数据采集第一次作业
作业1
大学排名爬取实验
(1)要求:用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020 )的数据,屏幕打印爬取的大学排名信息。
核心代码
import requests
from bs4 import BeautifulSoup
#模拟浏览器访问,避免被网站识别为爬虫而拒绝请求。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
}
#目标url
url = "http://www.shanghairanking.cn/rankings/bcur/2020"
#发送 HTTP 请求并处理响应
print("正在请求网页...")
response = requests.get(url, headers=headers)
response.encoding = 'utf-8' # 显式指定编码,避免中文乱码
response.raise_for_status()
# 解析 HTML
soup = BeautifulSoup(response.text, 'html.parser')
# 查找主表格
table = soup.find('table', class_='rk-table')
if not table:
raise Exception("未找到排名表格!请检查网页结构是否变化。")
#提取表格行
rows = table.find_all('tr')[1:]
#打印表头
print("排名\t学校名称\t\t省市\t学校类型\t总分")
total = 0
for row in rows:
tds = row.find_all('td')
if len(tds) < 5:
continue # 跳过异常行
#提取各列数据
ranking = tds[0].get_text(strip=True)
# 提取学校名称(中文)
name_span = tds[1].find('span', class_='name-cn')
school_name = name_span.get_text(strip=True) if name_span else 'N/A'
province = tds[2].get_text(strip=True)
school_type = tds[3].get_text(strip=True)
score = tds[4].get_text(strip=True)
#手动调整格式,美化输出结果
if(school_name!="北京航空航天大学"and school_name!="中国科学技术大学"):
print(f"{ranking}\t{school_name}\t\t{province}\t{school_type}\t\t{score}")
else:
print(f"{ranking}\t{school_name}\t{province}\t{school_type}\t\t{score}")
total += 1
print(f"\n✅ 共爬取 {total} 所大学数据。")#统计并输出总数
结果

我的思路是先使用 requests 获取当当网“书包”搜索页的 HTML,然后通过正则表达式提取商品名称(来自 a标签的 title)和价格(来自 class="price_n" 的 ),最后对齐打印结果,并做了编码处理和简单异常捕获。
(2)心得体会
通过本次爬虫实践,我掌握了使用 requests 和 BeautifulSoup 定向提取网页结构化数据的方法,加深了对 HTML 标签解析与数据清洗的理解。
作业2
购物网站书包信息爬取实验
(1)要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
核心代码:
# 发送请求并处理响应
try:
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'gbk'
html = response.text
# 提取商品名称(title 属性)
name_pattern = r'<a[^>]+title="([^"]+)"[^>]*class="pic"[^>]*>'
names = re.findall(name_pattern, html)
# 提取价格
price_pattern = r'<span[^>]+class\s*=\s*["\']price_n["\'][^>]*>\s*¥([\d.]+)\s*</span>'
prices = re.findall(price_pattern, html)
# 商品和价格数量
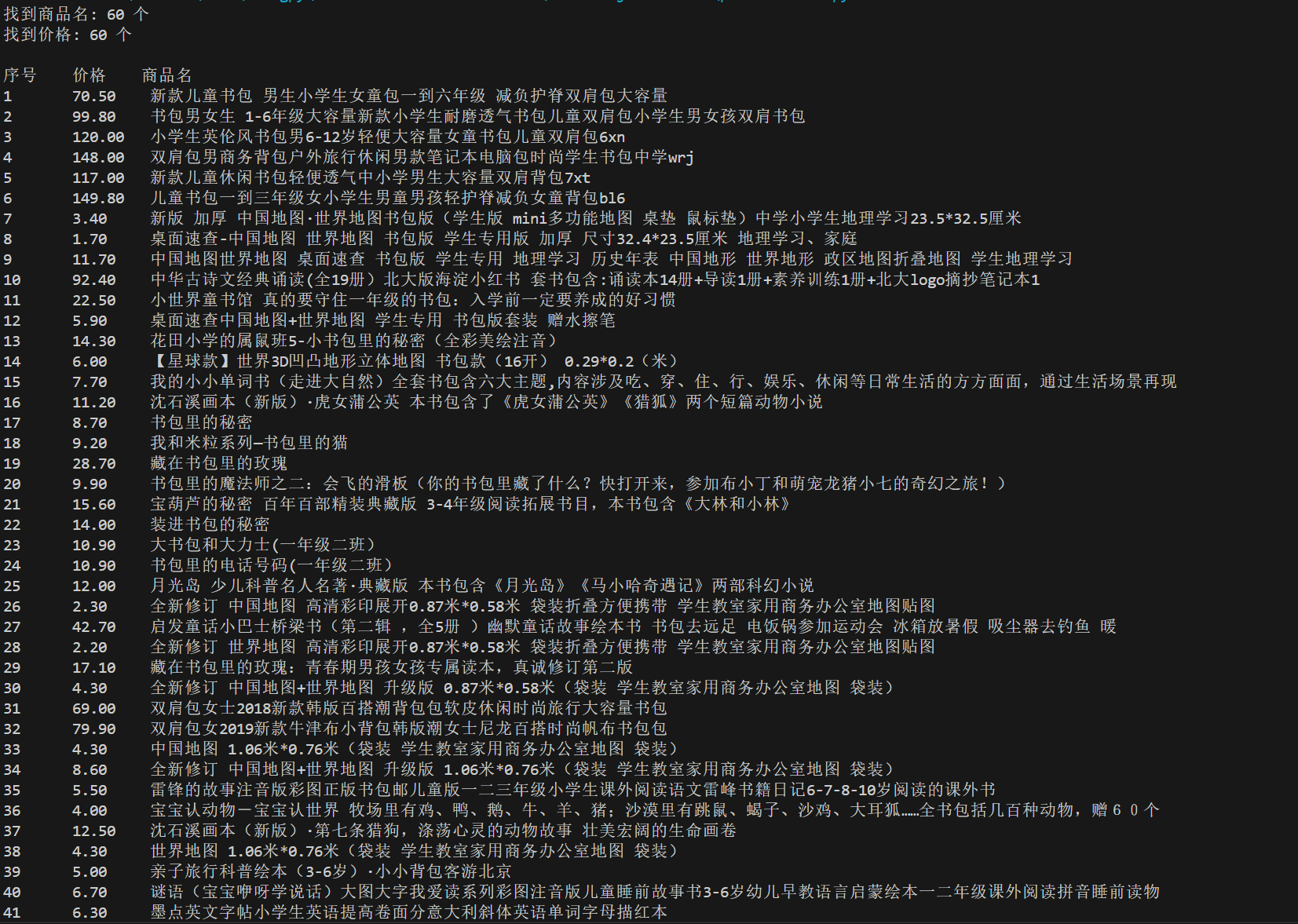
print(f"找到商品名: {len(names)} 个")
print(f"找到价格: {len(prices)} 个")
# 输出结果
print("\n序号\t价格\t商品名")
for i in range(min(len(names), len(prices))):
print(f"{i+1}\t{prices[i]}\t{names[i]}")
except Exception as e:
print(f"错误: {e}")
结果

我的思路是先使用 requests 获取软科2020中国大学排名页面,再通过 BeautifulSoup 解析 HTML,定位表格并逐行提取排名、校名、省市、类型和总分,最后格式化打印结果,实现了结构化数据的定向爬取与展示。
(2)心得体会
通过本次爬虫实践,我学会了使用 requests 和 re 库从当当网搜索页提取商品名称与价格,体会到正则表达式在简单结构网页中提取数据的高效性,也认识到其对页面变动的敏感性。
作业3
图片爬取实验
要求:爬取一个给定网页(https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG、JPG或PNG格式图片文件
核心代码:
# 编译正则:匹配 img 标签中的 src 属性(支持单引号、双引号、无引号)
img_pattern = re.compile(r'<img[^>]+src\s*=\s*[\'"]?([^\'"\s>]+)', re.IGNORECASE)
def fetch_page(url):
# 使用 urllib 下载网页内容,返回字符串
try:
with urllib.request.urlopen(url, timeout=10) as response:
if response.status == 200:
content = response.read()
# 匹配gb2312 或 utf-8
try:
html = content.decode('utf-8')
except UnicodeDecodeError:
try:
html = content.decode('gb2312')
except UnicodeDecodeError:
html = content.decode('utf-8', errors='ignore')
return html
else:
print(f"❌ 状态码 {response.status},跳过: {url}")
return None
except Exception as e:
print(f"⚠️ 无法访问 {url}: {e}")
return None
def extract_image_urls(html, page_url):
# 从 HTML 中提取所有图片 URL,并转为绝对路径
matches = img_pattern.findall(html)
abs_urls = []
for src in matches:
# 跳过 data:image 等 base64 图片(内嵌图片,无法下载)
if src.startswith('data:'):
continue
# 转为绝对 URL
abs_url = urllib.parse.urljoin(page_url, src)
abs_urls.append(abs_url)
return abs_urls
def download_image(img_url):
if img_url in downloaded_urls:
return #去重检查
try:
# 生成本地文件名(简单处理:取 URL 最后部分)
filename = os.path.basename(urllib.parse.urlparse(img_url).path)
if not filename or '.' not in filename:
filename = f"image_{hash(img_url) % 1000000}.jpg"
filepath = os.path.join(image_dir, filename)
# 避免文件名冲突
counter = 1
orig_filepath = filepath
while os.path.exists(filepath):
name, ext = os.path.splitext(orig_filepath)
filepath = f"{name}_{counter}{ext}"
counter += 1
print(f"下载图片: {img_url} → {filepath}")
urllib.request.urlretrieve(img_url, filepath)
downloaded_urls.add(img_url) #记录已下载
except Exception as e:
print(f"下载失败 {img_url}: {e}")


我的思路是先使用urllib 爬取福州大学新闻网“要闻动态”多页内容,再通过正则表达式提取所有 标签的 src 链接,然后转为绝对 URL,过滤非图片链接,并将 JPEG/JPG/PNG 等格式图片下载保存到本地 images 文件夹,同时利用集合实现去重、编码兼容、文件名冲突处理和请求延时,确保稳定高效地完成图片批量抓取。
(2)心得体会
通过本次实践,我掌握了如何使用 urllib 库进行网页内容抓取,并利用正则表达式匹配网页中图片标签的 src 属性,从而有效地提取出图片链接。在这个过程中,我学会了处理不同编码(如 utf-8 和 gb2312)的网页,确保了数据解析的准确性。同时,通过实现简单的去重逻辑和避免重复下载,我能够高效地管理下载的图片资源。此外,我还学了采取了适当的延时策略来减少请求频率,降低了被目标网站误判为恶意爬虫的风险。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号