

Storm入门(1)--概念及部署
前面介绍了流计算,在流计算领域,一个热门的计算框架就是-Storm。还是先介绍概念。。。
一、Storm是什么
在流处理过程中,我们除了考虑最重要的数据处理的逻辑,还需要维护消息队列和消费者,考虑消息怎么流、怎么序列化等。而Storm就是这样一个流式计算框架,它为你完成了消息传递等这些通用模块,让你专注于实时处理的业务逻辑。
Storm--一种分布式实时计算系统。Storm之于流计算,类似于Hadoop之于批处理。Storm可以简单、高效、可靠的处理流数据,它提供了简单的编程原语,并且支持多种语言,开发人员只需要关注业务逻辑。可以应用到很多领域,例如实时分析、在线机器学习、分布式RPC、ETL等。
下面进一步了解下Storm
二、Storm设计思想
在Storm里面包含几个组件:Streams, Sputs ,Bolts, Topology,Stream Groupings。
1、Streams(流)
Streams是Storm对数据的抽象。Storm处理的数据对象是“流数据”,流数据是一个无限的Tuple序列,这些Tuple序列会以分布式的方式并行创建和处理。
熟悉Python的同学可能对Tuple(元组)更容易理解一些,它就是一个元素的有序序列,每一个Tuple就是一个值列表,列表里的值的类型没有严格的规定,可以是基本类型、字符类型、字节数组也可以是其他可序列化的类型。
2、Spouts(喷口)
Spouts是Storm对数据源头的抽象。Spouts是stream的源头,从外部读取流数据并持续发出Tuple。
3、Bolts(螺栓)
Bolts是Storm对stream的状态转换过程的抽象。Bolts既可以处理tuple,也可以把处理以后的tuple作为新的streams发送给其他的bolts。对tuple的处理逻辑都被封装在bolts中,在bolts中可以对数据执行过滤、聚合、查询等操作。
4、Topology(拓扑)
Topology是Storm对Spouts和Bolts组成的网络的抽象。Topology是Storm中最高层次的抽象概念,可以被提交到Storm集群执行。一个Topology就是一个流转换图,图中的节点是Spouts或Bolts,图中的边表示Bolts订阅了哪个Stream。当Spout或bolt发送元组的时候,会把元组发送到每个订阅了该stream的bolt上进行处理。
topology支持通过各种编程语言来创建、提交topology。
5、Stream Groupings
Stream Groupings是Strom对组件之间tuple传送方式的抽象,用于告知topology如何在两个组件之间进行tuple的传送(组件之间可以是spout和bolt之间或者不同bolt之间)。stream groupings决定了一个任务在什么时候、以什么形式发送tuple。
Storm中的stream gouping有以下6种方式。
shuffleGrouping:随机分组,把stream中的tuple随机分发给各个bolts的task
fieldsGrouping:按字段分组,相同字段的tuple分配到同一个task中
all Grouping:广播发送,每个task收到所有的tuple
globalGrouping:全局分组,所有的tuple都发送到同一个task中
nonGrouping:不分组,和shuffleGrouping类似,当前task的执行和它的被订阅者在同一个线程中执行
directGrouping:直接分组,直接指定某个task来执行tuple的处理。
三、Storm框架设计
对于Strom框架的理解,类比着hdp可能会更容易理解些。
Strom运行在分布式集群中,我们可以类比下hadoop,hdp上运行的是MR作业,Storm上运行的是Topology。不过MR是有限的,会结束,但是topology会对数据进行持续处理,直到人为终止。
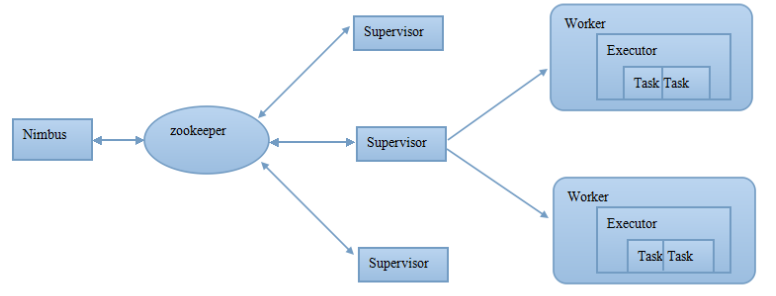
从集群物理结构来看,一个Storm集群包含Master节点和Worker节点。
Master节点
--Master节点上运行Nimbus后台程序,类似MR中的JobTracker。负责集群内代码的分发、worker任务的分配和故障监测。
Worker节点
--Worker运行Supervisor后台程序,负责监听分配给当前机器的工作,根据Nimbus分配的任务来启动或停止worker进程。每个supervisor有n个worker进程,负责代理task给worker进程,worker再孵化执行线程最终运行task。
worker负责执行特定的task,worker本身不执行任务,而是孵化executors,让executors执行task;executor本质上是worker进程孵化出来的线程,executor运行task都属于同一spout或bolt。task是实际执行的任务处理,或者是Spout或者是Bolt。
节点间通信
--storm使用内部消息系统在nimbus和supervisor之间进行通信。
master和worker之间不会直接交互,为了实现master和worker之间的协同,采用zookeeper作为协调组件。zk中存储master和worker的状态信息,以便节点故障时根据zk中状态信息进行快速恢复,保证storm的稳定性。
接下来从架构组件的角度总结下Strom架构:
Nimbus--Storm的核心组件,分析top并收集运行task,分发task给supervisor;监控top;无状态,依靠zk监控top的运行状况
Supervisor--每个supervisor有n个worker进程,负责代理task给worker;worker再孵化执行线程,最终运行task
Worker--执行特定的task,worker本身不执行任务,而是孵化executors,让executors执行task。
Executor--本质上是由worker进程孵化出来的线程;executor运行task都属于同一个spout或bolt。
Task--执行实际上的任务处理,或者spout或bolt
在这样的架构下,storm的工作流程如下图
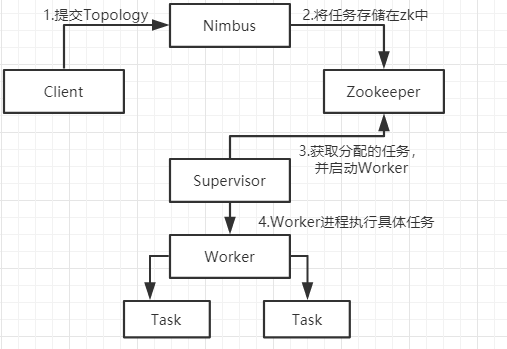
1、client把topology提交到storm集群
2、提交topo后nimbus收集task
3、Nimbus分发task,把分配给Supervisor的task写入zk
4、Supervisor周期性发送心跳表示自己还活着,如果Supervisor挂掉,nimbus将task分发给其他supervisor
5、Supervisor从zk中获取所分配的任务,启动worker进程,woker进程执行任务。
6、task完成后,supervisor等待新的task
7、如果nimbus挂掉,supervisor继续执行自己的task,task完成后,supervisor继续等待新的task
可靠性(Reliability)
Storm保证了拓扑中Spout产生的每个元组都会被处理。Storm是通过跟踪每个Spout所产生的所有元组构成的树形结构并得知这棵树何时被完整地处理来达到可靠性。每个拓扑对这些树形结构都有一个关联的“消息超时”。如果在这个超时时间里Storm检测到Spout产生的一个元组没有被成功处理完,那Sput的这个元组就处理失败了,后续会重新处理一遍。
为了发挥Storm的可靠性,需要你在创建一个元组树中的一条边时告诉Storm,也需要在处理完每个元组之后告诉Storm。这些都是通过Bolt吐元组数据用的OutputCollector对象来完成的。标记是在emit函数里完成,完成一个元组后需要使用ack函数来告诉Storm。
这些都在“保证消息处理”一文中会有更详细的介绍。
Workers(工作进程)
拓扑以一个或多个Worker进程的方式运行。每个Worker进程是一个物理的Java虚拟机,执行拓扑的一部分任务。例如,如果拓扑的并发设置成了300,分配了50个Worker,那么每个Worker执行6个任务(作为Worker内部的线程)。Storm会尽量把所有的任务均分到所有的Worker上。
四、Storm完全分布式安装部署
4-1 安装zk
4-2 安装storm
1、到storm官网下载安装包,并解压
2、为storm配置环境变量 vim /etc/profile
export STORM_HOME=/usr/local/storm
export PATH=$PATH:${STORM_HOME}/bin
使配置生效 source /etc/profile
3、配置storm
进入storm安装目录下conf文件夹,修改配置文件 vim storm.yaml
配置项如:
#zookeeper集群,注意空格,必须使用space,不可使用制表符 # - 与 " 之间留有空格 storm.zookeeper.servers: - "192.168.119.141" - "192.168.119.142" - "192.168.119.143" #nimbus设置两台机器,最好使用主机名,使用IP在webui界面会出现重复节点 nimbus.seeds: ["hadoop-01","hadoop-02"] #设置slots端口 supervisor.slots.sport: - 6700 - 6701 - 6702 - 6703 #设置UI的端口,默认8080,避免与tomcat端口重复 ui.port: 8082
4、将storm拷贝到集群内其他节点上
5、启动storm
nimubs节点上,
storm nimbus >/dev/null 2>&1 & storm ui >/dev/null 2>&1 &
supervisor节点上,
storm supervisor >/dev/null 2>&1 &
执行jps 命令
在没有运行任务时,我们必须应该要看到4个进程:
QuorumPeerMain、nimbus、core、supervisor
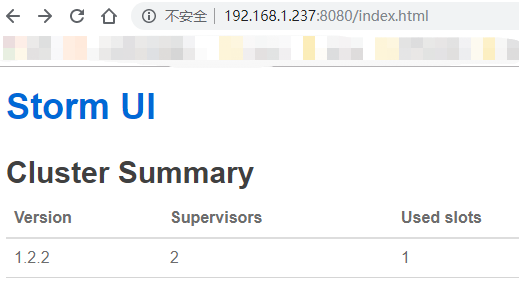
这样之后就可以在浏览器内通过访问 nimbus_IP/8020 查看集群情况
6. 启动logviewer(可选)
在所有从节点执行"nohup bin/storm logviewer >/dev/null 2>&1 &"启动log后台程序,并放到后台执行。
(nimbus节点可以不用启动logviewer进程,因为logviewer进程主要是为了方便查看任务的执行日志,这些执行日志都在supervisor节点上)。
参考: https://blog.51cto.com/xpleaf/2097682
https://blog.csdn.net/weixin_41715878/article/details/87912103
https://www.cnblogs.com/cstzhou/p/4710708.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号