
Oracle数据库索引
[什么是索引]
其实索引的作用就如同图书的目录,我们可以根据目录中的页码快速的找到所需的内容。
在关系型数据库中,索引是一种和表有关的数据结构(一般是树结构例如 Oracle数据库使用B-Tree树算法处理索引; Berkerly DB , sqlite , mysql 数据库都使用了B+树算法处理索引),它们都可以使查询的sql语句执行的更快
编写一本书,只有章节内容定好之后再设置目录;数据库索引也是一样,只有先插入好数据,再建立索引。
[为何索引可提高查询效率]
因为DB在执行一条sql语句的时候,默认的方式是根据搜索条件进行全表扫描,遇到匹配条件就加入搜索结果集合。如果我们对某一字段增加索引,查询时就会先去索引列表中一次定位到特定值的行数,大大减少遍历匹配的行数,所以能明显增加查询的速度。
[索引的类型]

[索引的类型]
1.全表扫描
全表扫描(FULL TABLE SCANS) 时所有行、所有数据快均会被读到,是效率最低的一种,一般会在表缺少索引、读取大量数据、访问小表或高并发时发生
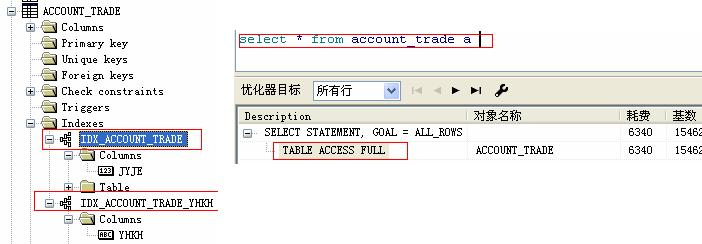
2. ROWID扫描
ROWID扫描是通过rowid中数据文件和块位置访问数据行。一般作为访问索引后的第二步,如果访问的列全部包含在索引中,则不会执行rowid扫描
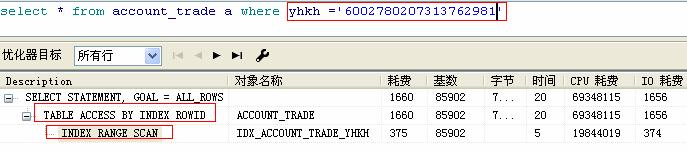
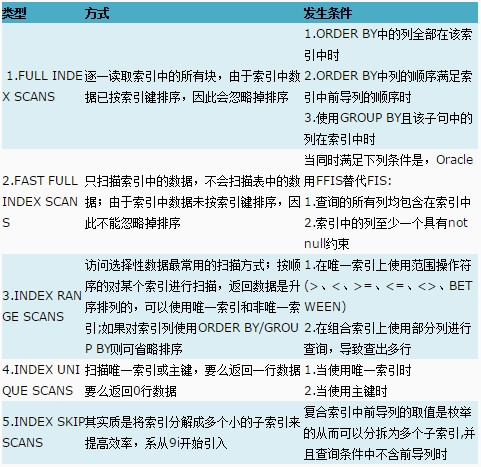
3. 索引扫描
索引扫描包括全索引扫描(full index scan FIS)、快速全索引扫描(fast full index scan FFIS)、索引范围扫描(index range scan)、索引唯一扫描(index unique scan)、索引跳跃式扫描(index skip scan)、
位图索引扫描(bitmap index scan)
[如何创建索引]
创建表:
create table person (id int, sex char(1), name char(10));
创建索引:
create index person_index on person (id);
查看创建的表与索引:
select object_name, object_type from user_objects;
除了可以根据单个字段创建索引,也可以根据多列创建索引:
create index person_index2 on person (sex, name);
删除索引:
drop index person_index;
[创建索引的注意事项]
1. 建立索引的目的是为了提高查询效率,但建立的索引过多会影响插入和删除数据的速度,这是因为我们修改表数据时,索引也要跟着修改,所以创建索引的时候我们需要权衡是查询多还是修改多。
2. 应该创建索引的字段:
① 经常作为查询条件的字段
② 经常用在多表连接的列,例如外键
③ 经常需要排序的字段
3. 应该少建或者不建索引的情况:
① 表中数据太少,增加索引基本不会带来查询速度的提升,反而浪费了存储空间。
② 经常需要插入、修改、删除操作的表
③ 表中数据重复且分布平均的字段(如“性别”)
④ 查询中很少用到不应该创建索引
⑤ 定义为text、image、bit数据类型的列不应该加索引
4. 一些sql的写法会限制索引的使用:
where子句中如果使用in、or、like、!= 、<>均会导致索引不能正常使用,将<>换成>and <,将is not null换成>=chr(0)
[where语句中索引的使用]
1. 索引列上不要使用is null 或 is not null
错误:select column from table where column is not null
正确:select column from table where column >= chr(0)
2. 索引列上不要使用函数:
错误:select column from table where substr(name, 1, 3) = 'ABC'
正确:select column from table where name like 'ABC%' // 避免通配符在词首出现
3. 索引列上不要使用NOT(!=、<>)
错误:select column from table where column != 10
正确:select column from table where column > 10 or column < 10
4. 索引列上不要进行计算
错误:select column from table where column / 10 > 10
正确:select column from table where column > 10 * 10
[索引建立原则]
一般的原则:越离散的字段越靠前。哪个列可以降低索引的扫描成本就放在前面。
由于索引的存储结构是树结构,故查询时使用的条件
因此,最理想的方法就是把拥有最小查询范围的条件作为驱动查询条件来使用。这里的最小查询范围也就意味着满足条件的数据在整体中所占的比重较小。所以,基于什么样的条件来创建索引将对缩减处理范围有着较大的影响。对于特定的读取类型,最有效的索引就是基于常量比较的列来创建的组合索引。
离散度在不超过全表的10%-15%的前提下索引才可以显示其所具有的价值。当离散度超过该值的情况下全表扫描可能反倒比索引扫描更有效。我们所追求的目标就是创建全表扫描所无法比拟的有效索引。
假设某个索引的离散度<1%,很明显小于损益分界点,但是在海量表中也不是个小数目,仍然会对在线处理构成极大的负担。如果基于一个列所创建的索引 无法实现预期目标,那么在不得已的情况下也只能基于多个列来创建组合索引。在各个列的离散度不太好的情况下,可以将这些列进行有效的组合,通过合力的有效 使用可以取得意想不到的效果。
为了实现以最少的索引满足对某个表的多样化的数据读取要求,应当为每个索引分配合理的任务。
1)在允许的情况下,对具有较好离散度的列单独创建索引,这样可以提高该索引的使用弹性;
2)对于离散度较差的列,通过对多列进行合理的组合来创建组合索引,虽然这样做在很大程度上降低了各个列的使用弹性,但是却可以发挥多个列的综合效应。
有时候基于离散度较好的列所创建的索引会与其识别能力比较相似的其他索引进行竞争。
如果很容易就能够分辨出查询条件的优劣,则只需要从中选择最好的一个作为驱动查询条件就可以了;但是如果很难分辨,则需要考虑让多个列相互组合来共同负责数据的读取任务,这就是所谓的索引合并(Index Merge)。
只有当合并的索引具有相似的离散度时索引合并才比较有效,当索引的离散度相差较大时使用索引合并的方法反倒容易影响执行效率。在两个索引行数悬殊的情况下,通常只使用其中最好的一个索引来负责读取数据,而另外的索引只负责检验即可。
在实际工作中,经常会遇到即使列的离散度不好也必须要创建索引的情况,为了解决此类问题而需要创建组合索引(Concatenated Index)。所谓的组合索引是指基于多列所创建的索引。在组合索引中执行索引合并时,由于提前将满足条件的行集集中到了一起,所以可以在很大程度上提高 读取数据的速度。
但是组合索引并非总能提高读取速度。只有在查询条件中对索引列使用了等值比较时组合索引才能够有突出的表现。当没有为组合索引中的第一个索引列赋予查询条件时,使用组合索引的效果会骤减,所以它的使用弹性和灵活性在很多条件下都受到限制。
转载:https://www.cnblogs.com/toby/archive/2012/11/09/2763151.html
转载:https://blog.csdn.net/zdp072/article/details/44203837

 浙公网安备 33010602011771号
浙公网安备 33010602011771号