
【Spark篇】---Spark中Master-HA和historyServer的搭建和应用
一、前述
本节讲述Spark Master的HA的搭建,为的是防止单点故障。
Spark-UI 的使用介绍,可以更好的监控Spark应用程序的执行。
二、具体细节
1、Master HA
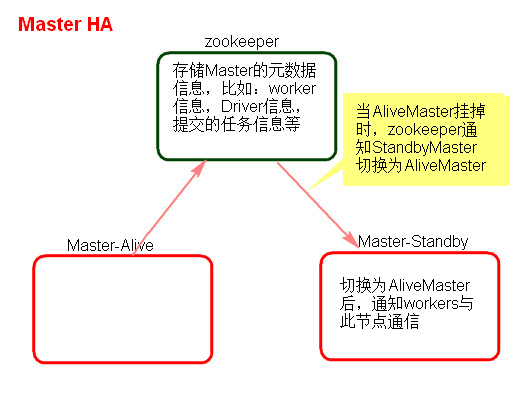
1、Master的高可用原理
Standalone集群只有一个Master,如果Master挂了就无法提交应用程序,需要给Master进行高可用配置,Master的高可用可以使用fileSystem(文件系统)和zookeeper(分布式协调服务)。
fileSystem只有存储功能,可以存储Master的元数据信息,用fileSystem搭建的Master高可用,在Master失败时,需要我们手动启动另外的备用Master,这种方式不推荐使用。
zookeeper有选举和存储功能,可以存储Master的元素据信息,使用zookeeper搭建的Master高可用,当Master挂掉时,备用的Master会自动切换,推荐使用这种方式搭建Master的HA。
2、Master高可用搭建
1) 在Spark Master节点上配置主Master,配置spark-env.sh
命令如下:-D指明配置
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node02:2181,node03:2181,node04:2181 -Dspark.deploy.zookeeper.dir=/sparkmaster0821

2) 发送到其他worker节点上
scp spark-env.sh root@node03:`pwd`
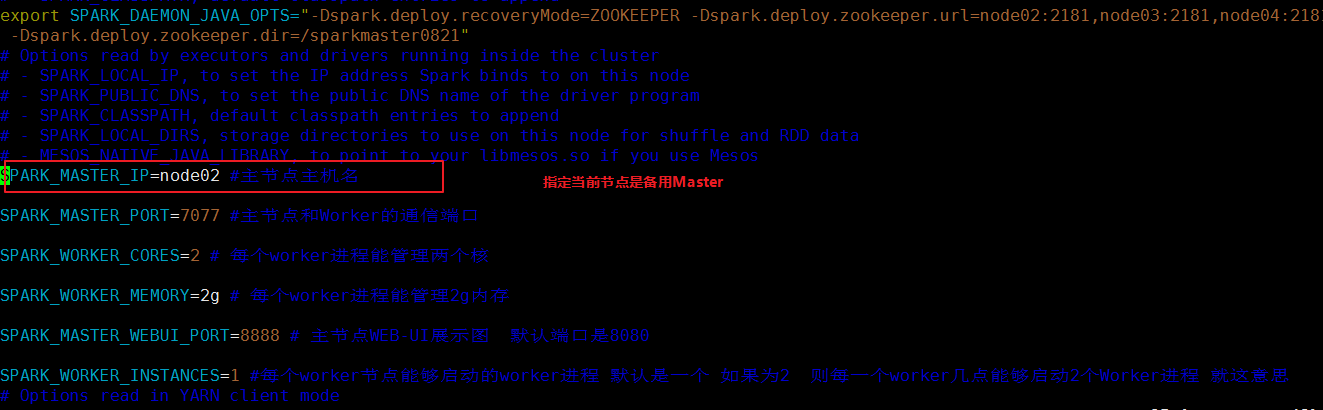
3) 找一台节点(非主Master节点)配置备用 Master,修改spark-env.sh配置节点上的MasterIP:
4) 启动集群之前启动zookeeper集群
5) 在主节点上启动spark Standalone集群:./start-all.sh 在从节点上(node02)启动备用集群:在saprk的Sbin目录下启动备用节点:./start-master.sh
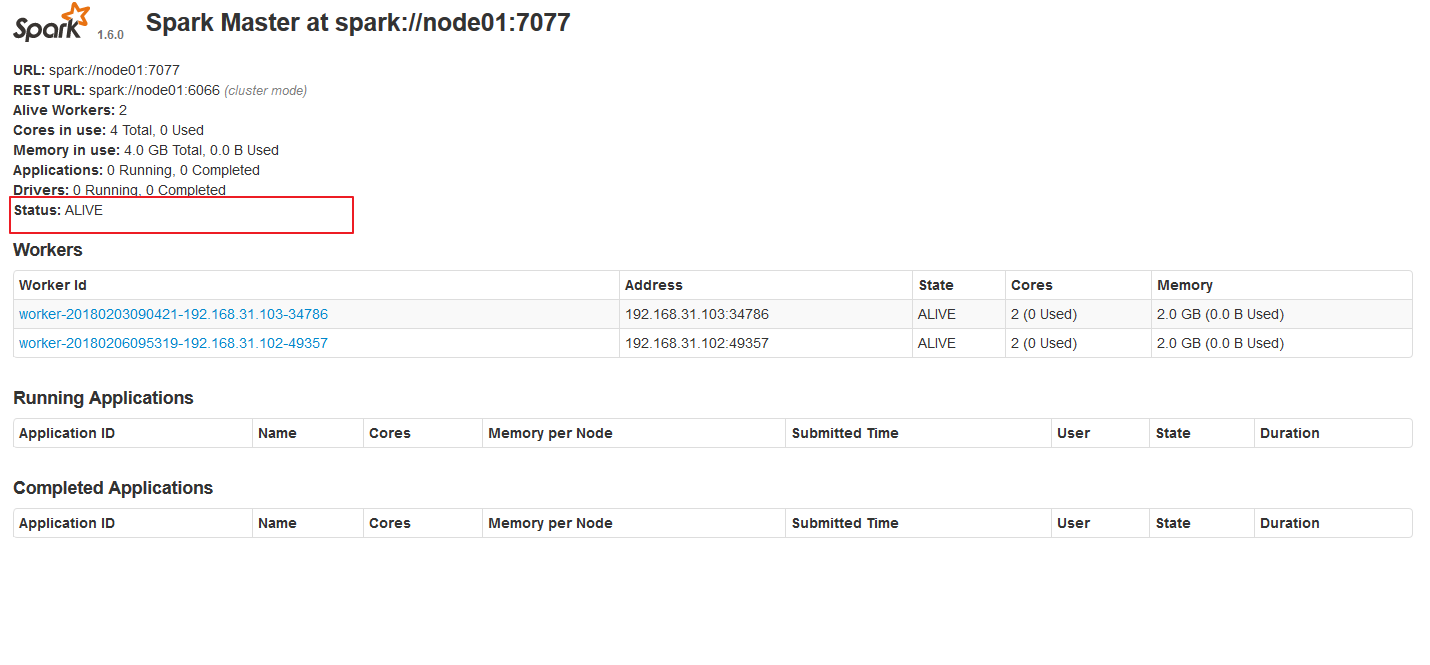
6) 打开主Master和备用Master WebUI页面,观察状态。
主master :
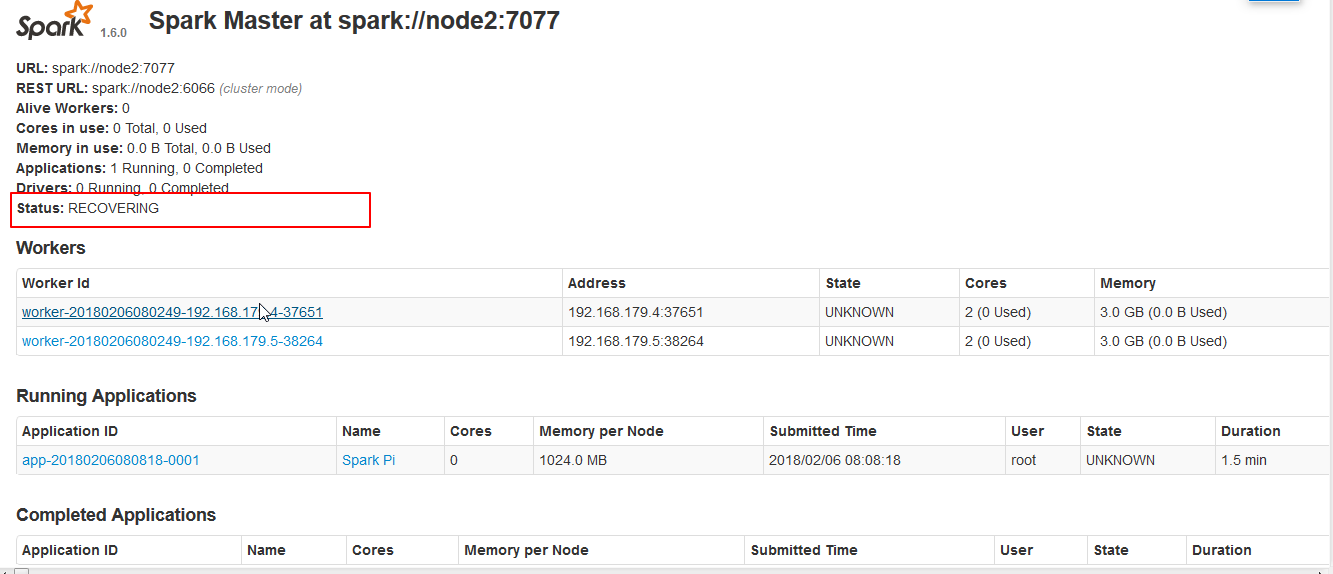
备用Master

切换过程中的Master的状态:
注意:
- 主备切换过程中不能提交Application。
- 主备切换过程中不影响已经在集群中运行的Application。因为Spark是粗粒度资源调,二主要task运行时的通信是和Driver 与Driver无关。
-
提交SparkPi程序应指定主备Master
./spark-submit --master spark://node01:7077,node02:7077 --class org.apache.spark.examples.SparkPi ../lib/spark-examples-1.6.0-hadoop2.6.0.jar 10000
2、配置historyServer
1、临时配置,对本次提交的应用程序起作用
./spark-shell --master spark://node1:7077
--name myapp1
--conf spark.eventLog.enabled=true
--conf spark.eventLog.dir=hdfs://node1:9000/spark/test
停止程序,在Web Ui中Completed Applications对应的ApplicationID中能查看history。
2、spark-default.conf配置文件中配置HistoryServer,对所有提交的Application都起作用
在客户端节点!!!,进入../spark-1.6.0/conf/ spark-defaults.conf最后加入:
//开启记录事件日志的功能
spark.eventLog.enabled true
//设置事件日志存储的目录
spark.eventLog.dir hdfs://node1:9000/spark/test
//设置HistoryServer加载事件日志的位置
spark.history.fs.logDirectory hdfs://node1:9000/spark/test
//日志优化选项,压缩日志
spark.eventLog.compress true
3、启动HistoryServer:./start-history-server.sh
访问HistoryServer:node4:18080,之后所有提交的应用程序运行状况都会被记录。
4040 Driver-web-UI对应端口
8081 Worker对应端口

 浙公网安备 33010602011771号
浙公网安备 33010602011771号