


集合
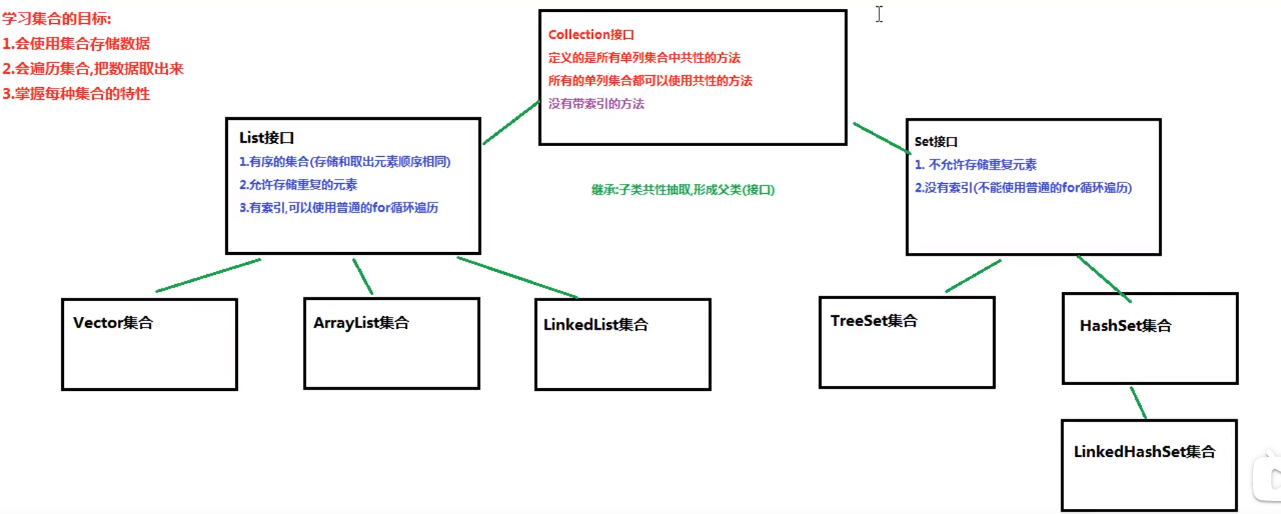
Collection中共用的方法:
- public boolean add(E e):把给定的对象添加到集合中
- public void clear():清空集合中所有的元素
- public boolean remove(E e):把给定的对象在集合中删除
- public boolean contains(E e):判断当前集合中是否包含给定的对象
- public boolean isEmpty():判断当前集合是否为空
- public int size():返回集合中元素的个数
- public Object[] toArray(): 把集合中的元素存储到数组中
Iterator接口:用来遍历和取出集合中的元素
首先要获取到Iterator这个实例,collection集合中有iterator()这个方法,可以直接得到。
Iterator<E> iterator()
返回此集合中元素的迭代器。 对于返回元素的顺序没有任何保证(除非此集合是某个提供保证的类的实例)。
有如下三个方法:
boolean hasNext() 如果迭代具有更多元素,则返回 true 。
E next() 返回迭代中的下一个元素。
default void remove() 从底层集合中移除此迭代器返回的最后一个元素(可选操作)。
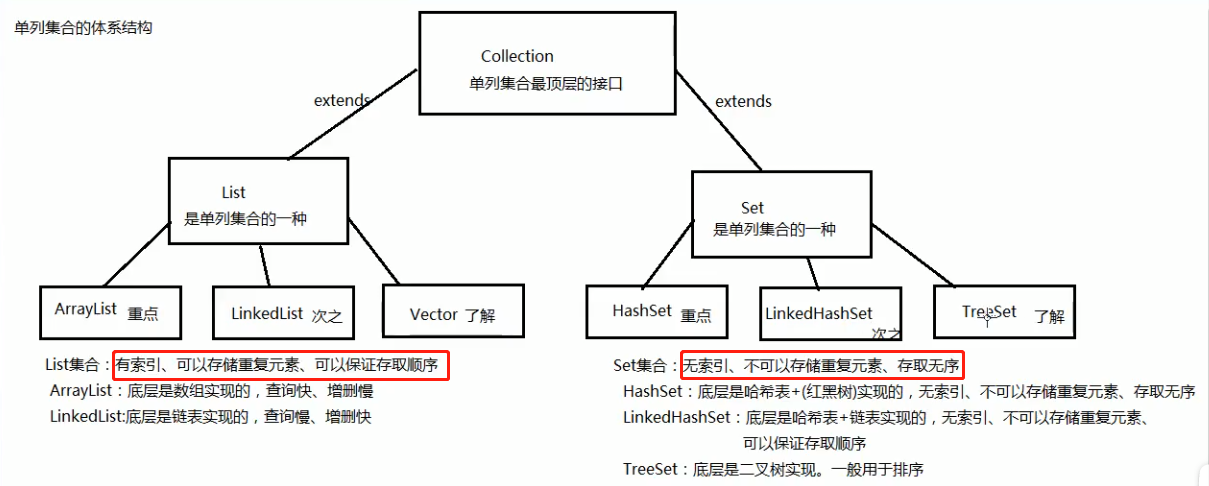
List接口的特点:
- 有序的集合,存储元素和取出元素的顺序是一致的。
- 有索引,包含了一些带索引的方法
- 允许存储重复的元素
List接口中带索引的方法(特有):
- public void add(int index, E element)
- public E get(int index)
- public E remove(int index)
- public E set(int index,E element)
因为LinkedList 增删比较快,所以比ArrayList 多了如下几个方法:
void addFirst(E e) 在此列表的开头插入指定的元素。 相当于 void push(E e)
void addLast(E e) 将指定的元素追加到此列表的末尾。相当于 boolean add(E e)
E removeFirst() 从此列表中删除并返回第一个元素。 E pop(E e)
boolean removeFirstOccurrence(Object o) 删除此列表中第一次出现的指定元素(从头到尾遍历列表时)。
E removeLast() 从此列表中删除并返回最后一个元素。
ArrayList 底层是数组实现的,所以查询快,增删慢。
LinkedList底层是链表实现的,所以查询慢,增删快。
Vector 是1.0版本就出现的线程安全的集合,底层也是数组。
Set接口:
特点:
- 不允许存储重复的元素(存储元素不重复的前提是:存储的元素必须重写hashCode方法和equals方法)
- 没有索引,没有带索引的方法,也不能用普通的for循环遍历(只能使用增强For 和迭代器遍历)

Set<String> set = new HashSet<>(); set.add("123"); set.add("a"); set.add("c"); set.add("a"); Iterator<String> iterator = set.iterator(); while(iterator.hasNext()) { String str = iterator.next(); System.out.println(str); //输出 a 123
} System.out.println("----------"); for(String str:set) { System.out.println(str); //输出 a 123
}
HashSet集合存储数据的结构:
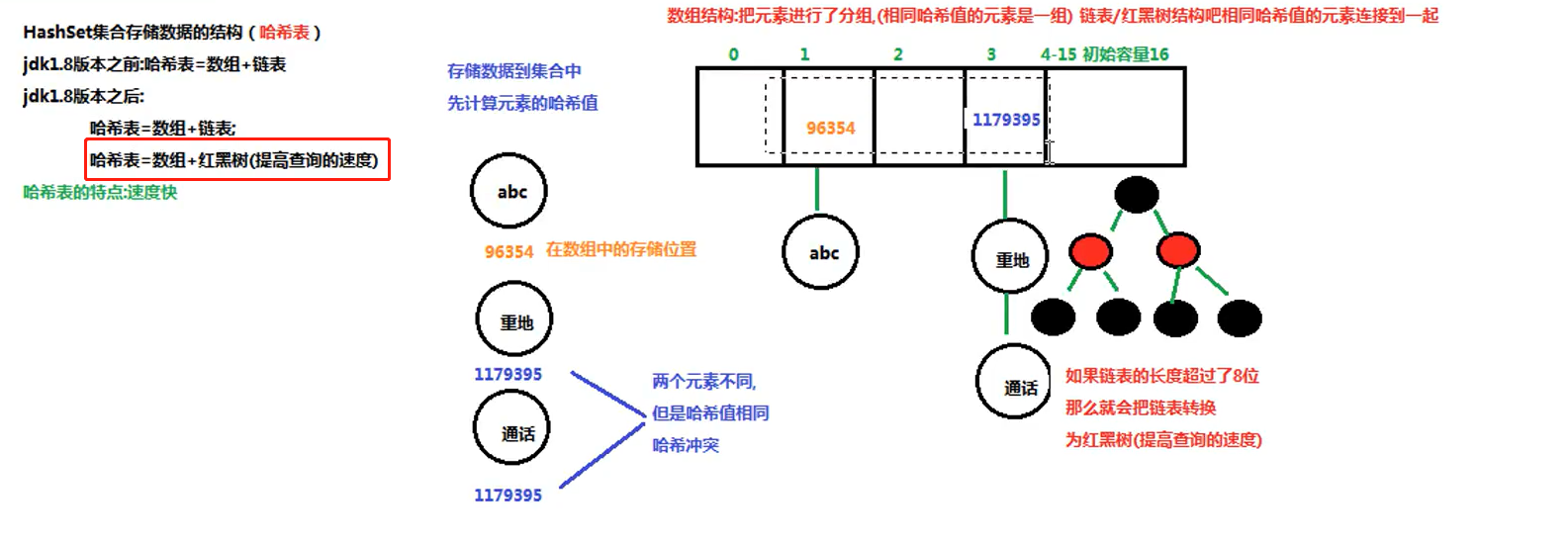
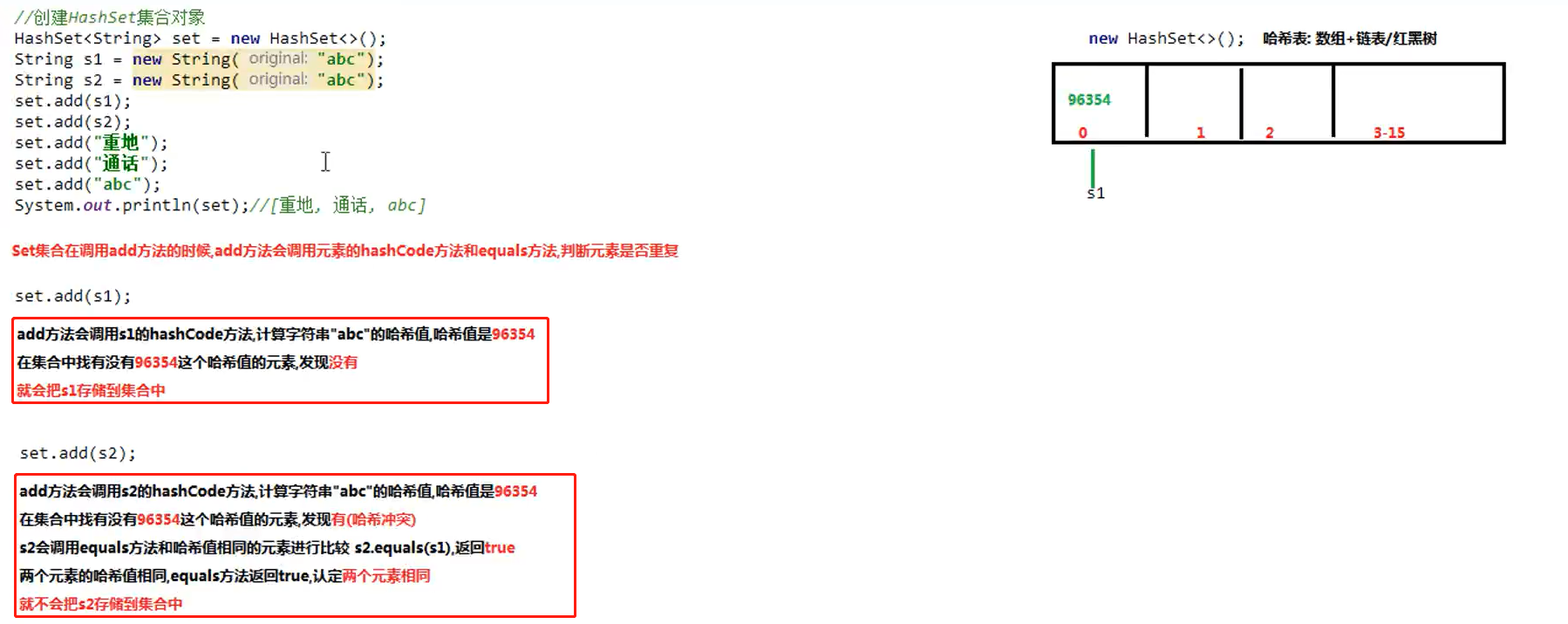
分析HashSet 不能添加重复元素的原因:(首先会在集合中查找元素的哈希值,如果找到相同的哈希值则再去调用equals方法,不同则会加入进去)
HashSet<String> hashSet = new HashSet(); String str1 = new String("abc"); String str2 = new String("abc"); hashSet.add(str1); hashSet.add(str2); hashSet.add("重地"); hashSet.add("通话"); hashSet.add("abc"); for(String str:hashSet) { System.out.println(str);//重地 通话 abc }
HashSet<Person> hashSet = new HashSet(); Person p1 = new Person("张三", 18); Person p2 = new Person("张三", 18); System.out.println(p1.equals(p2));//false hashSet.add(p1); hashSet.add(p2); for(Person p:hashSet) { System.out.println(p.toString());//Person [name=张三, age=18] Person [name=张三, age=18] }
LinkedHashSet特点:不可重复,但有序。

Collections(java.utils.Collections)
常用功能:

ArrayList<String> list = new ArrayList<String>(); Collections.addAll(list, "a","b","c","a"); for(String str:list) { System.out.println(str); }
如果是自定义类则需要实现Comparable接口,然后重写里面的compareTo方法
int compareTo(T o)
public class Person implements Comparable<Person>{ private String name; private int age; @Override public int compareTo(Person o) { // TODO Auto-generated method stub return this.age-o.age;//按年龄升序排序 } } public static void main(String[] args) { Person p1 = new Person("ZS",18); Person p2 = new Person("LS",15); Person p3 = new Person("WW",19); ArrayList<Person> list = new ArrayList(); Collections.addAll(list, p1,p2,p3); Collections.sort(list); for(Person p:list) { System.out.println(p); } }
public static <T> void sort(List<T> list, Comparator<? super T> c)
根据指定比较器引发的顺序对指定列表进行排序。
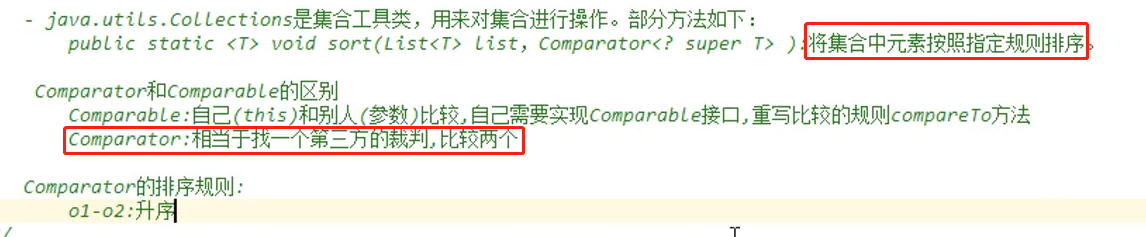
ArrayList<Integer> list = new ArrayList(); Collections.addAll(list, 2,8,7,1,9); //如果需要对list进行逆序排序(自定义排序) Collections.sort(list, new Comparator<Integer>() { public int compare(Integer o1, Integer o2) { return o2-o1; }; }); for(Integer i:list) { System.out.println(i); }
如果想要对集合进行降序排序,可以先调用sort()方法,然后再调用Collections里面的reverse()方法.
Map集合
(键值唯一,键值一一对应)
Map接口下面有HashMap和HashTable,HashMap下面还有一个LinkedHashMap.


Map中常用的方法:
public V put(K key,V value):把指定的键与指定的值添加到Map集合中。返回值:V key不重复,返回值V是null,key重复,会使用新的value替换map中重复的value,返回被替换的value值。
public V remove(Object key):从该集合中删除指定键的映射(如果存在)。 返回值:V key不存在,返回值V是null key存在,V返回被删除的值
public V get(Object key) 返回到指定键所映射的值,key存在,返回对应的value值,key不存在,返回null
public boolean containsValue(Object value):如果此集合将一个或多个键映射到指定的值,则返回 true 。
public boolean containsKey(Object key):如果此映射包含指定键的映射,则返回 true 。
public boolean isEmpty() 如果此集合不包含键值映射,则返回 true 。
public int size() 返回此地图中键值映射的数量。
HashMap集合的遍历:
第一种方式:entrySet()
public static void main(String[] args) { HashMap<String,Integer> map = new HashMap<>(); map.put("a",1); map.put("b",2); map.put("c",3); System.out.println(map.size()); Set<Entry<String,Integer>> set = map.entrySet(); Iterator<Entry<String,Integer>> iterator = set.iterator(); while(iterator.hasNext()) { Entry<String,Integer> entry = iterator.next(); String key = entry.getKey(); Integer value = entry.getValue(); System.out.println(key+"-->"+value); } }
第二种方式:keySet()
//遍历的第二种方式:keySet() Set<String> set = map.keySet(); for(String str:set) { Integer value = map.get(str); System.out.println(str+"-->"+value); }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号