

数据采集第二次作业
作业①:
爬取天气数据
实验要求:在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。
核心代码与结果:
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"
}
self.cityCode = {"福州": "101230101"}
def forecastCity(self, city):
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req).read()
data = UnicodeDammit(data, ["utf-8", "gbk"]).unicode_markup
soup = BeautifulSoup(data, "lxml")
ul = soup.find("ul", class_="t clearfix")
lis = ul.find_all("li", recursive=False)
for li in lis:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
def process(self):
self.db = WeatherDB()
self.db.openDB()
self.forecastCity("福州")
self.db.closeDB()

使用 urllib.request.Request 构造请求对象,为了顺利得到福州的天气预报数据,在请求时,必须添加User-Agent请求头来模拟浏览器,否则会请求失败。然后拼出目标 URL,发送请求并读取字节,并使用BeautifulSoup解析 HTML。

如图,我先定位 7 日预报列表,然后遍历它的直接子节点 li,一个li对应的就是一天,白天最高温在 span,夜间最低温在 i,拼成“高/低”,这样就实现了对天气预报数据的爬取。
心得:
这个任务的关键在于,需要准确定位天气预报所需的准确信息,并且需要能把我们需要的信息准确的提取出来。同时也必须添加请求头,如果不添加请求头,我们会被服务器拒绝访问。最后,编码问题也是无法忽视的,本次实验通过 BeautifulSoup 自带的 UnicodeDammit 模块解决了 gbk 和 utf-8 的自动检测问题,这是一个非常高效且显著的方法。
作业②
股票信息定向爬虫实验
实验要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
核心代码与结果:
URL = "https://push2.eastmoney.com/api/qt/clist/get"
HEADERS = {"User-Agent": "Mozilla/5.0"}
# f12=代码, f14=名称, f2=最新价, f3=涨跌幅(%), f4=涨跌额, f5=成交量(手), f6=成交额(元)
FIELDS = "f12,f14,f2,f3,f4,f5,f6"
FS_HS_A = "m:0+t:6,m:0+t:13"
if __name__ == "__main__":
page_size = 50 # 每页条数
pages = 5 # 翻页页数
rows = []
for p in range(1, pages + 1):
# 关键查询参数:
params = {
"pn": p, "pz": page_size, "po": 1, "np": 1, "fltt": 2,
"fid": "f3", "fs": FS_HS_A, "fields": FIELDS, "_": int(time.time() * 1000),
}
r = requests.get(URL, params=params, headers=HEADERS, timeout=10)
text = r.text.strip()
# 兼容 JSONP
if not text.startswith("{"):
m = re.search(r"\((\{.*\})\)\s*$", text)
text = m.group(1) if m else text
data = json.loads(text)
diff = (data.get("data") or {}).get("diff", []) or []
for d in diff:
# 从字典取值并做类型转换
code = d.get("f12"); name = d.get("f14")
price = float(d.get("f2"))
pct_chg = float(d.get("f3"))
chg = float(d.get("f4"))
vol = int(float(d.get("f5")))
amount = float(d.get("f6"))
if code:
rows.append((code, name, price, pct_chg, chg, vol, amount))
con = sqlite3.connect("stocks_min.db")
cur = con.cursor()
cur.execute("""
CREATE TABLE IF NOT EXISTS stocks_min (
code TEXT PRIMARY KEY,
name TEXT,
price REAL,
pct_chg REAL,
chg REAL,
vol INTEGER,
amount REAL
);
""")
cur.executemany("""
INSERT OR REPLACE INTO stocks_min
(code, name, price, pct_chg, chg, vol, amount)
VALUES (?, ?, ?, ?, ?, ?, ?);
""", rows)
con.commit()
cur.execute("SELECT code,name,price,pct_chg,chg,vol,amount FROM stocks_min LIMIT 10;")
for row in cur.fetchall():
print(row)
con.close()
print(f"沪深A股 入库 {len(rows)} 条 stocks_min.db")

打开东方财富网https://quote.eastmoney.com/center/gridlist.html#hs_a_board
右键检查元素,进入网络搜索api,从中我们可以找到对应的数据。

发给网站查询参数,同时也要通过正则把JSON抠出来,从 JSON 数据中取出 data.diff 数组,然后提取出来每一条数据并塞入rows里,为之后进入数据库准备。
心得:
网络数据抓取不仅仅是能拿到数据,而且要拿到我们想要的数据,相比于全部数据一次性全爬取下来,这样的效率是低下的,我们更应该分析我们真正需要什么,学会爬取api返回的json数据,这一步在财经网站反爬设计中也是关键。
作业③
爬取中国大学2021主榜实验
实验要求:
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021)所有院校信息。
核心代码与结果:
API = "https://www.shanghairanking.cn/api/pub/v1/bcur"
PARAMS = {"bcur_type": 11, "year": 2021}
HEADERS = {
"User-Agent": "Mozilla/5.0",
"Referer": "https://www.shanghairanking.cn/rankings/bcur/2021",}
def fetch_rankings():
r = requests.get(API, params=PARAMS, headers=HEADERS, timeout=20)
r.raise_for_status()
data = r.json()
# 关键数据在 data.rankings
lst = (data.get("data") or {}).get("rankings", [])
rows = []
for it in lst:
rank = it.get("ranking") or it.get("rank")
name = it.get("univNameCn") or it.get("univName")
province = it.get("province") # 省市
utype = it.get("univCategory") # 类型:综合/理工/…
score = it.get("score")
if rank and name:
rows.append((int(rank), str(name), str(province or ""), str(utype or ""), float(score or 0)))
return rows
我们需要通过F12确定具体的数据来源,使用 F12点开Network,发现接口。它返回 JSON 数据,键 data.rankings 存放所有高校排名信息。

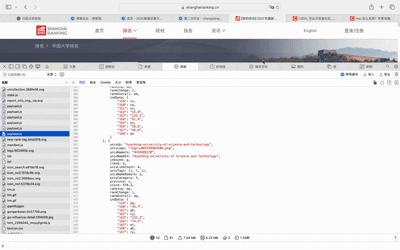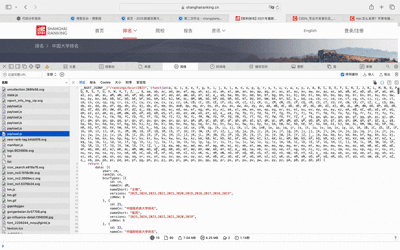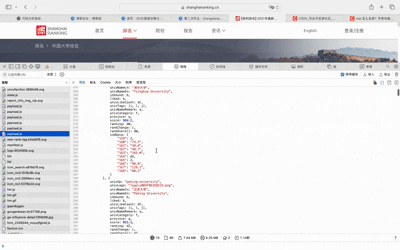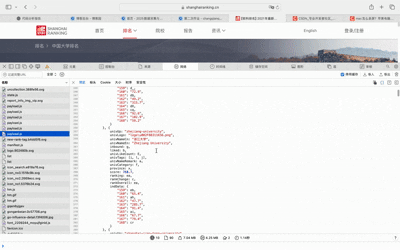
首先,我们发出请求,但要记得带请求头,不然会拒绝访问,接着从图中可以看到完整 JSON 对象,然后从JSON中挑选出我们需要的东西,剩下的也是放入row,最后存入数据库。
心得:
在本次任务中,更加深刻的体会到了该如何寻找api,在动态加载的网页结构中,分析api会比解析html更加有效快捷。同时也要api也会比html更加稳定,html的class很可能会因为网站改版发生变化,这会导致我们爬虫失败。最后,我们也要注意在js文件中的名称,如果设置不对也会导致爬取不到对应数据。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号