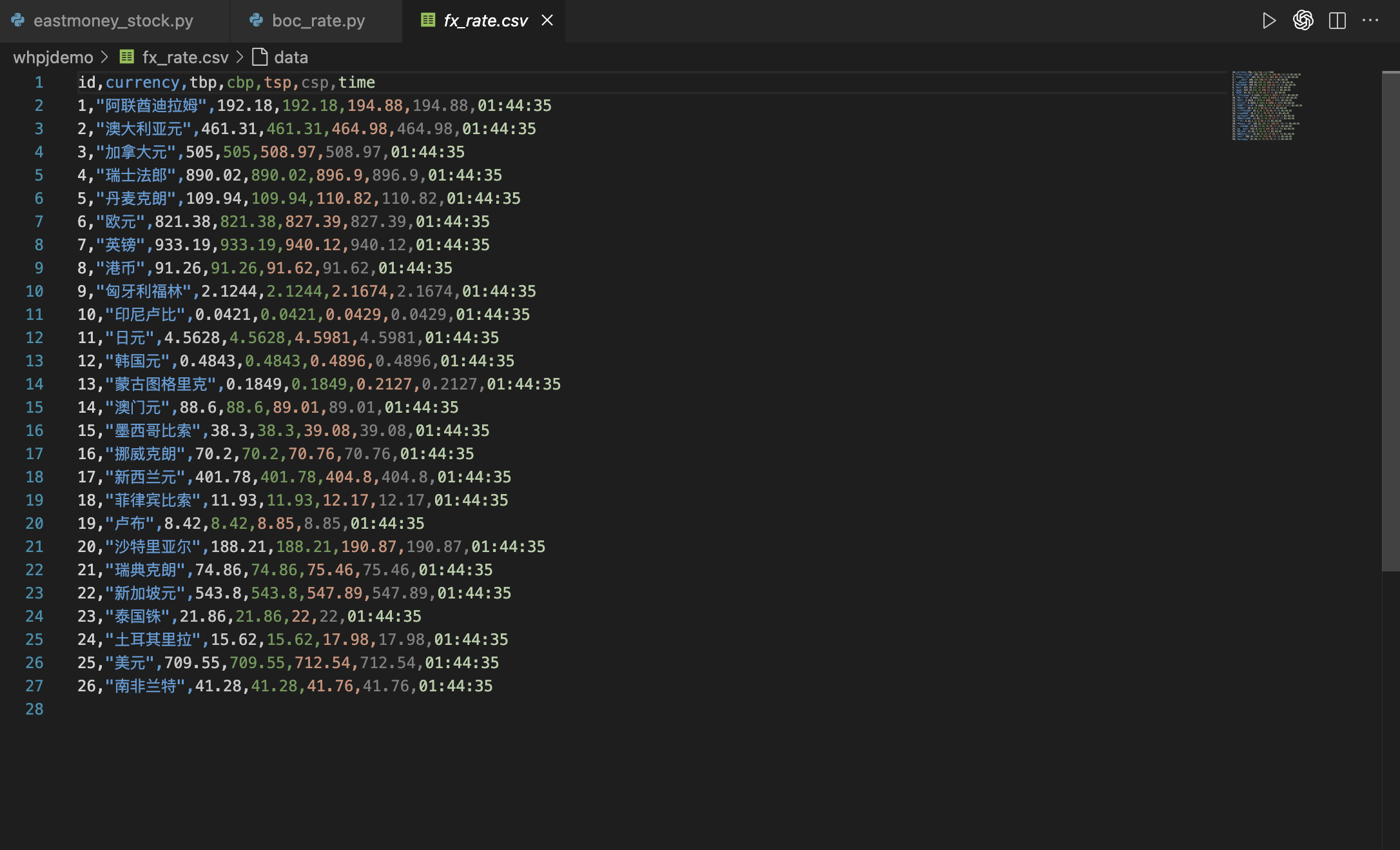
3.4实验结果
3.5心得体会
我的主要收获有两点:一是对网页结构和 XPath 更敏感了,一开始只是知道表格在页面里,用浏览器审查元素多看了几次,才确认 BOC_main 下面第一张表才是我要的数据,然后再按行、按列去拆。二是对 Scrapy 的解析流程更有感觉了:response 进来先锁定表,再 tr 循环拿 td 文本,清洗空白后按顺序映射到 Item 字段,最后交给 pipeline。以前只是觉得 Scrapy 有点“重”,这次真写完一个小功能,感觉它在处理这类结构化数据(表格、列表)时还是挺顺手的,只要前期把 XPath 和字段对应关系弄清楚,后面扩展和维护都会比较方便。
当然也遇到了一点问题,开始的时候我只知道页面上有一张外汇牌价表,后来用浏览器检查元素才发现,真正的数据都在 BOC_main 下面的第一张表里,第一行是表头,要从第二行开始取 tr。写代码时先用 XPath 找到表,再把每行的 td 文本取出来、去掉空白。
gitee链接
https://gitee.com/lin-kun123456/2025_crawl_project/tree/master/task3/work3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号