
协程(gevent模块、greenlet模块、urllib模块)、IO模型(阻塞IO、非阻塞IO模型、IO多路复用模型、selector模块) 第三十六天 2018.11.26
协程:
进程、线程、协程比较:
进程 启动多个进程 进程之间是由操作系统负责调用
线程 启动多个线程 真正被CPU执行的最小单位实际是线程
开启一个线程 创建一个线程 寄存器 堆栈
关闭一个线程
协程(爬虫 socket)
本质上是一个线程(可以理解为虚拟线程、帮助来实现任务遇到IO时在线程间的切换)
能够在多个任务之间切换来节省一些IO时间
协程中任务之间的切换也消耗时间,但是开销要远远小于进程线程之间的切换
进程和线程的任务切换右操作系统完成
协程任务之间的切换由程序(代码)完成,只有遇到协程模块能识别的IO操作的时候,程序才会进行任务切换,实现并发的效果
协程遇到IO就切换---->无认识的IO不切换
如果没遇到可识别的IO,程序就是顺序执行,就没有并发效果
通过生成器实现协程并行运算:
实现并发的手段,在多个任务间来回切换
import time
def consumer():
while True: # 开启无限循环
x = yield
time.sleep(1)
print('处理了数据 :',x)
def producer():
c = consumer() # 将c赋值为consumer生成器函数
next(c) # 生成器的next方法和send方法相互配合
for i in range(10): # next()触发生成器函数
time.sleep(1)
print('生产了数据 :',i)
c.send(i) # 触发生成器,把i赋值给光标停留前的yield
producer()
day9的生成器实现协程并行运算(生产者消费者模型)
import time
def consumer(name):
print('我是[%s],我准备开始吃包子了' %name)
while True:
baozi=yield #第二次之后遇到yield停留时间程序立刻跳到c1.send
#获得第i个包子
time.sleep(1) #吃包子时间间隔
print('%s 很开心的把[%s]吃掉了' %(name,baozi))
def producer():
c1=consumer('wupeiqi') #顾客名字及顾客个数
c2=consumer('yuanhao_SB')
c1.__next__() #可以换成c1.send(0)
c2.__next__() #可以换成c2.send(0)
for i in range(1,10): #顾客消费数目
time.sleep(1) #制作时间间隔
c1.send('猪肉馅包子 %s' %i) #把括号里的赋值给yield
c2.send('牛肉馅包子 %s' %i)
producer() #风湿理论---->函数即变量
#有消费(需求)才有生产(制作)
#两个函数一起执行----->并发 A->B->A->B->A->B
#每个函数通过一个循环控制,一个循环终止时另一个循环终止
协程模块---->greenlet模块
单纯的切换---->遇到IO原地阻塞---->先将函数注册给greenlet,再通过使用switch进行来回切换
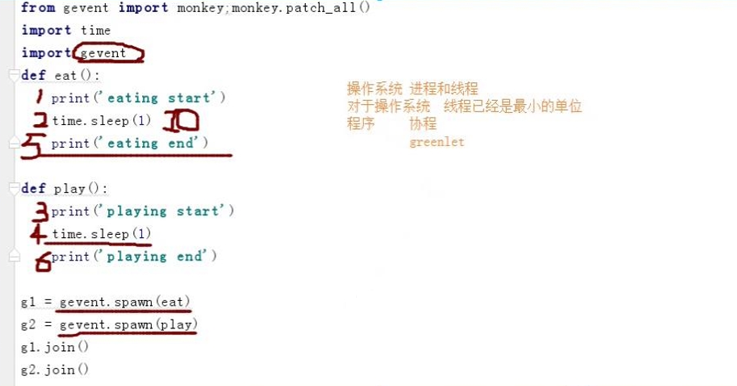
from greenlet import greenlet
def eat():
print('eating start')
g2.switch() # 切换到g2
print('eating end')
g2.switch()
def play():
print('playing start')
g1.switch() # 切换回g1
print('playing end')
g1 = greenlet(eat) # 函数注册给greenlet
g2 = greenlet(play)
g1.switch() # 切换
协程模块---->gevent模块
同步 和 异步
gevent.spawn(func,1,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,后面可以传多个参数
gevent模块无法识别其他IO,需要通过monkey模块调用monkey对象的patch_all()方法将所有IO模拟成gevent模块可以识别的IO
gevent.sleep()模拟的是gevent可以识别的IO阻塞
time.sleep()和其他阻塞无法被gevent识别,因此需要加monkey打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()
必须放到被打补丁者的前面,如time、socket模块之前
from gevent import monkey;monkey.patch_all() 会把patch_all之后所有模块的阻塞都打成一个包,打完包后,gevent模块就可以感知到其他模块的IO操作了
用threading.current_thread().getName()来查看每个协程对象,查看的结果为DummyThread-n,即假线程
from gevent import monkey;monkey.patch_all() # 会把patch_all之后所有模块的阻塞都打成一个包
import time # 打完包后,gevent模块就可以感知到time.sleep()
import gevent # 此模块感知不到time.sleep()
import threading
def eat():
print(threading.current_thread().getName())
print(threading.current_thread())
print('eating start')
time.sleep(1) # 执行到此,遇到IO跳到play函数
print('eating end')
def play():
print(threading.current_thread().getName()) # 查看线程名---->线程看来一个假的线程就是协程
print(threading.current_thread()) # id号为虚拟线程的id
print('playing start')
time.sleep(1) # 从eat函数跳来执行到此,遇到IO跳回eat函数
print('playing end')
g1 = gevent.spawn(eat) # 创建一个eat函数的协程对象
g2 = gevent.spawn(play) # 创建一个play函数的协程对象
g1.join() # 等待g1结束
g2.join() # 等待g2结束
'''
DummyThread-1
<_DummyThread(DummyThread-1, started daemon 64339232)>
eating start
DummyThread-2
<_DummyThread(DummyThread-2, started daemon 64339808)>
playing start
eating end
playing end
'''
gevent模块---->协程间的同步异步
from gevent import monkey;monkey.patch_all() # 会把patch_all之后所有模块的阻塞都打成一个包
import time # 打完包后,gevent模块就可以感知到time.sleep()
import gevent # 此模块感知不到time.sleep()
def task(n):
time.sleep(1)
print(n)
def sync(): # 同步
for i in range(10):
task(i)
def kk(): # 异步
g_lst = []
for i in range(10):
g = gevent.spawn(task,i) # 异步协程---->调用函数、传参
g_lst.append(g)
gevent.joinall(g_lst) # for g in g_lst:g.join() # .join等待结束
# gevent.joinall(g_lst) == for g in g_lst:g.join()
sync() # 同步控制
kk() # 异步控制
# 都为顺序输出0-9
协程---->并发、切换效率快
遇到IO时间切换到另一个线程规避IO时间
并发 = 进程+线程+协程
5 20 500
协程 : 能够在一个线程中实现并发效果的概念
能够规避一些任务中的IO操作
在任务的执行过程中,检测到IO就切换到其他任务
多线程 被弱化了
协程 在一个线程上 提高CPU 的利用率
协程相比于多线程的优势 切换的效率更快
协程---->urllib模块---->爬虫
爬虫的例子
正则基础
请求过程中的IO等待
获取数据的过程
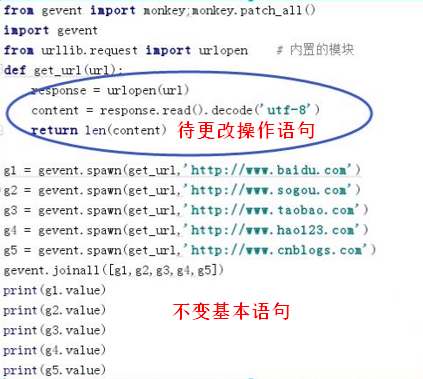
from gevent import monkey;monkey.patch_all()
import gevent # 引入协程
# import requests # 需要安装的
from urllib.request import urlopen # 内置的模块
def get_url(url):
response = urlopen(url) # 获取所爬取网页的数据
# response2 = requests.get(url)
content = response.read().decode('utf-8') # 完全按照格式来的html---->有格式的
# response2.content.decode('utf-8') # 拿到一个简化版---->写在一行(无格式)
return len(content) # 返回content的长度
g1 = gevent.spawn(get_url,'http://www.baidu.com') # spawn大量生产
g2 = gevent.spawn(get_url,'http://www.sogou.com') # 方法 参数
g3 = gevent.spawn(get_url,'http://www.taobao.com') # 创建一个协程对象
g4 = gevent.spawn(get_url,'http://www.hao123.com')
g5 = gevent.spawn(get_url,'http://www.cnblogs.com')
gevent.joinall([g1,g2,g3,g4,g5]) # 等待所有的都结束
print(g1.value)
print(g2.value) # .value拿到返回值
print(g3.value) # .join等待结束
print(g4.value)
print(g5.value)
ret = get_url('http://www.baidu.com')
print(ret)
协程---->socketserver

server端:
# 在线程之间的切换是操作系统级别
# 在协程之间的操作是代码级别
from gevent import monkey;monkey.patch_all()
import socket
import gevent
def talk(conn): # 把可以进行变化操作的设置为一个函数
conn.send(b'hello')
print(conn.recv(1024).decode('utf-8'))
conn.close()
sk = socket.socket()
sk.bind(('127.0.0.1',8080))
sk.listen()
while True:
conn,addr = sk.accept()
gevent.spawn(talk,conn) # 创建一个talk函数协程对象,传入的参数为连接
sk.close()
client端:
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',8080))
print(sk.recv(1024))
msg = input('>>>').encode('utf-8')
sk.send(msg)
sk.close()
IO模型:
笔记:
同步 提交一个任务之后要等待这个任务执行完毕
异步 只管提交任务,不等待这个任务执行完毕就可以做其他事情
阻塞 recv recvfrom accept
非阻塞
阻塞 线程 运行状态 --> 阻塞状态 --> 就绪
非阻塞
IO多路复用
select机制 Windows linux 都是操作系统轮询每一个被监听的项,看是否有读操作
poll机制 linux 它可以监听的对象比select机制可以监听的多
随着监听项的增多,导致效率降低
epoll机制 linux 给每个对象绑定了一个回调函数---->不通过操作系统的轮询,直接通过回调函数效率更高
selectors模块,能够自动选择适合的IO多路复用
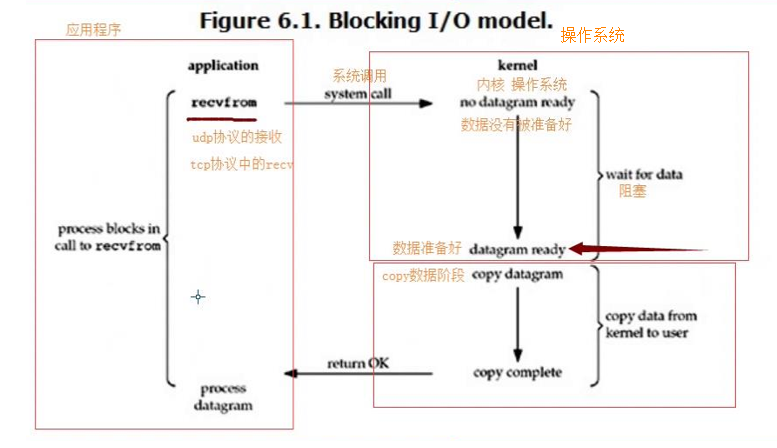
IO模型介绍:
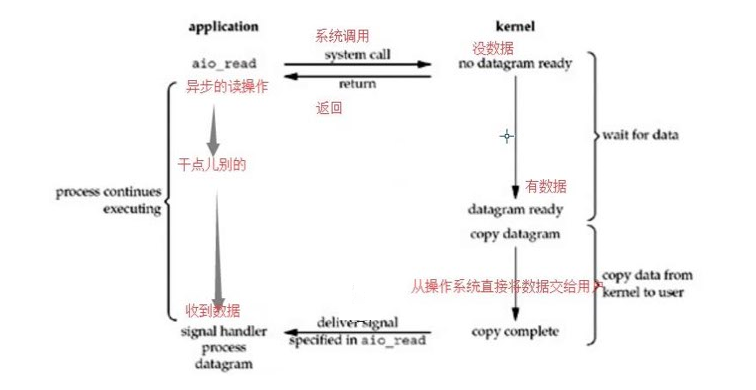
Stevens在文章中一共比较了五种IO Model:
* blocking IO 阻塞IO
* nonblocking IO 非阻塞IO
* IO multiplexing IO多路复用
* signal driven IO 信号驱动IO
* asynchronous IO 异步IO
由signal driven IO(信号驱动IO)在实际中并不常用,所以主要介绍其余四种IO Model。
一个IO的两个阶段:
#1)等待数据准备 (Waiting for the data to be ready) #2)将数据从内核拷贝到进程中(Copying the data from the kernel to the process)
IO模型---->阻塞IO
IO模型---->非阻塞IO
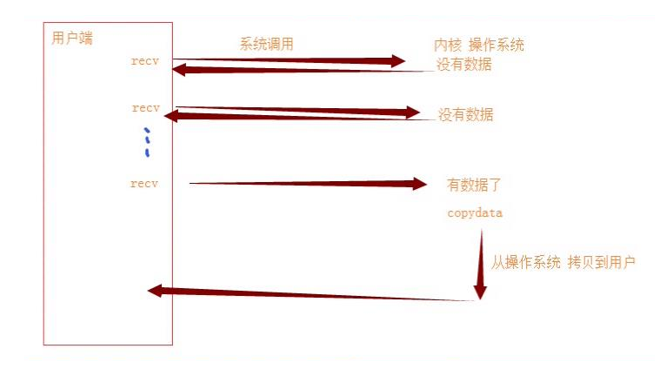
server端:

# while True---->异常占内存---->及其浪费cpu
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',9000))
sk.setblocking(False) # 设置为非阻塞
sk.listen()
# 通过两个列表---->连接列表和删除断开连接的列表
# 连接列表把每次连接存储起来
# 删除列表用来记录断开的连接,从而按删除列表里的元素删除连接列表里的无用元素
conn_l = [] # 连接列表
del_conn = [] # 删除已经断开的连接---->每次删除完连接列表里的元素,清空删除列表
while True:
try:
conn,addr = sk.accept() #不阻塞,但是没人连我会报错
print('建立连接了:',addr)
conn_l.append(conn)
except BlockingIOError:
for con in conn_l:
try:
msg = con.recv(1024) # 非阻塞,如果没有数据就报错
if msg == b'': # tcp协议不可以发送空消息
del_conn.append(con)
continue
print(msg)
con.send(b'byebye')
except BlockingIOError:pass
for con in del_conn: # for循环里不能删除本循环的项,否则会造成本循环索引错误
con.close()
conn_l.remove(con)
del_conn.clear()
# while True : 10000 500 501
client端:
import time
import socket
import threading
def func():
sk = socket.socket()
sk.connect(('127.0.0.1',9000))
sk.send(b'hello')
time.sleep(1)
print(sk.recv(1024))
sk.close()
for i in range(2):
threading.Thread(target=func).start() # 利用线程异步执行多个任务
IO模型---->IO多路复用
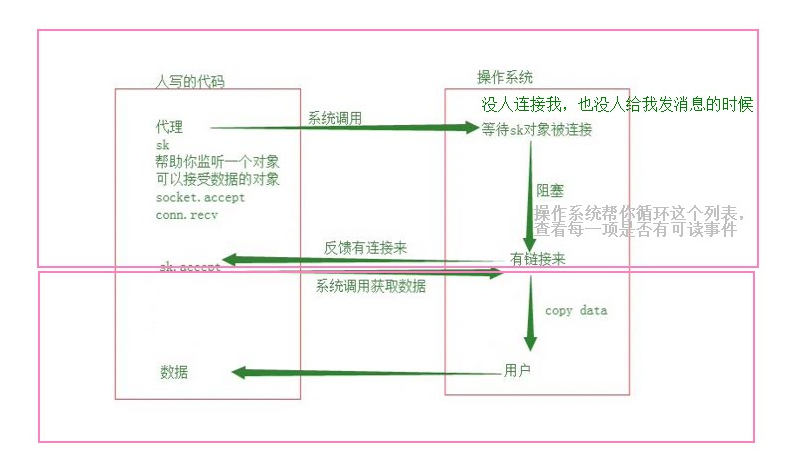
server端:
# 未使用牺牲CPU复用率来达到
# 通过操作系统的代理来实现监听从而达到
import select
import socket
sk = socket.socket()
sk.bind(('127.0.0.1',8000))
sk.setblocking(False) # 设置socket的接口为非阻塞
sk.listen()
read_lst = [sk] # 监听sk对象、conn连接
while True: # [sk,conn]
r_lst,w_lst,x_lst = select.select(read_lst,[],[])
# 读事件 写事件 条件修改
# r_lst里面只有要接收的连接/sk对象
for i in r_lst:
if i is sk: # sk对象
conn,addr = i.accept() # sk.accept()
read_lst.append(conn)
else: # conn连接
ret = i.recv(1024)
if ret == b'':
i.close()
read_lst.remove(i) # 在列表中删除已经断开的连接
continue
print(ret)
i.send(b'goodbye!')
# client端断开连接后会一直给server端发送空消息,直到server端断开连接
client端:
import time
import socket
import threading
def func():
sk = socket.socket()
sk.connect(('127.0.0.1',8000))
sk.send(b'hello')
time.sleep(3)
print(sk.recv(1024))
sk.close()
for i in range(20):
threading.Thread(target=func).start()
IO模型---->异步IO
Python暂时实现不了
selectors模块:
自动帮你选择合适的IO多路复用模型(select,poll,epoll)
IO多路复用
select机制 Windows linux 都是操作系统轮询每一个被监听的项,看是否有读操作
poll机制 linux 它可以监听的对象比select机制可以监听的多
随着监听项的增多,导致效率降低
epoll机制 linux 给每个对象绑定了一个回调函数---->不通过操作系统的轮询,直接通过回调函数效率更高
selectors模块,能够自动选择适合的IO多路复用
import selectors
from socket import *
def accept(sk,mask):
conn,addr=sk.accept()
sel.register(conn,selectors.EVENT_READ,read) # conn连接对象、可读事件、执行read
def read(conn,mask):
try:
data=conn.recv(1024)
if not data: # 如果没有接收到client端的消息
print('closing',conn)
sel.unregister(conn) # 注销代理所监听的conn对象
conn.close() # 关闭连接
return
conn.send(data.upper()+b'_SB')
except Exception:
print('closing', conn)
sel.unregister(conn) # 没有接收消息(进入阻塞)也关闭
conn.close()
sk=socket()
sk.setsockopt(SOL_SOCKET,SO_REUSEADDR,1) # 就是他在bind前面加,防止端口号被上次使用后占用
sk.bind(('127.0.0.1',8088))
sk.listen(5) # tcp队列的最大连接数,大部分设置为5
sk.setblocking(False) # 设置socket的接口为非阻塞
sel=selectors.DefaultSelector() # 选择一个适合我的IO多路复用的机制
sel.register(sk,selectors.EVENT_READ,accept) # 监听的是一个读事件 sk对象、可读事件、accept的回调函数
# EVENT_READ : 表示可读的; 它的值其实是1;
# EVENT_WRITE: 表示可写的; 它的值其实是2;
# 相当于网select的读列表里append了一个sk对象,并且绑定了一个回调函数accept
# 说白了就是 如果有人请求连接sk,就调用accrpt方法
while True:
events=sel.select() # 检测所有的sk,conn,是否有完成wait data阶段
for sel_obj,mask in events: # [conn] sk 连接
callback=sel_obj.data # callback=read
callback(sel_obj.fileobj,mask) # read(conn,1)
'''
register(fileobj, events, data=None) 作用:注册一个文件对象。
参数: fileobj——即可以是fd 也可以是一个拥有fileno()方法的对象;
events——上面的event Mask 常量; data
返回值: 一个SelectorKey类的实例;
unregister(fileobj) 作用: 注销一个已经注册过的文件对象;
返回值:一个SelectorKey类的实例;
select(timeout=None) 作用: 用于选择满足我们监听的event的文件对象;
返回值: 是一个(key, events)的元组,
其中key是一个SelectorKey类的实例, 而events 就是 event
Mask(EVENT_READ或EVENT_WRITE,或者二者的组合)
'''

 浙公网安备 33010602011771号
浙公网安备 33010602011771号