



3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。

2.请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster Manager
DAGScheduler, TaskScheduler.
Master<--->Worker <--Executor(挂载)
Master与worker的关系可以归为Master管理Worker,Worker通过Master提交,Master就发送使用调度算法给Application分配资源,完成消息的传递,实际的操作交给Worker
RDD为弹性数据集,具体操作过程中有简化计算过程的能里,Spark中只有遇到action才会执行RDD的计算,可以不用管中间结果,并且支持缓存,在内存中计算
Driver:即main函数并且构造sparkcontext对象,然后向executor申请资源,管理一个应用
Executor:挂载在Worker节点上,为程序要求缓存的RDD提供内存式存储,负责内存管理
Manager:管理应用执行过程中的资源分配
Cluster Manger:在基于standalone的Spark集群,Cluster Manger就是Master。
DAGScheduler:划分阶段,形成一系列的TaskSet,然后传给TaskScheduler,把具体的Task交给Worker节点上的Executor的线程池处理。线程池中的线程工作,通过BlockManager来读写数据。
DASGScheduler->TaskSet->TaskScheduler->Executor
Job:调用RDD的一个action,如count,即触发一个Job
Stage :表示一个Job的DAG,会在发生shuffle处被切分,切分后每一个部分即为一个Stage
Task : 最终被发送到Executor执行的任务
Driver由框架直接生成;
Executor执行的才是我们的业务逻辑代码。
执行的时候,框架控制我们代码的执行。Executor需要执行的结果汇报给框架也就是Driver。

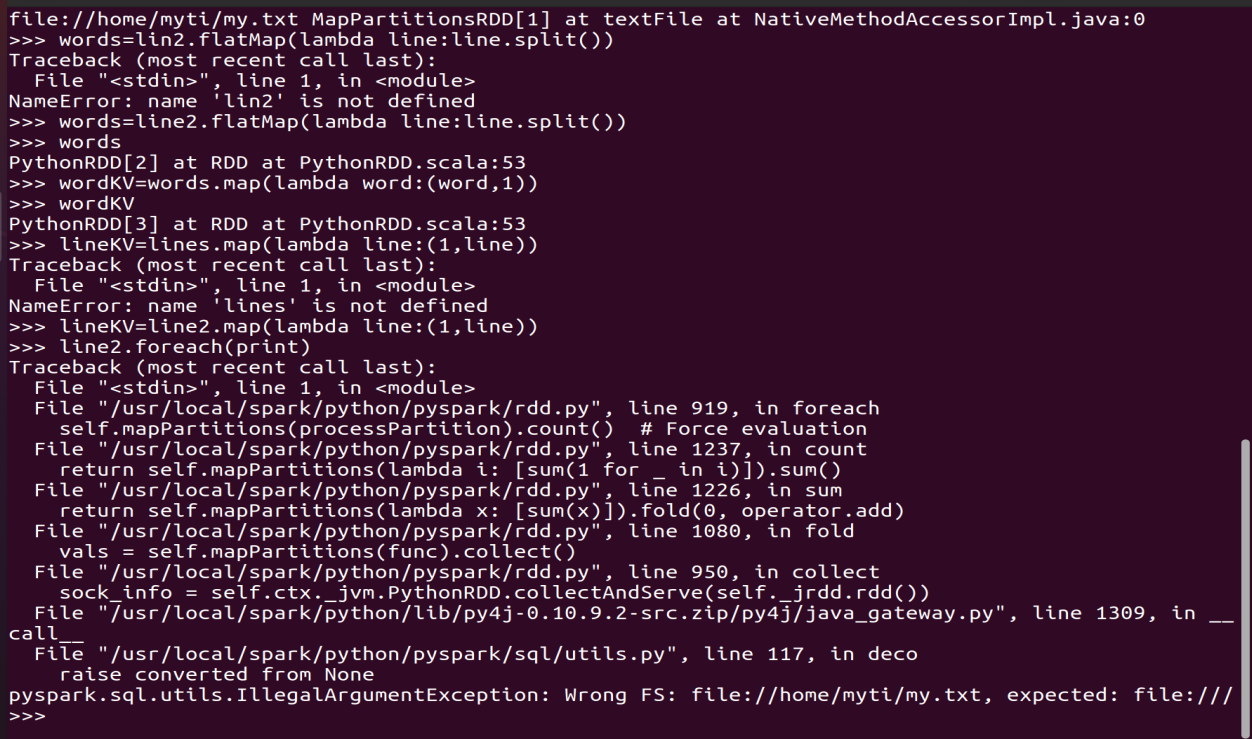
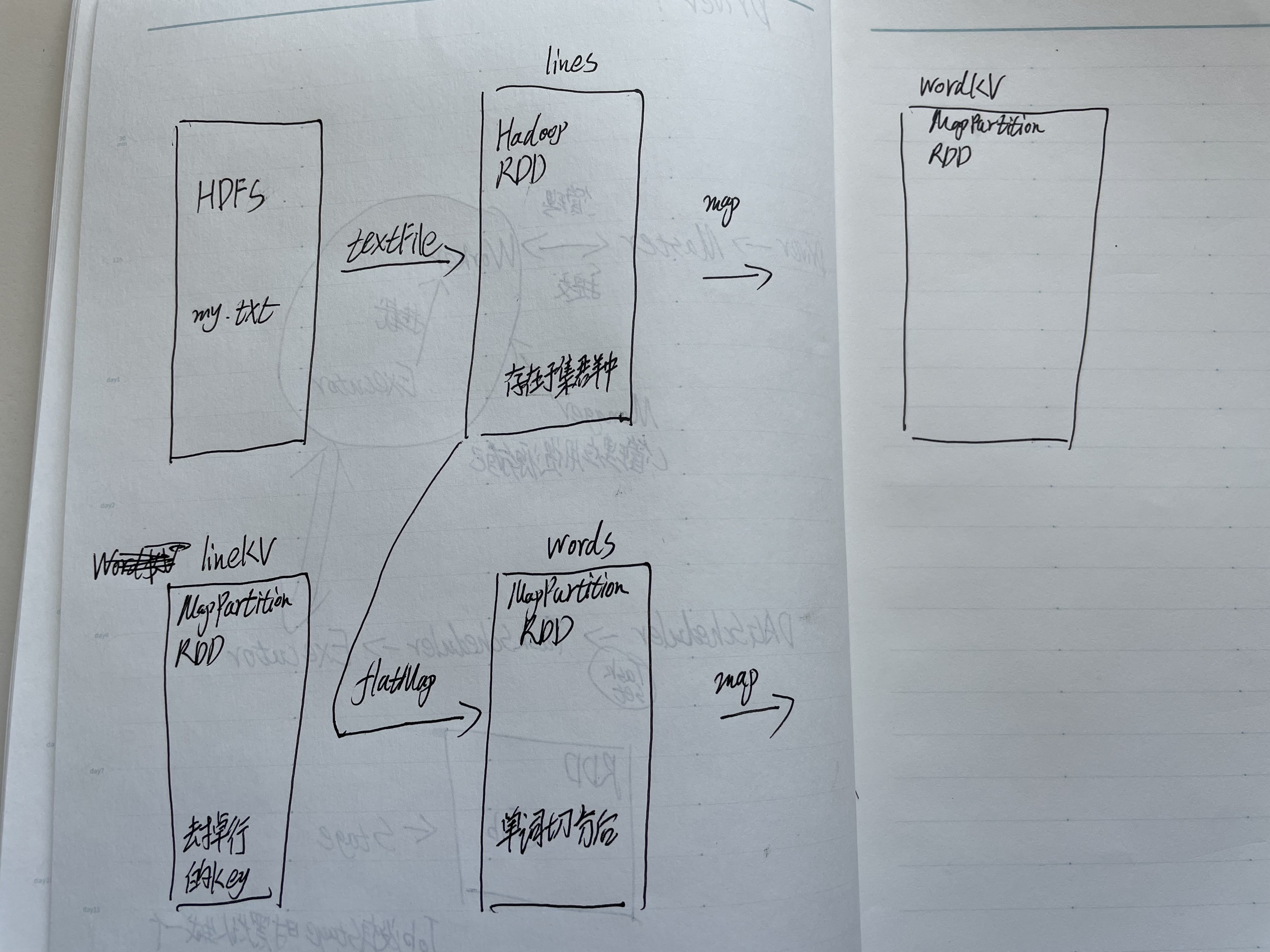
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。
>>> sc
>>> lines = sc.textFile("file:///home/hadoop/my.txt")
>>> lines
>>> words=lines.flatMap(lambda line:line.split())
>>> words
>>> wordKV=words.map(lambda word:(word,1))
>>> wordKV
>>> lineKV=lines.map(lambda line:(1,line))
>>> lineKV
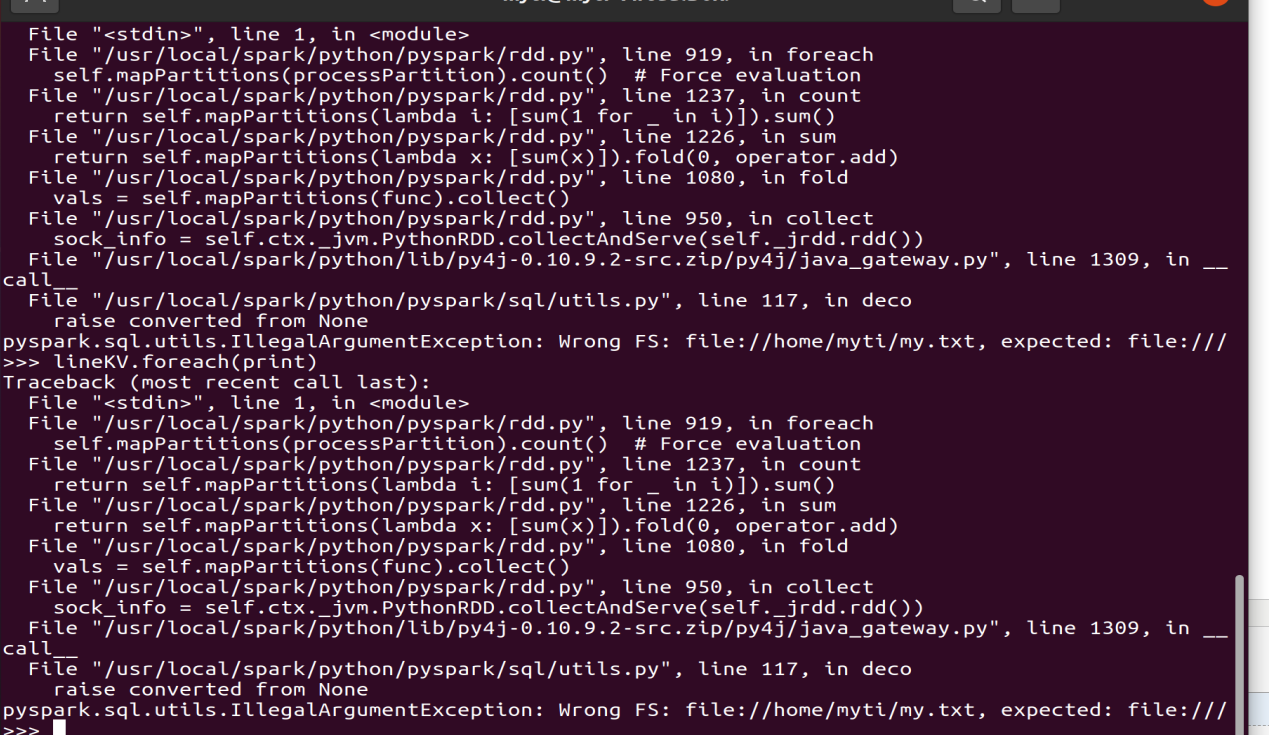
>>> lines.foreach(print)
>>> words.foreach(print)
>>>wordKV.foreach(print)
>>>lineKV.foreach(print)
自己生成sc
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("My App")
sc=SparkContext(conf=conf)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号