

【周总结 2021.5.12】pytorch对数据常用操作+人工智能算法介绍+外部注意力机制
数据常用操作
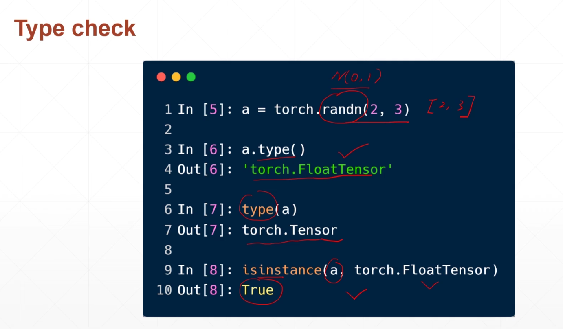
数据类型判断
Cuda中数据判断

按照维度(DIM)创建tensor
0维(标量)

1维

2维

3维

4维

判断维度和元素个数

从numpy或list中导入数据


未初始化数据特点 设置默认数据类型(set_default_tensor_type(torch.DoubleTensor)) 随机初始化数据(torch.rand(): [0,1] torch.rand_like randint [min,max) randn:正态分布 ) 全部赋值为同一个元素 full 生成等差数列(arrange/range) 等分数列(linspace/logspace) 全1全0 E (ones zeros eye) 范围内随机排列(randperm random.shuffle) Tensor索引take tensor变换view unsqueeze squeeze expand/edpand_as repeat transpose permute 通过 save 函数和 load 函数可以很⽅便地读写 Tensor 。 通过 save 函数和 load_state_dict 函数可以很⽅便地读写模型的参数。 可以通过 Module 类⾃定义神经⽹络中的层,从⽽可以被重复调⽤
算法总结
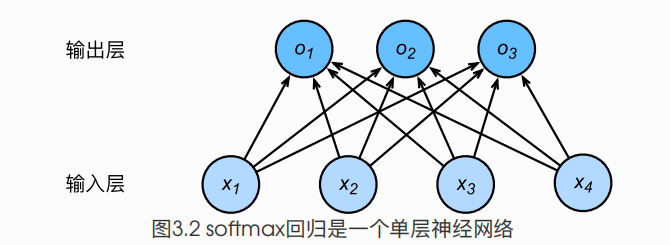
SOFTMAX回归模型
softmax回归跟线性回归⼀样将输⼊特征与权᯿做线性叠加。与线性回归的⼀个主要不同在于, softmax回归的输出值个数等于标签⾥的类别数。 交叉熵适合衡量两个概率分布的差异
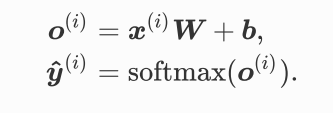

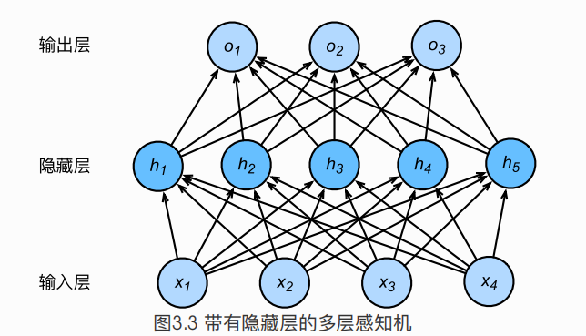
隐藏层
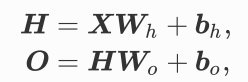
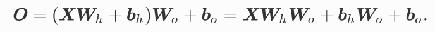
激活函数
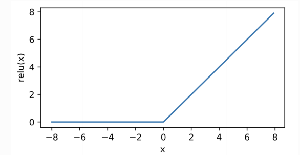
relu函数
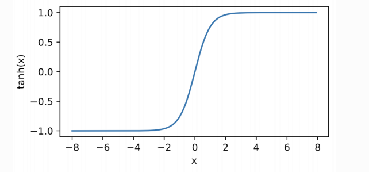
tanh函数
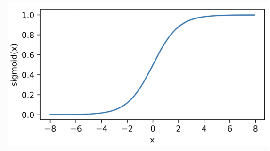
sigmoid函数

⽋拟合和过拟合
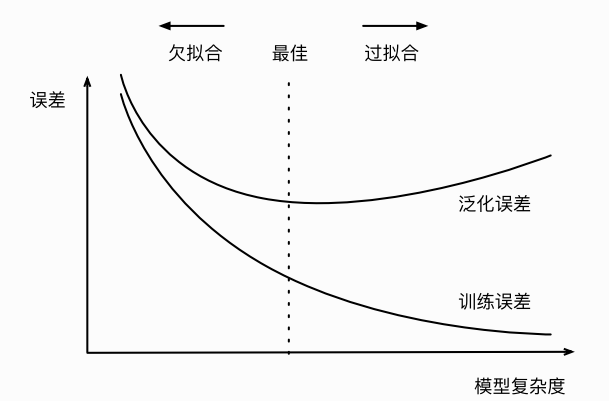
欠拟合: 增加模型的复杂度 惩罚力度 过拟合: 权重衰减:范数正则化 令权和先⾃乘⼩于1的数,再 减去不含惩罚项的梯度。因此范数正 则化⼜叫权衰减。 增加训练样本
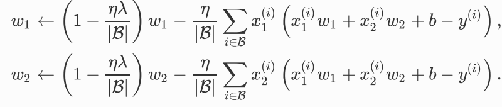
Forward and backward
正向传播沿着从输⼊层到输出层的顺序,依次计算并存储神经⽹络的中间变量。
反向传播沿着从输出层到输⼊层的顺序,依次计算并存储神经⽹络中间变量和参数的梯度。
K折交叉验证
在 K折交叉验证中我们训练 K次并返回训练和验证的平均误差。 可以使⽤K折交叉验证来选择模型并调节超参数
Pytorch中的模型构造
继承 MODULE 类来构造模型

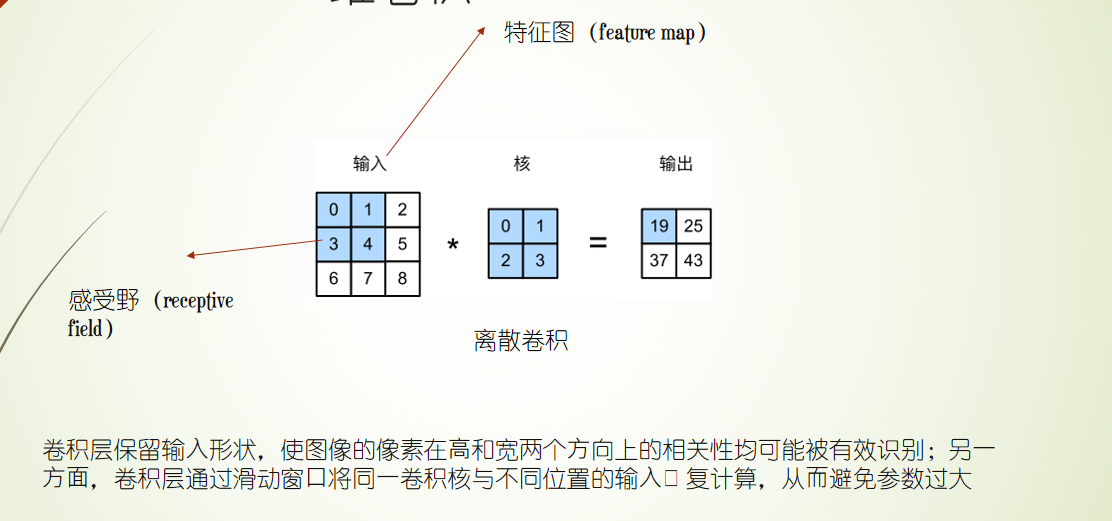
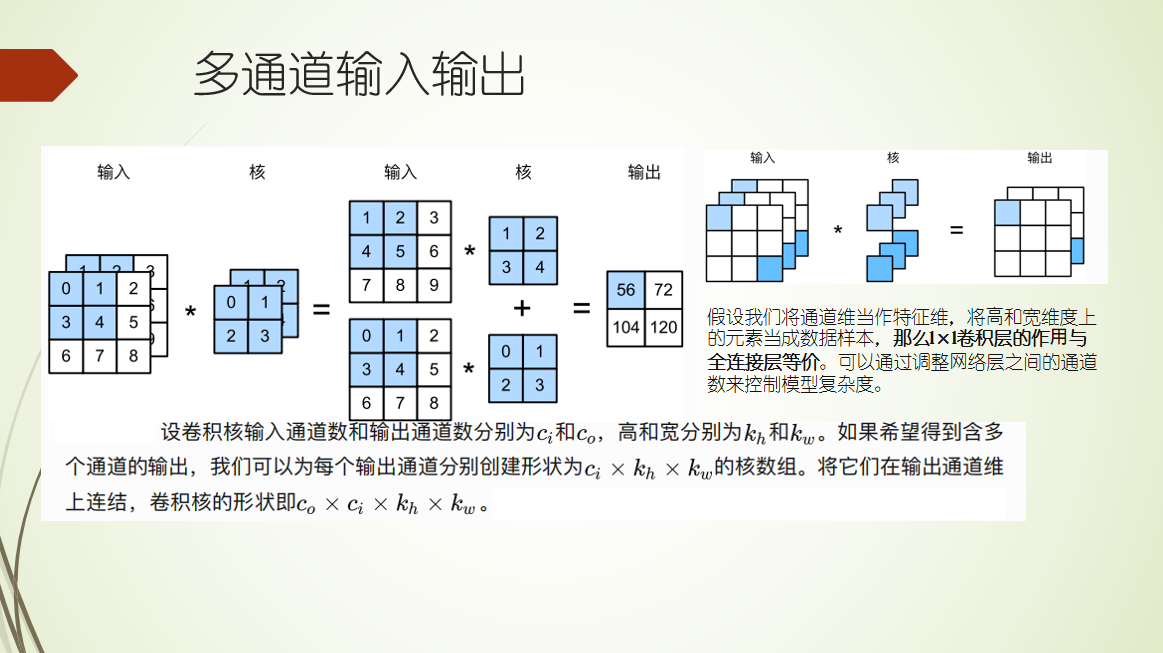
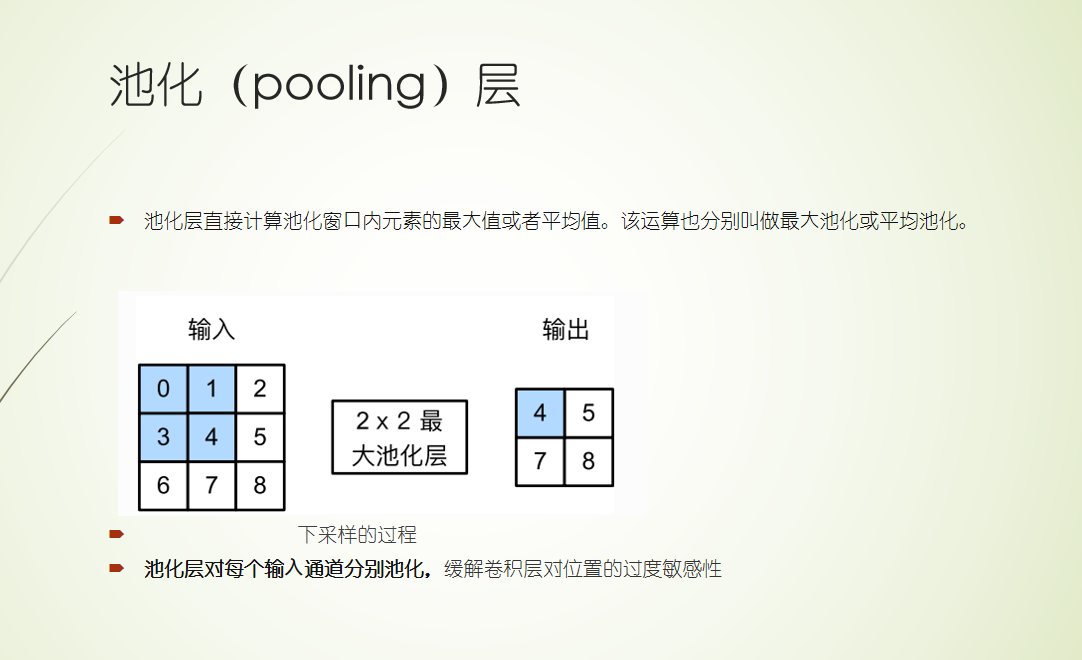
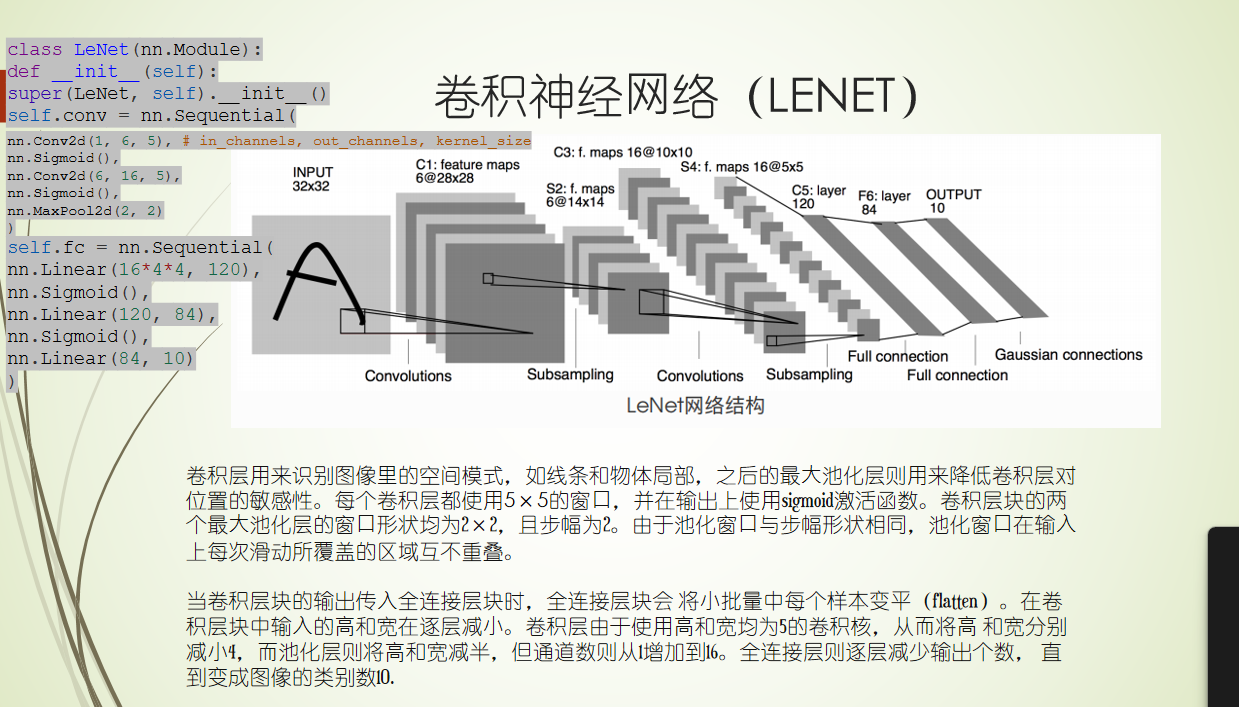
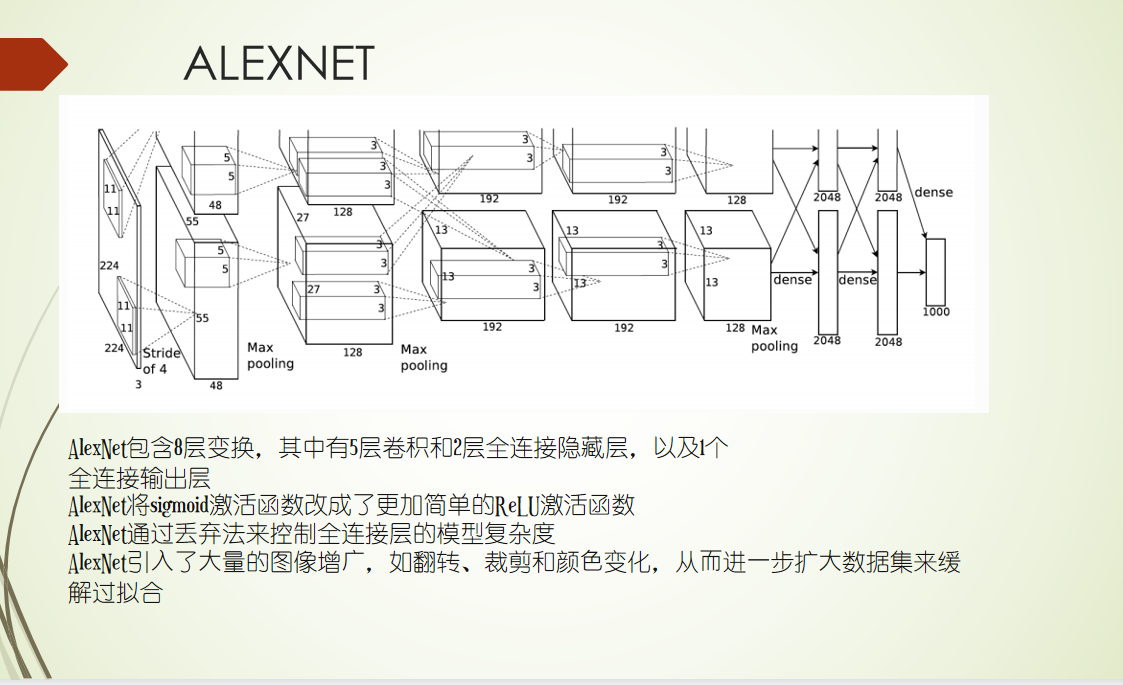
CNN 二维卷积


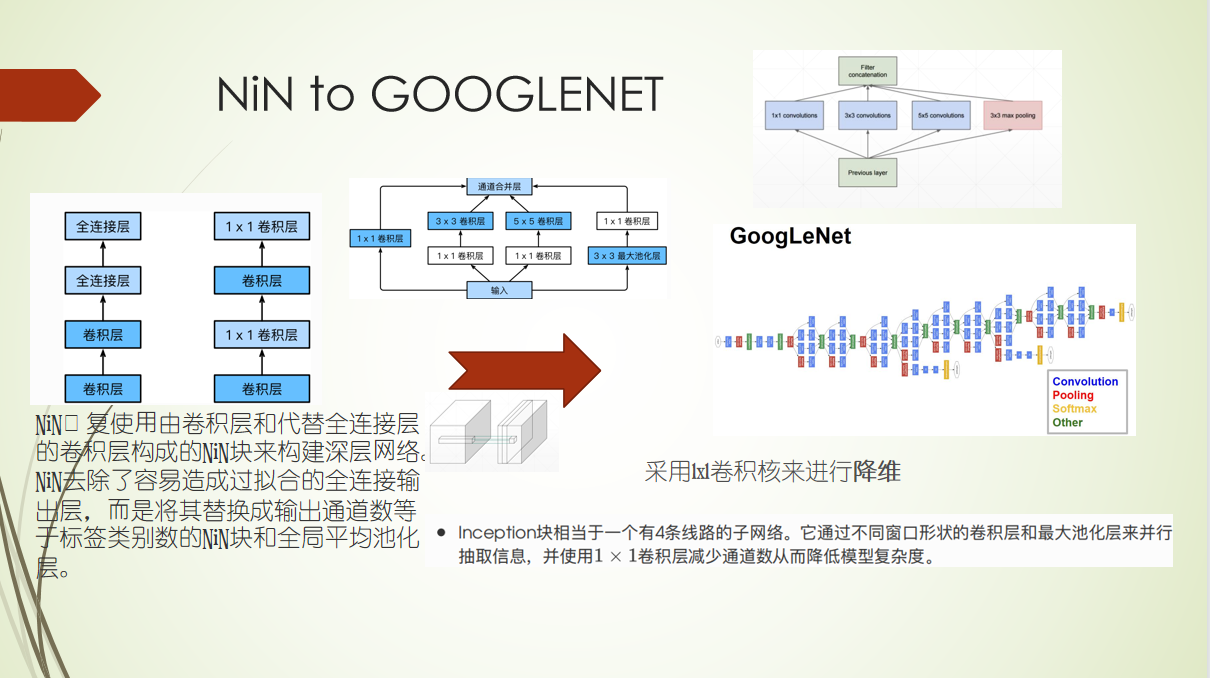
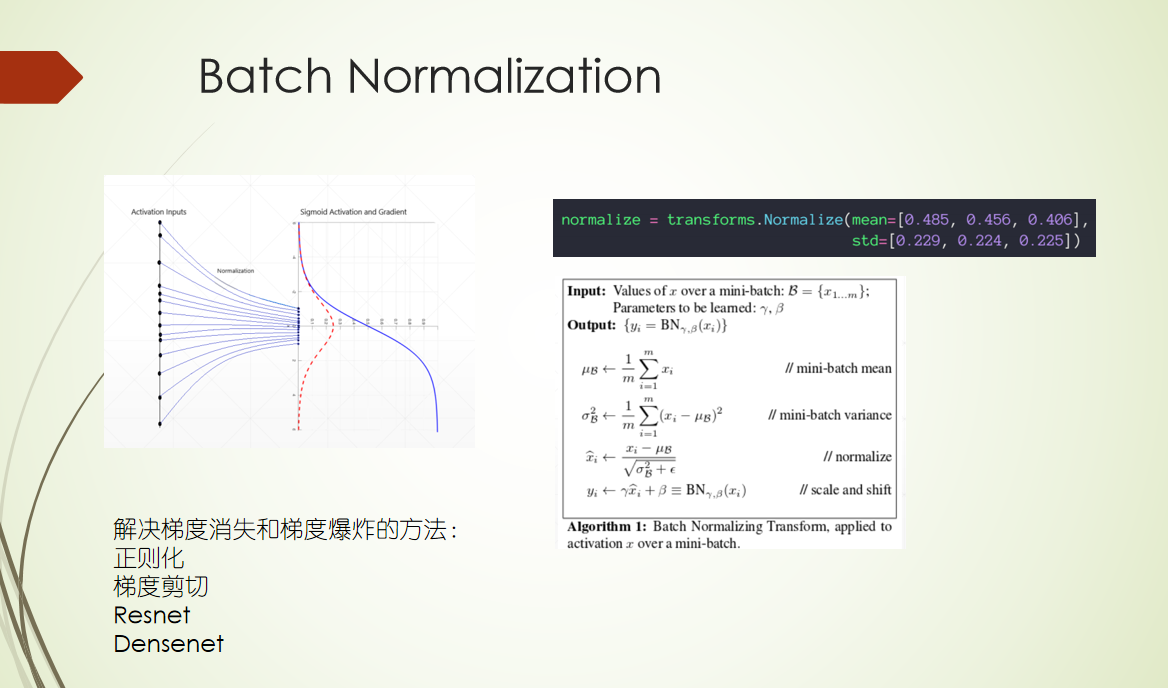
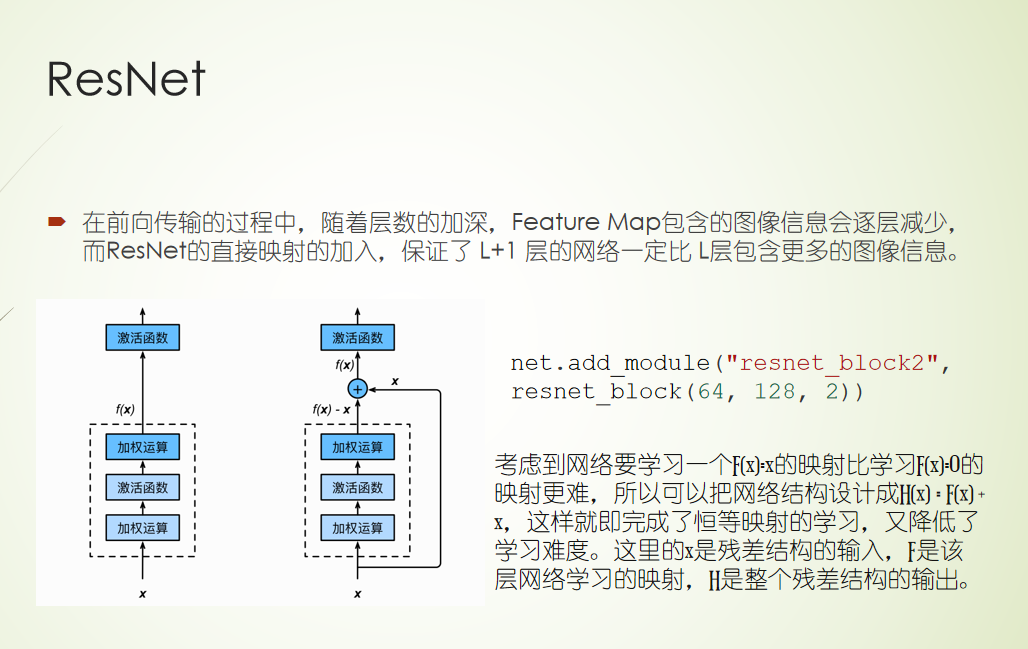
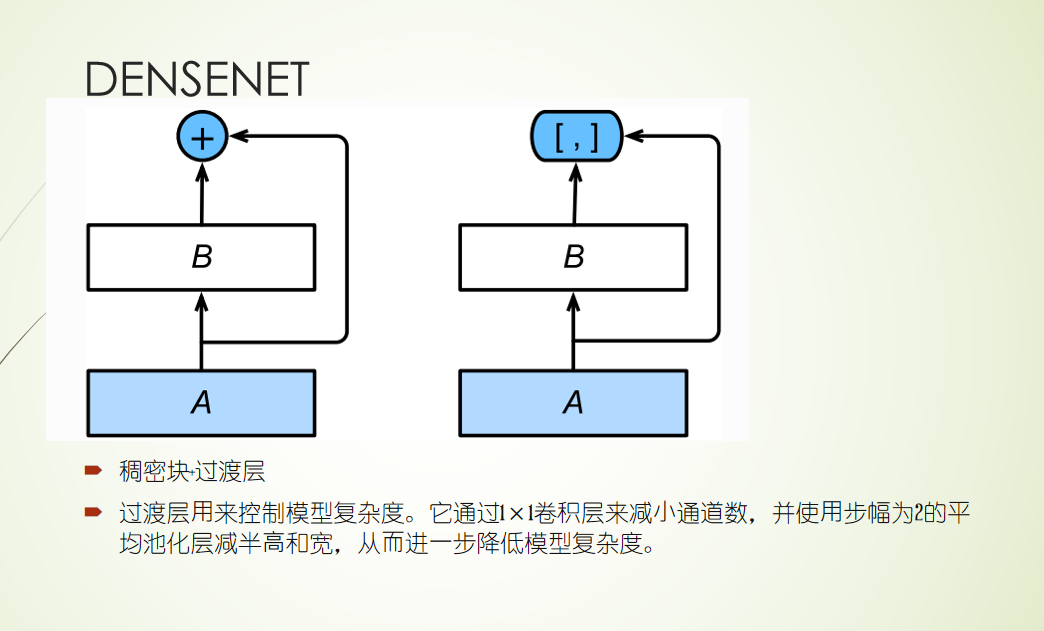

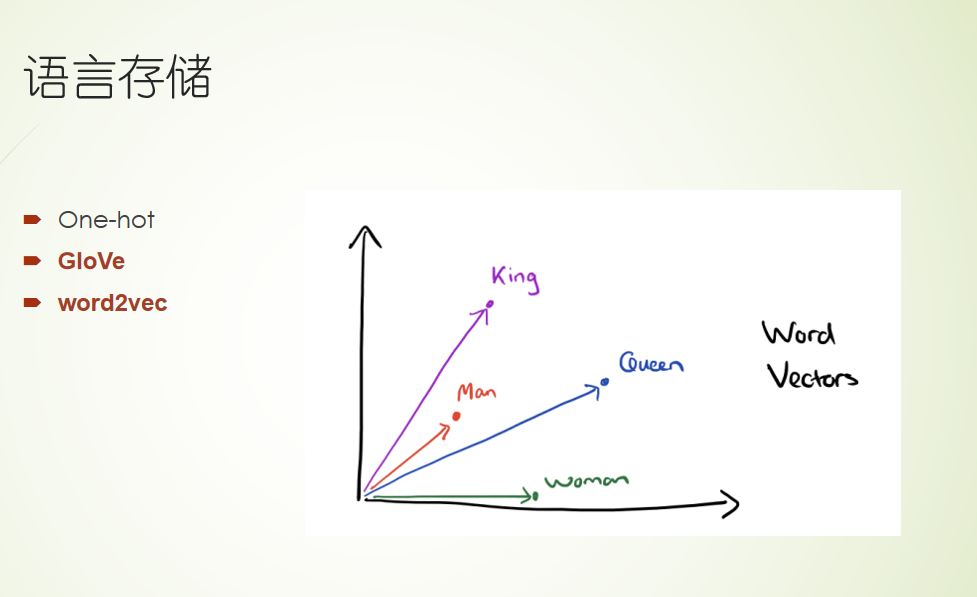
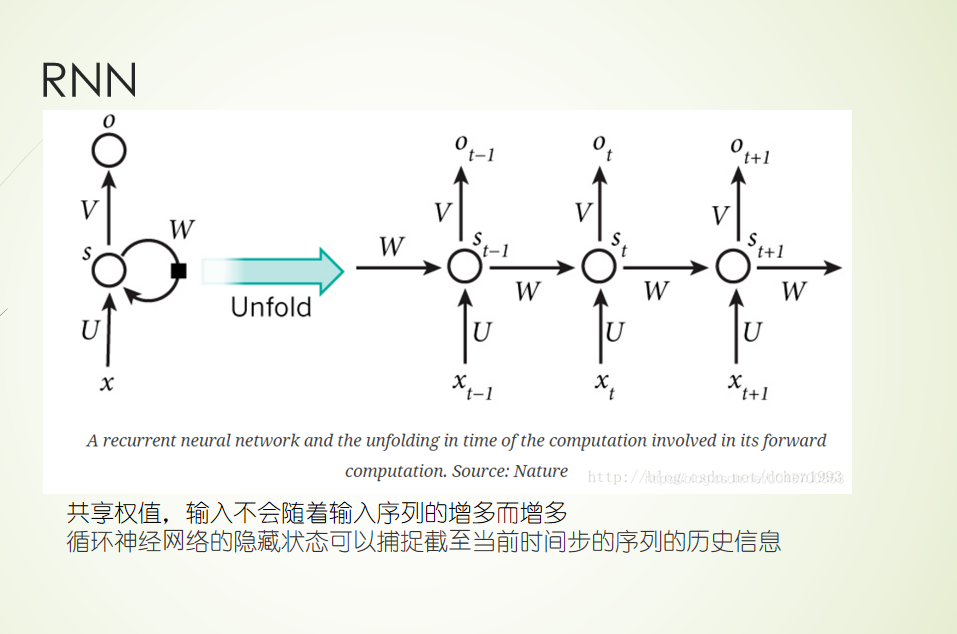
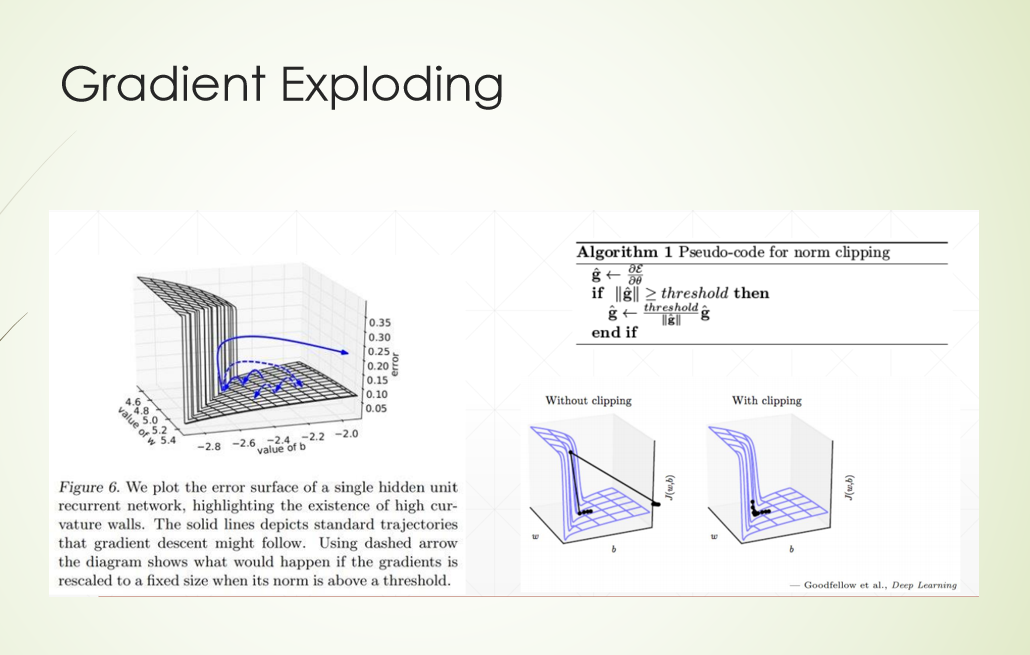
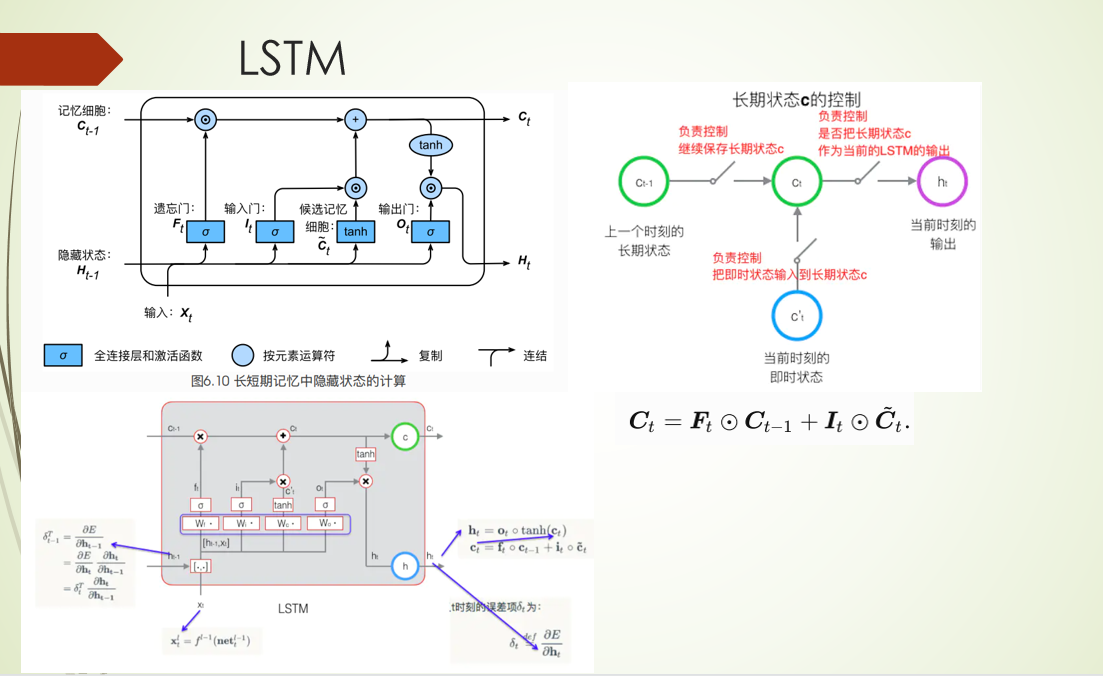
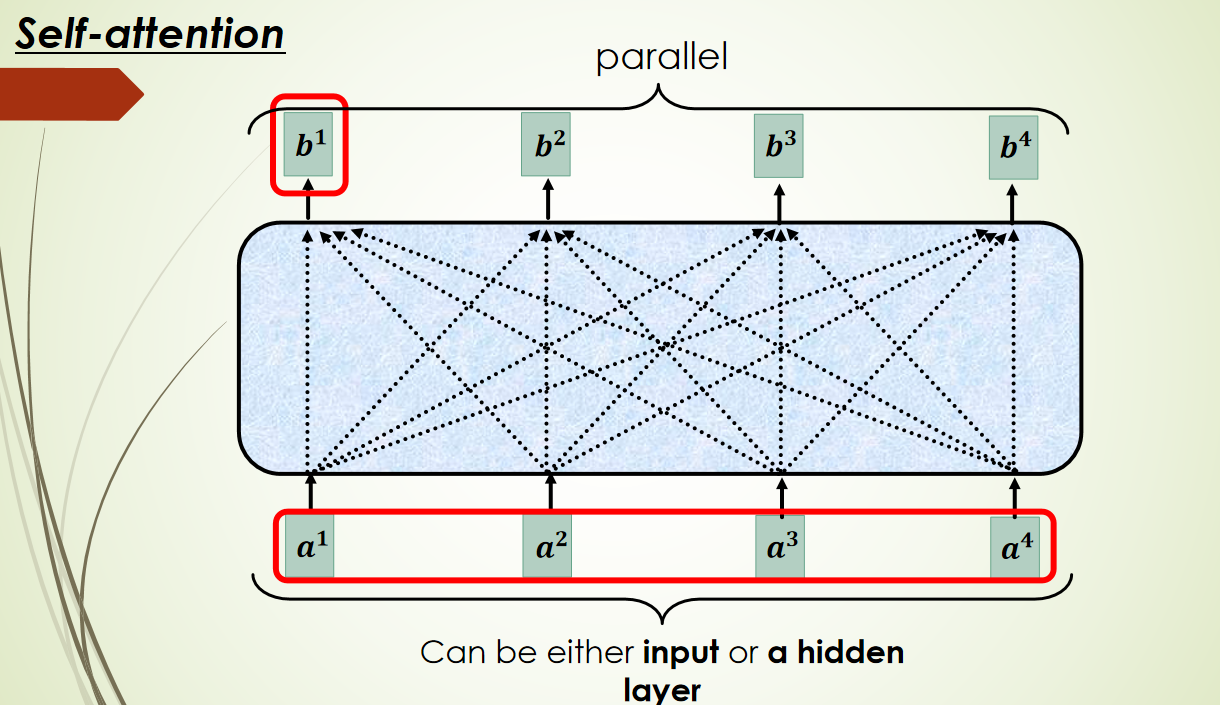
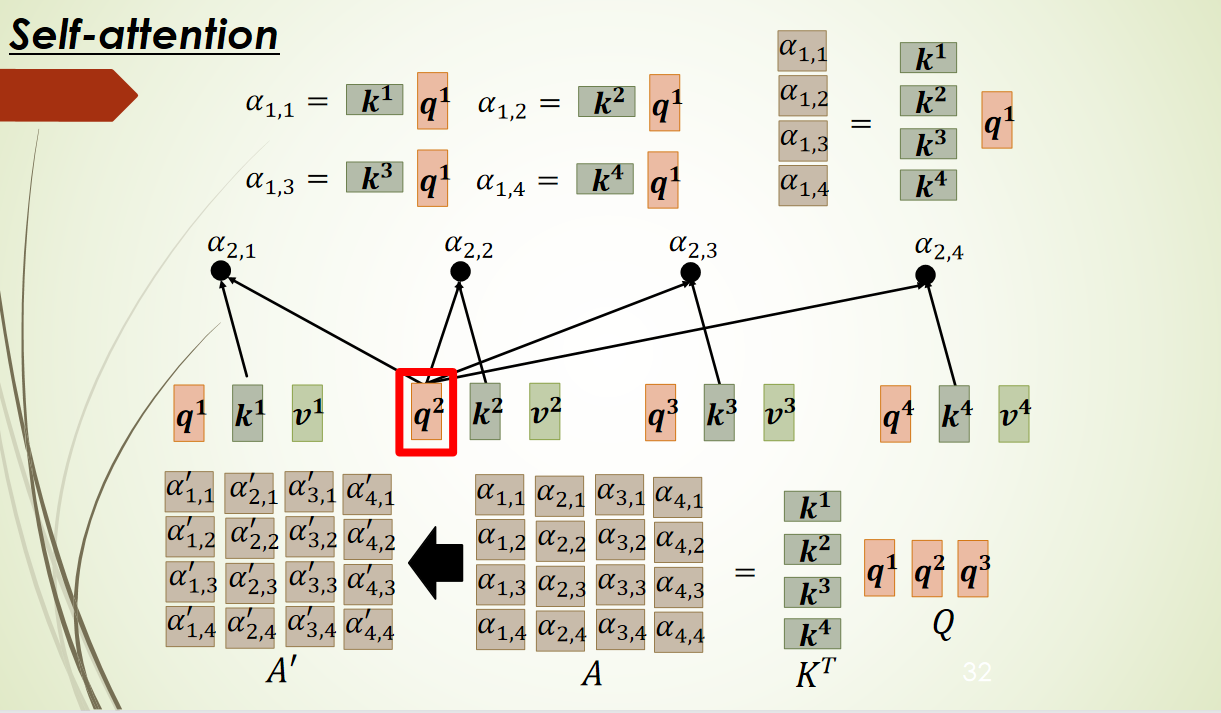
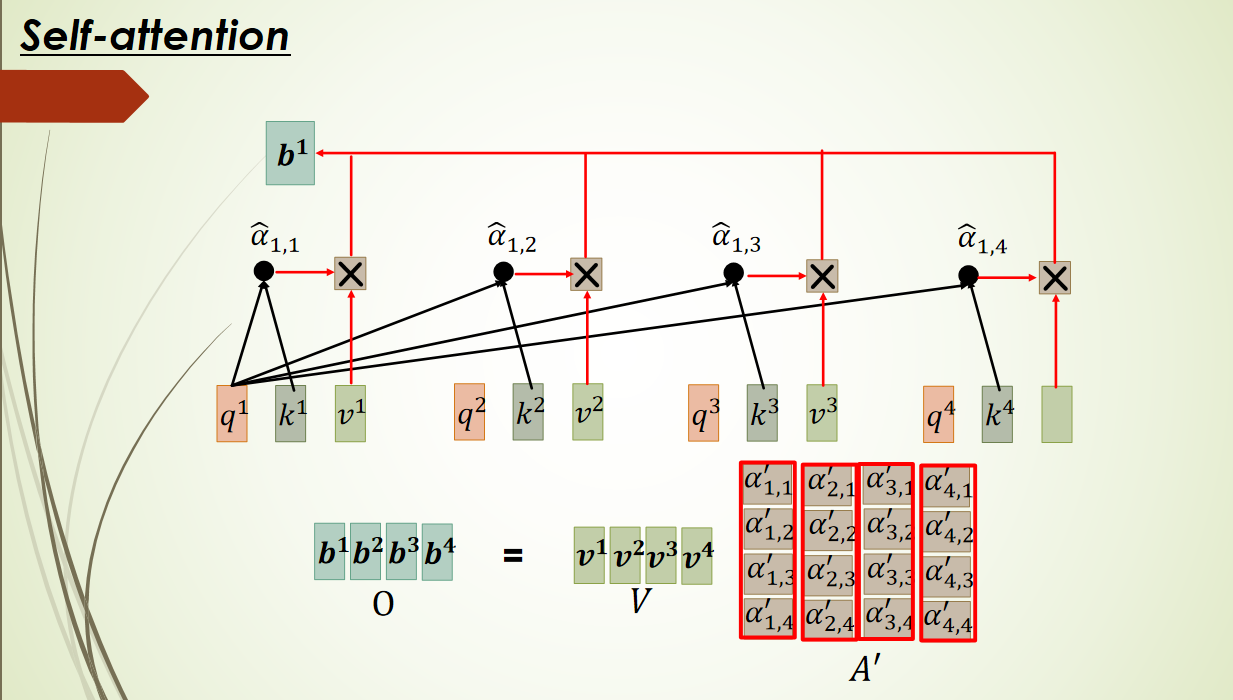


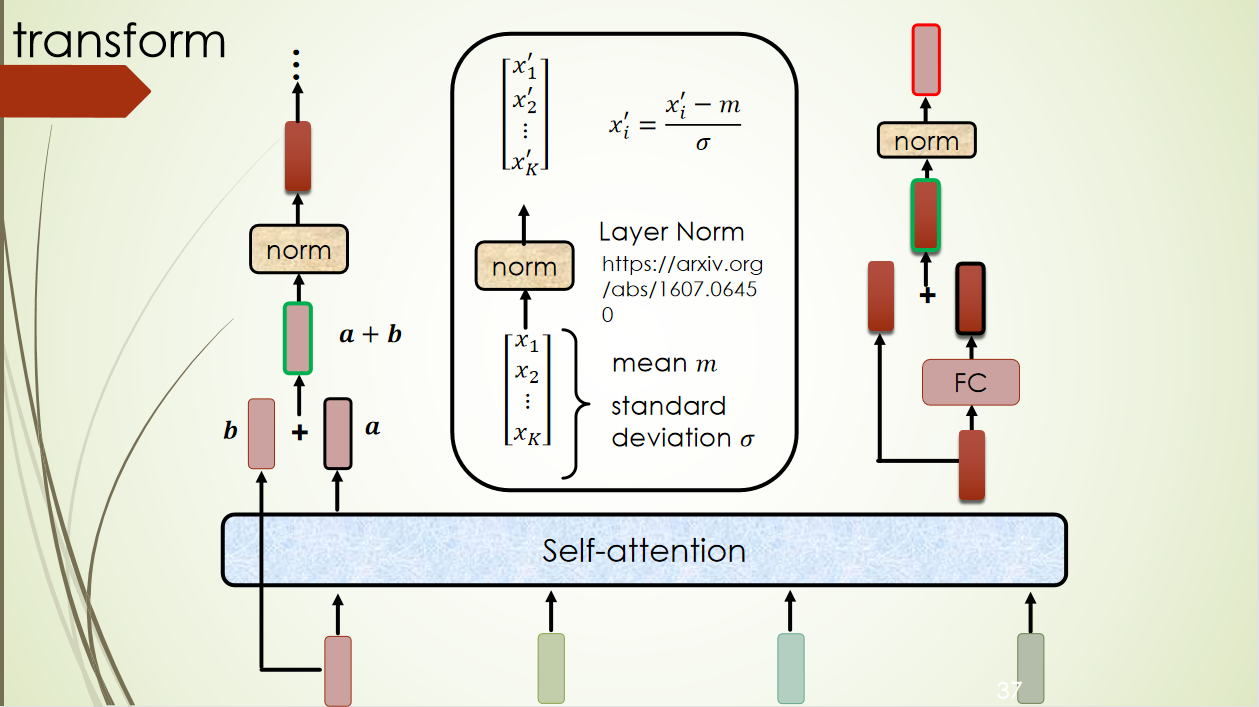

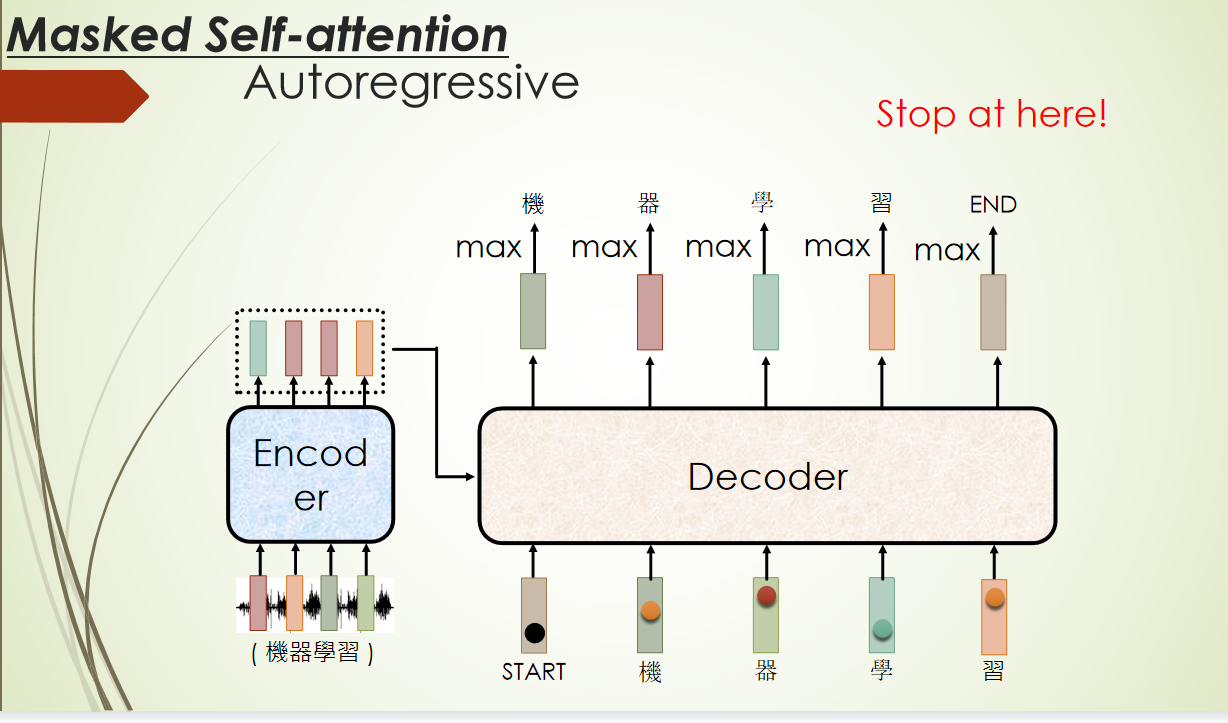
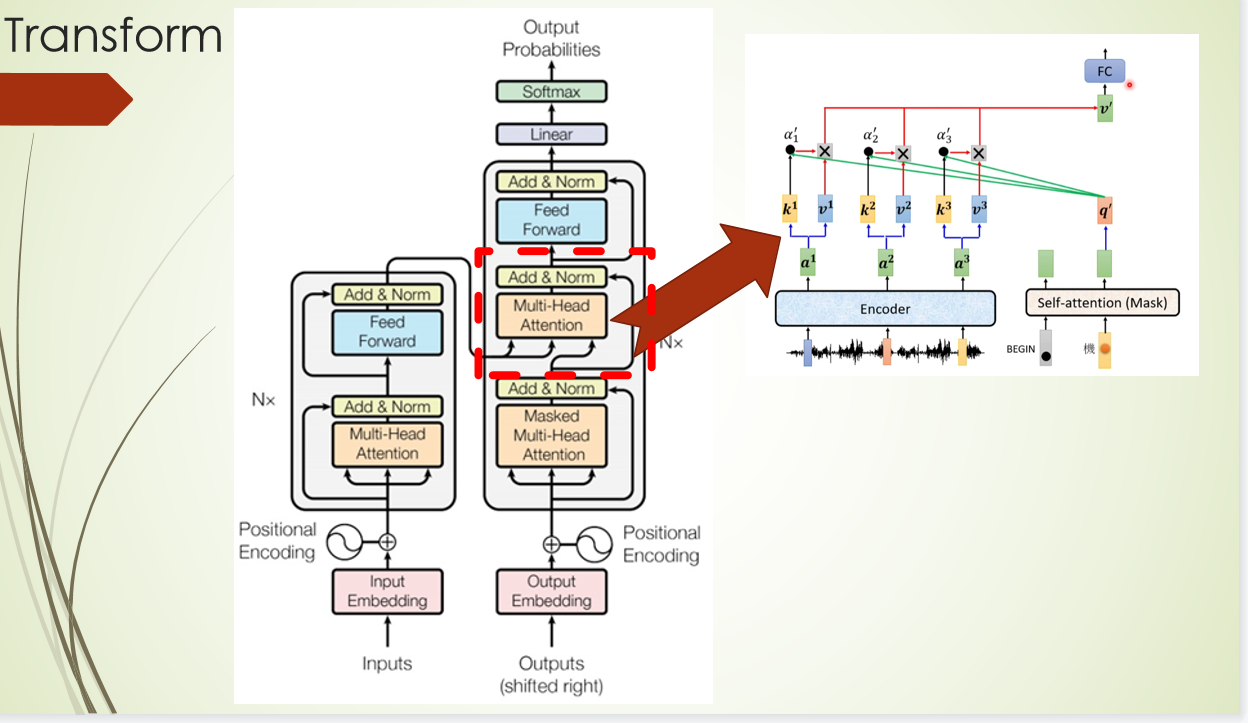
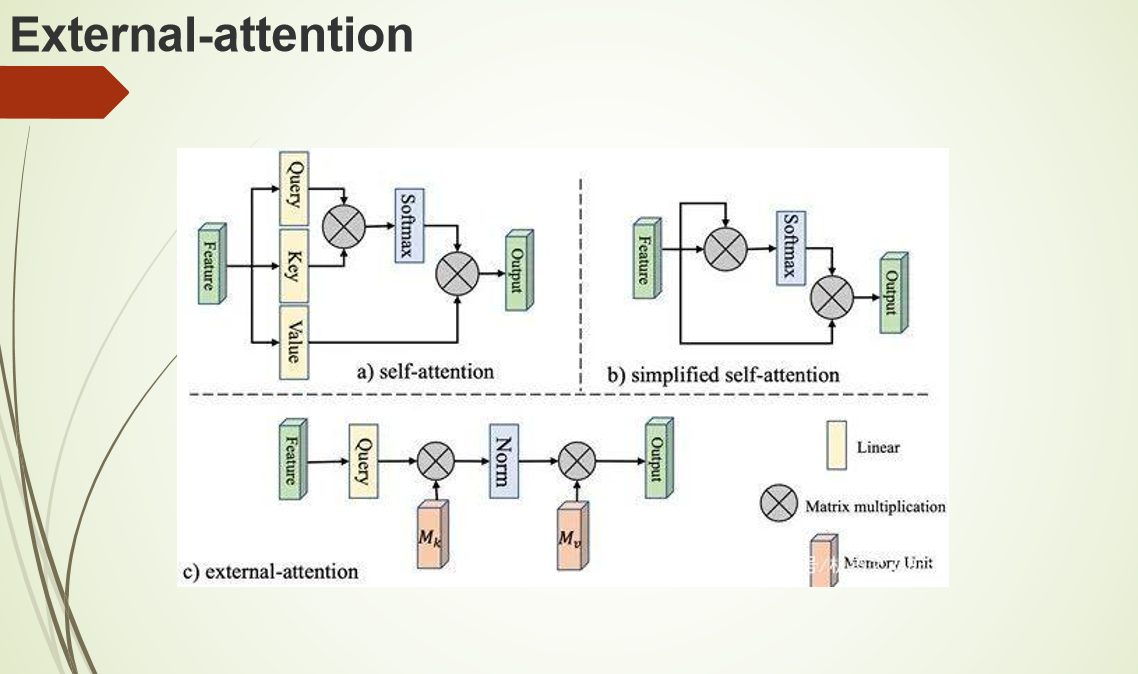
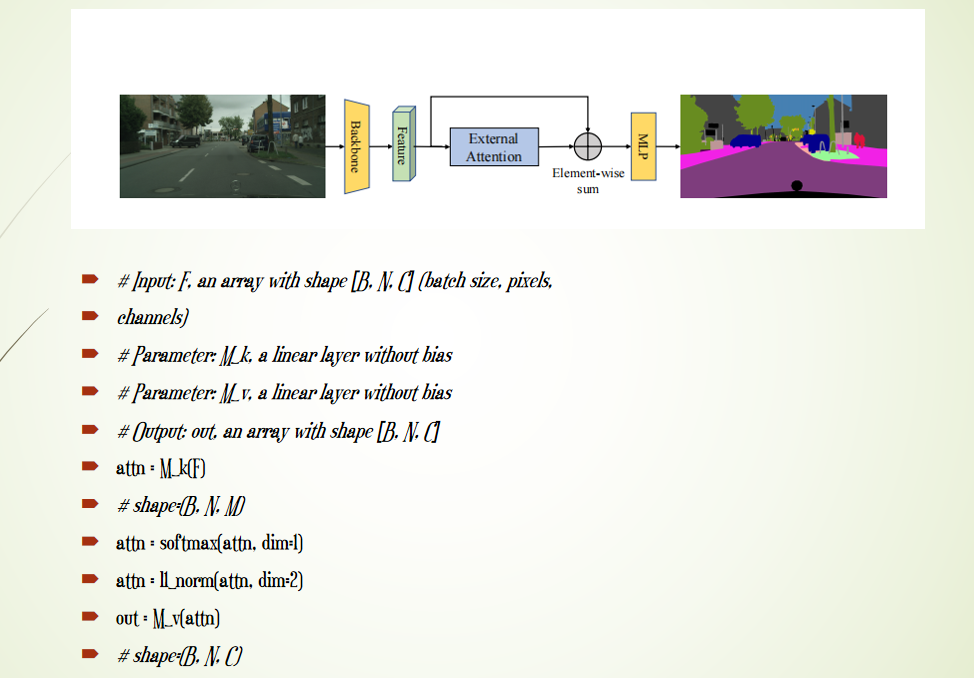
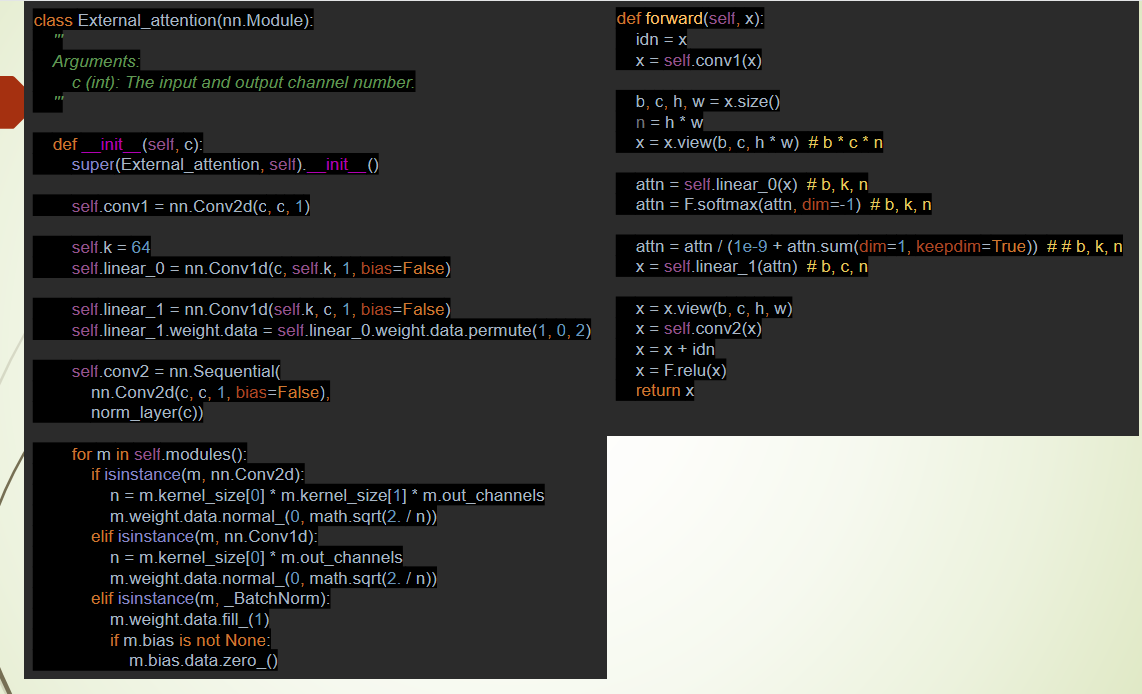
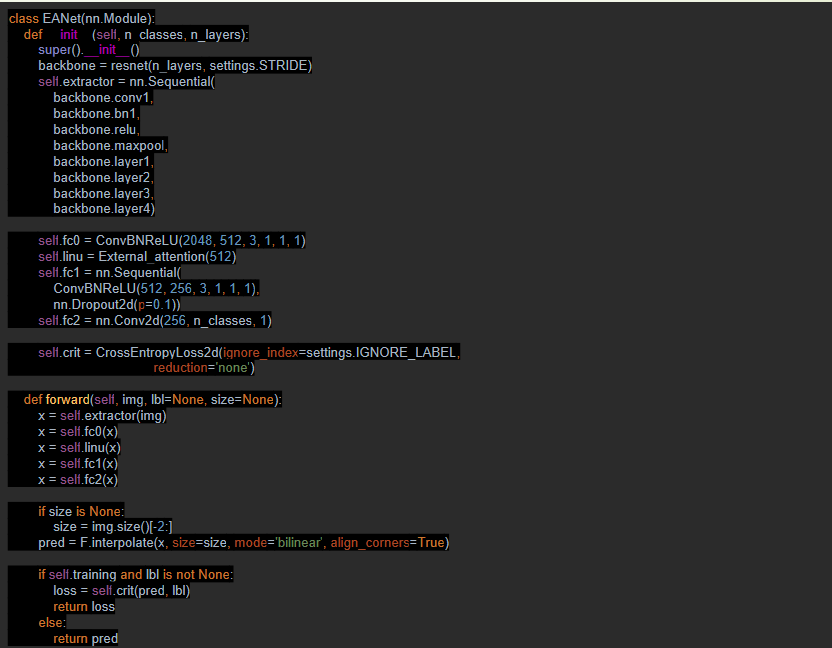
外部注意力机制


posted on 2021-11-08 11:28 KID_XiaoYuan 阅读(79) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号