7.Spark SQL
1.请分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
1.1 SparkSQL出现的原因
SparkSQL出现是因为关系数据库已经不能满足各种在大数据时代新增的用户需求。首先,用户需要在不同的结构化和非结构化数据中执行各种操作。
其次,用户需要执行像机器学习和图像处理等等高级分析,在实际应用中,也经常需要融合关系查询和分析复杂算法。而SparkSQL正好可以弥补这个缺陷。
1.2 SparkSQL的起源与发展。
Spark SQL 是Spark 用于结构化数据(structured data)处理的Spark模块。
SparkSQL的前身是Shark,给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是当时唯一运行在Hadoop上的SQL-on-hadoop工具。
2. 简述RDD 和DataFrame的联系与区别?
RDD代表弹性分布式数据集。它是记录的只读分区集合。 RDD是Spark的基本数据结构。它允许程序员以容错方式在大型集群上执行内存计算。
与RDD不同,数据组以列的形式组织起来,类似于关系数据库中的表。它是一个不可变的分布式数据集合。 Spark中的DataFrame允许开发人员将数据结构(类型)加到分布式数据集合上,从而实现更高级别的抽象。
3.DataFrame的创建
spark.read.text(url)

spark.read.json(url)

spark.read.format("text").load("people.txt")

spark.read.format("json").load("people.json")

描述从不同文件类型生成DataFrame的区别。
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。
4. PySpark-DataFrame各种常用操作
基于df的操作:
打印数据 df.show()默认打印前20条数据
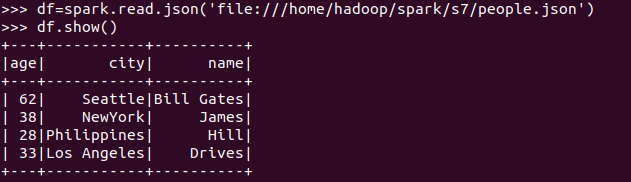
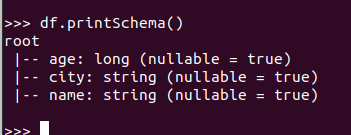
打印概要 df.printSchema()
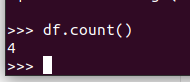
查询总行数 df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

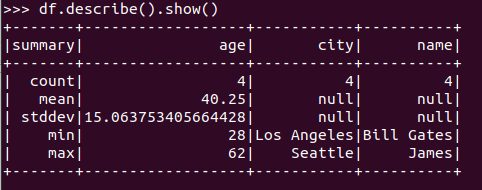
查询概况 df.describe().show()
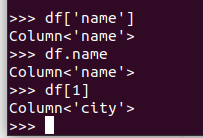
取列 df[‘name’], df.name, df[1]
基于spark.sql的操作:
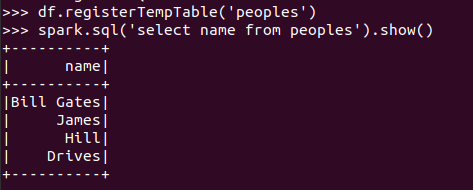
创建临时表虚拟表 df.registerTempTable('people')
spark.sql执行SQL语句 spark.sql('select name from people').show()
5. Pyspark中DataFrame与pandas中DataFrame
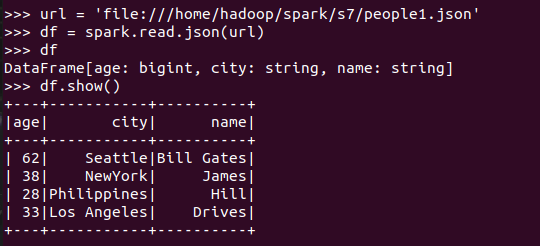
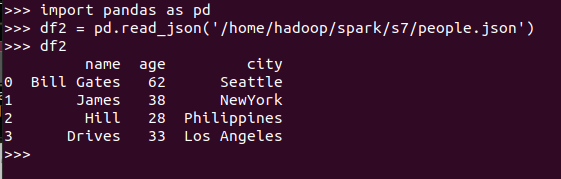
分别从文件创建DataFrame
pandas中DataFrame转换为Pyspark中DataFrame
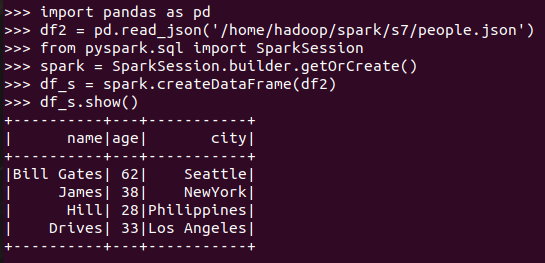
Pyspark中DataFrame转换为pandas中DataFrame
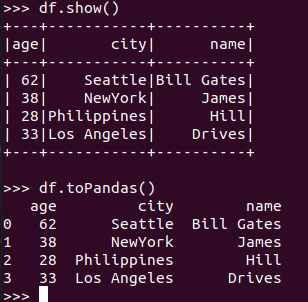
从创建与操作上,比较两者的异同
6.从RDD转换得到DataFrame
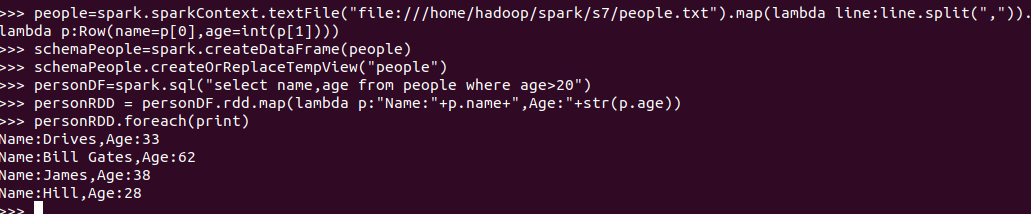
6.1 利用反射机制推断RDD模式
创建RDD sc.textFile(url).map(),读文件,分割数据项
每个RDD元素转换成 Row
由Row-RDD转换到DataFrame
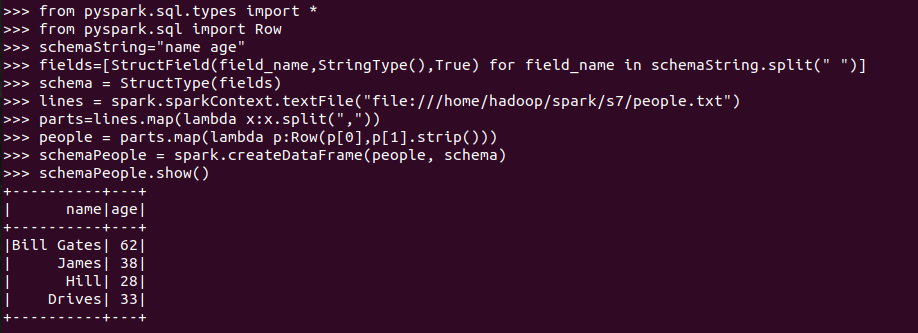
6.2 使用编程方式定义RDD模式
#下面生成“表头”
#下面生成“表中的记录”
#下面把“表头”和“表中的记录”拼装在一起
7. DataFrame的保存
df.write.text(dir)
df.write.json(dri)
df.write.format("text").save(dir)
df.write.format("json").save(dir)
df.write.format("json").save(dir)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号