姜睿喆---第一次个人编程作业
| 博客班级 | 2018级计算机和综合实验班 |
|---|---|
| 作业要求 | 作业要求 |
| 作业目标 | 采集腾讯视频里电视剧《在一起》的全部评论信息并进行分析处理,将所采集到的评论信息做成词云图,在index.html中显示词云图 |
| 作业源代码 | Github地址 |
| 学号 | 211814315 |
一、前期准备
1.建立GitHub仓库
这里我发现原本安装过的VSCode支持Git,便顺便学习了下如何用VSCode来进行Git操作,结果发现更容易上手,而且VSCode界面更简洁易懂,插件功能是真的强大,总归一句话,VSCode永远滴神!
2.《在一起》评论页面
| 实现过程 | 预计时间 |
|---|---|
| 数据收集 | 2h |
| 数据处理 | 1.5h |
| 数据分析展示 | 2h |
二、数据收集
最初准备通过selenium对评论页面底部加载按钮实现模拟点击,将评论都加载完后再进行爬取,实际操作后发现较难实现且耗费时间。便转换思路,通过使用正则表达式获取评论。
通过访问《在一起》评论页面,按下F12并重新刷新页面,点击页面底部查看更多评论可以发现

每点击一次加载便增加一条,可以判断出此为评论区加载项内容。右击新标签页打开可以查看源码


在页面中可以发现评论内容,由此可以通过这些页面来进行评论的爬取。在收集数个url进行对比后发现,页面主要通过改变cursor和source的数值来进行改变,每加载一次更多评论,source便加一,cursor起始值为0,在查找发现后cursor在每一个页面的
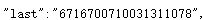
处,由此可推出下一个页面的cursor。在确认上述页面和url变化后通过正则表达式进行爬取,并将爬取到的评论保存至本地文档。
具体爬取代码见GitHub:《在一起评论爬取》.py
爬取评论结果见评论.txt
三、数据处理
在参考了几个分词库后,我选择使用jieba库进行数据处理。首先用pip install jieba,在安装完成后直接import jieba导入进行使用。这里也参考了不少文章进行学习jieba。学习分词的同时对json进行一定了解。在实现分词后,将结果按照一定格式保存为json文件,以便于之后使用。
四、数据分析展示
由于对JavaScript不熟,在参考了多个文章后,还是选择当个cv程序员,借鉴了网上的模板进行修改。在CSDN中找到了相关代码进行操作。简单的网页制作还是会的,在新建了index.html后进行H5代码的编写,其中加入JavaScript的代码。在套用模板后,将之前处理后的数据代入到对应的data部分,最终实现词云图。

本来还想着生成自定义形状的词云图,通用模板问题不大,然而最后发现问题貌似处在使用的图片模板上。根据说查找的CSDN博客的评论区所说,需要用到纯黑的矢量图,好吧瞬间无语,我说怎么老半天出不来(ˉ▽ˉ;)...。
