21-WEB服务器
WEB服务器
内容
- HTTP
- WEB服务器
- 网络通信
- 正则表达式
HTTP协议
在Web应用中,服务器把网页传给浏览器,实际上就是把网页的HTML代码发送给浏览器,让浏览器显示出来。而浏览器和服务器之间的传输协议是HTTP,所以:
- HTML是一种用来定义网页的文本,会HTML,就可以编写网页;
- HTTP是在网络上传输HTML的协议,用于浏览器和服务器的通信。
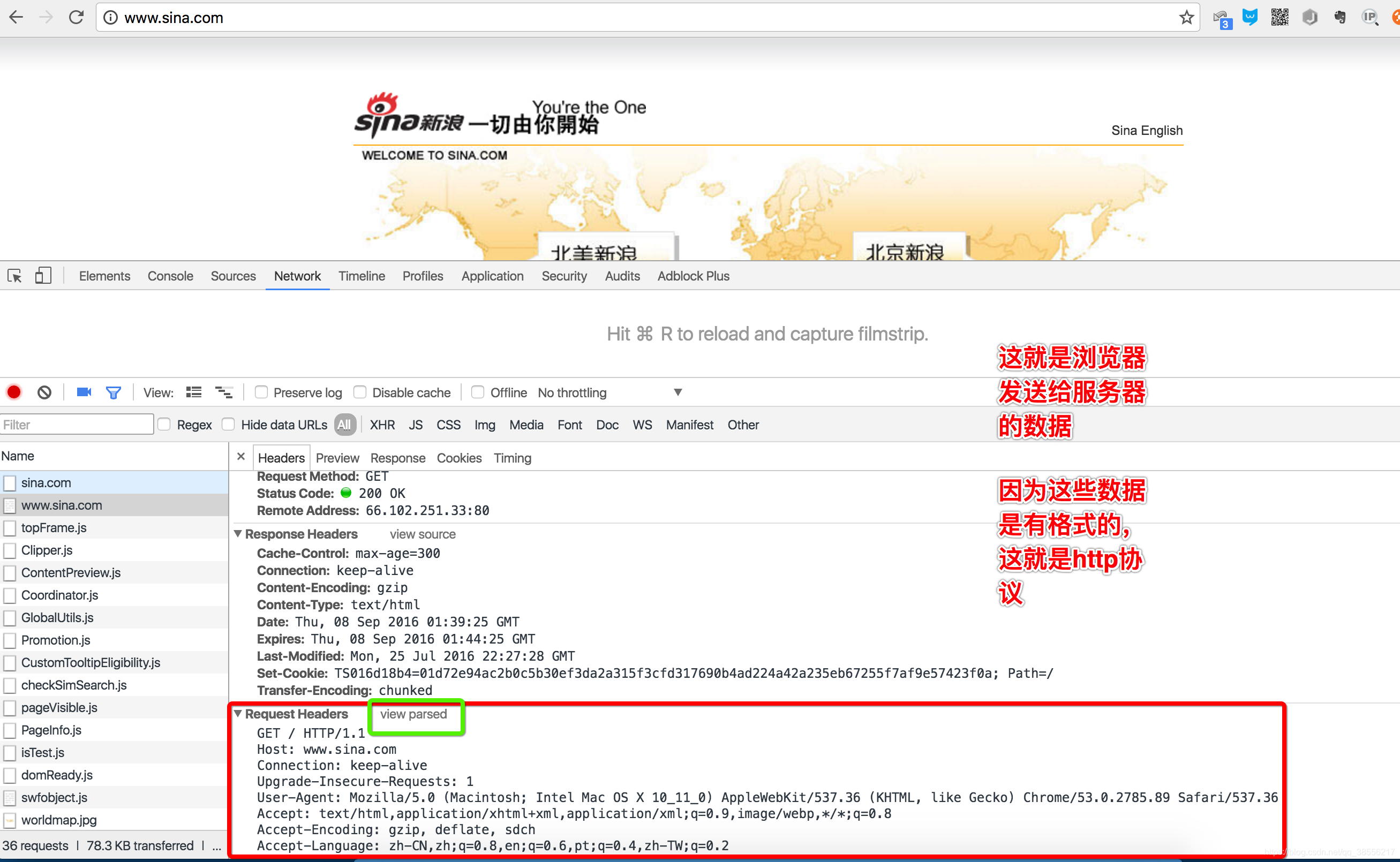
说明
最主要的头两行分析如下,第一行:
GET / HTTP/1.1
GET表示一个读取请求,将从服务器获得网页数据,/表示URL的路径,URL总是以/开头,/就表示首页,最后的HTTP/1.1指示采用的HTTP协议版本是1.1。目前HTTP协议的版本就是1.1,但是大部分服务器也支持1.0版本,主要区别在于1.1版本允许多个HTTP请求复用一个TCP连接,以加快传输速度。
从第二行开始,每一行都类似于Xxx: abcdefg:
Host: www.sina.com
表示请求的域名是www.sina.com。如果一台服务器有多个网站,服务器就需要通过Host来区分浏览器请求的是哪个网站。
WEB服务器
多线程版:
#coding=utf-8
import socket
import re
import threading
class WSGIServer(object):
def __init__(self, server_address):
# 创建一个tcp套接字
self.listen_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 允许立即使用上次绑定的port
self.listen_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
# 绑定
self.listen_socket.bind(server_address)
# 变为被动,并制定队列的长度
self.listen_socket.listen(128)
def serve_forever(self):
"循环运行web服务器,等待客户端的链接并为客户端服务"
while True:
# 等待新客户端到来
client_socket, client_address = self.listen_socket.accept()
print(client_address)
new_process = threading.Thread(target=self.handleRequest, args=(client_socket,))
new_process.start()
# 因为线程是共享同一个套接字,所以主线程不能关闭,否则子线程就不能再使用这个套接字了
# client_socket.close()
def handleRequest(self, client_socket):
"用一个新的进程,为一个客户端进行服务"
recv_data = client_socket.recv(1024).decode('utf-8')
print(recv_data)
requestHeaderLines = recv_data.splitlines()
for line in requestHeaderLines:
print(line)
request_line = requestHeaderLines[0]
get_file_name = re.match("[^/]+(/[^ ]*)", request_line).group(1)
print("file name is ===>%s" % get_file_name) # for test
if get_file_name == "/":
get_file_name = DOCUMENTS_ROOT + "/index.html"
else:
get_file_name = DOCUMENTS_ROOT + get_file_name
print("file name is ===2>%s" % get_file_name) # for test
try:
f = open(get_file_name, "rb")
except IOError:
response_header = "HTTP/1.1 404 not found\r\n"
response_header += "\r\n"
response_body = "====sorry ,file not found===="
else:
response_header = "HTTP/1.1 200 OK\r\n"
response_header += "\r\n"
response_body = f.read()
f.close()
finally:
client_socket.send(response_header.encode('utf-8'))
client_socket.send(response_body)
client_socket.close()
# 设定服务器的端口
SERVER_ADDR = (HOST, PORT) = "", 8888
# 设置服务器服务静态资源时的路径
DOCUMENTS_ROOT = "./html"
def main():
httpd = WSGIServer(SERVER_ADDR)
print("web Server: Serving HTTP on port %d ...\n" % PORT)
httpd.serve_forever()
if __name__ == "__main__":
main()
Web静态服务器-gevent版
from gevent import monkey
import gevent
import socket
import sys
import re
monkey.patch_all()
class WSGIServer(object):
"""定义一个WSGI服务器的类"""
def __init__(self, port, documents_root):
# 1. 创建套接字
self.server_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2. 绑定本地信息
self.server_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
self.server_socket.bind(("", port))
# 3. 变为监听套接字
self.server_socket.listen(128)
self.documents_root = documents_root
def run_forever(self):
"""运行服务器"""
# 等待对方链接
while True:
new_socket, new_addr = self.server_socket.accept()
gevent.spawn(self.deal_with_request, new_socket) # 创建一个协程准备运行它
def deal_with_request(self, client_socket):
"""为这个浏览器服务器"""
while True:
# 接收数据
request = client_socket.recv(1024).decode('utf-8')
# print(gevent.getcurrent())
# print(request)
# 当浏览器接收完数据后,会自动调用close进行关闭,因此当其关闭时,web也要关闭这个套接字
if not request:
new_socket.close()
break
request_lines = request.splitlines()
for i, line in enumerate(request_lines):
print(i, line)
# 提取请求的文件(index.html)
# GET /a/b/c/d/e/index.html HTTP/1.1
ret = re.match(r"([^/]*)([^ ]+)", request_lines[0])
if ret:
print("正则提取数据:", ret.group(1))
print("正则提取数据:", ret.group(2))
file_name = ret.group(2)
if file_name == "/":
file_name = "/index.html"
file_path_name = self.documents_root + file_name
try:
f = open(file_path_name, "rb")
except:
# 如果不能打开这个文件,那么意味着没有这个资源,没有资源 那么也得需要告诉浏览器 一些数据才行
# 404
response_body = "没有你需要的文件......".encode("utf-8")
response_headers = "HTTP/1.1 404 not found\r\n"
response_headers += "Content-Type:text/html;charset=utf-8\r\n"
response_headers += "Content-Length:%d\r\n" % len(response_body)
response_headers += "\r\n"
send_data = response_headers.encode("utf-8") + response_body
client_socket.send(send_data)
else:
content = f.read()
f.close()
# 响应的body信息
response_body = content
# 响应头信息
response_headers = "HTTP/1.1 200 OK\r\n"
response_headers += "Content-Type:text/html;charset=utf-8\r\n"
response_headers += "Content-Length:%d\r\n" % len(response_body)
response_headers += "\r\n"
send_data = response_headers.encode("utf-8") + response_body
client_socket.send(send_data)
# 设置服务器服务静态资源时的路径
DOCUMENTS_ROOT = "./html"
def main():
"""控制web服务器整体"""
# python3 xxxx.py 7890
if len(sys.argv) == 2:
port = sys.argv[1]
if port.isdigit():
port = int(port)
else:
print("运行方式如: python3 xxx.py 7890")
return
print("http服务器使用的port:%s" % port)
http_server = WSGIServer(port, DOCUMENTS_ROOT")
http_server.run_forever()
if __name__ == "__main__":
main()
网络通信
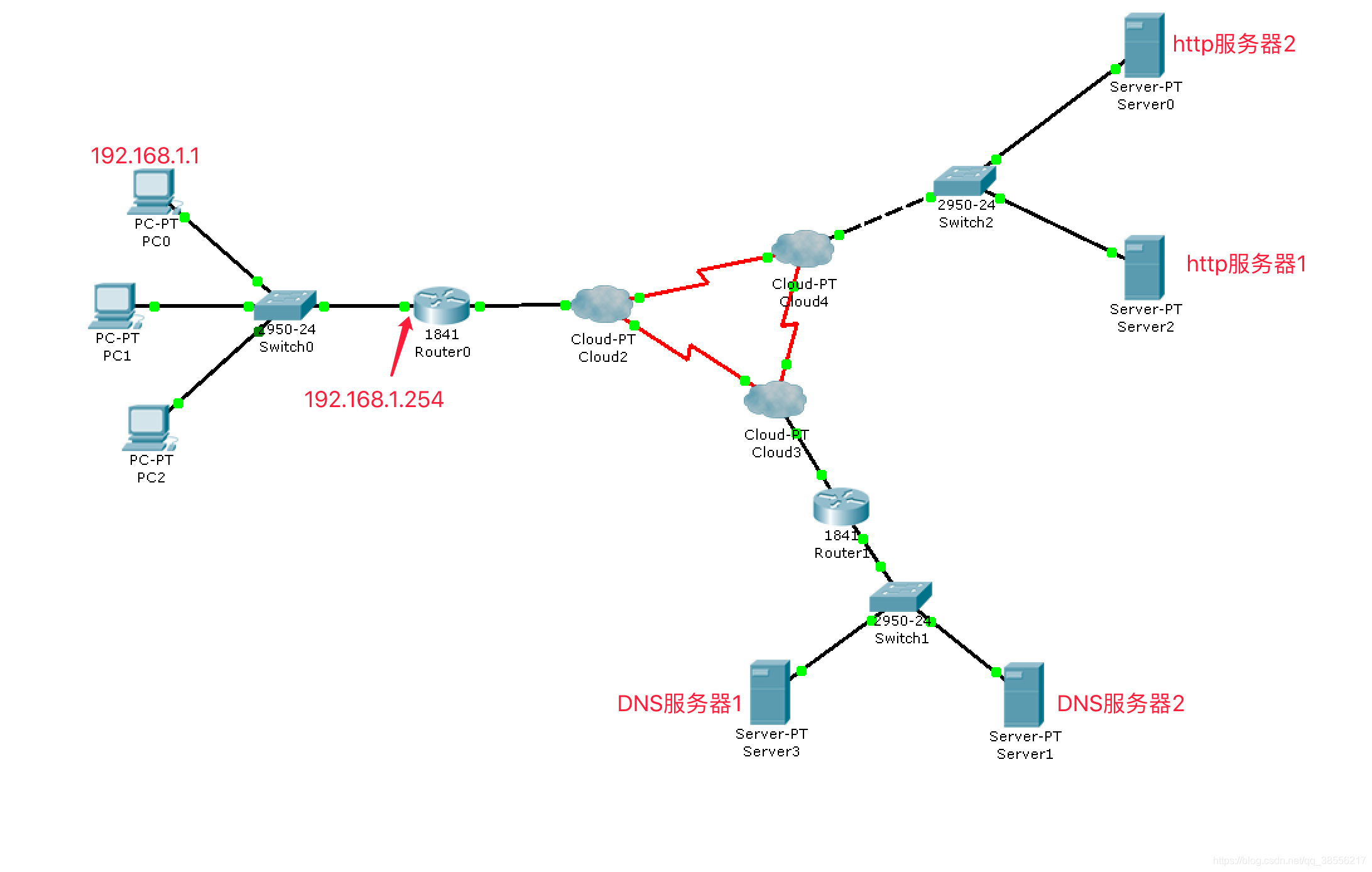
说明
- 在浏览器中输入一个网址时,需要将它先解析出ip地址来
- 当得到ip地址之后,浏览器以tcp的方式3次握手链接服务器
- 以tcp的方式发送http协议的请求数据 给 服务器
- 服务器tcp的方式回应http协议的应答数据 给浏览器总结
总结
- MAC地址:在设备与设备之间数据通信时用来标记收发双方(网卡的序列号)
- IP地址:在逻辑上标记一台电脑,用来指引数据包的收发方向(相当于电脑的序列号)
- 网络掩码:用来区分ip地址的网络号和主机号
- 默认网关:当需要发送的数据包的目的ip不在本网段内时,就会发送给默认的一台电脑,成为网关
- 集线器:已过时,用来连接多态电脑,缺点:每次收发数据都进行广播,网络会变的拥堵
- 交换机:集线器的升级版,有学习功能知道需要发送给哪台设备,根据需要进行单播、广播
- 路由器:连接多个不同的网段,让他们之间可以进行收发数据,每次收到数据后,ip不变,但是MAC地址会变化
- DNS:用来解析出IP(类似电话簿)
- http服务器:提供浏览器能够访问到的数据
正则表达式
re模块
操作在Python中需要通过正则表达式对字符串进行匹配的时候,可以使用一个模块,名字为re
-
re模块的使用过程
#coding=utf-8 # 导入re模块 import re # 使用match方法进行匹配操作 result = re.match(正则表达式,要匹配的字符串) # 如果上一步匹配到数据的话,可以使用group方法来提取数据 result.group()
- re.match() 能够匹配出以xxx开头的字符串
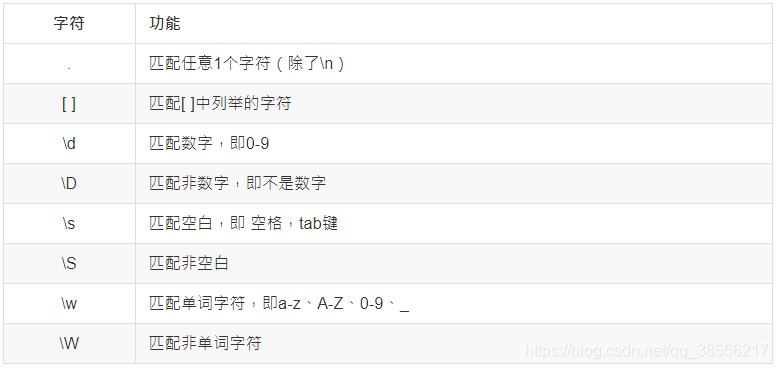
匹配单个字符
匹配多个字符
匹配多个字符的相关格式
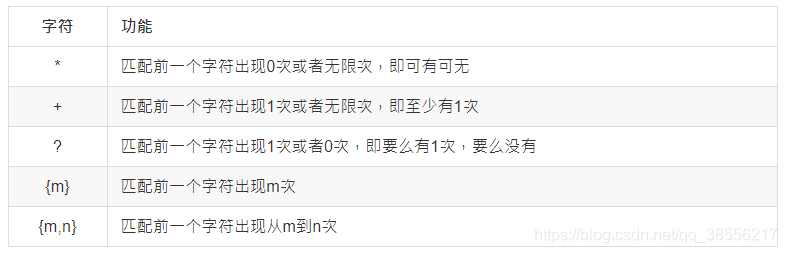
示例1:*
需求:匹配出,一个字符串第一个字母为大小字符,后面都是小写字母并且这些小写字母可有可无
#coding=utf-8
import re
ret = re.match("[A-Z][a-z]*","M")
print(ret.group())
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
运行结果:
M
Mnn
Aabcdef
示例2:+
需求:匹配出,变量名是否有效
#coding=utf-8
import re
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[\w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)
运行结果:
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 __name__ 符合要求
示例3:?
需求:匹配出,0到99之间的数字
#coding=utf-8
import re
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?\d","33")
print(ret.group())
ret = re.match("[1-9]?\d","09")
print(ret.group())
运行结果:
7
33
0 # 这个结果并不是想要的,利用$才能解决
示例4:{m}
需求:匹配出,8到20位的密码,可以是大小写英文字母、数字、下划线
#coding=utf-8
import re
ret = re.match("[a-zA-Z0-9_]{6}","12a3g45678")
print(ret.group())
ret = re.match("[a-zA-Z0-9_]{8,20}","1ad12f23s34455ff66")
print(ret.group())
运行结果:
12a3g4
1ad12f23s34455ff66
匹配开头结尾

示例1:$
需求:匹配163.com的邮箱地址
#coding=utf-8
import re
email_list = ["xiaoWang@163.com", "xiaoWang@163.comheihei", ".com.xiaowang@qq.com"]
for email in email_list:
ret = re.match("[\w]{4,20}@163\.com$", email)
if ret:
print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group()))
else:
print("%s 不符合要求" % email)
运行结果:
xiaoWang@163.com 是符合规定的邮件地址,匹配后的结果是:xiaoWang@163.com
xiaoWang@163.comheihei 不符合要求
.com.xiaowang@qq.com 不符合要求

 浙公网安备 33010602011771号
浙公网安备 33010602011771号