

爬虫小案例:联想词汇搜索
数据来源:http://ictclas.nlpir.org/nlpir/ (一个很牛逼的网站,上面有非常多的处理语言的功能(如分词标注、情感分析、相关词汇))
当然这个网站还有其他的功能,像“分词标注”,就是把你输入的文本切成一个个的词,并且把这些词的词性都标出来;
还有“情感分析”的功能,就是分析你输入的文本里面“乐”、“恶”、“怒”、“哀”等情绪的占比是多少......
可是,这些功能的意义在哪呢?
在人工智能领域里,有一个很重要的领域,叫自然语言处理(NLP)。NLP致力于让计算机听懂人的话,理解人的话,在此基础上,人与计算机才有对话的可能。
而这个处理语言的网站的主要功能(如分词标注、情感分析、关键词提取、相关词汇等),就是NLP中的核心的底层技术。
我们所理解的siri、小爱同学、微软小冰,这些可以和人交流的对话系统,也是建构在NLP之上的。
无论最后建成的大楼有多么宏伟,都不可缺少坚实的地基。而对词语的基本处理,就是人工智能的一种“地基”,所以大家不要小觑这个网站中对语言处理的基本功能。
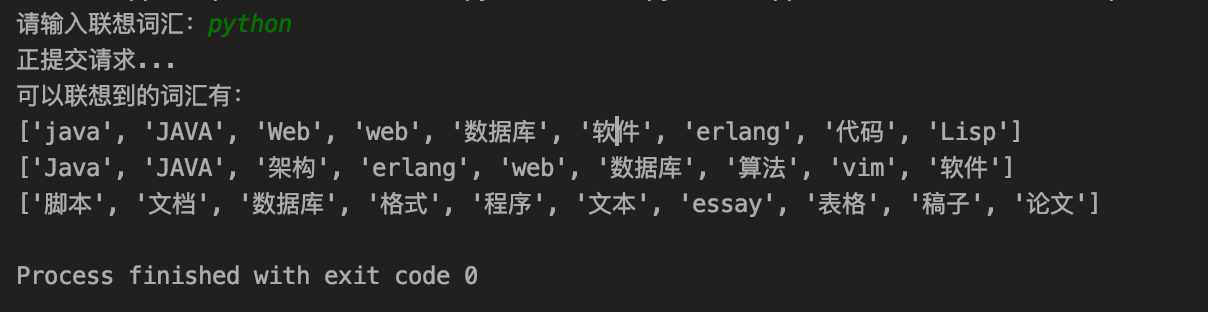
import requests url = 'http://ictclas.nlpir.org/nlpir/index6/getWord2Vec.do' headers = { 'referer':'http://ictclas.nlpir.org/nlpir/', 'user-agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36 OPR/65.0.3467.78 (Edition Baidu)' } data = { 'content':input('请输入联想词汇:') } print('正提交请求...') res = requests.post(url, headers=headers, data=data) if res.status_code == 200: # 分析 vjsons =res.json()['vjson'] words = [] for value in vjsons.values(): word = [] for i in value: word.append(i.split(',')[0]) words.append(word) print('可以联想到的词汇有:') for i in words: print(i) else: print('服务器请求失败!')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号