


GIL全局解释器锁/死锁现象/进程池与线程池

GIL全局解释器锁
在官网中,对GIL全局解释器锁的解释如下:
In CPython, the global interpreter lock, or GIL, is a mutex that prevents multiple
native threads from executing Python bytecodes at once. This lock is necessary mainly
because CPython’s memory management is not thread-safe. (However, since the GIL
exists, other features have grown to depend on the guarantees that it enforces.)
1、python解释器有很多版本,比如Cpython,Jpython,pypython
在Cpython中GIL全局解释器锁其实也是一把互斥锁,主要用于阻止同一个进程下的多个线程同时被运行(Cpython的多线程无法使用多核优势-->不能并行可以并发)
GIL全局解释器锁肯定存在与Cpython解释器中,主要原因就在于Cpython解释器的内存管理部室线程安全的。
2、内存管理-->垃圾回收机制
垃圾回收机制:引用计数,标记清楚,分代回收
3、同一个进程内的多个线程想要运行,必须先抢GIL锁
4、所有解释型的语言几乎都无法实现同一个进程下的多个线程同时运行。
验证GIL的存在
from threading import Thread
import time
m = 100
def test():
global m
m -= 1
t_list = []
for i in range(100):
t = Thread(target=test)
t.start()
t_list.append(t)
for i in t_list:
i.join()
print(m)
⚠️ 同一个进程下的多个线程虽然有GIL的存在不会出现并行的效果
但是由于线程内有io操作的话还是会造成数据的错乱,这个时候就需要我们添加互斥锁。

死锁现象
from threading import Thread, Lock
import time
A = Lock()
B = Lock()
class MyThread(Thread):
def run(self):
self.func1()
self.func2()
def func1(self):
A.acquire()
print('%s 抢到了A锁' % self.name) # current_thread().name 获取线程名称
B.acquire()
print('%s 抢到了B锁' % self.name)
time.sleep(1)
B.release()
print('%s 释放了B锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
def func2(self):
B.acquire()
print('%s 抢到了B锁' % self.name)
A.acquire()
print('%s 抢到了A锁' % self.name)
A.release()
print('%s 释放了A锁' % self.name)
B.release()
print('%s 释放了B锁' % self.name)
for i in range(10):
obj = MyThread()
obj.start()
注意:就算知道锁的特性及使用方式 也不要轻易的使用 因为容易产生死锁现象
python多线程的作用
这个要视情况而定
🌼 IO密集型
如果有4个任务,每个任务都耗时10秒
此时开设多进程没有太大的优势,遇到IO就需要切换,并且开设进程还需要申请内存空间和重新走父进程的代码,
而开设多线程就很有优势了,不需要消耗额外的资源
🌼 计算密集型
如果有4个任务,每个任务都耗时10秒
开设多进程可以利用多核优势
开设多线程无法使用多核优势
进程池和线程池
进程池:提前开设了固定个数的进程,之后反复调用这些进程完成工作
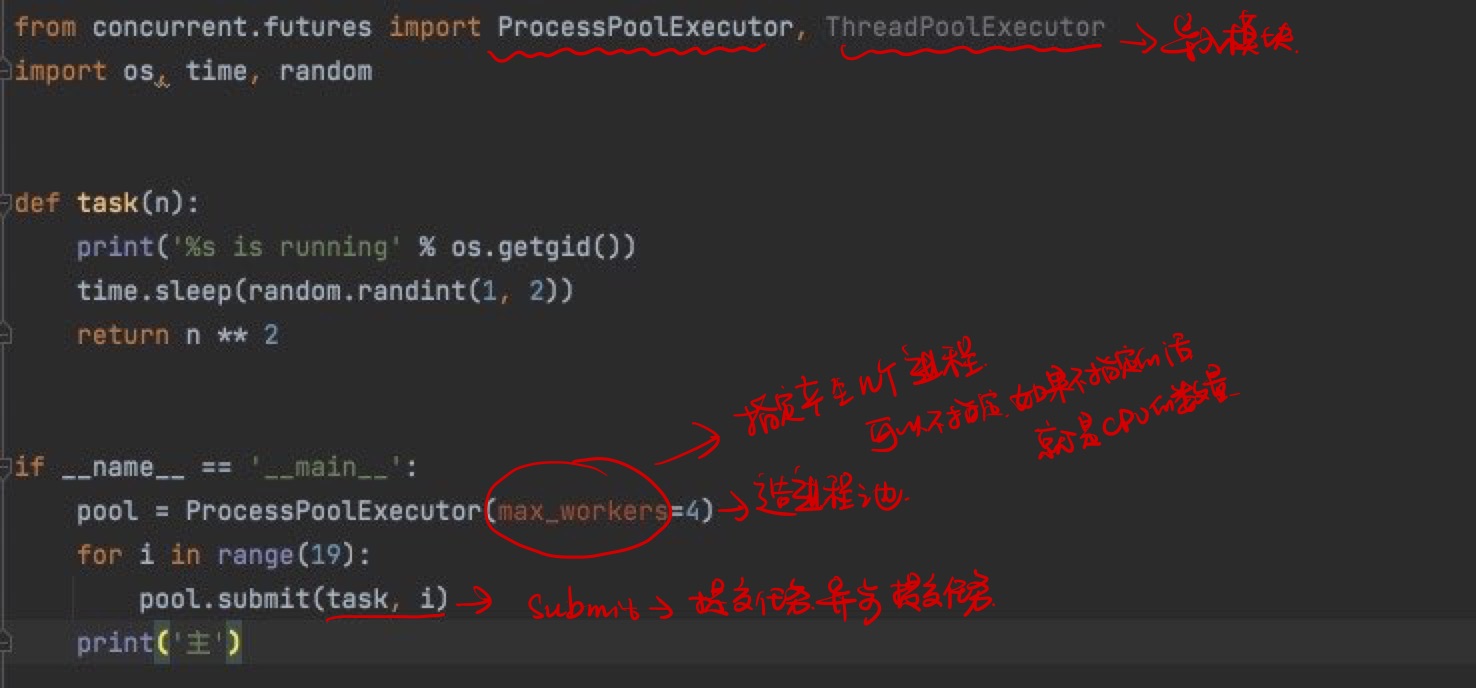
🌼 那我们怎么得到返回值呢:
第一种方法:
from concurrent.futures import ProcessPoolExecutor, ThreadPoolExecutor
import os, time, random
def task(n):
print('%s is running' % os.getpid())
time.sleep(random.randint(1, 3))
return n ** 2
if __name__ == '__main__':
pool = ProcessPoolExecutor(max_workers=2)
l=[]
for i in range(19):
future=pool.submit(task, i)
l.append(future)
pool.shutdown(wait=True)
print('主')
for obj in l:
print(obj.result())
🌼 第二种方式
def task(n):
print('%s is running' % os.getpid())
time.sleep(random.randint(1, 3))
return n ** 2
def handle(future): #future是主进程提交任务后得到一个返回结果,future.result() 得到进程池内代码运行后得到的结果
res = future.result()
print('%s 正在处理结果:%s' % (os.getpid(), res))
time.sleep(2)
if __name__ == '__main__':
pool = ProcessPoolExecutor(max_workers=4)
l = []
for i in range(19):
pool.submit(task, i).add_done_callback(handle)
# add_done_callback 回调函数,意思是主进程每提交一个任务就绑定一个方法
pool.shutdown(wait=True)
print('主')
线程池:提前开设了固定个数的线程,之后反复调用这些进程完成工作
from concurrent.futures import ThreadPoolExecutor
from threading import current_thread
import time, random
def task(n):
print('%s is running' %current_thread().name)
time.sleep(random.randint(1, 3))
return n ** 2
def handle(future): #future是主进程提交任务后得到一个返回结果,future.result() 得到进程池内代码运行后得到的结果
res = future.result()
print('%s 正在处理结果:%s' % (current_thread().name, res))
time.sleep(2)
if __name__ == '__main__':
pool = ThreadPoolExecutor(max_workers=10) #如果没有指定最大值,是cpu数量的5倍
l = []
for i in range(19):
pool.submit(task, i).add_done_callback(handle)
# add_done_callback 回调函数,意思是主进程每提交一个任务就绑定一个方法
pool.shutdown(wait=True)
print('主')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号