NaiveBayes
在 scikit-learn 中,一共有3个朴素贝叶斯的分类算法类。分别是 GaussianNB、MultinomialNB 和 BernoulliNB。其中 GaussianNB 就是先验为高斯分布(正态分布)的朴素贝叶斯,MultinomialNB 就是先验为多项式分布的朴素贝叶斯,而 BernoulliNB 就是先验为伯努利分布的朴素贝叶斯。
这三个类适用的分类场景各不相同,一般来说:
- 如果样本特征的分布大部分是连续值,使用 GaussianNB 比较好
- 如果样本特征的分大部分是多元离散值,使用 MultinomialNB 比较合适
- 如果样本特征是二元离散值或者很稀疏的多元离散值,应该使用 BernoulliNB
GaussianNB 假设特征的先验概率为正态分布:
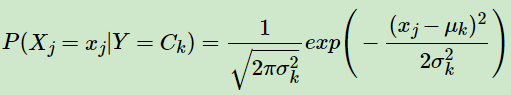
其中\(C_k\)为Y的第k类类别。\(μ_k\)和\(σ^2_k\)为需要从训练集估计的值。
GaussianNB 会根据训练集求出\(μ_k\)和\(σ^2_k\)。 \(μ_k\)为在样本类别\(C_k\)中,所有\(X_j\)的平均值。\(σ^2_k\)为在样本类别\(C_k\)中,所有\(X_j\)的方差。
在使用 GaussianNB 的 fit 方法拟合数据后,可以进行预测。此时预测有三种方法,包括 predict,predict_log_proba 和 predict_proba。
- predict方法就是我们最常用的预测方法,直接给出测试集的预测类别输出。
- predict_proba则不同,它会给出测试集样本在各个类别上预测的概率。容易理解,predict_proba预测出的各个类别概率里的最大值对应的类别,也就是predict方法得到类别。
- predict_log_proba和predict_proba类似,它会给出测试集样本在各个类别上预测的概率的一个对数转化。转化后predict_log_proba预测出的各个类别对数概率里的最大值对应的类别,也就是predict方法得到类别。
import numpy as np
from sklearn.naive_bayes import GaussianNB
# X是数据,Y是对应的Labels
X=np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]])
Y = np.array([1, 1, 1, 2, 2, 2])
clf=GaussianNB()
# 使用fit拟合数据--》就是学习X,Y
clf.fit(X,Y)
# 学习完毕
# 开始测试
# 使用三种预测方法:predict,predict_proba和predict_log_proba。
# 三者的 参数是一个array-like of shape --->(n_samples, n_features)
# ①predict的预测是一个类
print("==Predict result by predict==")
c1=clf.predict([[-0.8,-1]])
print(c1) #[1]--》predict此数据是label为1
# ②predict_proba预测是一个概率(给出测试集样本在各个类别上预测的概率)
print("==Predict result by predict_proba==")
c2=clf.predict_proba([[-0.8,-1]]) #[[9.99999949e-01(是label为1的概率) 5.05653254e-08(是label为2的概率)]]
print(c2)
# ③predict_log_proba预测(它会给出测试集样本在各个类别上预测的概率的一个对数转化)
print("==Predict result by predict_log_proba==")
c3=clf.predict_log_proba([[-0.8,-1]]) #[[-5.05653266e-08 -1.67999998e+01]]
print(c3)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号