Python | California房价的回归分析
一、选题背景:
《Hands-On Machine Learning with Scikit-Learn & TensorFlow》第二章名叫End-to-End Machine Learning Project。这章的任务是利用加州普查数据,建立一个加州房价模型。这个数据包含每个街区组的人口、收入中位数、房价中位数等指标,利用给出的指标进行学习,预测任何街区的的房价中位数。这个模型的输出将再输入到一个投资分析系统,投资分析系统会根据这个数据以及别的数据判断是否值得投资这一地区。
二、数据说明:
数据来源于Kaggle,Kaggle是由联合创始人、首席执行官安东尼·高德布卢姆(Anthony Goldbloom)2010年在墨尔本创立的,主要为开发商和数据科学家提供举办机器学习竞赛、托管数据库、编写和分享代码的平台。该平台已经吸引了80万名数据科学家的关注,这些用户资源或许正是吸引谷歌的主要因素。
三、实施过程及代码:
导入Kaggle提供的数据:
1 ### 导入Kaggle提供的数据 2 df=pd.read_csv(r'housing.csv') 3 df.head()

分析原始数据:
1 # #先分析原始数据 2 df.info()

1 df['ocean_proximity'].value_counts()

1 df.isnull().sum()

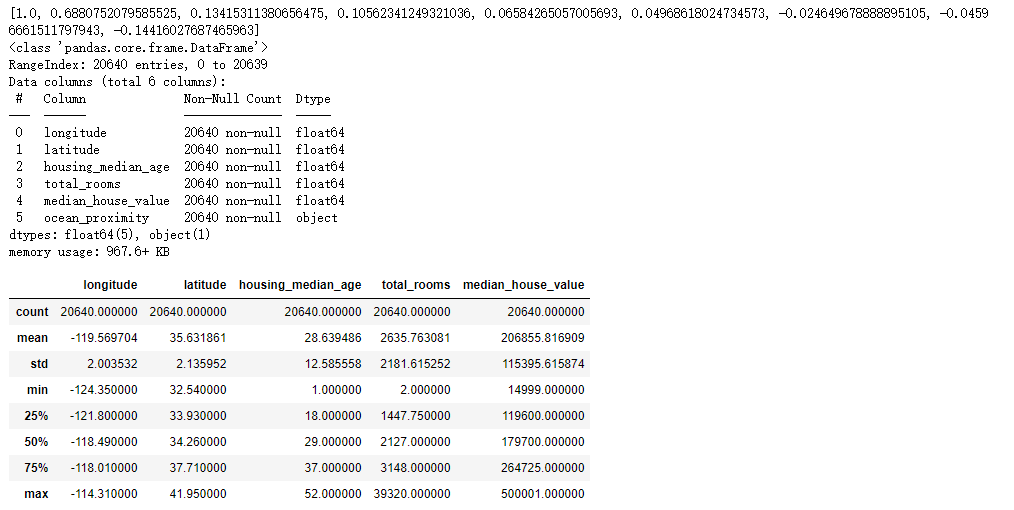
1 df.describe() 2 # 查看第一列数据是不是索引项 3 df["longitude"]

1 #对于重复值进行查询,并且做出处理 2 df4 = df.copy() 3 df[df.duplicated()].count()

1 # 对median_house_value这里面如果有空的数值进行删除,因为为空数值无意义 2 df4.dropna(axis=0,subset = ["median_house_value"],inplace=True) 3 df4.head(10),df.shape
1 df.hist(bins=50,figsize=(20,15)) 2 plt.show()
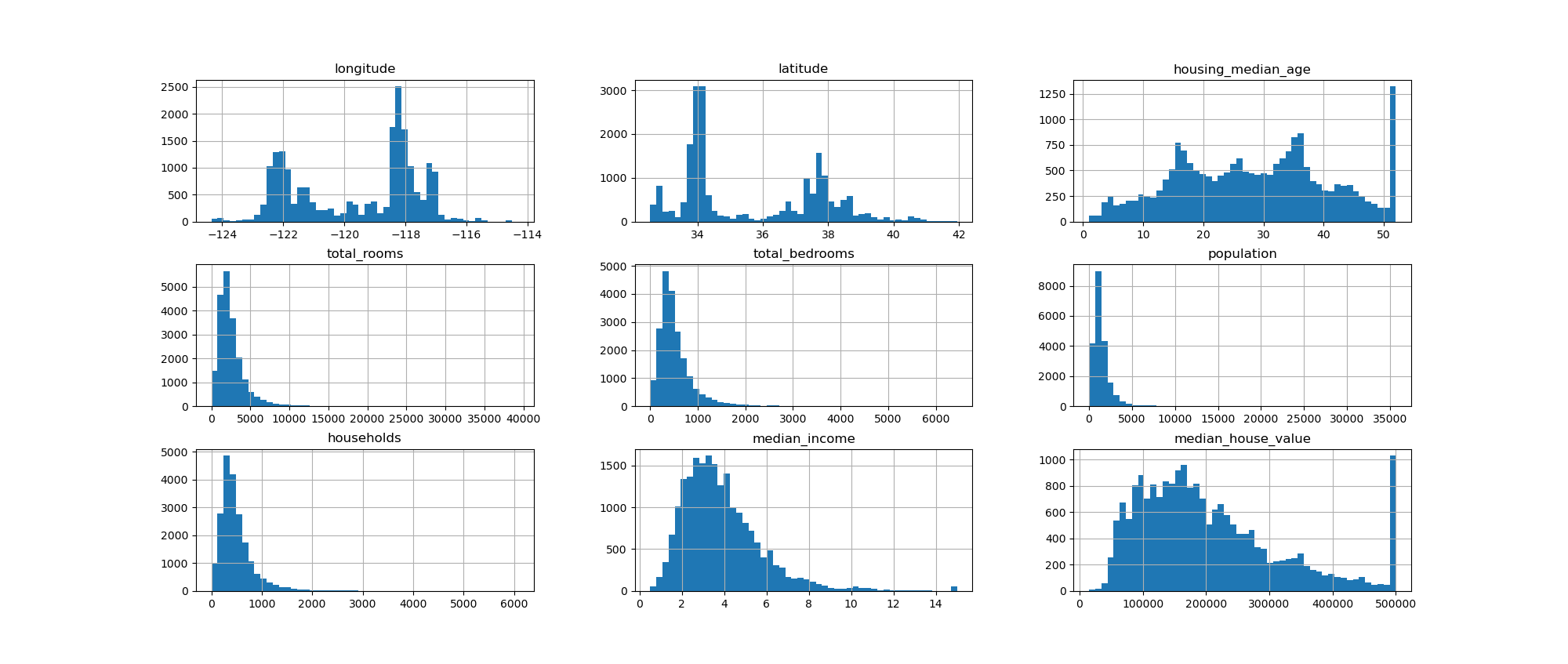
1 df.plot(kind='scatter',x='longitude',y='latitude',alpha=0.4,s=df['population']/100,label='population',figsize=(10,7), 2 c='median_house_value',cmap=plt.get_cmap('jet'),colorbar=True) 3 plt.legend() 4 plt.show()

看一下各变量与房价的相关系数:
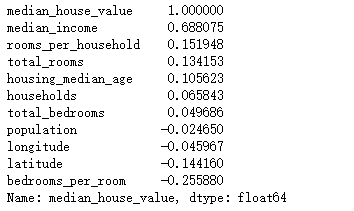
1 ### 看一下各变量与房价的相关系数 2 df1 = df.copy() 3 del df1['longitude'] 4 corr=df1.corr() 5 socre = corr['median_house_value'].sort_values(ascending=False) 6 print(socre)

1 # 我们对其中某一变量进行删除观察其余变量与房价之间的相关系数 2 df2 = df.copy() 3 list_name = ["longitude","latitude","housing_median_age","total_rooms"] 4 for i in list_name: 5 del df2[i] 6 corr=df2.corr() 7 socre = corr['median_house_value'].sort_values(ascending=False) 8 print(socre)

1 # 当我们对数据改变之后,我们对数据进行初步分析 2 df2.info() 3 df2['ocean_proximity'].value_counts() 4 df2.isnull().sum() 5 df2.duplicated().sum() 6 df2.describe()

1 # 观察后面几个变量对房价的影响关系 2 list_name2 =["total_bedrooms","population","households","median_income"] 3 df3 = df.copy() 4 for i in list_name2: 5 del df3[i] 6 corr=df3.corr() 7 socre = corr['median_house_value'].sort_values(ascending=False) 8 print(socre)

1 bijiao_zong = [] 2 df = df.copy() 3 corr=df.corr() 4 socre = corr['median_house_value'].sort_values(ascending=False) 5 for u in socre: 6 bijiao_zong.append(u) 7 print(bijiao_zong) 8 # 当我们对数据改变之后,我们对数据进行初步分析 9 df3.info() 10 df3['ocean_proximity'].value_counts() 11 df3.isnull().sum() 12 df3.duplicated().sum() 13 df3.describe()
1 #插入一些有用的变量 (比如:每间客房的卧室数量) 2 df["rooms_per_household"] = df["total_rooms"]/df["households"] 3 df["bedrooms_per_room"] = df["total_bedrooms"]/df["total_rooms"] 4 corr=df.corr() 5 corr['median_house_value'].sort_values(ascending=False)
1 del df['total_rooms'] 2 del df['total_bedrooms'] 3 corr=df.corr() 4 corr['median_house_value'].sort_values(ascending=False)

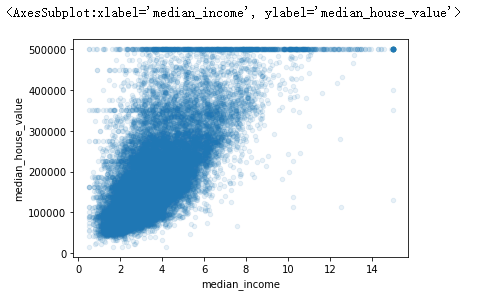
1 df.plot(kind='scatter',x='median_income',y='median_house_value',alpha=0.1)
1 ### 用中介值填缺少的值 2 from sklearn.impute import SimpleImputer 3 imputer=SimpleImputer(strategy='median') 4 nums=df.drop('ocean_proximity',axis='columns') 5 imputer.fit(nums) 6 imputer.statistics_

1 imputed=imputer.transform(nums) 2 df_nums=pd.DataFrame(imputed,columns=nums.columns) 3 df_nums.info()
1 # 造分类变量的虚拟变量 2 df_cat=df[['ocean_proximity']] 3 df_cat.head()
1 df_cat1=pd.get_dummies(df_cat,columns=['ocean_proximity']) 2 df_cat1.info()
1 df_r=df_nums.join(df_cat1) 2 df_r.info()
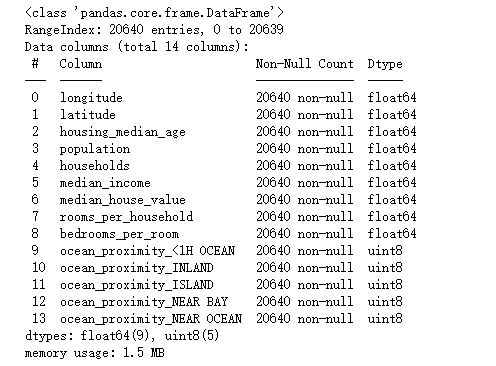
1 df_r.head()

划分数据:
1 # ## 划分数据 2 X=df_r.drop('median_house_value',axis=1) 3 X = sm.add_constant(X) 4 y=df_r['median_house_value'] 5 X.head(),y.head()

建立一个线性回归模型:
1 #建立一个线性回归模型 2 model=sm.OLS(y,X).fit() 3 model.summary()
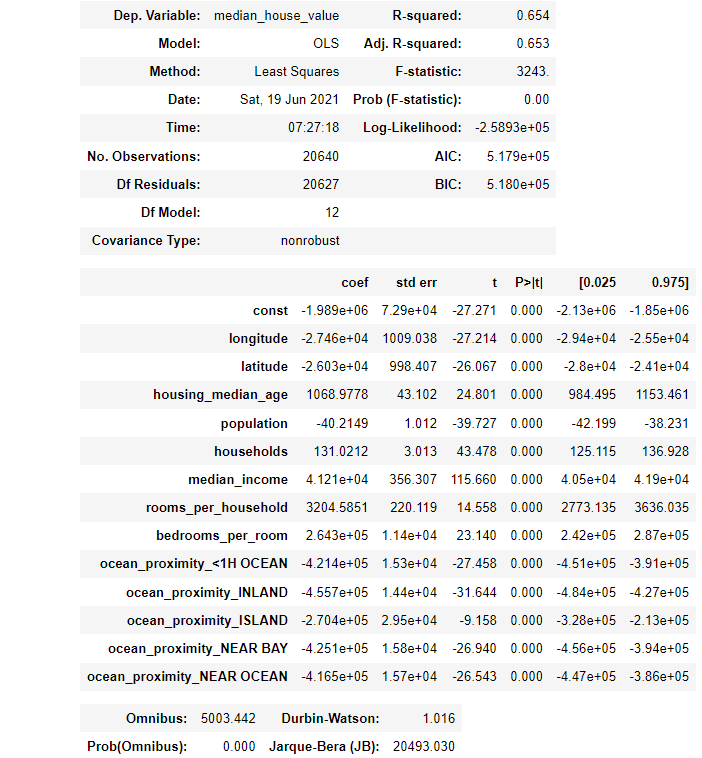
1 # ## 结果还可以(修正R方=0.65),但还要继续分析考虑它的二次多项和三次多项 2 from sklearn.base import BaseEstimator, RegressorMixin 3 from sklearn.model_selection import cross_val_score 4 class SMWrapper(BaseEstimator, RegressorMixin): 5 def __init__(self, model_class, fit_intercept=True): 6 self.model_class = model_class 7 self.fit_intercept = fit_intercept 8 def fit(self, X, y): 9 if self.fit_intercept: 10 X = sm.add_constant(X) 11 self.model_ = self.model_class(y, X) 12 self.results_ = self.model_.fit() 13 def predict(self, X): 14 if self.fit_intercept: 15 X = sm.add_constant(X) 16 return self.results_.predict(X)
1 def poly(X,y): 2 result=[] 3 for i in range(3): 4 poly=PolynomialFeatures(degree=i+1) 5 X_pol=poly.fit_transform(X) 6 scores=cross_val_score(SMWrapper(sm.OLS), X_pol, y, scoring='r2',cv=5) 7 mean=scores.mean() 8 result.append((i+1,mean)) 9 return result 10 poly(X,y)
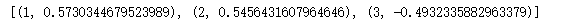
1 # ## 二次多项和三次多项的修正R方下降了,所以就使用线性模型 2 ## 现在看一下各变量的p值(有没有大于0.05的p值) 3 def pvalue(p): 4 print('p_values: ','\n', p,'\n') 5 print('p_values under 0.05: ') 6 if len(p[p>0.05])!=0: 7 print(p[p>0.05]) 8 else: 9 print('None') 10 p=model.pvalues 11 pvalue(p)

1 ## 各变量的p值都小于0.05,所以每个变量都是有用的 2 ## 那看一下个变量的VIF值是多少 3 from statsmodels.stats.outliers_influence import variance_inflation_factor 4 vif=pd.Series([variance_inflation_factor(X.values, i) for i in range(X.shape[1])], index=X.columns) 5 print('VIF: ','\n',vif)

1 ### 各变量的VIF值都没有问题 2 ## 最后,该模型的各变量的系数是: 3 print('Model parametres are: ','\n',model.params)

完整代码:
1 #!/usr/bin/env python 2 # coding: utf-8 3 4 import pandas as pd 5 import numpy as np 6 import matplotlib.pyplot as plt 7 import seaborn as sns 8 import statsmodels.api as sm 9 from sklearn.preprocessing import PolynomialFeatures 10 import warnings 11 warnings.filterwarnings('ignore') 12 # 让表格直接在jupyter显示出来 13 get_ipython().run_line_magic('matplotlib', 'inline') 14 15 ### 导入Kaggle提供的数据 16 df=pd.read_csv(r'housing.csv') 17 # 对导进来的数据进行显示 18 19 df.head() 20 21 # #先分析原始数据 22 df.info() 23 # 展示数据列表中一些缺失 24 df['ocean_proximity'].value_counts() 25 26 df.isnull().sum() 27 df.duplicated().sum() 28 df.describe() 29 # 查看第一列数据是不是索引项 30 df["longitude"] 31 32 #对于重复值进行查询,并且做出处理 33 df4 = df.copy() 34 df[df.duplicated()].count() 35 36 # 对median_house_value这里面如果有空的数值进行删除,因为为空数值无意义 37 df4.dropna(axis=0,subset = ["median_house_value"],inplace=True) 38 df4.head(10),df.shape 39 40 # 画出直方图,直观展示各个数据之间关系 41 df.hist(bins=50,figsize=(20,15)) 42 # 展示直方图 43 plt.show() 44 45 # 展示其中热力图,展示房价之间关系存在 46 df.plot(kind='scatter',x='longitude',y='latitude',alpha=0.4,s=df['population']/100,label='population',figsize=(10,7), 47 c='median_house_value',cmap=plt.get_cmap('jet'),colorbar=True) 48 plt.legend() 49 # 展示图片 50 plt.show() 51 52 ### 看一下各变量与房价的相关系数 53 df1 = df.copy() 54 # 删除其中一个变量观察其中影响 55 del df1['longitude'] 56 corr=df1.corr() 57 socre = corr['median_house_value'].sort_values(ascending=False) 58 # 展示各个变量之间存在的关系 59 print(socre) 60 61 # 我们对其中某一变量进行删除观察其余变量与房价之间的相关系数 62 df2 = df.copy() 63 list_name = ["longitude","latitude","housing_median_age","total_rooms"] 64 # 循环的方式来展示他们之间的关系 65 # 展示变量之间与房价存在的关系 66 for i in list_name: 67 del df2[i] 68 corr=df2.corr() 69 socre = corr['median_house_value'].sort_values(ascending=False) 70 # 展示各个变量之间存在的关系 71 print(socre) 72 73 # 观察中间几个变量对房价的影响关系 74 list_name5 =["housing_median_age","total_rooms""total_bedrooms","population","households","median_income"] 75 df5 = df.copy() 76 # 循环的方式来展示他们之间的关系 77 for i in list_name5: 78 del df5[i] 79 corr=df5.corr() 80 socre = corr['median_house_value'].sort_values(ascending=False) 81 print(socre) 82 83 # 当我们对数据改变之后,我们对数据进行初步分析 84 df2.info() 85 df2['ocean_proximity'].value_counts() 86 87 #计算数据的总和 88 df2.isnull().sum() 89 df2.duplicated().sum() 90 91 # 得到数据进行描述 92 df2.describe() 93 94 # 当我们对数据改变之后,我们对数据进行初步分析 95 df2.info() 96 df2['ocean_proximity'].value_counts() 97 df2.isnull().sum() 98 df2.duplicated().sum() 99 df2.describe() 100 101 # 观察后面几个变量对房价的影响关系 102 list_name2 =["total_bedrooms","population","households","median_income"] 103 104 df3 = df.copy() 105 # 循环的方式来展示他们之间的关系 106 107 for i in list_name2: 108 del df3[i] 109 corr=df3.corr() 110 socre = corr['median_house_value'].sort_values(ascending=False) 111 print(socre) 112 113 bijiao_zong = [] 114 df = df.copy() 115 corr=df.corr() 116 socre = corr['median_house_value'].sort_values(ascending=False) 117 for u in socre: 118 bijiao_zong.append(u) 119 print(bijiao_zong) 120 # 当我们对数据改变之后,我们对数据进行初步分析 121 df3.info() 122 df3['ocean_proximity'].value_counts() 123 df3.isnull().sum() 124 df3.duplicated().sum() 125 df3.describe() 126 127 #插入一些有用的变量 (比如:每间客房的卧室数量) 128 df["rooms_per_household"] = df["total_rooms"]/df["households"] 129 df["bedrooms_per_room"] = df["total_bedrooms"]/df["total_rooms"] 130 corr=df.corr() 131 corr['median_house_value'].sort_values(ascending=False) 132 133 # 删除这俩个数据我们发现他们都是独立同分布的 134 del df['total_rooms'] 135 del df['total_bedrooms'] 136 corr=df.corr() 137 corr['median_house_value'].sort_values(ascending=False) 138 # 画出房价与收入的散点图 139 df.plot(kind='scatter',x='median_income',y='median_house_value',alpha=0.1) 140 ### 用中介值填缺少的值 141 from sklearn.impute import SimpleImputer 142 143 imputer=SimpleImputer(strategy='median') 144 nums=df.drop('ocean_proximity',axis='columns') 145 146 imputer.fit(nums) 147 imputer.statistics_ 148 149 imputed=imputer.transform(nums) 150 df_nums=pd.DataFrame(imputed,columns=nums.columns) 151 152 # 展示处理之后的数据 153 df_nums.info() 154 # 造分类变量的虚拟变量 155 156 df_cat=df[['ocean_proximity']] 157 #展示ocean_proximity这一列数据 158 df_cat.head() 159 #对ocean_proximity这一列进行预处理 160 df_cat1=pd.get_dummies(df_cat,columns=['ocean_proximity']) 161 # 处理后数据展示 162 df_cat1.info() 163 df_r=df_nums.join(df_cat1) 164 # 展示全局数据df 类型 165 166 df_r.info() 167 # 读取df_r头文件 168 df_r.head() 169 170 # ## 划分数据 171 X=df_r.drop('median_house_value',axis=1) 172 173 X = sm.add_constant(X) 174 y=df_r['median_house_value'] 175 # 划分x,y数据 176 X.head(),y.head() 177 #先建立一个线性回归模型 178 model=sm.OLS(y,X).fit() 179 180 model.summary() 181 182 # ## 结果还可以(修正R方=0.65),但还要继续分析考虑它的二次多项和三次多项 183 from sklearn.base import BaseEstimator, RegressorMixin 184 from sklearn.model_selection import cross_val_score 185 # 定义一个类,针对分析二次三次 186 187 class SMWrapper(BaseEstimator, RegressorMixin): 188 189 def __init__(self, model_class, fit_intercept=True): 190 self.model_class = model_class 191 self.fit_intercept = fit_intercept 192 193 # 进行数据预测 194 def fit(self, X, y): 195 if self.fit_intercept: 196 X = sm.add_constant(X) 197 self.model_ = self.model_class(y, X) 198 self.results_ = self.model_.fit() 199 200 def predict(self, X): 201 if self.fit_intercept: 202 X = sm.add_constant(X) 203 204 return self.results_.predict(X) 205 206 207 def poly(X,y): 208 result=[] 209 210 for i in range(3): 211 poly=PolynomialFeatures(degree=i+1) 212 X_pol=poly.fit_transform(X) 213 scores=cross_val_score(SMWrapper(sm.OLS), X_pol, y, scoring='r2',cv=5) 214 mean=scores.mean() 215 result.append((i+1,mean)) 216 return result 217 poly(X,y) 218 219 # ## 二次多项和三次多项的修正R方下降了,所以就使用线性模型 220 ## 现在看一下各变量的p值(有没有大于0.05的p值) 221 def pvalue(p): 222 print('p_values: ','\n', p,'\n') 223 print('p_values under 0.05: ') 224 225 if len(p[p>0.05])!=0: 226 print(p[p>0.05]) 227 else: 228 print('None') 229 #模型参数预测 230 p=model.pvalues 231 # 打印出其中的参数 232 pvalue(p) 233 234 ## 各变量的p值都小于0.05,所以每个变量都是有用的 235 ## 那看一下个变量的VIF值是多少 236 from statsmodels.stats.outliers_influence import variance_inflation_factor 237 238 vif=pd.Series([variance_inflation_factor(X.values, i) for i in range(X.shape[1])], index=X.columns) 239 # 打印出来vif的值 240 print('VIF: ','\n',vif) 241 242 ### 各变量的VIF值都没有问题 243 244 ## 最后,该模型的各变量的系数是: 245 246 print('Model parametres are: ','\n',model.params)
四:总结:
数据处理一直是当下最热门的话题,其中逻辑回归lOS模型是当下主要对数据处理进行回归的主要模型。我们选取美国加利福尼亚关于房源价值的等系列信息数据集。进行回归分析。分析房子价值与其他变量的相关性。并且用直方图以及热力图进行直观的展示。这次项目达到预期的效果,今后会继续提高自己。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号