我是新来的,我需要知道这些吗?网关上的限流器
1. nginx原生限流能力
ngx_http_limit_req_module 提供的请求限流能力必须基于某个预定义的key,eg: client Ip, request_uri, host_name, 这个限流器是基于漏桶算法。
limit_req_zone $binary_remote_addr zone=ip:10m rate=5r/s;
server {
listen 80;
location / {
limit_req zone=ip burst=12 delay=8;
proxy_pass http://website;
}
}
① 使用二进制client ip 作为限流的基础维度,相比字符串形式的remote_addr 占用空间更小
② 限流的配置名是ip, 使用了nginx的共享内存来存储 <remote_addr:rateLimit>键值对
③ r= 5r/s 漏桶每s放行5个请求, 支持的最大并发能力是12(排队请求12)
④ 上文“漏桶算法”显示,排队中的请求会有等待的延迟时间,如果不希望过多的等待,指定delay参数(默认是0,排队的请求都被延迟)。
那问题又来了, 我就想基于整体请求速率限流,不想根据某个特定的请求key限流, 阁下又该如何回锅?
nginx map指令就可以派上用场:map 基于现有变量$remote_addr创建新变量$global_req_key。
http {
map $remote_addr $global_req_key {
default 0;
// 有很多分支值,去掉这些分支,就99归1了。
}
limit_req_zone $gloobal_req_key zone=global:10m r=10r/s;
}
ref
-
nginx上还有
特定键上发生的连接数的限流指令limit_conn_zone 供参考。 -
openresty 内置了限流模块lua-resty-limit-traffic, 支持漏桶、固定窗口限速,支持施加多个限流策略。
2. kong网关限流能力
kong 网关上有rate-limiting插件,可以提供限流能力
| 功能性需求 | 非功能性需求 |
|---|---|
| 通过userid,ip,apikey 识别用户 | 低延时(<10ms) |
| 基于配置的规则限制请求 | 高可用大于一致性 |
| 返回合适的错误响应头和状态码 | 能扩展支撑 1M qps |
核心实体:
- Rules
- Clients
- Requests
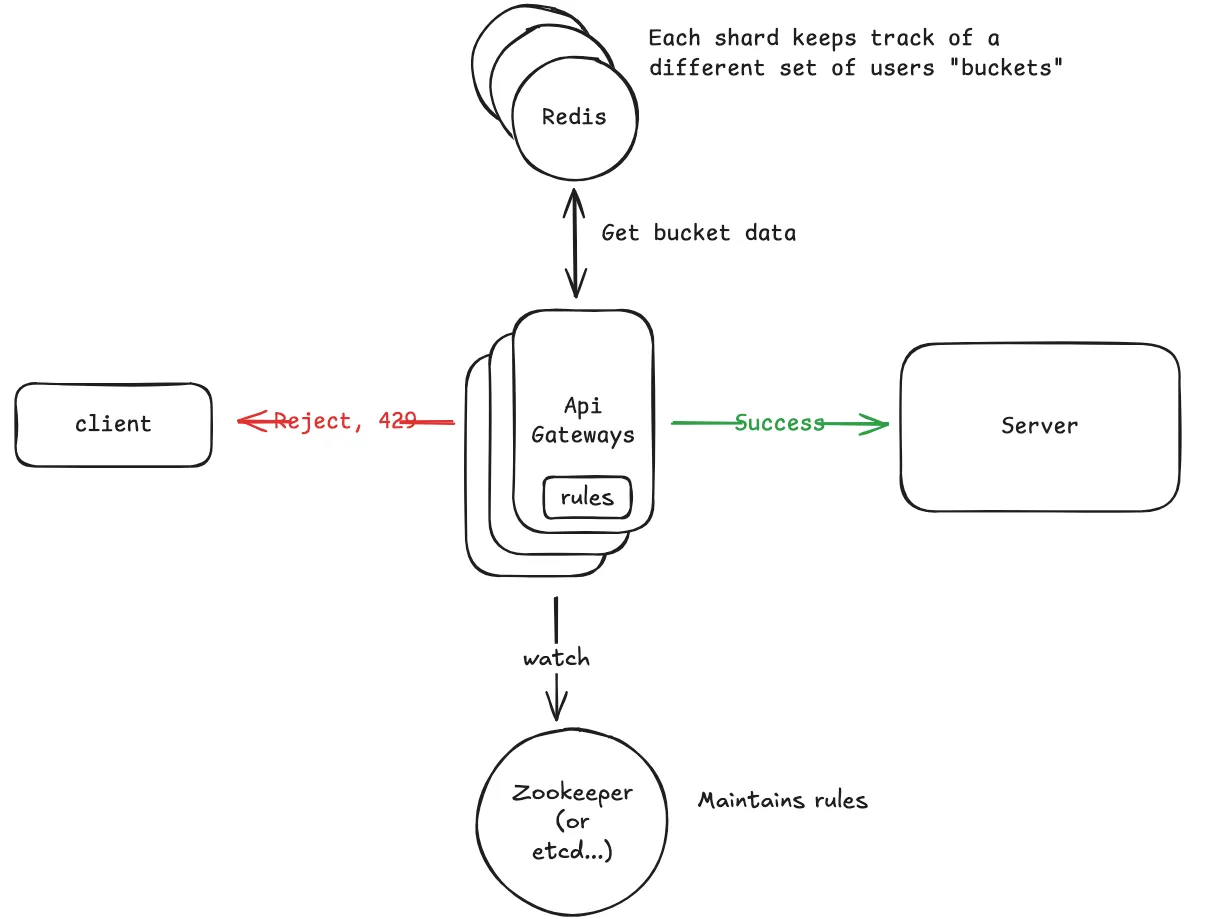
当请求到来,识别用户, 找到可应用的规则;
根据这些规则检查当前的使用情况,并决定是允许还是拒绝请求。
系统接口: kong/plugins/rate-limiting/handler.lua/function RateLimitingHandler:access(conf)
kong网关支持的上层设计
① 识别用户
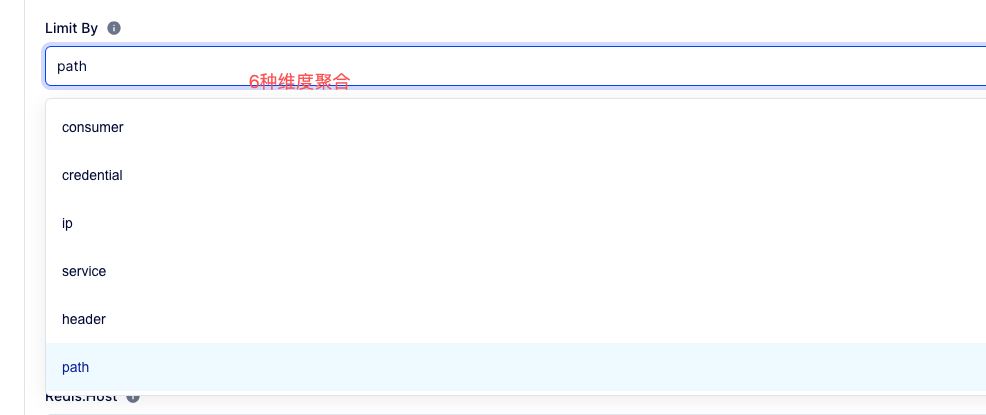
6种维度聚合, 默认使用ip聚合。
② 固定窗口限流
③ 请求超限时,支持自定义响应头和响应码
④ 故障容错: 当第三方数据源出现故障,是否禁用限流。(Fault Tolerant= true意味着忽略故障,继续转发)。
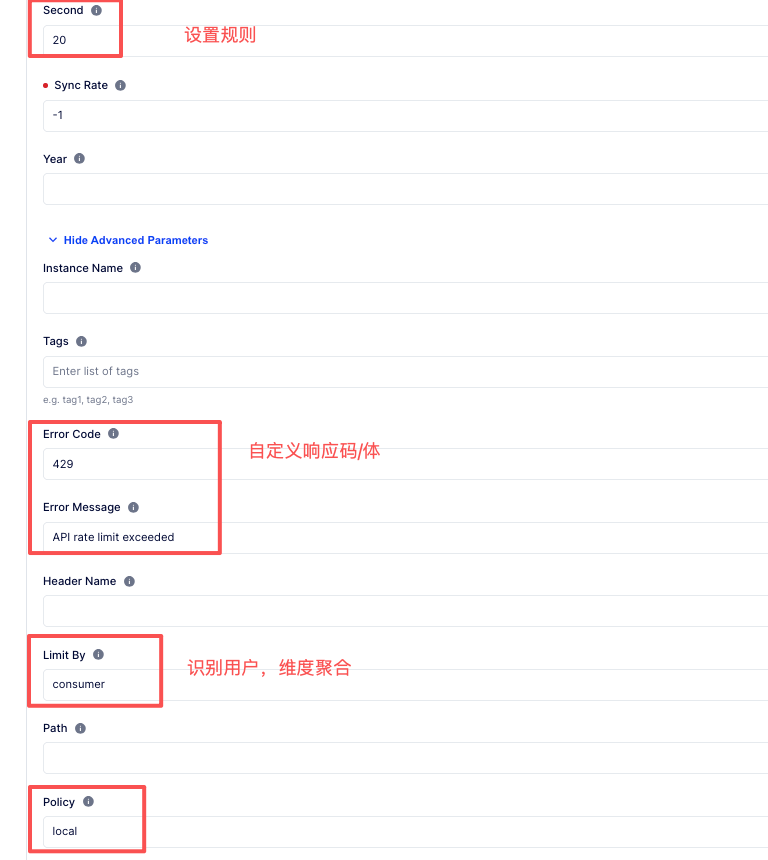
kong网关内置的限流插件, 支持local, cluster, redis三种策略, 技术选型要从限流精度和限流组件引入的的延迟角度来考量。
对于要求高精度的(涉及财务)的交易请求,推荐使用 cluster或者redis,kong网关的cluster策略其实就是使用kong 网关的数据存储postgres, 性能肯定没有redis好,但好在不需要引入新的组件。
开源版本rate limit插件只支持standalone单机模式redis; 企业版rate-limiting-advanced支持哨兵和redis-cluster模式。
在docker-kong官方脚手架新增redis服务作为限流计算器的的第三方存储:
volumes:
kong_data: {}
redis_data: {}
// ......
services:
redis:
image: redis:latest
restart: always
ports:
- '6379:6379'
command: redis-server --save 20 1 --loglevel notice
networks:
- kong-net
volumes:
- redis_data:/data
验证有效:

3. 分布式限流
上文我们分享了 redis作为令牌桶限流器第三方存储的实现,对于小规模业务QPS效果很好。
但是当我们的目标QPS规模为 100 万个请求/秒时,架构难以支撑。
一个典型的 Redis 单实例每秒可处理约 100,000-200,000 次操作,具体取决于操作的复杂程度。我们的每个速率限制检查都需要多个 Redis 操作(至少需要一个 HMGET 来获取状态,一个 HSET 来更新状态)。因此,在成为瓶颈之前,我们的单Redis 实例每秒可实际处理约 50000-100000 次速率限制检查。
3.1 应对1M/s的业务请求:
① 业务层面做分片redis:
在业务层面使用一致性哈希算法将来自userid (clientip,api_key) 的user tokenbuckets 数据映射到不同redis实例。 按照上面的计算,应对1M/s的请求,需要10台redis分片实例。
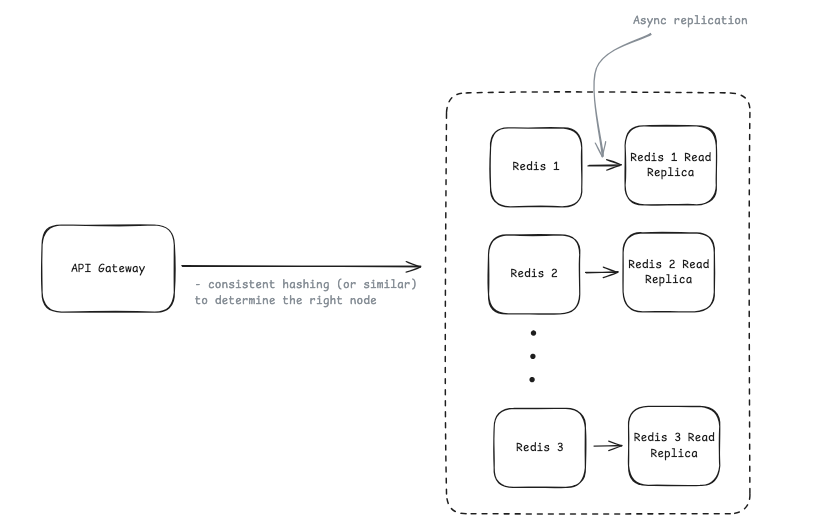
② 更可行的是采用 redis cluster
Redis Cluster会自动处理上面描述的数据分片,key被划分为16384个哈希槽,并将这些槽分布在多个Redis 节点上。
当你存储类似 userbucket:junio 这样的限速key时,Redis Cluster 会自动根据key的哈希槽来决定应将其存储在哪个节点上。这样,你只需连接到 Redis 集群,它就会自动处理路由,而无需在API网关中构建自定义的业务层面的一致性哈希逻辑。
保障高可用设计,redis cluster标准姿势是master-replicas :
3.2 减少引入限流中间件的延迟
- 网关与redis cluster交互时,使用连接池,重用连接
- 在靠近用户请求的地方部署 限速组件
推荐使用push方法来动态更新规则配置
4. 如何优雅实施“限流”?
在订单系统中应用“限流”,你怎么理解“限流”和”订单有损“的关系?
这里的关键是区分“有损服务” 和“完全不可用服务”, 体现的是“牺牲局部,保全整体”的设计哲学。
-
分层和分机限流
[x] 前端限流: 在按钮上做防止重复提交,页面上用验证码过滤机器人
[x] 网关层限流: 对每个API,每个用户,每个客户端ip设置频率限制, 防止滥用脚本
[x] 应用层限流: 针对不同的业务场景设置不同的阈值。 -
柔性限流
- 队列化(削峰填谷)
- 友好提示
- 降级策略
- 动态限流和自动化
本文来自博客园,作者:{有态度的马甲},转载请注明原文链接:https://www.cnblogs.com/JulianHuang/p/19249720
欢迎关注我的原创技术、职场公众号, 加好友谈天说地,一起进化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号