数据采集第3次作业
作业1
图片2种方式爬取实验
(1)要求:要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网( http://www.weather.com.cn )。实现单线程和多线程的方式爬取。
代码:
单线程
# simple_single.py
import os
import requests
from urllib.parse import urljoin
from bs4 import BeautifulSoup
url = 'http://www.weather.com.cn' # 要爬取的网页地址
headers = {'User-Agent': 'Mozilla/5.0'} # 模拟浏览器
os.makedirs('weather_images_single', exist_ok=True)
# 获取页面并解析图片链接
resp = requests.get(url, headers=headers) # 向目标网站发送 GET 请求
soup = BeautifulSoup(resp.text, 'html.parser') # 使用 BeautifulSoup 解析返回的 HTML 文本
img_urls = [urljoin(url, img['src']) for img in soup.find_all('img', src=True)] # 提取所有 <img> 标签中带有 src 属性的元素,并将 src 值转为绝对 URL
# 去除重复的URL
img_urls = list(set(img_urls))
# 打印所有图片 URL
print(f"共找到 {len(img_urls)} 张图片:")
# 遍历图片 URL 列表,按序号逐行打印
for i, u in enumerate(img_urls, 1):
print(f"{i}. {u}")
# 逐个下载
for u in img_urls:
try:
r = requests.get(u, headers=headers) # 向图片 URL 发起请求
# 只有状态码为 200(成功)时才保存
if r.status_code == 200:
filename = u.split('/')[-1].split('?')[0] or 'image.jpg'
with open(f'weather_images_single/{filename}', 'wb') as f:
f.write(r.content) # 以二进制写模式打开文件,保存图片内容
except:
pass
print(" 单线程下载完成!")
多线程
# simple_multi.py
import os
import requests
from urllib.parse import urljoin
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
url = 'http://www.weather.com.cn' # 要爬取的网页地址
headers = {'User-Agent': 'Mozilla/5.0'} # 模拟浏览器
os.makedirs('images_mt', exist_ok=True)
# 获取图片链接
resp = requests.get(url, headers=headers) # 向目标网站发送 GET 请求
soup = BeautifulSoup(resp.text, 'html.parser') # 使用 BeautifulSoup 解析返回的 HTML 文本
img_urls = [urljoin(url, img['src']) for img in soup.find_all('img', src=True)] # 提取所有 <img> 标签中带有 src 属性的元素,并将 src 值转为绝对 URL
# 去除重复的URL
img_urls = list(set(img_urls))
# 打印
print(f"共找到 {len(img_urls)} 张图片:")
# 遍历图片 URL 列表,按序号逐行打印
for i, u in enumerate(img_urls, 1):
print(f"{i}. {u}")
# 下载函数
def download(u):
try:
r = requests.get(u, headers=headers) # 向图片 URL 发起请求
# 只有状态码为 200(成功)时才保存
if r.status_code == 200:
filename = u.split('/')[-1].split('?')[0] or 'image.jpg'
with open(f'images_mt/{filename}', 'wb') as f:
f.write(r.content) # 以二进制写模式打开文件,保存图片内容
except:
pass
# 并发下载
with ThreadPoolExecutor(5) as pool:
pool.map(download, img_urls)
print(" 多线程下载完成!")
结果:
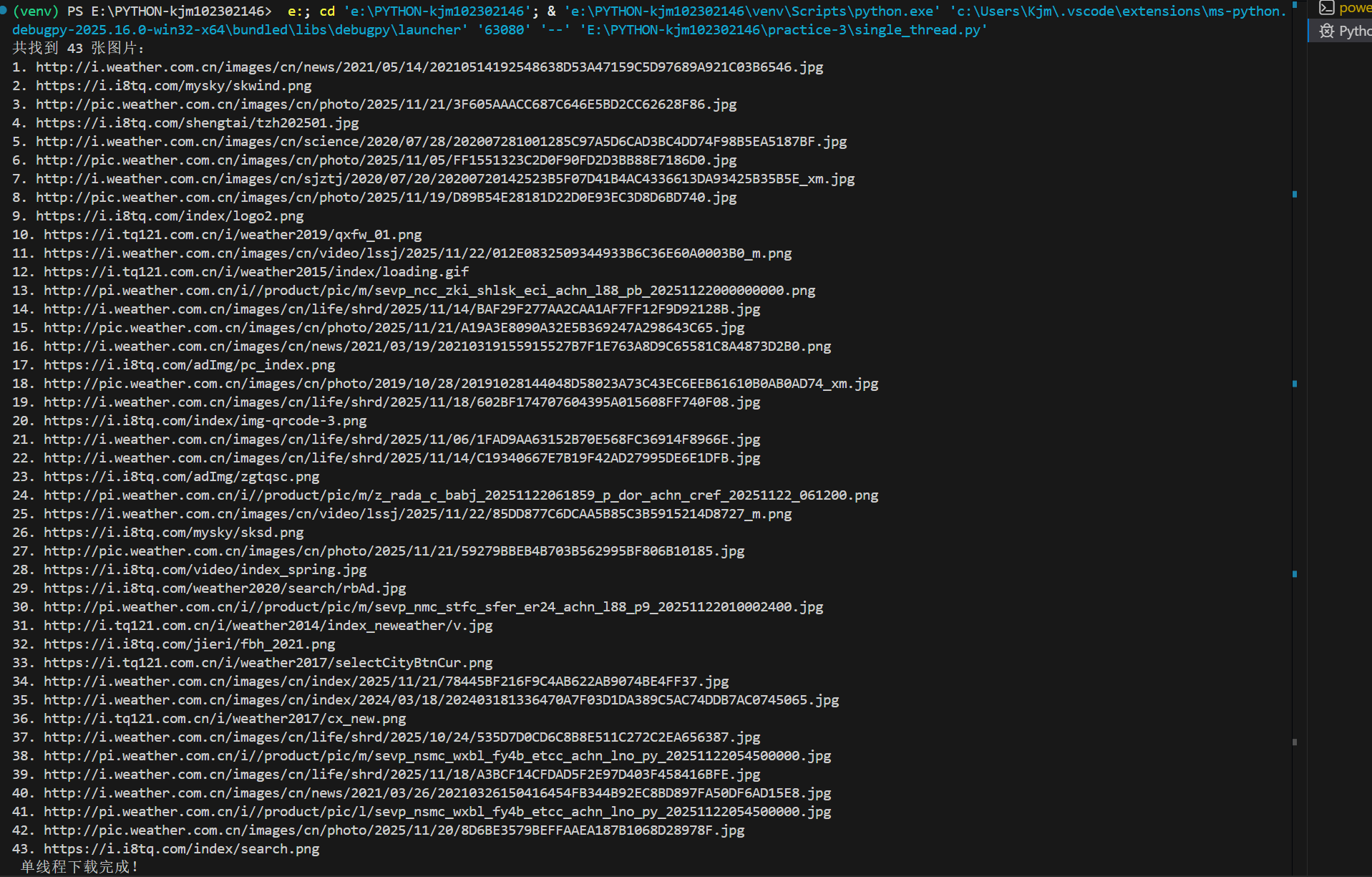
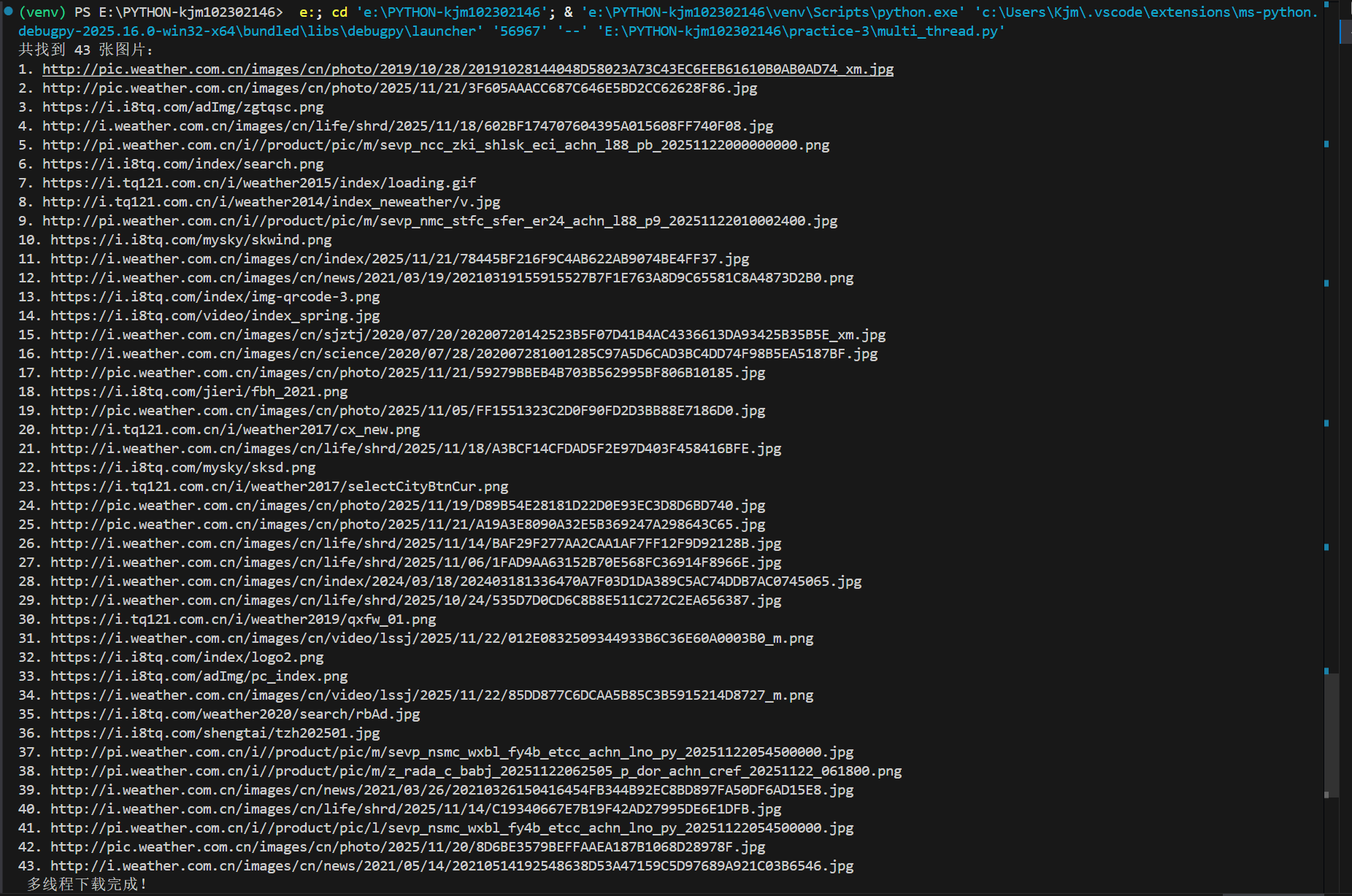
(2)心得体会:
通过实现单线程与多线程爬取中国气象网图片,我深刻体会到多线程在I/O密集型任务中的显著效率优势。单线程逻辑简单、易于调试,但速度慢;多线程虽需处理并发控制和异常管理,却能大幅提升爬取速度。同时,遵守网站robots协议、设置合理请求间隔,是负责任网络爬虫的基本素养。
作业2
Scrapy+Xpath股票爬取实验
(1)要求:熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 Scrapy + XPath + MySQL 数据库存储技术路线爬取股票相关信息。
核心代码:
class EastmoneyStockSpider(scrapy.Spider):
name = 'eastmoney_stock'
def start_requests(self):
# 构造东方财富网股票行情 API 的完整 URL
url = (
"https://28.push2.eastmoney.com/api/qt/clist/get?"
"pn=1&pz=100&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&"
"fltt=2&invt=2&fid=f3&"
"fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23&"
"fields=f12,f14,f2,f3,f4,f5,f6,f15,f16,f17,f18"
)
# 设置请求头(Headers),模拟浏览器访问,避免被反爬
headers = {
'Referer': 'https://quote.eastmoney.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36',
}
# 使用 yield 返回 Request 对象
yield scrapy.Request(url=url, headers=headers, callback=self.parse)
def parse(self, response):
try:
# 将响应体(response.text)解析为 Python 字典
data = json.loads(response.text)
# 从 JSON 中提取股票列表
stocks = data.get('data', {}).get('diff', [])
now = datetime.now().strftime("%Y-%m-%d %H:%M:%S") # 当前时间
# 遍历每一只股票
for stock in stocks:
item = StockItem()
# 从 JSON 字段中提取对应值,并赋给 Item 的各个字段
item['股票代码'] = stock.get('f12', '')
item['股票名称'] = stock.get('f14', '')
item['当前价格'] = str(stock.get('f2', ''))
item['涨跌幅百分比'] = str(stock.get('f3', ''))
item['涨跌额'] = str(stock.get('f4', ''))
item['成交量手'] = str(stock.get('f5', ''))
item['成交额元'] = str(stock.get('f6', ''))
item['振幅百分比'] = str(stock.get('f17', ''))
item['最高价'] = str(stock.get('f15', ''))
item['最低价'] = str(stock.get('f16', ''))
item['开盘价'] = str(stock.get('f18', ''))
item['昨收价'] = str(stock.get('f3', ''))
item['更新时间'] = now
yield item # 将填充好的 Item 交给 Scrapy 引擎
except Exception as e:
self.logger.error(f"解析失败: {e}")
# stock_spider/items.py
import scrapy
class StockItem(scrapy.Item):
股票代码 = scrapy.Field()
股票名称 = scrapy.Field()
当前价格 = scrapy.Field()
涨跌幅百分比 = scrapy.Field()
涨跌额 = scrapy.Field()
成交量手 = scrapy.Field()
成交额元 = scrapy.Field()
振幅百分比 = scrapy.Field()
最高价 = scrapy.Field()
最低价 = scrapy.Field()
开盘价 = scrapy.Field()
昨收价 = scrapy.Field()
更新时间 = scrapy.Field()
# stock_spider/pipelines.py
import sqlite3
class StockPipeline:
def open_spider(self, spider):
self.conn = sqlite3.connect('stocks.db')
self.cursor = self.conn.cursor()
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS stocks (
id INTEGER PRIMARY KEY AUTOINCREMENT,
股票代码 TEXT UNIQUE,
股票名称 TEXT,
当前价格 TEXT,
涨跌幅百分比 TEXT,
涨跌额 TEXT,
成交量手 TEXT,
成交额元 TEXT,
振幅百分比 TEXT,
最高价 TEXT,
最低价 TEXT,
开盘价 TEXT,
昨收价 TEXT,
更新时间 TEXT
)
''')
self.conn.commit()
def process_item(self, item, spider):
self.cursor.execute('''
INSERT OR REPLACE INTO stocks
(股票代码, 股票名称, 当前价格, 涨跌幅百分比, 涨跌额,
成交量手, 成交额元, 振幅百分比, 最高价, 最低价, 开盘价, 昨收价, 更新时间)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
item['股票代码'],
item['股票名称'],
item['当前价格'],
item['涨跌幅百分比'],
item['涨跌额'],
item['成交量手'],
item['成交额元'],
item['振幅百分比'],
item['最高价'],
item['最低价'],
item.get('开盘价', ''),
item.get('昨收价', ''),
item.get('更新时间', '')
))
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
# stock_spider/settings.py
BOT_NAME = 'stock_spider'
SPIDER_MODULES = ['stock_spider.spiders']
NEWSPIDER_MODULE = 'stock_spider.spiders'
ROBOTSTXT_OBEY = False
CONCURRENT_REQUESTS = 1
DOWNLOAD_DELAY = 2
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36'
ITEM_PIPELINES = {
'stock_spider.pipelines.StockPipeline': 300,
}
LOG_LEVEL = 'WARNING'
# 控制 CSV 字段顺序和编码
FEED_EXPORT_ENCODING = 'utf-8-sig' # 防止 Excel 乱码(带 BOM 的 UTF-8)
FEED_EXPORT_FIELDS = [
'股票代码',
'股票名称',
'当前价格',
'涨跌幅百分比',
'涨跌额',
'成交量手',
'成交额元',
'振幅百分比',
'最高价',
'最低价',
'开盘价',
'昨收价',
'更新时间'
]
结果:
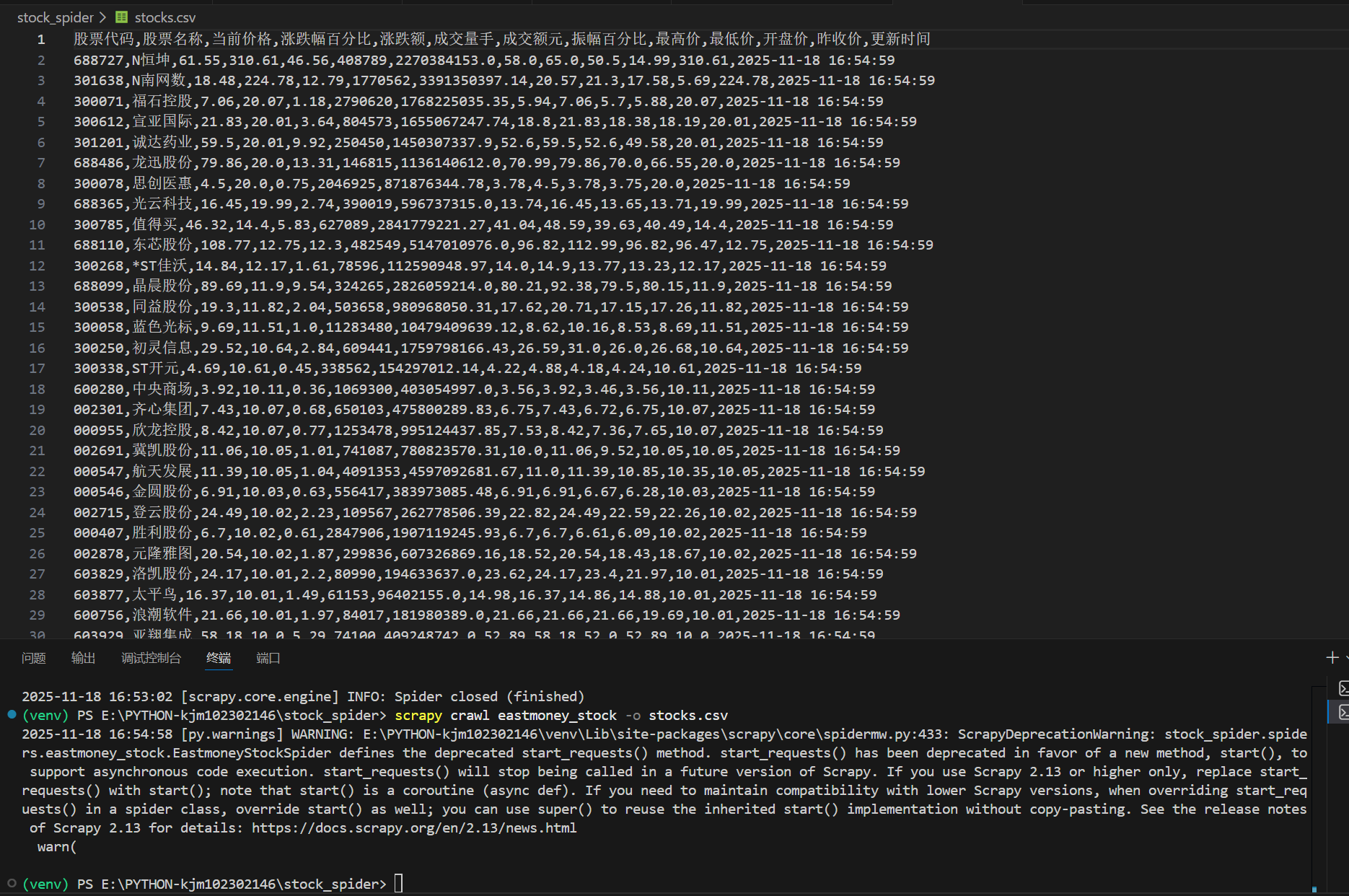
(2)心得体会:
通过本次实践,我深入掌握了Scrapy框架中Item定义与Pipeline数据处理的流程,熟练运用XPath精准提取股票信息,并成功将数据持久化至MySQL数据库。整个过程强化了我对网络爬虫结构化设计的理解,也提升了数据清洗、字段映射及异常处理能力,为后续复杂爬虫项目打下坚实基础。
作业3
Scrapy+Xpath爬取外汇信息实验
(1)要求:熟练掌握 Scrapy 中 Item、Pipeline 数据的序列化输出方法;使用 Scrapy 框架 + XPath + MySQL 数据库存储技术路线爬取外汇网站数据。
核心代码:
# boc_spider/spiders/boc.py
import scrapy
from boc_spider.items import BocItem
class BocSpider(scrapy.Spider):
name = 'boc'
allowed_domains = ['boc.cn']
start_urls = ['https://www.boc.cn/sourcedb/whpj/']
def parse(self, response):
# 选择页面中第二个 table(第一个是顶部导航)
tables = response.xpath('//table')
if len(tables) < 2:
self.logger.error("未找到数据表格")
return
data_table = tables[1] # 第二个 table
# 获取所有行
rows = data_table.xpath('.//tr')
# 跳过第一行(表头)
for row in rows[1:]:
tds = row.xpath('./td/text()').getall()
if len(tds) < 7:
continue
item = BocItem()
item['Currency'] = tds[0].strip()
item['TBP'] = tds[1].strip() # 现汇买入价
item['CBP'] = tds[2].strip() # 现钞买入价
item['TSP'] = tds[3].strip() # 现汇卖出价
item['CSP'] = tds[4].strip() # 现钞卖出价
item['Time'] = tds[6].strip() # 发布日期
yield item
# boc_spider/items.py
import scrapy
class BocItem(scrapy.Item):
Currency = scrapy.Field()
TBP = scrapy.Field()
CBP = scrapy.Field()
TSP = scrapy.Field()
CSP = scrapy.Field()
Time = scrapy.Field()
# boc_spider/pipelines.py
import sqlite3
class BocPipeline:
def open_spider(self, spider):
self.conn = sqlite3.connect('boc_exchange.db')
self.cursor = self.conn.cursor()
self.cursor.execute('''
CREATE TABLE IF NOT EXISTS exchange_rates (
id INTEGER PRIMARY KEY AUTOINCREMENT,
Currency TEXT,
TBP TEXT,
CBP TEXT,
TSP TEXT,
CSP TEXT,
Time TEXT
)
''')
self.conn.commit()
def process_item(self, item, spider):
self.cursor.execute('''
INSERT OR REPLACE INTO exchange_rates
(Currency, TBP, CBP, TSP, CSP, Time)
VALUES (?, ?, ?, ?, ?, ?)
''', (
item['Currency'], # 从 Item 中提取货币名称
item['TBP'], # 现汇买入价
item['CBP'], # 现钞买入价
item['TSP'], # 现汇卖出价
item['CSP'], # 现钞卖出价
item['Time'] # 更新时间
))
self.conn.commit()
return item
def close_spider(self, spider):
self.conn.close()
# boc_spider/settings.py
BOT_NAME = 'boc_spider'
SPIDER_MODULES = ['boc_spider.spiders']
NEWSPIDER_MODULE = 'boc_spider.spiders'
ROBOTSTXT_OBEY = False
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0 Safari/537.36'
# 启用 SQLITE3
ITEM_PIPELINES = {
'boc_spider.pipelines.BocPipeline': 300,
}
CONCURRENT_REQUESTS_PER_DOMAIN = 1
DOWNLOAD_DELAY = 1
FEED_EXPORT_ENCODING = 'utf-8'
ADDONS = {}
# 控制 CSV 字段顺序和编码(防 Excel 乱码)
FEED_EXPORT_ENCODING = 'utf-8-sig'
FEED_EXPORT_FIELDS = ['Currency', 'TBP', 'CBP', 'TSP', 'CSP', 'Time']
结果:
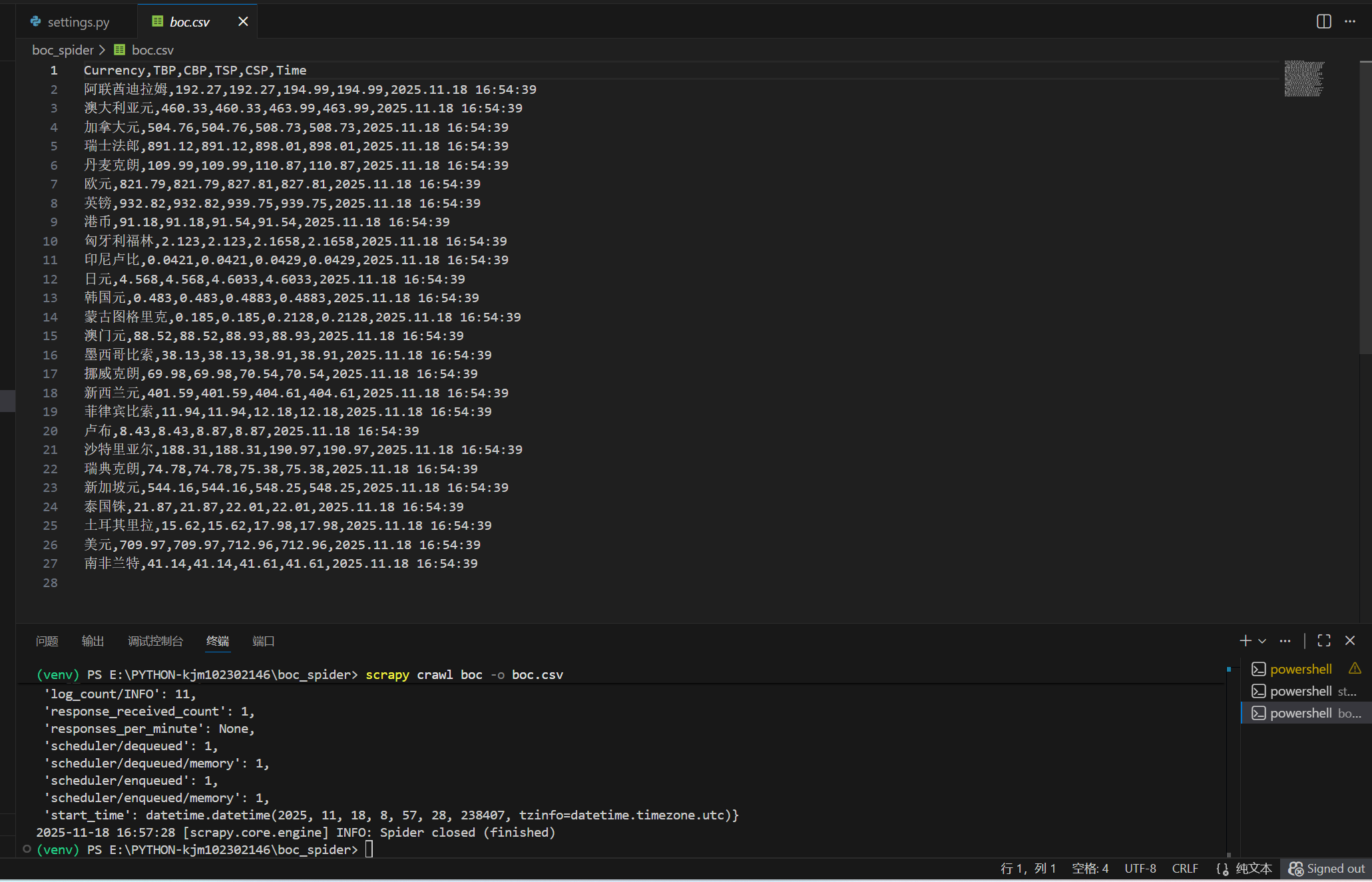
(2)心得体会:
通过本次爬取外汇数据的实践,我进一步掌握了Scrapy框架中Item和Pipeline的使用,能够熟练结合XPath提取目标字段,并将结构化数据高效存储到MySQL数据库。整个过程加深了我对爬虫数据流转机制的理解,也提升了在实际项目中处理动态网页与数据持久化的综合能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号