


面试总结2.0
1 shell命令:如何查询内存大小 文件大小和端口有没有被占用等 awk获取行列内容
1,lsof -i:端口号
2,netstat -tunlp|grep 端口号
lsof abc.txt 显示开启文件abc.txt的进程
lsof -i :22 知道22端口现在运行什么程序
lsof -c abc 显示abc进程现在打开的文件
lsof -g gid 显示归属gid的进程情况
lsof +d /usr/local/ 显示目录下被进程开启的文件
lsof +D /usr/local/ 同上,但是会搜索目录下的目录,时间较长
lsof -i 用以显示符合条件的进程情况
语法: lsof -i[46] [protocol][@hostname|hostaddr][:service|port]
46 --> IPv4 or IPv6
protocol --> TCP or UDP
hostname --> Internet host name
hostaddr --> IPv4位置
service --> /etc/service中的 service name (可以不只一个)
port --> 端口号 (可以不只一个)
例子: TCP:25 - TCP and port 25
lsof -n 不将IP转换为hostname,缺省是不加上-n参数
例子: lsof -i tcp@ohaha.ks.edu.tw:ftp -n
lsof -p 12 看进程号为12的进程打开了哪些文件
lsof +|-r [t] 控制lsof不断重复执行,缺省是15s刷新
-r,lsof会永远不断的执行,直到收到中断信号
+r,lsof会一直执行,直到没有档案被显示
例子:不断查看目前ftp连接的情况:lsof -i tcp@ohaha.ks.edu.tw:ftp -r
lsof -s 列出打开文件的大小,如果没有大小,则留下空白
netstat -ntlp //查看当前所有tcp端口 netstat -ntulp | grep 80 //查看所有80端口使用情况 netstat -ntulp | grep 3306 //查看所有3306端口使用情况
3、awk命令:
这个awk命令被称作三剑客…开始以为很简单的一个命令 其实内容还是挺多的… 我查了一下先从简单的开始说吧
被问及如果打印第三行的内容 那就是 awk 'NR==3'这里的NR是行的意思 如果是第三列就是 awk '{print $3}' 倒数第三列就是 $-3
这里都是类似的,那么继续升级
awk '$3 == 0 { print $1 }' file1 file2
打印file1和file2文件中第三个字段为0的每一行的第一个字段。 同理行列还可以做运算。更多参考博客内容https://awk.readthedocs.io/en/latest/chapter-one.html这里说的很详细
最后综合一个 如何利用awk和df计算剩余磁盘空间的栗子:df -m|awk '$4~/^[0-9]/ {split($4,array,"[A-Z]");b+=array[1]} END {print b/1024}'
其他查询命令:
4、显示进程信息(包括CPU、内存使用等信息):top
top使用格式 top [-] [d] [p] [q] [c] [C] [S] [s] [n] top参数说明 d: 指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。 p: 通过指定监控进程ID来仅仅监控某个进程的状态。 q: 该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。 S: 指定累计模式 s: 使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。 i: 使top不显示任何闲置或者僵死进程。 c: 显示整个命令行而不只是显示命令名 交互命令 Ctrl+L: 擦除并且重写屏幕。 h或者?: 显示帮助画面,给出一些简短的命令总结说明。 k: 终止一个进程。系统将提示用户输入需要终止的进程PID,以及需要发送给该进程什么样的信号。一般的终止进程可以使用15信号;如果不能正常结束那就使用信号9强制结束该进程。默认值是信号15。在安全模式中此命令被屏蔽。 i: 忽略闲置和僵死进程。这是一个开关式命令。 q: 退出程序。 r: 重新安排一个进程的优先级别。系统提示用户输入需要改变的进程PID以及需要设置的进程优先级值。输入一个正值将使优先级降低,反之则可以使该进程拥有更高的优先权。默认值是10。 S: 切换到累计模式。 s: 改变两次刷新之间的延迟时间。系统将提示用户输入新的时间,单位为s。如果有小数,就换算成m s。输入0值则系统将不断刷新,默认值是5 s。需要注意的是如果设置太小的时间,很可能会引起不断刷新,从而根本来不及看清显示的情况,而且系统负载也会大大增加。 f或者F: 从当前显示中添加或者删除项目。 o或者O: 改变显示项目的顺序。 l: 切换显示平均负载和启动时间信息。 m: 切换显示内存信息。 t: 切换显示进程和CPU状态信息。 c: 切换显示命令名称和完整命令行。 M: 根据驻留内存大小进行排序。 P: 根据CPU使用百分比大小进行排序。 T: 根据时间/累计时间进行排序。 W: 将当前设置写入~/.toprc文件中。这是写top配置文件的推荐方法。
举例:
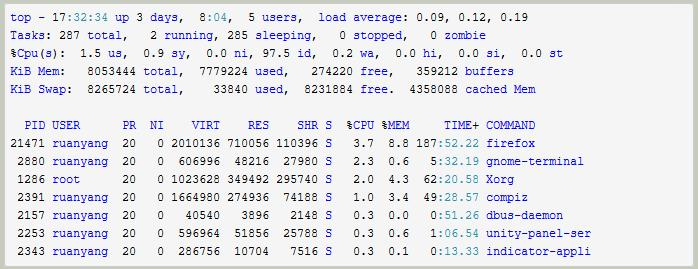
- 第一行:任务队列信息,与uptime命令执行结果相同。
- 17:32:34:系统当前时间
- up 3 days, 8:04:主机已运行时间
- 5 users:用户连接数(不是用户数,who命令)
- load average: 0.09, 0.12, 0.19:系统平均负载,统计最近1,5,15分钟的系统平均负载
补充:uptime -V可查询版本
- 第二行:进程信息
- Tasks: 287 total:进程总数
- 2 running:正在运行的进程数
- 285 sleeping:睡眠的进程数
- 0 stopped:停止的进程数
- 0 zombie:僵尸进程数
- 第三行:CPU信息(当有多个CPU时,这些内容可能会超过两行)
- 1.5 us:用户空间所占CPU百分比
- 0.9 sy:内核空间占用CPU百分比
- 0.0 ni:用户进程空间内改变过优先级的进程占用CPU百分比
- 97.5 id:空闲CPU百分比
- 0.2 wa:等待输入输出的CPU时间百分比
- 0.0 hi:硬件CPU中断占用百分比
- 0.0 si:软中断占用百分比
- 0.0 st:虚拟机占用百分比
- 第四行:内存信息(与第五行的信息类似与free命令)
- 8053444 total:物理内存总量
- 7779224 used:已使用的内存总量
- 274220 free:空闲的内存总量(free+used=total)
- 359212 buffers:用作内核缓存的内存量
- 第五行:swap信息
- 8265724 total:交换分区总量
- 33840 used:已使用的交换分区总量
- 8231884 free:空闲交换区总量
- 4358088 cached Mem:缓冲的交换区总量,内存中的内容被换出到交换区,然后又被换入到内存,但是使用过的交换区没有被覆盖,交换区的这些内容已存在于内存中的交换区的大小,相应的内存再次被换出时可不必再对交换区写入。
5、vmstat(虚拟内存统计)的缩写,可对操作系统的虚拟内存、进程、CPU活动进行监控。是对系统的整体情况进行统计,不足之处是无法对某个进程进行深入分析。
6、lscpu:此命令用来显示cpu的相关信息
lscpu从sysfs和/proc/cpuinfo收集cpu体系结构信息,命令的输出比较易读
命令输出的信息包含cpu数量,线程,核数,套接字和Nom-Uniform Memeor Access(NUMA),缓存等
不是所有的列都支持所有的架构,如果指定了不支持的列,那么lscpu将打印列,但不显示数据。
使用举例:lscpu /proc/cpuinfo
7、uptime
以下显示输入uptime的信息:
04:03:58 up 10 days, 13:19, 1 user, load average: 0.54, 0.40, 0.20
- 当前时间 04:03:58
- 系统已运行的时间 10 days, 13:19
- 当前在线用户 1 user
- 平均负载:0.54, 0.40, 0.20,最近1分钟、5分钟、15分钟系统的负载
8、ps 显示进程相关信息的命令
使用举例:ps -ef ps -aux
9、pidstat是sysstat工具的一个命令,用于监控全部或指定进程的cpu、内存、线程、设备IO等系统资源的占用情况。pidstat首次运行时显示自系统启动开始的各项统计信息,之后运行pidstat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
pidstat -u -p ALL查看所有进程的 CPU 使用情况
参数表:
-u:默认的参数,显示各个进程的cpu使用统计 -r:显示各个进程的内存使用统计 -d:显示各个进程的IO使用情况 -p:指定进程号 -w:显示每个进程的上下文切换情况 -t:显示选择任务的线程的统计信息外的额外信息 -T { TASK | CHILD | ALL } 这个选项指定了pidstat监控的。TASK表示报告独立的task,CHILD关键字表示报告进程下所有线程统计信息。ALL表示报告独立的task和task下面的所有线程。 注意:task和子线程的全局的统计信息和pidstat选项无关。这些统计信息不会对应到当前的统计间隔,这些统计信息只有在子线程kill或者完成的时候才会被收集。 -V:版本号 -h:在一行上显示了所有活动,这样其他程序可以容易解析。 -I:在SMP环境,表示任务的CPU使用率/内核数量 -l:显示命令名和所有参数
10、文件类:
显示文件使用空间:du
显示磁盘空间使用情况:df
iotop iostat strace
11、网络类
netstat:显示与IP、TCP、UDP和ICMP协议相关的统计数据,一般用于检验本机各端口的网络连接情况。netstat是在内核中访问网络及相关信息的程序,它能提供TCP连接,TCP和UDP监听,进程内存管理的相关报告。相关链接:https://www.cnblogs.com/ftl1012/p/netstat.html
tcpdump:是一个运行在命令行下的抓包工具。它允许用户拦截和显示发送或收到过网络连接到该计算机的TCP/IP和其他数据包。
相关参数:
-a 将网络地址和广播地址转变成名字; -d 将匹配信息包的代码以人们能够理解的汇编格式给出; -dd 将匹配信息包的代码以c语言程序段的格式给出; -ddd 将匹配信息包的代码以十进制的形式给出; -e 在输出行打印出数据链路层的头部信息,包括源mac和目的mac,以及网络层的协议; -f 将外部的Internet地址以数字的形式打印出来; -l 使标准输出变为缓冲行形式; -n 指定将每个监听到数据包中的域名转换成IP地址后显示,不把网络地址转换成名字; -nn: 指定将每个监听到的数据包中的域名转换成IP、端口从应用名称转换成端口号后显示 -t 在输出的每一行不打印时间戳; -v 输出一个稍微详细的信息,例如在ip包中可以包括ttl和服务类型的信息; -vv 输出详细的报文信息; -c 在收到指定的包的数目后,tcpdump就会停止; -F 从指定的文件中读取表达式,忽略其它的表达式; -i 指定监听的网络接口; -p: 将网卡设置为非混杂模式,不能与host或broadcast一起使用 -r 从指定的文件中读取包(这些包一般通过-w选项产生); -w 直接将包写入文件中,并不分析和打印出来; -s snaplen snaplen表示从一个包中截取的字节数。0表示包不截断,抓完整的数据包。默认的话 tcpdump 只显示部分数据包,默认68字节。 -T 将监听到的包直接解释为指定的类型的报文,常见的类型有rpc (远程过程调用)和snmp(简单网络管理协议;) -X 告诉tcpdump命令,需要把协议头和包内容都原原本本的显示出来(tcpdump会以16进制和ASCII的形式显示)
ping命令用来测试主机之间网络的连通性。
-d:使用Socket的SO_DEBUG功能; -c<完成次数>:设置完成要求回应的次数; -f:极限检测; -i<间隔秒数>:指定收发信息的间隔时间; -I<网络界面>:使用指定的网络界面送出数据包; -l<前置载入>:设置在送出要求信息之前,先行发出的数据包; -n:只输出数值; -p<范本样式>:设置填满数据包的范本样式; -q:不显示指令执行过程,开头和结尾的相关信息除外; -r:忽略普通的Routing Table,直接将数据包送到远端主机上; -R:记录路由过程; -s<数据包大小>:设置数据包的大小; -t<存活数值>:设置存活数值TTL的大小; -v:详细显示指令的执行过程。
12、 iotop监控所有的磁盘和文件系统的磁盘 I/O 统计
iotop -[选项]
--version://显示程序的版本号并退出
-h, --help://显示此帮助消息并退出
-o, --only://仅显示实际执行I / O的进程或线程,只显示在划硬盘的程序
-b, --batch://非交互模式,批量处理 用来记录日志的
-n NUM, --iter=NUM://设定循环几次
-d SEC, --delay=SEC://设定显示时间间隔[秒]
-p PID, --pid=PID://要监控的进程/线程[全部]
-u USER, --user=USER://用户监控[全部]
-P, --processes://只显示进程,而不是所有线程
-a, --accumulated://显示累积的I / O而不是带宽
-k, --kilobytes://使用千字节而不是人性化的单位
-t, --time://在每一行上添加一个时间戳(暗示--batch)
-q, --quiet://抑制一些标题行(暗示--batch)
2 文件的静态链接和动态链接的过程:
动态链接的基本思想是把程序按照模块拆分成各个相对独立部分,在程序运行时才将它们链接在一起形成一个完整的程序,而不是像静态链接一样把所有程序模块都链接成一个单独的可执行文件。
在动态链接过程中,如果Program1调用了lib.o的动态链接文件,而Program2也需要调用lib.o的时候就不会再把lib.o在内存中重新再次加载,而是把已加载的lib映射到program2中。
一个可执行文件的加载过程:./a.out->构建envp和argv->调用fork创建子进程,与父进程shell完全相同(只读/共享)包括只读代码段,用户数据段,堆、用户栈等。调用execve,在子进程->调用execve()在子进程中加载运行程序,将该程序的.text节和.data .bss节等加载到当前进程的虚拟空间中。调用该程序的main函数开始在一个进程上运行。
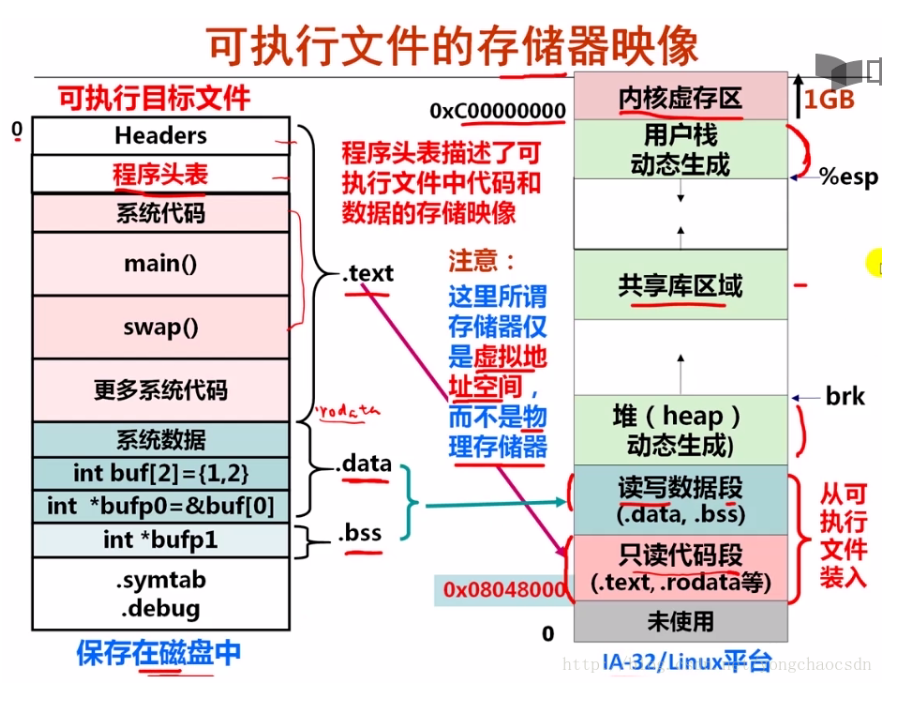

在动态链接有两种方式1:第一次被加载通过动态链接器自动完成:2:在运行时候被加载可以通过调用dlopen函数。
共享库的加载过程是不确定的,在无需修改代码的情况下共享库可以将共享库加载到任意位置并运行。称之为位置无关代码(PIC)。
动态链接的优点显而易见,就是即使需要每个程序都依赖同一个库,但是该库不会像静态链接那样在内存中存在多分,副本,而是这多个程序在执行时共享同一份副本;另一个优点是,更新也比较方便,更新时只需要替换原来的目标文件,而无需将所有的程序再重新链接一遍。当程序下一次运行时,新版本的目标文件会被自动加载到内存并且链接起来,程序就完成了升级的目标。但是动态链接也是有缺点的,因为把链接推迟到了程序运行时,所以每次执行程序都需要进行链接,所以性能会有一定损失。
参考博客:https://blog.csdn.net/yongchaocsdn/article/details/78377843
3 文件的编译原理

一、预处理:
使用-E选项,表示只进行预编译,对应生成一个 .i 文件。
预处理过程进行的操作:
将所有的“#define”删除,并且展开所有的宏定义
处理所有的条件编译指令,比如“#if”、“#ifdef”、“#elif”、“#else”、“#endif”
处理“#include”预编译指令,将被包含的头文件插入到该编译指令的位置。(这个过程是递归进行的,因为被包含的文件可能还包含了其他文件)
删除所有的注释“//”和“/* */”。
添加行号和文件名标识,方便后边编译时编译器产生调试用的行号心意以及编译时产生编译错误或警告时能够显示行号。
保留所有的#pragma编译指令,因为编译器需要使用它们。
使用一个简单的程序来验证一下事实是否如上述所说的一样
编写一个简单的程序,然后使用-E选项执行预处理过程,打开生成的 .i 文件与源文件进行比对,结果一目了然
对于给代码加上行号这个就不在这里演示了,我们在写代码的时候是不会手动添加行号的,我们看到的行号都是自己使用的编辑工具自动加上的,而这些行号编译系统是看不到的,但是呢,我们发现如果我们哪一行的代码出现了问题,编译的时候就会给出提示说哪行的代码有什么问题,这就已经证明,编译器是会自动添加行号的。
二、编译:
使用-S选项,表示编译操作执行完就结束。对应生成一个 .s 文件。
编译过程是整个程序构建的核心部分,编译成功,会将源代码由文本形式转换成机器语言,编译过程就是把预处理完的文件进行一系列词法分析、语法分析、语义分析以及优化后生成相应的汇编代码文件。
词法分析:
词法分析是使用一种叫做lex的程序实现词法扫描,它会按照用户之前描述好的词法规则将输入的字符串分割成一个个记号。产生的记号一般分为:关键字、标识符、字面量(包含数字、字符串等)和特殊符号(运算符、等号等),然后他们放到对应的表中。
语法分析:语法分析器根据用户给定的语法规则,将词法分析产生的记号序列进行解析,然后将它们构成一棵语法树。对于不同的语言,只是其语法规则不一样。用于语法分析也有一个现成的工具,叫做:yacc。
语义分析:
语法分析完成了对表达式语法层面的分析,但是它不了解这个语句是否真正有意义。有的语句在语法上是合法的,但是却是没有实际的意义,比如说两个指针的做乘法运算,这个时候就需要进行语义分析,但是编译器能分析的语义也只有静态语义。
静态语义:在编译期就可以确定的语义。通常包括声明与类型的匹配、类型的转换。比如当一个浮点型的表达式赋值给一个整型的表达式时,其中隐含一个从浮点型到整型的转换,而语义分析就需要完成这个转换,再比如,将一个浮点型的表达式赋值给一个指针,这肯定是不行的,语义分析的时候就会发现两者类型不匹配,编译器就会报错。
动态语义:只有在运行期才能确定的语义。比如说两个整数做除法,语法上没问题,类型也匹配,听着好像没毛病,但是,如果除数是0的话,这就有问题了,而这个问题事先是不知道的,只有在运行的时候才能发现他是有问题的,这就是动态语义。
中间代码生成
我们的代码是可以进行优化的,对于一些在编译期间就能确定的值,是会将它进行优化的,比如说上边例子中的 2+6,在编译期间就可以确定他的值为8了,但是直接在语法上进行优化的话比较困难,这时优化器会先将语法树转成中间代码。中间代码一般与目标机器和运行环境无关。(不包含数据的尺寸、变量地址和寄存器的名字等)。中间代码在不同的编译器中有着不同的形式,比较常见的有三地址码和P-代码。
中间代码使得编译器可以分为前端和后端。编译器前端负责产生于机器无关的中间代码,编译器后端将中间代码换成机器代码。
目标代码生成与优化
代码生成器将中间代码转成机器代码,这个过程是依赖于目标机器的,因为不同的机器有着不同的字长、寄存器、数据类型等。
最后目标代码优化器对目标代码进行优化,比如选择合适的寻址方式、使用唯一来代替乘除法、删除出多余的指令等。
三、汇编
汇编过程调用汇编器as来完成,是用于将汇编代码转换成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。
使用命令as hello.s -o hello.o 或者使用gcc -c hello.s -o hello.o来执行到汇编过程结束,对应生成的文件是.o文件。
四、链接
链接的主要内容就是将各个模块之间相互引用的部分正确的衔接起来。它的工作就是把一些指令对其他符号地址的引用加以修正。链接过程主要包括了地址和空间分配、符号决议和重定向
符号决议:有时候也被叫做符号绑定、名称绑定、名称决议、或者地址绑定,其实就是指用符号来去标识一个地址。
比如说 int a = 6;这样一句代码,用a来标识一个块4个字节大小的空间,空间里边存放的内容就是4.
重定位:重新计算各个目标的地址过程叫做重定位。
最基本的链接叫做静态链接,就是将每个模块的源代码文件编译成目标文件(Linux:.o Windows:.obj),然后将目标文件和库一起链接形成最后的可执行文件。库其实就是一组目标文件的包,就是一些最常用的代码变异成目标文件后打包存放。最常见的库就是运行时库,它是支持程序运行的基本函数的集合。
4 cs模型和bs模型等编程模型
C/S结构,即Client/Server(客户机/服务器)结构,是大家熟知的软件系统体系结构,通过将任务合理分配到Client端和Server端,降低了系统的通讯开销,可以充分利用两端硬件环境的优势。早期的软件系统多以此作为首选设计标准。
(用的是ip,tcp/udp通信协议)
B/S结构,即Browser/Server(浏览器/服务器)结构,是随着Internet技术的兴起,对C/S结构的一种变化或者改进的结构。在这种结构下,用户界面完全通过WWW浏览器实现,一部分事务逻辑在前端实现,但是主要事务逻辑在服务器端实现,形成所谓3-tier结构。 (采用的是上层的http或者https通信协议)
B/S结构,主要是利用了不断成熟的WWW浏览器技术,结合浏览器的多种scrīpt语言(VBscrīpt、Javascrīpt…)和ActiveX技术,用通用浏览器就实现了原来需要复杂专用软件才能实现的强大功能,并节约了开发成本,是一种全新的软件系统构造技术。随着Windows 98/Windows 2000将浏览器技术植入操作系统内部,这种结构更成为当今应用软件的首选体系结构。
C/S 与 B/S 区别:
Client/Server是建立在局域网的基础上的.Browser/Server是建立在广域网的基础上的.
1.硬件环境不同
C/S 一般建立在专用的网络上, 小范围里的网络环境, 局域网之间再通过专门服务器提供连接和数据交换服务.
B/S 建立在广域网之上的, 不必是专门的网络硬件环境,例如电话上网, 租用设备. 信息管理. 有比C/S更强的适应范围, 一般只要有操作系统和浏览器就行
2.对安全要求不同
C/S 一般面向相对固定的用户群, 对信息安全的控制能力很强. 一般高度机密的信息系统采用C/S 结构适宜. 可以通过B/S发布部分可公开信息.
B/S 建立在广域网之上, 对安全的控制能力相对弱, 面向是不可知的用户群.
3.对程序架构不同
C/S 程序可以更加注重流程, 可以对权限多层次校验, 对系统运行速度可以较少考虑.
B/S 对安全以及访问速度的多重的考虑, 建立在需要更加优化的基础之上. 比C/S有更高的要求 B/S结构的程序架构是发展的趋势, 从MS的.Net系列的BizTalk 2000 Exchange 2000等, 全面支持网络的构件搭建的系统. SUN 和IBM推的JavaBean 构件技术等,使 B/S更加成熟.
4.软件重用不同
C/S 程序可以不可避免的整体性考虑, 构件的重用性不如在B/S要求下的构件的重用性好.
B/S 对的多重结构,要求构件相对独立的功能. 能够相对较好的重用.
5.系统维护不同
系统维护在是软件生存周期中,开销大, -------重要
C/S 程序由于整体性, 必须整体考察, 处理出现的问题以及系统升级. 升级难. 可能是再做一个全新的系统
B/S 构件组成,方面构件个别的更换,实现系统的无缝升级. 系统维护开销减到最小.用户从网上自己下载安装就可以实现升级.
6.处理问题不同
C/S 程序可以处理用户面固定, 并且在相同区域, 安全要求高需求, 与操作系统相关. 应该都是相同的系统
B/S 建立在广域网上, 面向不同的用户群, 分散地域, 这是C/S无法作到的. 与操作系统平台关系最小.
7.用户接口不同
C/S 多是建立的Window平台上,表现方法有限,对程序员普遍要求较高
B/S 建立在浏览器上, 有更加丰富和生动的表现方式与用户交流. 并且大部分难度减低,减低开发成本.
8.信息流不同
C/S 程序一般是典型的中央集权的机械式处理, 交互性相对低
B/S 信息流向可变化, B-B B-C B-G等信息、流向的变化, 更象交易中心
5 C++11的新标准特性
-std=c++11
1:nullptr
nullptr 出现的目的是为了替代 NULL。
在某种意义上来说,传统 C++ 会把 NULL、0 视为同一种东西,这取决于编译器如何定义 NULL,有些编译器会将 NULL 定义为 ((void*)0),有些则会直接将其定义为 0。
C++ 不允许直接将 void * 隐式转换到其他类型,但如果 NULL 被定义为 ((void*)0),那么当编译char *ch = NULL;时,NULL 只好被定义为 0。
为了解决这个问题,C++11 引入了 nullptr 关键字,专门用来区分空指针、0。
2:推导类型:
C++11 引入了 auto 和 decltype 这两个关键字实现了类型推导,让编译器来操心变量的类型。
auto 不能用于函数传参,还不能用于推导数组类型
3:基于for循环的区间迭代
例如对arr从开始到结束的遍历可以写成
for(auto &i : arr);
4:提供了统一的语法来初始化任意的对象
struct A { int a; float b; }; struct B { B(int _a, float _b): a(_a), b(_b) {} private: int a; float b; }; A a {1, 1.1}; // 统一的初始化语法 B b {2, 2.2};
5:构造函数
委托构造:
C++11 引入了委托构造的概念,这使得构造函数可以在同一个类中一个构造函数调用另一个构造函数,从而达到简化代码的目的:
class Base { public: int value1; int value2; Base() { value1 = 1; } Base(int value) : Base() { // 委托 Base() 构造函数 value2 = 2; } };
继承构造
在继承体系中,如果派生类想要使用基类的构造函数,需要在构造函数中显式声明。
假若基类拥有为数众多的不同版本的构造函数,这样,在派生类中得写很多对应的“透传”构造函数。如下:
struct A { A(int i) {} A(double d,int i){} A(float f,int i,const char* c){} //...等等系列的构造函数版本 }; struct B:A { B(int i):A(i){} B(double d,int i):A(d,i){} B(folat f,int i,const char* c):A(f,i,e){} //......等等好多个和基类构造函数对应的构造函数
};
struct A { A(int i) {} A(double d,int i){} A(float f,int i,const char* c){} //...等等系列的构造函数版本 }; struct B:A { using A::A; //关于基类各构造函数的继承一句话搞定 //...... };//c++11标准
6:原子类型实现多线程的同步的三种方法
// 使用CAS实现多线程无锁访问共享变量,达到线程同步 # include <iostream> # include <thread> # include <mutex> # include <atomic> using namespace std; std::atomic<int> var(0); void add() { int expect = var; while (!atomic_compare_exchange_weak(&var, &expect, var + 1)); } int main(int argc, char *argv[]) { int count = 2000; std::thread threads[count]; for (int i = 0; i < count; ++i) threads[i] = std::thread(add); for (int i = 0; i < count; ++i) threads[i].join(); cout << var << endl; // var 为 2000,无误!! return 0; }
// 使用原子数据类型的原子方法操作,达到同步线程 # include <iostream> # include <thread> # include <mutex> # include <atomic> using namespace std; std::atomic<int> var(0); void add() { var.fetch_add(1); // cout << std::boolalpha ; // cout << "is_lock_free:" << var.is_lock_free() << endl; // true } int main(int argc, char *argv[]) { int count = 2000; std::thread threads[count]; // default-constructed threads for (int i = 0; i < count; ++i) threads[i] = std::thread(add); for (int i = 0; i < count; ++i) threads[i].join(); cout << var << endl; return 0; }
// 使用RAII的mutex,同步线程 # include <iostream> # include <thread> # include <mutex> # include <atomic> using namespace std; std::mutex mtx; void add(int *var) { std::lock_guard<std::mutex> l(mtx); (*var)++; } int main(int argc, char *argv[]) { int count = 2000; std::thread threads[count]; // default-constructed threads int *var = new int [1]; for (int i = 0; i < count; ++i) threads[i] = std::thread(add, var); for (int i = 0; i < count; ++i) threads[i].join(); cout << *var << endl; return 0; }
参考博客:https://blog.csdn.net/jiange_zh/article/details/79356417
6 epoll的内部实现 双向arry+红黑树?
首先分析epoll的数据结构:
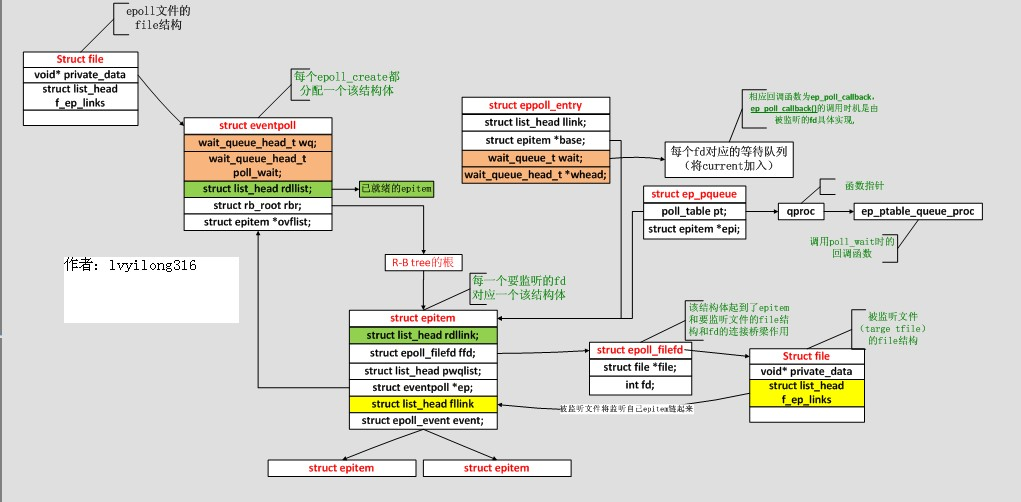
对于epoll整个过程大概如下:
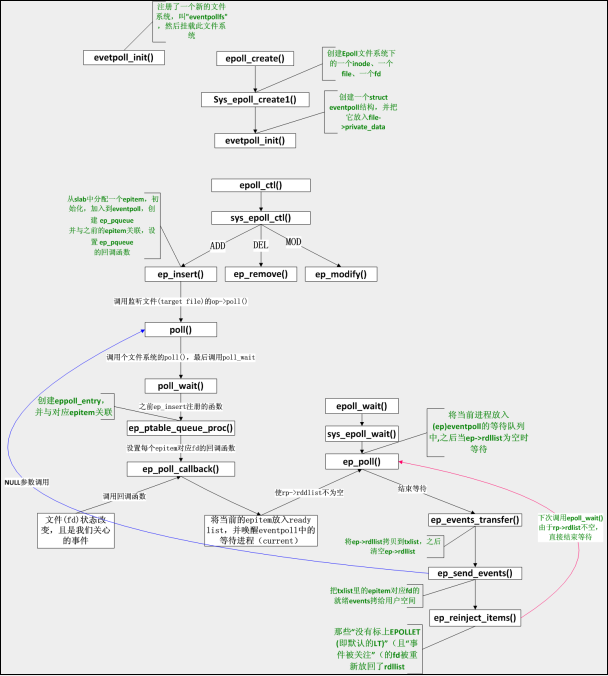
接下来根据图来说明一下epoll的流程
在初始化阶段,要在内存中申请两个类似于内存池的结构,存放ep item和epollentry,接下来在create的时候创建一个node file和fd 创建event_poll 并且把得到的fd保存在数据结构为rbtree root为根节点的红黑树中。create中返回的fd是event_pollfs中创建的。进而开始执行Ctrl功能epoll_ctl() 它根据用户的不同操作分为insert remove modify三种模式。在insert被调用的时候调用监听文件,在调用注册函数poll_wait queue_proc()设置fd对应的回调函数。等待被callback唤醒。当被调用回调函数的时候,fd的状态发生改变,同时吧fd放入就绪队列ready_list中,唤醒event_poll中的current。对epoll_wait函数而言,当readylist为空的时候等待,当有进程把fd放入eventpoll以后结束等待,把rdlist拷贝到tx_list后清空,tx_list会吧对应的fd拷贝到用户空间,类似于进行send 同时把因为没有收发操作的fd不放回只把进行了标记的fd再放回ready_list里继续等待下次被拷贝发送。
相比而言poll的系统调用,操作系统都要把current(当前进程)挂到fd对应的所有设备的等待队列上,可以想象,fd多到上千的时候,这样“挂”法很费事;而每次调用epoll_wait则没有这么罗嗦,epoll只在epoll_ctl时把current挂一遍(这第一遍是免不了的)并给每个fd一个命令“好了就调回调函数”,如果设备有事件了,通过回调函数,会把fd放入rdllist,而每次调用epoll_wait就只是收集rdllist里的fd就可以了——epoll巧妙的利用回调函数,实现了更高效的事件驱动模型。
7 线程的资源 存放在哪里 栈指针?
线程之间 共享的资源有:
8 c++父类如何调用子类?
dynamic_cast将一个基类对象指针(或引用)cast到继承类指针,dynamic_cast会根据基类指针是否真正指向继承类指针来做相应处理, 即会作出一定的判断。
若对指针进行dynamic_cast,失败返回null,成功返回正常cast后的对象指针;
若对引用进行dynamic_cast,失败抛出一个异常,成功返回正常cast后的对象引用。
RTTI info 存在于虚表的第一项。因为RTTI 依赖于虚表,所以用dynamic_cast 对应的类一定要有虚函数。
9: 静态运算符重载是怎么实现的
多态函数最终会加上他的参数类型,比如func_int_float这种。函数存放在栈里面。首先词法分析,肯定不会有涉及对多态的动作。语法分析可能会优化这个函数,也有可能是在编译期间。所以是在形成.i文件或者是.s文件的时候对多态有动作了。然后在.o文件转成汇编的过程中,针对不同的多态函数安排不同的地址。
举个栗子:
该程序在编译后的结果:

可以看见在这里已经发生了改变。
10 new和malloc的区别
(1)malloc和new都是在堆上开辟内存的
malloc只负责开辟内存,没有初始化功能,需要用户自己初始化;new不但开辟内存,还可以进行初始化,如new int(10);表示在堆上开辟了一个4字节的int整形内存,初始值是10,再如new int[10] ();表示在堆上开辟了一个包含10个整形元素的数组,初始值都为0。
(2)malloc是函数,开辟内存需要传入字节数,如malloc(100);表示在堆上开辟了100个字节的内存,返回void*,表示分配的堆内存的起始地址,因此malloc的返回值需要强转成指定类型的地址;new是运算符,开辟内存需要指定类型,返回指定类型的地址,因此不需要进行强转。
(3)malloc开辟内存失败返回NULL,new开辟内存失败抛出bad_alloc类型的异常,需要捕获异常才能判断内存开辟成功或失败,new运算符其实是operator new函数的调用,它底层调用的也是malloc来开辟内存的,new它比malloc多的就是初始化功能,对于类类型来说,所谓初始化,就是调用相应的构造函数。
(4)malloc开辟的内存永远是通过free来释放的;而new单个元素内存,用的是delete,如果new[]数组,用的是delete[]来释放内存的。
(5)malloc开辟内存只有一种方式,而new有四种分别是普通的new(内存开辟失败抛出bad_alloc异常), nothrow版本的new,const new以及定位new。
特别的memcpy等,realloc函数不能在C++中简单使用,因为这些函数进行的都是内存值拷贝(也就是对象的浅拷贝),会发生浅拷贝这个严重的问题!
11文件锁 线程锁 进程锁 都有哪些?
> 线程锁/进程锁/文件锁
1.线程锁是锁线程的,锁住禁用,如果4线程的CPU锁一个线程剩余三个(如果可以锁的话),就像四车道封锁一条车道还剩3个车道可以跑车;
2.进程锁是锁进程的,进程就是正在运行的程序,锁住进程就是锁住程序禁止程序的任何操作,就像锁住汽车不能开车一样。
3.文件锁是锁文件的,文件锁住就无法使用,必须解锁才可以使用。
通过对文件上锁,只有拥有锁的进程才能拥有对应锁权限的操作权限。而没有锁的进程只能挂起或者处理其他的事务直到拥有锁。从而在并发的场景下,我们才能对文件的读写进行控制。获取的文件锁是进程之间的锁。
-- lock()和tryLock()的区别:
lock()方法当无法获得锁时会阻塞。是阻塞式的,它要阻塞进程直到锁可以获得,或调用lock()的线程中继,或调用lock()的通道关闭
对独占锁和共享锁的支持必须由底层的操作系统提供。锁的类型可以通过FileLock.isShared()进行查询,我们不能获取缓冲器上的锁,只能是通道上的。
tryLock()方法当无法获得锁时会获得null值。是非阻塞式的,它设法获取锁,但如果不能获得,例如因为其他一些进程已经持有相同的锁,而且不共享时,它将直接从方法调用返回。
虽然常规都是使用new RandomAccessFile(file,”rw”).getChannel().lock();获得锁。但是如果使用new FileInputStream(file).getChannel().lock();获得锁时。会抛出NonWritableChannelException异常。
如果使用new FileOutputStream(file).getChannel().lock()时,会先将原文件的内容清空,因此最好使用new FileOutputStream(file,true).getChannel().lock()。
> 共享锁和独占锁区别
1.独占锁:也称排它锁,如果一个线程获得一个文件的独占锁,那么其它线程就不能再获得同一文件的独占锁或共享锁,直到独占锁被释放;当a.txt文件被加独占锁时 其它线程不可读也不可写;
2.共享锁:如果一个线程获得一个文件的共享锁,那么其它线程可以获得同一文件的共享锁或同一文件部分内容的共享锁,但不能获取排它锁;当a.txt文件被加共享锁时 其它线程可读但不可写;
如何获得共享锁fc.tryLock(position,size,isShare);第三个参数为true时,为共享锁。
volatile只保证可见性,不保证原子性!
线程之间的锁有:互斥锁、条件锁、自旋锁、读写锁、递归锁。一般而言,锁的功能越强大,性能就会越低。
1、互斥锁
互斥锁用于控制多个线程对他们之间共享资源互斥访问的一个信号量。也就是说是为了避免多个线程在某一时刻同时操作一个共享资源。例如线程池中的有多个空闲线程和一个任务队列。任何是一个线程都要使用互斥锁互斥访问任务队列,以避免多个线程同时访问任务队列以发生错乱。
在某一时刻,只有一个线程可以获取互斥锁,在释放互斥锁之前其他线程都不能获取该互斥锁。如果其他线程想要获取这个互斥锁,那么这个线程只能以阻塞方式进行等待。
2、条件锁
条件锁就是所谓的条件变量,某一个线程因为某个条件为满足时可以使用条件变量使改程序处于阻塞状态。一旦条件满足以“信号量”的方式唤醒一个因为该条件而被阻塞的线程。最为常见就是在线程池中,起初没有任务时任务队列为空,此时线程池中的线程因为“任务队列为空”这个条件处于阻塞状态。一旦有任务进来,就会以信号量的方式唤醒一个线程来处理这个任务。这个过程中就使用到了条件变量pthread_cond_t。
3、自旋锁
如果T1正在使用自旋锁,而T2也去申请这个自旋锁,此时T2肯定得不到这个自旋锁。与互斥锁相反的是,此时运行T2的处理器core2会一直不断地循环检查锁是否可用(自旋锁请求),直到获取到这个自旋锁为止。
从“自旋锁”的名字也可以看出来,如果一个线程想要获取一个被使用的自旋锁,那么它会一致占用CPU请求这个自旋锁使得CPU不能去做其他的事情,直到获取这个锁为止,这就是“自旋”的含义。
当发生阻塞时,互斥锁可以让CPU去处理其他的任务;而自旋锁让CPU一直不断循环请求获取这个锁。通过两个含义的对比可以我们知道“自旋锁”是比较耗费CPU的。
4、读写锁
说到读写锁我们可以借助于“读者-写者”问题进行理解。首先我们简单说下“读者-写者”问题。
计算机中某些数据被多个进程共享,对数据库的操作有两种:一种是读操作,就是从数据库中读取数据不会修改数据库中内容;另一种就是写操作,写操作会修改数据库中存放的数据。因此可以得到我们允许在数据库上同时执行多个“读”操作,但是某一时刻只能在数据库上有一个“写”操作来更新数据。这就是一个简单的读者-写者模型。
分布式锁:当多个进程不在同一个系统之中时,使用分布式锁控制多个进程对资源的访问。
intsmaze说简单点,实现分布式锁必须要依靠第三方存储介质来存储锁的元数据等信息。比如分布式集群要操作某一行数据时,这个数据的流水号是唯一的,那么我们就把这个流水号作为一把锁的id,当某进程要操作该数据时,先去第三方存储介质中看该锁id是否存在,如果不存在,则将该锁id写入,然后执对该数据的操作;当其他进程要访问这个数据时,会先到第三方存储介质中查看有没有这个数据的锁id,有的话就认为这行数据目前已经有其他进程在使用了,就会不断地轮询第三方存储介质看其他进程是否释放掉该锁;当进程操作完该数据后,该进程就到第三方存储介质中把该锁id删除掉,这样其他轮询的进程就能得到对该锁的控制。
最后进程锁lock和文件锁flock
在默认情况下,文件锁是劝告式的,这表示一个进程可以简单地忽略另一个进程在文件上放置的锁。要使得劝告式加锁模型能够正常工作,所有访问文件的进程都必须要配合,即在执行文件IO之前先放置一把锁。
flock主要三种操作类型:
LOCK_SH,共享锁,多个进程可以使用同一把锁,常被用作读共享锁;
LOCK_EX,排他锁,同时只允许一个进程使用,常被用作写锁;
LOCK_UN,释放锁;
12日志文件的切割
日志文件按天切割脚本:
#!/bin/bash #此脚本用于自动分割Nginx的日志,包括access.log和error.log #每天00:00执行此脚本 将前一天的access.log重命名为access-xxxx-xx-xx.log格式,并重新打开日志文件 #Nginx日志文件所在目录 LOG_PATH=/opt/nginx/logs #获取昨天的日期 YESTERDAY=$(date -d "yesterday" +%Y-%m-%d) #获取pid文件路径 PID=/var/run/nginx/nginx.pid #分割日志 mv ${LOG_PATH}access.log ${LOG_PATH}access-${YESTERDAY}.log mv ${LOG_PATH}error.log ${LOG_PATH}error-${YESTERDAY}.log #向Nginx主进程发送USR1信号,重新打开日志文件 kill -USR1 `cat ${PID}`
13 fork的读时共享,写时复制
fork的运行过程
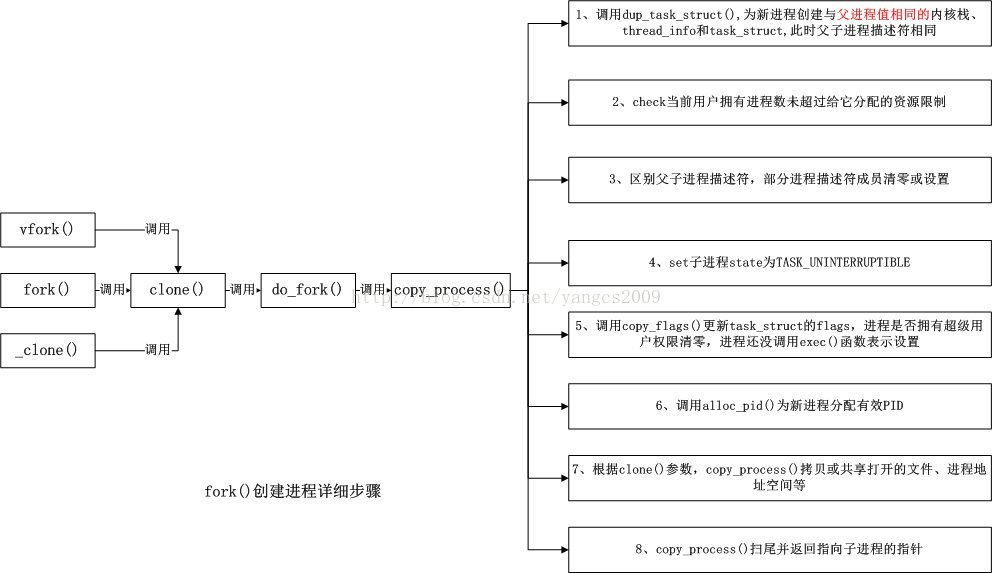
当发出fork( )系统调用时,内核原样复制父进程的整个地址空间并把复制的那一份分配给子进程。这种行为是非常耗时的,因为它需要:
· 为子进程的页表分配页面
· 为子进程的页分配页面
· 初始化子进程的页表
· 把父进程的页复制到子进程相应的页中
cow的思想:父进程和子进程共享页面而不是复制 页面。然而,只要页面被共享,它们就不能被修改。无论父进程和子进程何时试图写一个共享的页面,就产生一个错误,这时内核就把这个页复制到一个新的页面中 并标记为可写。原来的页面仍然是写保护的:当其它进程试图写入时,内核检查写进程是否是这个页面的唯一属主;如果是,它把这个页面标记为对这个进程是可写的。
1. 现在P1用fork()函数为进程创建一个子进程P2,
内核:
(1)复制P1的正文段,数据段,堆,栈这四个部分,注意是其内容相同。
(2)为这四个部分分配物理块,P2的:正文段->PI的正文段的物理块,其实就是不为P2分配正文段块,让P2的正文段指向P1的正文段块,数据 段->P2自己的数据段块(为其分配对应的块),堆->P2自己的堆块,栈->P2自己的栈块。如下图所示:同左到右大的方向箭头表示复制内容。

2.写时复制技术:内核只为新生成的子进程创建虚拟空间结构,它们来复制于父进程的虚拟究竟结构,但是不为这些段分配物理内存,它们共享父进程的物理空间,当父子进程中有更改相应段的行为发生时,再为子进程相应的段分配物理空间。
14 malloc原理
它有一个将可用的内存块连接为一个长长的列表的所谓空暇链表。调用malloc函数时,它沿连接表寻找一个大到足以满足 用户请求所须要的内存块。然后,将该内存块一分为二(一块的大小与用户请求的大小相等,还有一块的大小就是剩下的字节)。接下来,将分配给用户的那块内存传 给用户,并将剩下的那块(假设有的话)返回到连接表上。调用free函数时,它将用户释放的内存块连接到空暇链上。到最后,空暇链会被切成非常多的小内存片 段,假设这时用户申请一个大的内存片段,那么空暇链上可能没有能够满足用户要求的片段了。于是,malloc函数请求延时,并開始在空暇链上翻箱倒柜地检 查各内存片段,对它们进行整理,将相邻的小空暇块合并成较大的内存块。
15 负载均衡算法
轮询
比如A服务器的权重是5,B服务器的权重是1,C服务器的权重是1。
这个权重,我们称之为“固定权重”,既然这个叫“固定权重”,那么肯定还有叫“非固定权重的”,没错,“非固定权重”每次都会根据一定的规则变动。
- 第一次访问,ABC的“非固定权重”分别是 5 1 1(初始),因为5是其中最大的,5对应的就是A服务器,所以这次选到的服务器就是A,然后我们用当前被选中的服务器的权重-各个服务器的权重之和,也就是A服务器的权重-各个服务器的权重之和。也就是5-7=-2,没被选中的服务器的“非固定权重”不做变化,现在三台服务器的“非固定权重”分别是-2 1 1。
- 第二次访问,把第一次访问最后得到的“非固定权重”+“固定权重”,现在三台服务器的“非固定权重”是3,2,2,因为3是其中最大的,3对应的就是A服务器,所以这次选到的服务器就是A,然后我们用当前被选中的服务器的权重-各个服务器的权重之和,也就是A服务器的权重-各个服务器的权重之和。也就是3-7=-4,没被选中的服务器的“非固定权重”不做变化,现在三台服务器的“非固定权重”分别是-4 1 1。
- 第三次访问,把第二次访问最后得到的“非固定权重”+“固定权重”,现在三台服务器的“非固定权重”是1,3,3,这个时候3虽然是最大的,但是却出现了两个,我们选第一个,第一个3对应的就是B服务器,所以这次选到的服务器就是B,然后我们用当前被选中的服务器的权重-各个服务器的权重之和,也就是B服务器的权重-各个服务器的权重之和。也就是3-7=-4,没被选中的服务器的“非固定权重”不做变化,现在三台服务器的“非固定权重”分别是1 -4 3。
...
以此类推,最终得到这样的表格:
| 请求 | 获得服务器前的非固定权重 | 选中的服务器 | 获得服务器后的非固定权重 |
|---|---|---|---|
| 1 | {5, 1, 1} | A | {-2, 1, 1} |
| 2 | {3, 2, 2} | A | {-4, 2, 2} |
| 3 | {1, 3, 3} | B | {1, -4, 3} |
| 4 | {6, -3, 4} | A | {-1, -3, 4} |
| 5 | {4, -2, 5} | C | {4, -2, -2} |
| 6 | {9, -1, -1} | A | {2, -1, -1} |
| 7 | {7, 0, 0} | A | {0, 0, 0} |
| 8 | {5, 1, 1} | A | {-2, 1, 1} |
哈希
负载均衡算法中的哈希算法,就是根据某个值生成一个哈希值,然后对应到某台服务器上去,当然可以根据用户,也可以根据请求参数,或者根据其他,想怎么来就怎么来。如果根据用户,就比较巧妙的解决了负载均衡下Session共享的问题,用户小明走的永远是A服务器,用户小笨永远走的是B服务器。
那么如何用代码实现呢,这里又需要引出一个新的概念:哈希环。
什么?我只听过奥运五环,还有“啊 五环 你比四环多一环,啊 五环 你比六环少一环”,这个哈希环又是什么鬼?容我慢慢道来。
哈希环,就是一个环!这...好像...有点难解释呀,我们还是画图来说明把。
一个圆是由无数个点组成的,这是最简单的数学知识,相信大家都可以理解吧,哈希环也一样,哈希环也是有无数个“哈希点”构成的,当然并没有“哈希点”这样的说法,只是为了便于大家理解。
我们先计算出服务器的哈希值,比如根据IP,然后把这个哈希值放到环里,如上图所示。
来了一个请求,我们再根据某个值进行哈希,如果计算出来的哈希值落到了A和B的中间,那么按照顺时针算法,这个请求给B服务器。
理想很丰满,现实很孤单,可能三台服务器掌管的“区域”大小相差很大很大,或者干脆其中一台服务器坏了,会出现如下的情况:
可以看出,A掌管的“区域”实在是太大,B可以说是“很悠闲,喝着咖啡,看着电影”,像这种情况,就叫“哈希倾斜”。
那么怎么避免这种情况呢?虚拟节点。
什么是虚拟节点呢,说白了,就是虚拟的节点...好像..没解释啊...还是上一张丑到爆炸的图吧:
其中,正方形的是真实的节点,或者说真实的服务器,五边形的是虚拟节点,或者说是虚拟的服务器,当一个请求过来,落到了A1和B1之间,那么按照顺时针的规则,应该由B1服务器进行处理,但是B1服务器是虚拟的,它是从B服务器映射出来的,所以再交给B服务器进行处理。
posted on 2020-03-10 11:14 KID_XiaoYuan 阅读(264) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号