


2020北航面向对象第一单元总结
2020北航面向对象第一单元总结
第一次作业
第一次的作业而言相对简单,只需要对输入的字符串进行解构、保存、求导然后输出四个步骤就完成了,但就我 个人而言,pre进行的预习活动远不能让我对java的基础操作驾轻就熟,因此在第一次作业上远谈不上面向对象的思想,于我而言更像是去熟悉工具的基础上朝着面向对象靠拢,从我个人的理解出发去建造类
**代码度量 **
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Polynomial.main(String[]) | 1 | 4 | 4 |
| Term.Term(String) | 2 | 15 | 19 |
| Term.differential() | 1 | 2 | 2 |
| Term.getCoe() | 1 | 1 | 1 |
| Term.getIndex() | 1 | 1 | 1 |
| Term.plusTerm(BigInteger) | 1 | 1 | 1 |
| TermList.addTerm(Term) | 1 | 2 | 2 |
| TermList.firstPrint() | 3 | 5 | 5 |
| TermList.getMap() | 1 | 1 | 1 |
| TermList.getMonitor() | 1 | 1 | 1 |
| TermList.listPrint(BigInteger) | 3 | 8 | 9 |
UML类图
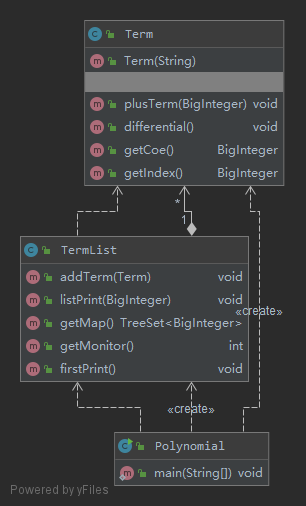
问题
- 第一次作业在主类中分项,在Term类中解析项并保存,在解析时本应该本着对格式进行分析的角度用正则匹配分割,但我使用了字符状态机进行读入,导致如度量所示,Term类个构造函数冗长繁琐又容易出错
- 对类的封装不到位,主函数本应只用生成termlist然后 调用termlist输出,而不与term进行接触,但如类图所示,在termlist的生成时我通过在主函数内生成term加入到termlist中使得耦合更加严重
优化方面第一次作业十分简单,只需要用HashMap保存term类即可实现同类项的合并
第一次作业的bug多数集中在对不输出的判断,在系数为0时多数同学采用不输出,可能最终导致没有输出的情况
第二次作业
第二次作业加入了三角函数,这次的作业其实充分展示了我根深蒂固的面向过程思想,虽然希望写出符合面向对象思想的代码,但是鉴于第一次作业的构造,为了延续第一次作业的思路,我仅仅只是在项的内部加入了对三角函数及其指数的保存,并没有新建类,这也导致了我第三次作业完全只能重构,代码复用性为0,在之后的每次作业当中都应该谨记这次的教训
代码度量
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| GetPoly.dealStart(String) | 2 | 3 | 5 |
| GetPoly.polyRead() | 1 | 1 | 1 |
| GetPoly.rmSpace(String) | 1 | 1 | 1 |
| Index.Index(BigInteger,BigInteger,BigInteger) | 1 | 1 | 1 |
| Index.equals(Object) | 3 | 4 | 5 |
| Index.getCosIndex() | 1 | 1 | 1 |
| Index.getSinIndex() | 1 | 1 | 1 |
| Index.getVarIndex() | 1 | 1 | 1 |
| Index.hashCode() | 1 | 1 | 1 |
| Poly.Poly(String) | 1 | 2 | 2 |
| Poly.addTerm(Term) | 1 | 2 | 2 |
| Poly.differential() | 1 | 4 | 4 |
| Poly.genList() | 1 | 2 | 2 |
| Poly.getWrong() | 1 | 1 | 1 |
| Poly.polyCheck() | 1 | 3 | 5 |
| Poly.print() | 3 | 6 | 6 |
| Poly.simplify() | 5 | 6 | 6 |
| Polynomial.main(String[]) | 1 | 2 | 2 |
| Term.Term(BigInteger,BigInteger,BigInteger,BigInteger) | 1 | 1 | 1 |
| Term.Term(String) | 1 | 6 | 8 |
| Term.change(int) | 1 | 2 | 2 |
| Term.differential(int) | 4 | 4 | 4 |
| Term.getCoef() | 1 | 1 | 1 |
| Term.getCos() | 1 | 1 | 1 |
| Term.getIndex() | 1 | 1 | 1 |
| Term.getSin() | 1 | 1 | 1 |
| Term.getVar() | 1 | 1 | 1 |
| Term.match(Term) | 4 | 6 | 7 |
| Term.noIndex() | 1 | 1 | 1 |
| Term.plusTerm(Term) | 1 | 1 | 1 |
| Term.printTerm(int) | 3 | 13 | 15 |
UML类图
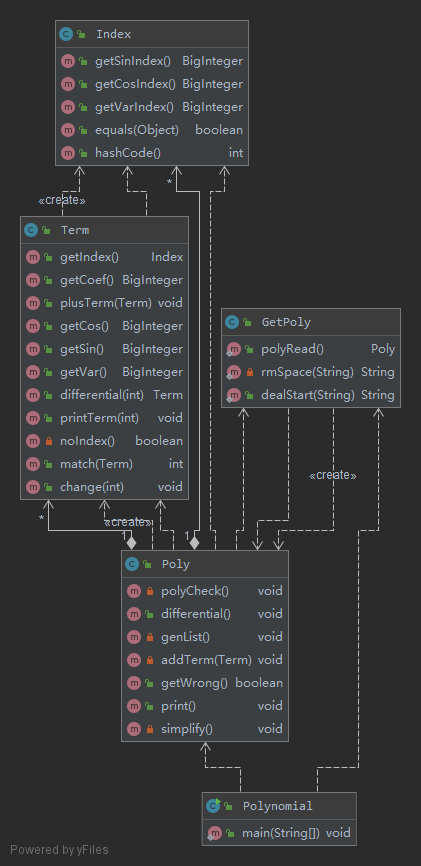
思路
- 为了让第一次的代码得到充分利用延续了第一次的想法(应该改换思路重构的)
- 对多余字符判断并去除
- 按项拆分投入到项解析,因为每一项最多只有三类sin,cos和x,如果不存在则将其指数设为0,将每一项建立一个类
- 将项以指数合集为key存入hashmap中完成第一次合并,然后进行求导,最后再次进行sin2+cos2的合并,输出
问题 - index的使用本身仅仅只是为了合并同类项,是完完全全包含在term当中的属性,因此应该做的是重写term中的comparable接口而不是新建一个index,这导致如度量图中equals的复杂度很高
- 在了解过工厂模式再来回顾本次的作业可以看到GetPoly做的就是Factory应当做的工作 ,但是因为当时并不了解工厂模式,所以建立了这样一个没有属性的读入和处理的方法类属实败笔,并且对于输入字符串的空格等格式处理应该独立于生成子类的类当中,新建一个类,避免耦合,并且用户在对字符串进行处理时能够更加自由,在后续加入更多处理方法时也不需要对原有的代码进行修改
- 两类三角函数和幂函数共处一类,耦合严重,导致三者的求导需要分别实现,使得第三次作业完全无法使用第二次的代码,反映在度量图中printTerm,differential和match的复杂度很高,因为每次进行对应的操作前都需要对类型进行判断,是背离了面向对象思想的
由于这种高耦合的代码在优化过程中也给我造成了困难,在拆项时首先要对含有项进行判断很容易导致tle,因此最后只是简单的进行了一次遍历然后合并处理
在互测部分主要的问题集中于wf和tle的问题,部分同学因为指数大小或格式的原因将正确的式子误判成wf,而部分优化的同学则递归过深导致超时,由于中测的存在,求导出错的同学实际上并不多
第三次作业
第三次作业相对前两次作业的难度得到了显著的提升,不过首先我确定了的是第一次和第二次作业的代码和想法对于这一次都没有什么用处。这一次的想法最开始是得到指导书中提示的启发,然后在和同学的讨论过程当中逐步成型,相比于前两次的作业,这次的作业向面向对象靠拢了一些,但是不得不承认的是耦合度以及单类的复杂程度还是很高,并且类以及类内方法不够有序和有逻辑,这就导致在互测结束debug的时候我甚至不愿意读自己的代码,更不用说几个月后还能够理解代码了,因此在之后的作业我要争取不仅符合checkstyle的代码规范,更要使代码美观、易于理解和有逻辑性。
代码度量
| Method | ev(G) | iv(G) | v(G) |
|---|---|---|---|
| Constant.Constant(String) | 1 | 1 | 1 |
| Constant.differential() | 1 | 1 | 1 |
| Constant.origin() | 1 | 1 | 1 |
| Constant.setNum(BigInteger) | 1 | 1 | 1 |
| Contain.Contain(String) | 1 | 9 | 13 |
| Contain.differential() | 4 | 4 | 4 |
| Contain.getIndex() | 1 | 1 | 1 |
| Contain.origin() | 1 | 1 | 1 |
| GetPoly.checkIn(String) | 7 | 6 | 8 |
| GetPoly.indexCheck(String) | 3 | 3 | 4 |
| GetPoly.modify(String) | 1 | 4 | 5 |
| GetPoly.polyCheck(String) | 5 | 4 | 28 |
| GetPoly.polyRead() | 4 | 2 | 4 |
| GetPoly.spaceCheck(String) | 10 | 4 | 12 |
| GetPoly.splitTerm(String) | 1 | 4 | 11 |
| GetPoly.termCheck(String) | 10 | 9 | 13 |
| Multiply.Multiply(String) | 4 | 4 | 6 |
| Multiply.addTerm(ArrayList |
1 | 13 | 13 |
| Multiply.differential() | 5 | 5 | 5 |
| Multiply.getIn(String) | 2 | 2 | 2 |
| Multiply.splitTerm(String) | 1 | 4 | 11 |
| Plus.Plus(String) | 2 | 4 | 27 |
| Plus.differential() | 1 | 2 | 2 |
| Plus.origin() | 1 | 1 | 1 |
| Poly.Poly(String,boolean) | 1 | 1 | 1 |
| Poly.differential() | 1 | 1 | 1 |
| Poly.generate() | 1 | 1 | 1 |
| Poly.getWrFmt() | 1 | 1 | 1 |
| Polynomial.main(String[]) | 1 | 2 | 2 |
| Polynomial.printOut(String) | 1 | 6 | 6 |
| Power.differential() | 2 | 2 | 2 |
| Power.getIndex() | 1 | 1 | 1 |
| Power.origin() | 1 | 1 | 1 |
| Power.setPower(int) | 1 | 1 | 3 |
| Triangle.Triangle(int,int) | 1 | 1 | 1 |
| Triangle.differential() | 4 | 4 | 4 |
| Triangle.getIndex() | 1 | 1 | 1 |
| Triangle.origin() | 1 | 1 | 1 |
| Triangle.setIndex(int) | 1 | 1 | 1 |
| Triangle.setPoly() | 1 | 1 | 6 |
思路
- 首先处理空白字符,在排除所有空白字符可能导致wf的原因后删除所有的空白字符使后续的处理更加方便
- 其次处理指数符号以及sin,cos对应的括号,将**->^,sin()->sin[],这样在解析字符串时就会方便一些,并且在最后只需要再替换回来就可以了
- 处理wf问题,递归的拆分字符串直到匹配到不符合规定的字符串返回
- 对每一种关系和底层函数建立类,实现同一个接口中返回本身和返回求导两种方法,递归拆分字符串然后求导输出
问题
- 依旧是第二次作业中的GetPoly,应该拆分成Factory,字符串检查,字符串处理三个类
- 在wf的判断和字符串的解析过程中有大量相似的代码,因为他们的拆分过程都一样,只是在最后对拆分得到的结果的处理不同,而我在实现这部分代码的时候为图不出错和快捷则是直接复制了拆分部分的代码,导致了如上表代码度量中split的重复出现,部分方法的冗余,体现出的复杂度极高,polyCheck和Plus的构造函数也是十分相似,因此二者在v(G)复杂程度上甚至达到了27和28,也因此我最后在Plus类中出现了bug,丢掉了5个强测点,代码的复杂度过高确实会导致bug的频繁发生,在后续的作业中会尽量降低每个方法的复杂度
- 过多的使用if-else语句并且分支过多导致代码显得非常乱且难以阅读
- 在求导部分有很多可以合并的步骤,但我都分到了具体的分支下,增加代码量和复杂程度
本次我的优化几乎是0,只有在单个项进行了合并,在输出项时对空项采取了不输出,因为比较害怕在强测中错点和产生tle,所以没有进行合并和去括号(此处以后改正,作业的目的还是让我们精益求精的过程中锻炼自己的能力)
我的代码在本次产生了巨大的bug就是在返回表达式中没有添加外层括号,导致一个表达式分裂开来,在互测中我发现较多的bug就是优化的同学在输入嵌套层数过多时会超时,也有一部分同学在特殊情况下输出是空
测试情况
我在这三次的作业当中都采用的是人工生成代码并比对,不得不说这样的效率太低,虽然能够发现一些一般数据测不出的错误,但相应的有时就会无法发现一些显而易见的错误,就像是第三次作业中我的bug,如果用自动评测机可能不出半个小时就会发现错误,而且人工比结果效率低切容易出错,对于第三次作业的结果更是几乎无法比对,建立一个评测机对于我们的作业来讲还是十分重要的
在hack部分,我多数情况下使用的都是我在构造时遇到的bug或者是我有意避开的bug,阅读代码进行针对性bug构造在第一次尝试过,这种构造方式在A屋时较为有效,在C屋则可能效率不足,并且读代码时尽量针对难点较高部分或者复杂程度高的部分阅读
创建模式与心得体会
我的第一二次作业还略微的具有连贯性,但是到了第三次就轰然崩塌,究其原因还是耦合度的问题,前两次过高的耦合度无法满足第三次的需求,三角函数与幂函数粘合在一起,类的产生和错误模式分析在一起,导致了第三次的重构。
重构的效果也并不理想,因为没有采用合理的模式方法而是自顾自的写下去。尽管第三次的作业类似简单工厂模式,但是还是没有完全发挥工厂模式的特点,仅仅让子类都实现了一个接口,在Factory方面还需要进一步的改进,另外在第一二次作业中,判断和生成都是交由主函数来做的,这也是极为不好的点。
第一单元的作业对我而言是第一次实打实的开始使用面向对象的思想去写一次代码,如果说面向过程就是像我一二次作业的判断、解析、保存然后求导输出这种按照计算机工作流程来编写代码的话,面向对象就更类似我们去创建项,分析这个项怎么得到的,能够做什么,然后在工厂中创建对应的对象,然后在主函数中对我们的对象发出命令,让他完成我们希望他做的并且从定义上他能够做到的事情。
这三次的作业让我认识到了很多以前没有认识到的问题,其一是代码的风格,从命名到分类,好的风格才能写出有逻辑的代码;其二是类的构建,面向对象并不是你要他去做什么就去构造一个类来让他做这件事,这样就让方法变成了函数,面向对象更应该是你需要什么然后去构造他最后规定他能够做什么;其三就是耦合度与复杂度的问题,在数据结构课中,我们是为达目的不择手段,复制粘贴,函数只在必要时如递归时构造,每一条代码都是为了推进答案到达下一个阶段,而面向对象更像是我们找齐了工具,然后简单的完成我们的工作,甚至下一次工作有了变动我们的工具还能够使用,因此我们编写时一定保证独立性,才能够进一步的去达到复用性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号