
2024 CCF BDCI 小样本条件下的自然语言至图查询语言翻译大模型微调|Google T5预训练语言模型训练与PyTorch框架的使用
代码详见 https://gitee.com/wang-qiangsy/bdci
目录
一.赛题介绍
1.赛题背景
现代关系型数据库使用SQL(Structured Query Language)作为查询语言,由于SQL语言本身复杂的特性,只有少数研发工程师和数据分析师能够熟练使用数据库。但是随着大语言模型技术的发展,及Text2Sql数据集的不断完善,经过大量Text2Sql数据集训练后的大模型已经初步具备了将自然语言翻译成可执行的SQL语句的能力,极大的降低了关系型数据库的使用门槛。
同样的,在图数据库领域也存在相似的问题,甚至更为严峻。由于图数据库本身并没有统一的查询语言,目前是多种查询语法并存的状态,使用门槛比关系型数据库更高。即便想要使用大模型技术将自然语言翻译成可执行的图查询语言,依然面临着缺乏Text2Sql领域海量语料的困难。如何通过每一种图查询语言现有的少量语料,微调出一个可以高质量的将自然语言翻译成对应图查询语言的大模型,并以此降低图数据库的使用门槛,成为了现阶段的一个重要研究方向。
2.赛题任务
参赛者需要使用提供的在TuGraph-DB上可执行的Cypher语料,对一个指定的本地模型进行微调,使得微调后的模型能够准确的将测试集中的自然语言描述翻译成对应的Cypher语句,翻译结果将基于文本相似度和语法正确性两个方面综合评分。
二.关于Google T5预训练语言模型
1.T5模型主要特点
- 统一框架
T5将输入和输出格式化为纯文本字符串。 - 基于Transformer架构
T5采用标准的Transformer模型架构,包含一个编码器和一个解码器。与GPT相比,其双向编码器和自回归解码器相结合,更适合生成式任务。 - 多任务学习
T5在一个包含各种任务的超大数据集上进行预训练,使模型能够适应不同任务的切换。 - 开放的预训练与微调方式
预训练:使用了C4(Colossal Clean Crawled Corpus)数据集,重点清洗了Web文本。
微调:通过特定任务的数据集进一步优化。
2.T5模型与赛题任务的适配性分析
- 文本到文本统一框架
由于T5本质是一个将所有任务转化为文本输入和文本输出的模型,具有将输入和输出格式化为纯文本字符串的特点,所以正好与“自然语言描述到Cypher语句翻译”这一任务匹配。 - 生成式任务能力
T5在多任务训练中积累了强大的生成能力,Cypher语句是一种结构化查询语言,其语法较为固定,T5的自回归生成解码器在确保生成语句语法正确性方面具有优势。 - 迁移学习的可扩展性
通过在提供的Cypher语料上微调,T5能够快速适配新任务,达到较高的准确率和生成质量。
3.模型的优化
- 指令调优
- 数据增强
- 知识注入
- 模型蒸馏
三.解题思路
1.数据准备
- 加载Schema文件:从指定路径加载movie.json,yago.json,the_three_body.json和finbench.json的Schema文件,并将其存储在一个字典中。每个Schema文件描述了一个数据库的结构,包括节点(VERTEX)和边(EDGE)的定义及其属性。
- 加载训练数据:从指定路径加载训练数据train_cypher,训练数据包含自然语言描述和对应的Cypher语句。
2.数据处理
- 定义数据集类:我们先是使用CypherDataset类将训练数据和Schema结合起来,然后使用Tokenizer将自然语言描述和目标Cypher语句编码为模型可接受的格式。(详细代码中的__getitem__方法中,将自然语言描述和对应的Schema结合,构建输入文本。使用Tokenizer对输入文本和目标文本进行编码,返回模型所需的张量格式数据。)
3.模型训练
- 初始化模型和Tokenizer:使用预训练的T5模型和对应的Tokenizer。
- 创建数据集实例:使用CypherDataset类创建训练数据集,使用Tokenizer将自然语言描述和目标Cypher语句编码为模型可接受的格式。
- 设置训练参数:使用TrainingArguments类设置训练参数,如训练轮数、批次大小、学习率等。
- 创建Trainer实例:使用Trainer类进行模型训练,Trainer类封装了训练过程中的许多细节,如梯度计算、参数更新、模型保存等。
4.模型评估
- 文本相似度:对生成的Cypher语句与参考答案进行文本相似度计算,评估模型的翻译准确性。
- 语法正确性:检查生成的Cypher语句的语法正确性,确保其能够在TuGraph-DB上正确执行。
四.代码实现
1.配置类(Config)
class Config:
def __init__(self):
self.model_name = "t5-base" # 使用T5基础模型
self.cache_dir = "./model_cache" # 模型缓存目录
self.output_dir = "./results" # 输出目录
self.num_train_epochs = 3 # 训练轮数
self.batch_size = 4 # 批次大小
self.learning_rate = 5e-5 # 学习率
self.max_length = 512 # 最大序列长度
self.warmup_steps = 100 # 预热步数
self.save_steps = 1000 # 保存检查点的步数间隔
self.eval_steps = 1000 # 评估的步数间隔
2.数据集类 (CypherDataset)
class CypherDataset(Dataset):
# 数据处理的核心类,继承自PyTorch的Dataset
def __init__(self, data, schemas, tokenizer, max_length):
# 初始化数据集,接收原始数据、schema定义、分词器和最大长度
def __getitem__(self, idx):
# 构建输入格式:Schema + Question
# 返回经过编码的输入数据、注意力掩码和标签
3.训练函数 (train)
关键代码段
def train():
# 加载schema文件
schemas = {}
# ...
# 初始化模型和tokenizer
tokenizer = T5Tokenizer.from_pretrained(...)
model = T5ForConditionalGeneration.from_pretrained(...)
# 创建数据集和训练器
train_dataset = CypherDataset(...)
trainer = Trainer(...)
# 训练和保存
trainer.train()
trainer.save_model("./cypher_model")
4.预测函数(generate_predictions)
关键代码段
def generate_predictions():
# 加载模型
model = T5ForConditionalGeneration.from_pretrained(...)
tokenizer = T5Tokenizer.from_pretrained(...)
# 生成预测
predictions = []
for item in test_data:
input_text = f"Schema: {schema}\nQuestion: {item['question']}"
outputs = model.generate(...)
predicted_text = tokenizer.decode(...)
predictions.append(...)
5.主要依赖:
- torch: PyTorch深度学习框架
- transformers: Hugging Face的转换器库
- numpy: 数值计算库
- json: JSON数据处理
五.不足与分析
1.错误的处理机制
- 缺乏日志管理,无法更好地对代码各种报错信息进行调试处理,在训练cypher语料时,无法及时获取相关信息反馈。
- 进行错误处理机制的完善,引入日志系统。
import logging
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
try:
with open(file_path, 'r', encoding='utf-8') as f:
schema = json.load(f)
except FileNotFoundError:
logger.error(f"文件不存在: {file_path}")
continue
except json.JSONDecodeError as e:
logger.error(f"JSON解析错误 {file_path}: {str(e)}")
continue
except Exception as e:
logger.error(f"加载schema时发生未知错误: {str(e)}")
continue
2.数据预处理和处理不平衡数据问题的缺乏
- 对数据的预处理不够充分,可能导致数据质量和数据格式达不到预期。训练语料信息的缺乏,在训练任务中,不同类别的数据样本数量差异较大。
- 进行数据清洗和数据格式化进行数据预处理,通过重采样,重新定义损失函数解决不平衡数据的处理。
class CypherDataset(Dataset):
def __init__(self, data, schemas, tokenizer, max_length):
self.data = self._preprocess_data(data) # 添加预处理
def _preprocess_data(self, data):
processed_data = []
for item in data:
# 数据清洗
if self._validate_item(item):
# 数据增强
augmented_items = self._augment_data(item)
processed_data.extend(augmented_items)
return processed_data
六.团队分工
- 王强:模型训练,代码编写,博客写作。
- 马鑫:模型调研,模型训练,代码优化。
- 陈家凯:程序说明书,语料准备。
- 吴佳辉:模型调研,材料整合ppt制作。
七.总结与收获
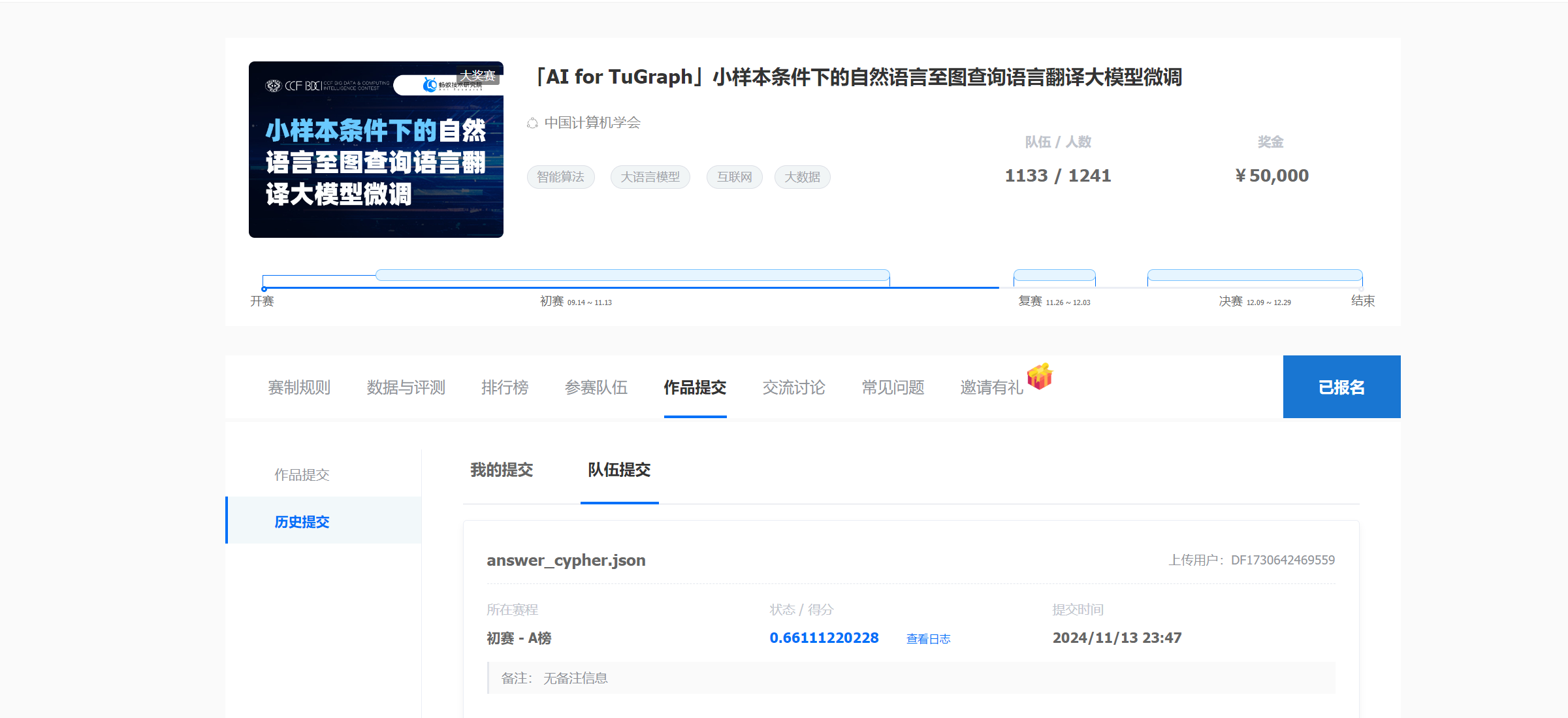
1.竞赛最终得分
2.感受与收获
- 数据预处理:小组学习了如何加载和处理JSON格式的训练和测试数据。并通过编写自定义的Dataset类,掌握了如何将数据转换为模型可以接受的格式。
- 模型微调:小组了解如何使用Hugging Face的Transformers库进行模型微调。并且对T5模型进行微调后用于特定任务。
- 图数据库与Cypher语句:在通过处理不同的schema文件中,理解了图数据库的结构和Cypher查询语言。
- 通过这个项目,我们小组不仅提升了自然语言处理和深度学习的技能,还对图数据库和Cypher查询语言有了更深入的理解。这些收获将对我们未来的学习框架的使用和大模型微调带来积极的影响。总的来说,这次项目实践让我们在理论和实践上都有了显著的提升。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号