🔥字节一面:go的协程相比线程,轻量在哪?
如题, 说到轻量级用户态线程,就要从操作系统的调度模型这个大背景 开始聊了。
1. 大背景:常规资源调度模型
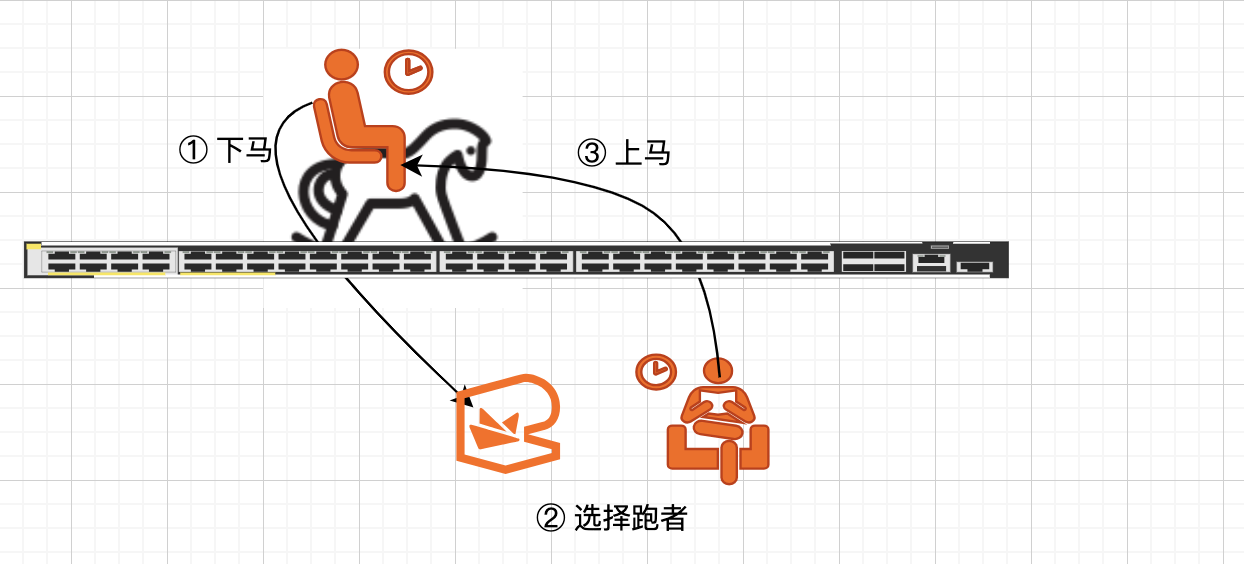
调度说白了就是: 下马、换人、再上马跑, 资源就是马。
操作系统分为用户态和内核态(或者叫用户空间和内核空间), 内核态是一种特殊的调度程序,统筹有限的计算机硬件资源,例如协调CPU资源、分配内存资源、并且提供稳定的环境供应用程序运行`。
Q:那内核态究竟是什么呢? 为什么要划分内核态?
A: 计算机是多进程操作系统,多个用户进程同时都在利用有限的物理资源:cpu、内存、io, 需要一个超然的角色来管理和调度有限的物理资源,
于是操作系统抽象出了内核对象,用于代表上述物理资源,内核态代码维护的内核对象,最终完成了资源调度。
另外用户可以系统调用、api函数来产生和操作内核对象。
eg: C# new Thread创建了线程对象,实际是通过CLR创建了操作系统线程(线程内核对象)。
本文重点聚焦在cpu(计算资源)的调度模型上。
2. 聚焦到常规cpu资源调度模型
进程是资源占有的基本单位, 线程是cpu调度的基本单位,
线程中的代码是在用户态运行, 而常规调度模型(大背景)存在内核态, 故可以知道常规的线程调度会产生“线程切换”。
2.1 线程切换
说简单的就是:当前线程放弃cpu执行片, 调度器安排另外一个线程接受cpu调度, 说白了存在一个“下马、换人、再上马跑”的切换过程, 我就问你要不要减个速嘛。
实际上:
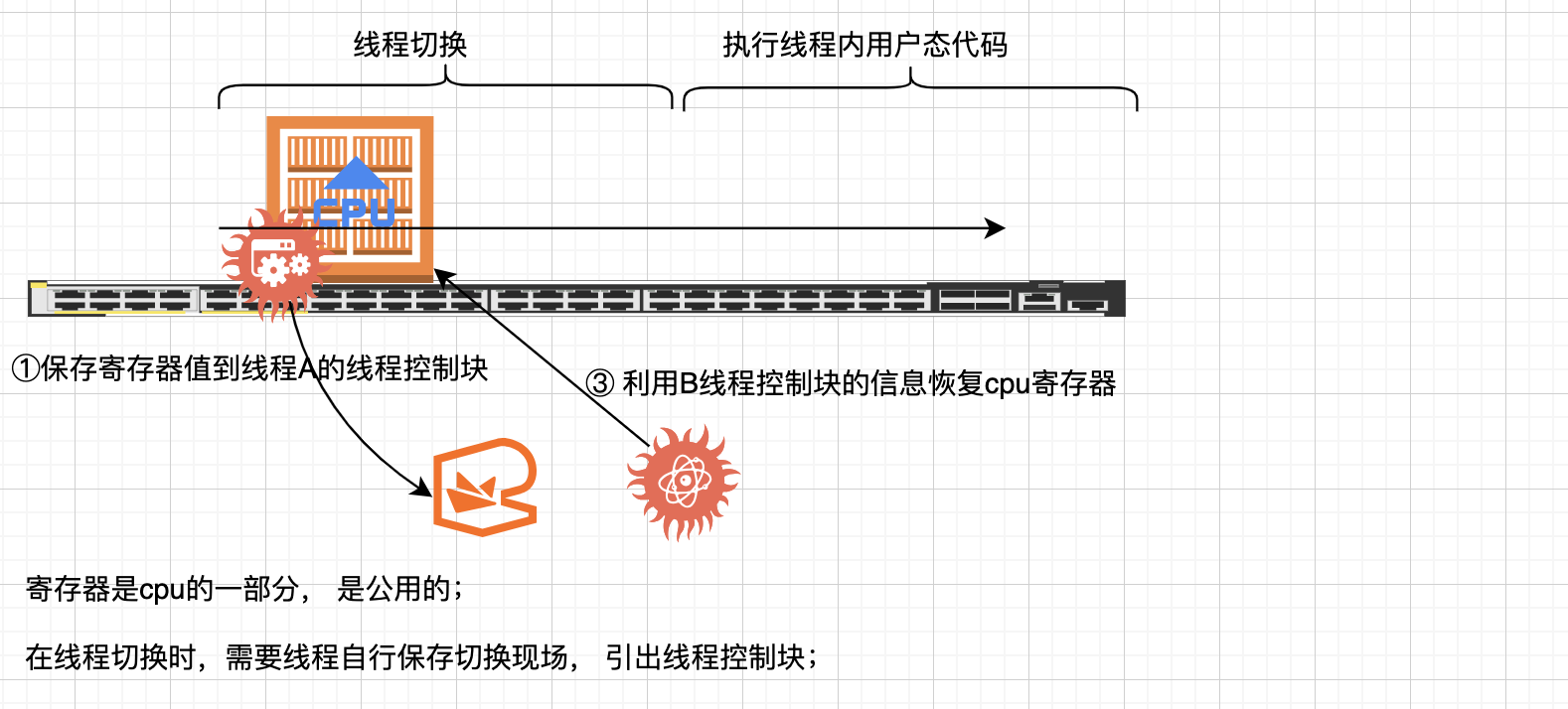
① 保存当前线程的寄存器状态:操作系统首先需要保存当前正在运行的线程的所有寄存器值。这是因为每个线程都有自己独立的执行环境,包括程序计数器、栈指针、通用寄存器等。
② 选择下一个要执行的线程:调度器根据一定的算法(如时间片轮转、优先级调度等)选择下一个要执行的线程。
③ 恢复选定线程的寄存器状态:一旦确定了下一个要执行的线程,操作系统就会从该线程的控制块(TCB, Thread Control Block)中恢复其寄存器状态,包括设置程序计数器到正确的指令位置,恢复栈指针以及其它通用寄存器的值。
2.2 线程切换的时机
分为用户代码导致的 和 操作系统主动形成的线程切换。
| ① 自发性上下文切换 | 线程受用户代码指令导致的切出 |
|---|---|
| Thread.sleep() | 线程主动休眠 |
| object.wait() | 线程等待锁 |
| Thread.yield() | 当前线程主动让出CPU,如果有其他就绪线程就执行其他线程,如果没有则继续当前线程 |
| oThread.join() | 阻塞发起调用的线程,直到oThread执行完毕 |
| ② 非自发性上下文切换: 来自内核线程调度器管控 |
|---|
| 线程的时间片用完 ,cpu时间片雨露均沾 |
| 高优先级线程抢占 |
| 虚拟机的垃圾回收动作 |
线程上下文切换的代价是高昂的:上下文切换的延迟取决于不同的因素,大概是50到100ns左右,考虑到硬件平均在每个核心上每ns执行12条指令,那么一次上下文切换可能会花费600到1200条指令的延迟时间。
2.3 线程切换的影响
| ① 直接开销 |
|---|
| 保存当前/恢复新线程上下文所需的开销 |
| 线程调度器调度线程的开销 |
| ② 间接开销 |
|---|
| 重新加载高速缓存 |
| 上下文切换可能导致 一级缓存被冲刷,写入下一级缓存或内存 |
3. go的用户态轻量级线程
如上面所述,常规线程切换会存在用户态程序和内核态调度程序的切换, 有一个减速换挡的瞬间。
大佬们思考了另外一个思路:将调度尽量维持在用户态。
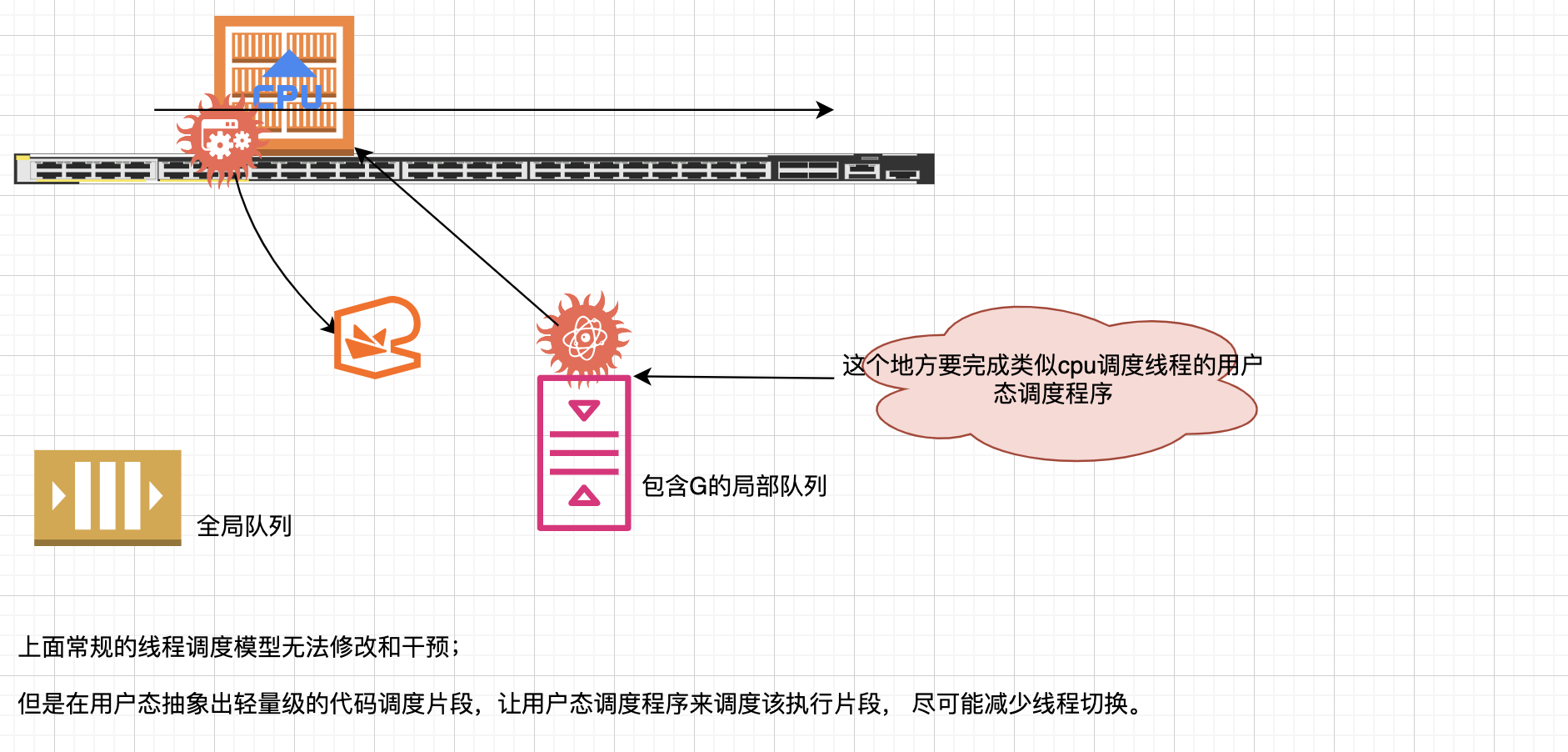
系统线程对goroutine的调度与内核对系统线程的调度原理是一样的,实质都是通过保存和恢复CPU寄存器的值来达到切换goroutine/切换线程的目的。
因此在go语言调度器源代码中,goroutine的数据结构g里面也有类似线程控制块那样的状态值,来保存/恢复cpu寄存器值。
调度器代码可以通过g对象来对goroutine进行调度。
当goroutine被调离CPU时,调度器代码负责把CPU寄存器的值保存在g对象的成员变量之中;
当goroutine被调度起来运行时,调度器代码又负责把g对象的成员变量所保存的寄存器的值恢复到CPU的寄存器前面我们所讲的G,M,P,在源码中均有与之对应的数据结构。
3.1 goroutine GPM模型历史演进
由早期的GM模型,演进到GPM调度模型。
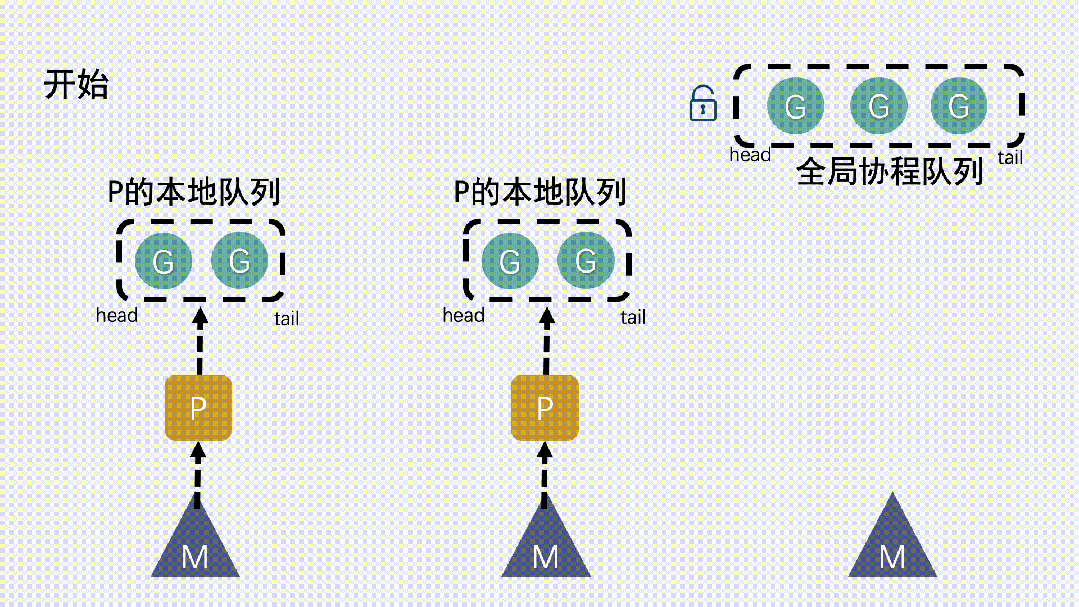
每个G(Goroutine)要想真正运行起来,需要通过用户态的调度器P 进入待调度本地队列(local runq)中。
对于M来说,调度器P解耦了调度/执行, 避免了对全局G队列的有锁抢占。
3.2 GPM调度优势
(1) 上下文切换代价小: P 是G、M之间的桥梁,调度器对于goroutine的调度,很明显也会有切换,这个切换是很轻量的:
只涉及
- PC (程序计数器,标记当前执行的代码的位置)
- SP (当前执行的函数堆栈栈顶指针)
- BP 三个寄存器的值的修改;
而对比线程的上下文切换则需要陷入内核模式、以及16个寄存器的刷新。
(2) 内存占用小: 线程栈空间通常是2M, Goroutine栈空间最小是2k, golang可以轻松支持1w+的goroutine运行,而线程数量到达1k(此时基本就达到单机瓶颈了), 内存占用就到2G。
以上是宏观的GPM调度模型, 实际可能发生的调度场景、 调度执行中的情形一样重要
4. GO 协程调度时机
M上执行的代码是在 G -->g0--->G 上循环, g0负责找到runable的goroutine,
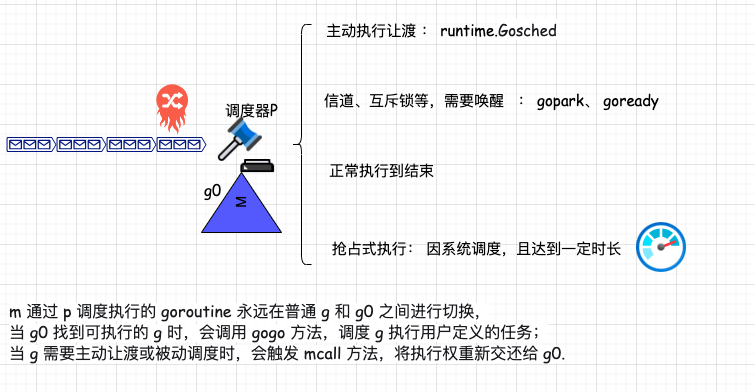
抢占调度:
倘若 g 执行系统调用超过指定的时长,且全局的 p 资源比较紧缺,此时将 p 和 g 解绑,抢占出来用于其他 g 的调度. 等 g 完成系统调用后,会重新进入可执行队列中等待被调度.
值得一提的是,前 3 种调度方式都由 m 下的 g0 完成,唯独抢占调度不同.
因为发起系统调用时需要打破用户态的边界进入内核态,此时 m 也会因系统调用而陷入僵直,无法主动完成抢占调度的行为.
因此,在 Golang 进程会有一个全局监控协程 monitor g 的存在,这个 g 会越过 p 直接与一个 m 进行绑定,不断轮询对所有 p 的执行状况进行监控. 倘若发现满足抢占调度的条件,则会从第三方的角度出手干预,主动发起该动作。
调度流程的主干方法是位于 runtime/proc.go 中的schedule(),此时的执行权位于 g0 手中。
func schedule() {
// ...
gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available
// ...
execute(gp, inheritTime)
}
goroutine在执行层面的情况, 也是调度细节的一部分:
Go scheduler is not a preemptive scheduler but a cooperating scheduler. Being a cooperating scheduler means the scheduler needs well-defined user space events that happen at safe points in the code to make scheduling decisions. The followings are the opportunities for scheduling:
① The use of the keyword go
This is how we create a new goroutine, scheduler gain an opportunity when a new goroutine was created.
② 同步 and 信道操作
If an mutex, or channel operation call will cause the Goroutine to block, the scheduler can context-switch a new Goroutine to run. Once the Goroutine can run again, it will be re-queued automatically.
③ System calls
Including async and sync system calls, go has different way to deal with them. With async type like network request, a network poller would be used, goroutine that might block is moved to net poller, let the proccesor can execute the next one.
With sync type like file I/O, the current pair of G and M will be seperated from G, P, M model. Meawhile, a new machine would be created in order to keep the original G, P, M model working, and the block goroutine would be take back while system call finished.
④ Garbage collection
Since the GC runs using its own set of Goroutines, those Goroutines need time on an M to run, scheduler needs an opportunity to handle that.
总结起来,可分为两类:
- 网络 IO、信道操作、同步锁:只阻塞 G,M、P 可用,即线程不会让出时间片
- 磁盘IO:阻塞的M、G从GPM模型脱离, 需要切换一个新的M去承接原始P (有线程切换)
5. goroutine生命周期
Go 必须对每个运行着的线程上的 Goroutine 进行调度和管理。
这个调度的功能被委托给了一个叫做g0的特殊的 goroutine, g0 是每个 OS 线程创建的第一个goroutine。
g0为新创建的goroutine
- 设置PC/SP字段初始值
- 更新goroutine内部的 ID和status
Go 需要一种方法来掌控goroutine的结束。
这个控制是在 goroutine 的创建初始,执行片段之前,通过PC指针值设置了SP指针值的首个函数栈帧(名为goexit的函数), 这个技巧强制goroutine在结束工作后调用函数goexit。
newg.sched.pc = funcPC(goexit) + sys.PCQuantum
newg.sched.g = guintptr(unsafe.Pointer(newg))
gostartcallfn(&newg.sched, fn)
//------------- ......
// adjust Gobuf as if it executed a call to fn with context ctxt
// and then did an immediate gosave.
func gostartcall(buf *gobuf, fn, ctxt unsafe.Pointer) {
sp := buf.sp
...
sp -= sys.PtrSize
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
buf.sp = sp
buf.pc = uintptr(fn)
buf.ctxt = ctxt
}
6. goroutine的常规实践
-
在一个函数前放置go即可开启一个go的 协程,如其他函数一样,可以有形参,不过函数返回值会被忽略。
-
在golang中, 大家习惯使用一个封装了业务逻辑的闭包来启动一个goroutine, 该闭包负责管理并发的数据和状态,例如闭包从信道中读取数据并传递给业务逻辑, 业务逻辑完全不知道它是在一个goroutine中,
然后函数的结果被写回另外一个信道,这种职责分离使代码模块化、可测试,并使得api调用简单,无需关注并发问题。
<!---->
func process(val int) int {
}
func runningConcurrently(in <-chan int, out chan <- int) {
go func() { // 业务逻辑协程
for val := range in {
result := process(val)
out<- result // 利用信道来在协程间通信
}
}
}
ref
本文来自博客园,作者:{有态度的马甲},转载请注明原文链接:https://www.cnblogs.com/JulianHuang/p/16008107.html
欢迎关注我的原创技术、职场公众号, 加好友谈天说地,一起进化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号