3.Spark设计与运行原理,基本操作
1.Spark已打造出结构一体化、功能多样化的大数据生态系统,请用图文阐述Spark生态系统的组成及各组件的功能。
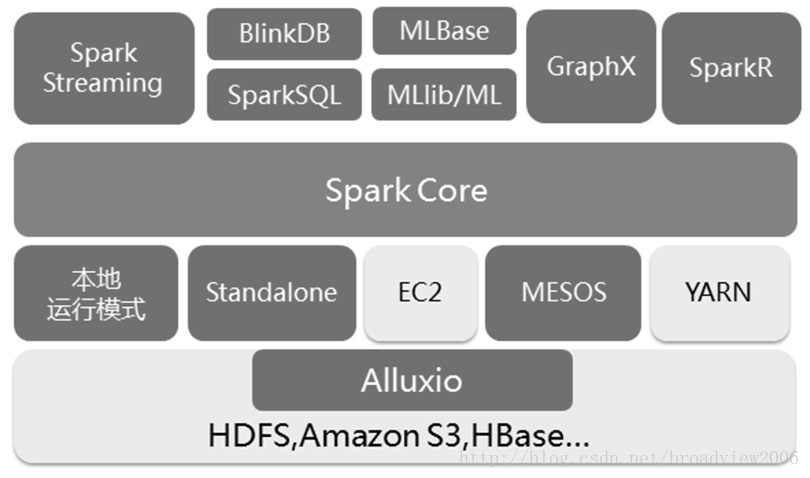
Spark Core :是整个BDAS 生态系统的核心组件,是一个分布式大数据处理框架。Spark Core提供了多种资源调度管理,通过内存计算、有向无环图(DAG)等机制保证分布式计算的快速,并引入了RDD 的抽象保证数据的高容错性。
Spark Streaming: 是一个对实时数据流进行高吞吐、高容错的流式处理系统,可以对多种数据源(如Kafka、Flume、Twitter 和ZeroMQ 等)进行类似Map、Reduce 和Join 等复杂操作,并将结果保存到外部文件系统、数据库或应用到实时仪表盘。相比其他的处理引擎要么只专注于流处理,要么只负责批处理(仅提供需要外部实现的流处理API 接口),而Spark Streaming 最大的优势是提供的处理引擎和RDD 编程模型可以同时进行批处理与流处理。对于传统流处理中一次处理一条记录的方式而言,Spark Streaming 使用的是将流数据离散化处理(Discretized Streams),通过该处理方式能够进行秒级以下的数据批处理。在SparkStreaming 处理过程中,Receiver 并行接收数据,并将数据缓存至Spark 工作节点的内存中。经过延迟优化后,Spark 引擎对短任务(几十毫秒)能够进行批处理,并且可将结果输出至其他系统中。与传统连续算子模型不同,其模型是静态分配给一个节点进行计算,而Spark 可基于数据的来源以及可用资源情况动态分配给工作节点。
Spark SQL :前身是Shark,它发布时Hive 可以说是SQL on Hadoop 的唯一选择(Hive 负责将SQL 编译成可扩展的MapReduce 作业),鉴于Hive 的性能以及与Spark 的兼容,Shark 由此而生。Shark 即Hive on Spark,本质上是通过Hive 的HQL 进行解析,把HQL 翻译成Spark 上对应的RDD 操作,然后通过Hive 的Metadata 获取数据库里的表信息,实际为HDFS 上的数据和文件,最后由Shark 获取并放到Spark 上运算。Shark 的最大特性就是速度快,能与Hive 的完全兼容,并且可以在Shell 模式下使用rdd2sql 这样的API,把HQL 得到的结果集继续在Scala环境下运算,支持用户编写简单的机器学习或简单分析处理函数,对HQL 结果进一步分析计算。
BlinkDB :是一个用于在海量数据上运行交互式SQL 查询的大规模并行查询引擎,它允许用户通过权衡数据精度来提升查询响应时间,其数据的精度被控制在允许的误差范围内。
MLBase :是Spark 生态系统中专注于机器学习的组件,它的目标是让机器学习的门槛更低,让一些可能并不了解机器学习的用户能够方便地使用MLBase。MLBase 分为4 个部分:MLRuntime、MLlib、MLI 和ML Optimizer。
GraphX :最初是伯克利AMP 实验室的一个分布式图计算框架项目,后来整合到Spark 中成为一个核心组件。它是Spark 中用于图和图并行计算的API,可以认为是GraphLab 和Pregel 在Spark 上的重写及优化。跟其他分布式图计算框架相比,GraphX 最大的优势是:在Spark 基础上提供了一栈式数据解决方案,可以高效地完成图计算的完整的流水作业。
SparkR:是遵循GNU 协议的一款开源、免费的软件,广泛应用于统计计算和统计制图,但是它只能单机运行。为了能够使用R 语言分析大规模分布式的数据,伯克利分校AMP 实验室开发了SparkR,并在Spark 1.4 版本中加入了该组件。通过SparkR 可以分析大规模的数据集,并通过R Shell 交互式地在SparkR 上运行作业。
Alluxio :是一个分布式内存文件系统,它是一个高容错的分布式文件系统,允许文件以内存的速度在集群框架中进行可靠的共享,就像Spark 和 MapReduce 那样。Alluxio 是架构在最底层的分布式文件存储和上层的各种计算框架之间的一种中间件。其主要职责是将那些不需要落地到DFS 里的文件,落地到分布式内存文件系统中,来达到共享内存,从而提高效率。同时可以减少内存冗余、GC 时间等
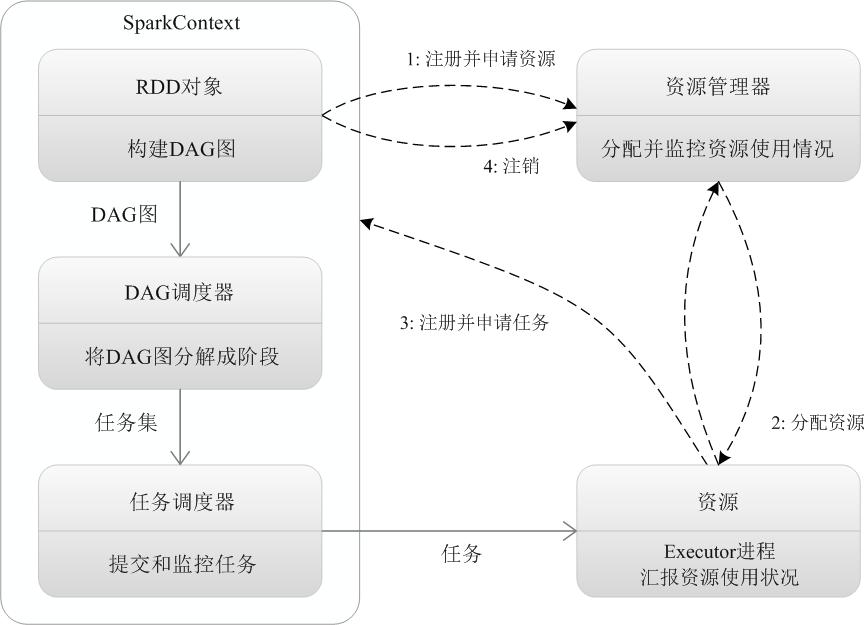
2.请详细阐述Spark的几个主要概念及相互关系:
Master, Worker; RDD,DAG; Application, job,stage,task; driver,executor,Claster Manager;DAGScheduler, TaskScheduler.
(1)Master
Spark 特有资源调度系统的 Leader,掌管着整个集群的资源信息(Standalone模式),类似于 Yarn 集群中的ResourceManager。主要功能:
监听 Worker,看集群中的 Worker 是否正常工作;
管理 Worker、Application(接收 Worker 的注册并管理所有的 Worker;接收 Client 提交的 Application,调度等待的Application 并向Worker提交)。
(2)Worker
Spark 特有资源调度系统的 Slaver,一个集群中有多个 Slaver(Standalone),每个 Slaver 掌管着所在节点的资源信息,类似于 Yarn 框架中的 NodeManager。主要功能:
通过 RegisterWorker 注册到 Master;
定时发送心跳给 Master;
根据 Master 发送的 Application 配置进程环境,并启动 ExecutorBackend(执行 Task 所需的临时进程)。
(3)RDD
RDD 是 Spark 对数据的核心抽象,其实就是分布式的元素集合。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有RDD 以及调用 RDD 操作进行求值。而在这一切背后, Spark 会自动将 RDD 中的数据分发到集群上,并将操作并行化执行。
Spark 中 RDD 是一种不可变的分布式对象集合,所以,对 RDD 的每一个操作都会生成一个新的 RDD。
(4)DAG
RDD依赖组成的有向无环图,来表明一个Application中RDD的依赖关系。
(5)Application
基于 Spark 构建的用户程序,一般包括了集群上的一个 driver 程序与多个 executor。
(6)job
由多个 task 组成的一个并行计算, 这些 task 产生自一个 Spark action (比如, save, collect) 操作。
(7)stage
每个 job 被分解为多个 stage, 每个 stage 其实就是一些 task 的集合, 这些 stage 之间相互依赖 (与 MapReduce 中的 map 与 reduce stage 类似),执行过程中,每碰到一个shuffle就是一个stage。
(8)task
发送到一个 executor 的一系列工作。
(9)driver(Driver Program)
运行 application 的 main() 函数和创建 SparkContext 的进程。
(10)executor
SparkContext 对象一旦成功连接到集群管理器, 就可以获取到集群中每个节点上的执行器(Executor)。
(11)Cluster Manager
获取集群资源的一个外部服务, 比如 standalone 管理器, Mesos 和 YARN。
(12)DAGScheduler
DAGScheduler是一个高级的scheduler 层,他实现了基于stage的调度,他为每一个job都计算stage,跟踪哪一个rdd和stage的输出被物化(固化),以及寻找到执行job的最小的调度,然后他会将stage作为tasksets提交给底层的TaskScheduler,由TaskScheduler执行。
(13)TaskScheduler
每一个taskScheduler只为一个单独的SparkContext进行调度安排tasks,DAGScheduler会为每一个stage向TaskScheduler提交Tasksets(也就是说TaskSets是在DAGScheduler完成组装),TaskScheduler会负责向cluster发送tasks,并且调用backend来运行task。并且在tasks失败的时候,重试,然后会将运行task,重试task的事件返回给DAGScheduler。
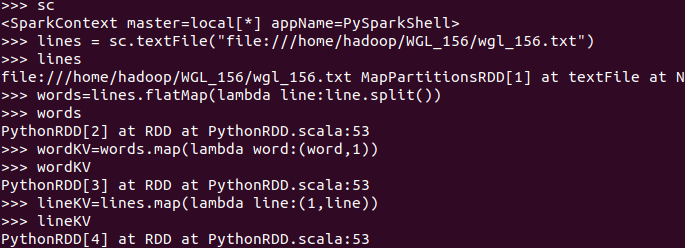
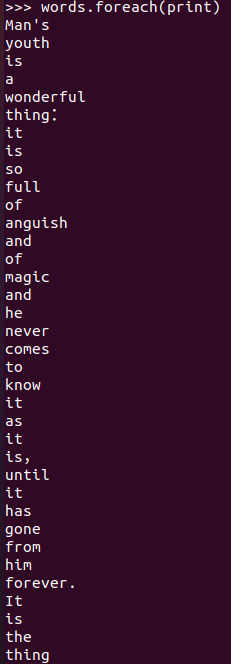
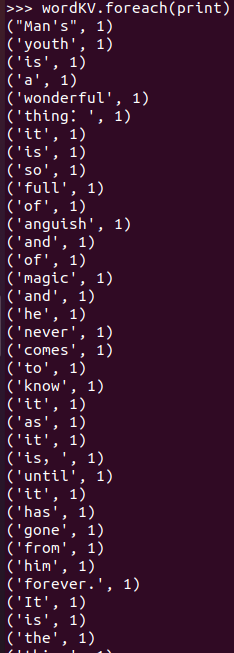
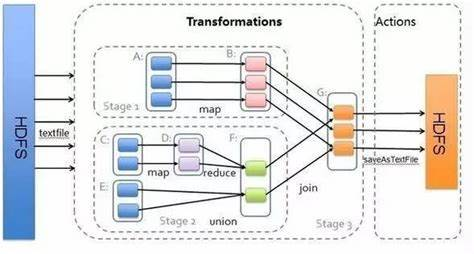
3.在PySparkShell尝试以下代码,观察执行结果,理解sc,RDD,DAG。请画出相应的RDD转换关系图。



 浙公网安备 33010602011771号
浙公网安备 33010602011771号