


【深度学习】|01复旦大学邱锡鹏《神经网络与深度学习》学习小笔记(一)机器学习概述
正则化;
线性函数的概率角度推导;
先验分布决定的Loss函数;
有监督,无监督,增强学习;
两种正则化(损害优化):
(1)增加优化约束L1,L2
(2)干扰优化过程:权重衰减,随机梯度下降,提前终止(我们使用一个验证集(Validation Dataset)来测试每一次迭代的参数在验证集上是否最优。如果在验证集上的错误率不再下降,就停止迭代。)
线性回归的概率角度推导:
假设标签y为一个随机变量,其服从以均值方差分别为如下的正态分布
所以y服从的正态分布为:
在数据集上的联合概率密度函数为:
极大似然思想求解w:
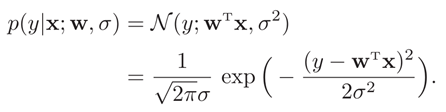
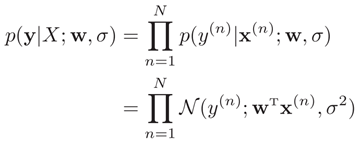
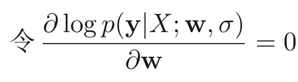
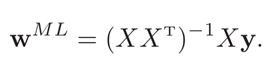
最大后验估计
Lasso是L1回归,岭回归是L2回归
Lasso全称:Least absolute shrinkage and selection operator
先验假设为正态分布的时候相当于L2正则化
先验假设为拉普拉斯分布的时候相当于L1正则化(这里θ应该写成w)(双指数分布)
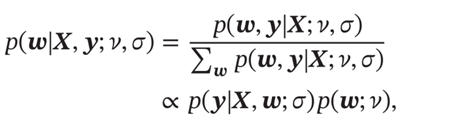


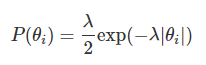
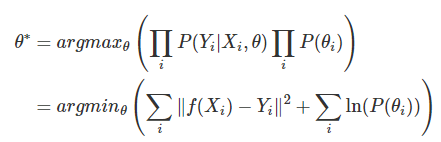
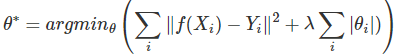
三种:

PAC大数定律:Probably Approximately Correct 大数定律
当训练集大小|D|趋向无穷大时,泛化错误趋向于0,即经验风险趋近于期望风险。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号