第三周学习
1. 磁盘存储术语总结和理解.
1.1、磁盘物理结构相关(机器硬盘)
- 扇区:磁道的细分单位(通常为512字节或4KB),是磁盘最小的物理存储单元。
- 磁道:盘片上的同心圆环,数据存储在磁道上。
- 盘片:磁盘中存储数据的圆形磁性盘片,通常由玻璃或铝合金制成,表面覆盖磁性材料。
- 柱面:所有盘片同一半径位置的磁道组成的圆柱形结构,提升多磁头并行读写效率。
- 磁头:悬浮在盘片上方,用于读取或写入数据的微型电磁装置。
1.2 、存储技术分类
| 磁盘类型 | 原理 | 优劣势 | 使用场景 |
|---|---|---|---|
| 机器硬盘 | 依赖旋转盘片和磁头进行数据读写 | 价格相对便宜,读写速度慢,寿命长 | 适合需要持久化保存的数据和数据备份 |
| 固态硬盘 | 闪存芯片 | 读写速度快、功耗低,但寿命有限 | 做系统盘使用 |
1.3、存储管理技术
1、RAID
磁盘阵列技术,通过组合多块磁盘提升性能或冗余
2、LVM
逻辑卷管理,允许动态调整磁盘分区大小和组合多块物理磁盘。
1.4文件系统和分区
分区:
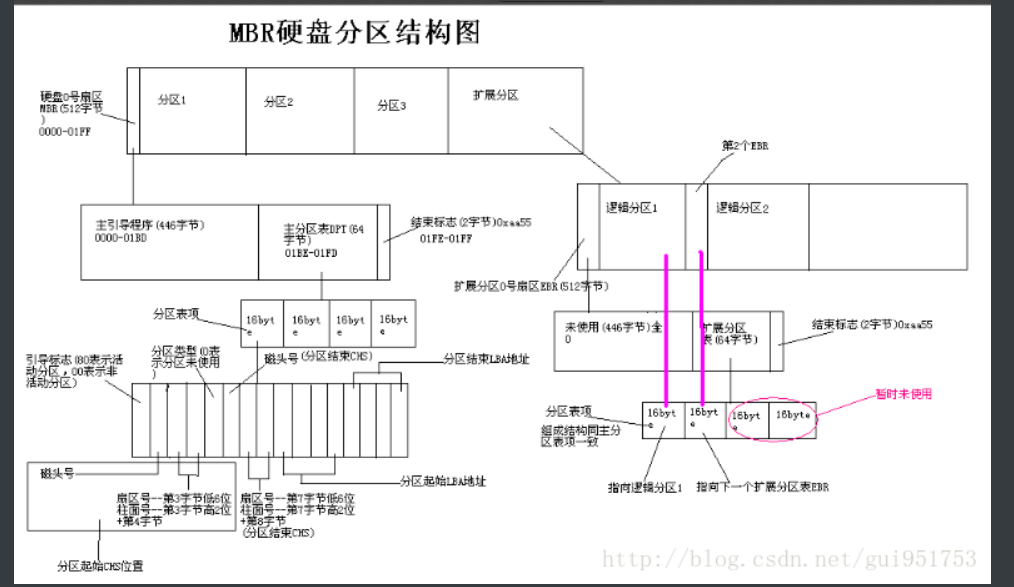
- MBR
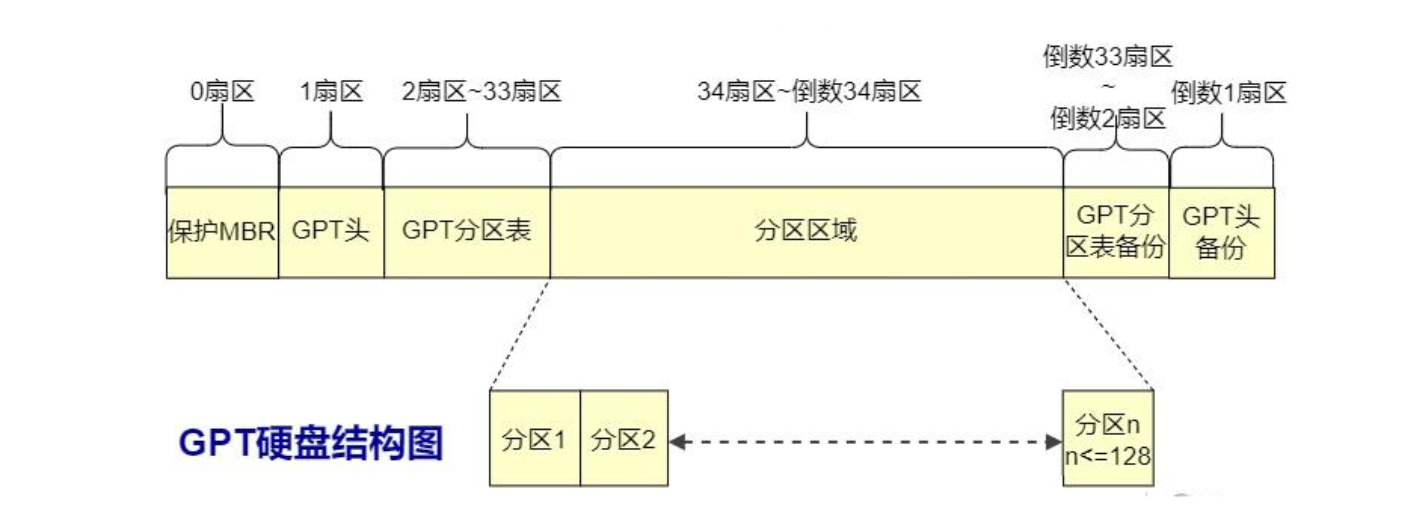
传统分区表格式,支持最大2TB磁盘和4个主分区。 - GPT
现代分区表格式,支持更大磁盘(如18EB)和更多分区
文件系统: - NTFS:Windows默认,支持大文件和权限控制。
- ext4:Linux常用,日志式文件系统。
- APFS:Apple专用,针对SSD优化。
- FAT32/exFAT:跨平台兼容,适合U盘
2. 总结MBR,GPT结构区别。
2.1结构组成
- MBR
位置:磁盘的第一个扇区(0号扇区)
内容:
引导代码(446字节):用于启动操作系统
分区表(64字节):一个主分区固定占用16字节,所以最多只能记录4个主分区;
若需更多分区,需使用扩展分区(Extended Partition)和逻辑分区(Logical Partition)。
结束标志(2字节,0x55AA)
- GPT:
位置:
保护性MBR(第1个扇区):兼容旧系统,防止误识别为未格式化磁盘。
GPT头(第2个扇区):包含磁盘GUID、分区表位置、备份头位置及CRC校验码。
分区表(后续多个扇区):默认支持 128个主分区(可扩展),每个分区条目128字节,包含GUID、名称、起止地址等元数据。
备份分区表与GPT头:存储在磁盘末端,提高容错能力。
2.2、分区容量限制
- MBR:使用32位LBA(逻辑块地址),最大支持 2TB 的磁盘。超过此容量,剩余空间无法被识别
- GPT:使用64位LBA,理论支持最大 9.4ZB(1 ZB = 1亿TB),满足现代大容量存储需求
2.3、安全性和可靠性
* MBR:
无校验机制,分区表损坏可能导致数据丢失
依赖单一备份,恢复困难。
- GPT:
支持 CRC32校验(检测数据完整性)
提供备份分区表与GPT头,可自动修复损坏
支持分区属性标记(如“只读”或“隐藏”)
2.4、适用场景
- MBR:
旧硬件(传统BIOS)
小容量硬盘(≤2TB)
需兼容老旧系统(如Windows XP) - GPT:
新硬件(UEFI固件)
大容量硬盘(>2TB)
需多分区(如服务器、工作站)
要求高数据安全性与恢复能力
2.5、总结对比表
| 特性 | MBR | GPT |
|---|---|---|
| 最大磁盘容量 | 2TB | 9.4ZB(理论值) |
| 最大主分区数 | 4个(扩展分区支持逻辑分区) | 默认128个 |
| 兼容性 | 传统BIOS与所有系统 | UEFI + 现代系统(数据分区通用) |
| 安全性 | 无校验机制 | CRC校验 + 备份分区表 |
| 适用场景 | 旧硬件、小容量磁盘 | 新硬件、大容量磁盘、高可靠性需求 |
3. 总结学过的分区,文件系统管理。
3.1 磁盘分区
一、磁盘分区核心概念
1、分区的定义
- 将物理磁盘划分为多个逻辑单元,每个单元视为独立磁盘,用于安装系统、存储数据或隔离用途。
2、分区表的作用
- 记录磁盘分区的起始位置、大小、类型等信息,操作系统通过分区表识别和管理分区。
二、磁盘分区的类型
1、主分区
- 特点:
- 可安装操作系统(如Windows系统盘通常为主分区)。
- MBR磁盘最多支持4个主分区,GPT磁盘无数量限制。
- 限制:若使用MBR磁盘且需更多分区,必须使用扩展分区。
2、扩展分区
- 特点
- 本身不直接存储数据,仅作为逻辑分区的“容器”。
- 每个MBR磁盘只能有1个扩展分区(占主分区名额)。
- 逻辑分区
- 在扩展分区内创建,数量不限(具体受操作系统限制,如Windows支持128个)
- 用于存储普通数据(如D盘、E盘)
三、分区表类型对比(MBR vs GPT)
| 特性 | MBR | GPT |
|---|---|---|
| 兼容性 | 旧系统(如Windows XP)支持 | 需64位系统 + UEFI启动(Windows 8+推荐) |
| 最大磁盘容量 | 2TB | 理论18EB(支持超大磁盘) |
| 分区数量 | 4个主分区,或3主分区+1扩展分区 | 128个分区(Windows默认限制) |
| 数据安全性 | 分区表单一备份,易损坏 | 多备份分区表,支持CRC校验,更可靠 |
| 典型应用 | 旧电脑、小容量硬盘 | 新电脑、大容量硬盘(尤其是超过2TB的磁盘) |
四、高级分区方案
LVM(Linux逻辑卷管理)
- 动态调整分区大小,支持逻辑卷组合多个物理磁盘。
RAID分区
- 通过硬件或软件实现磁盘阵列(如RAID 0加速、RAID 1备份)。
3.2、文件系统管理
- Windows常用
- NTFS:支持大文件、权限控制、日志功能(推荐系统盘)。
- FAT32:兼容性强(U盘、跨平台),但单文件不能超过4GB。
- exFAT:无4GB限制,适合移动存储设备(如SD卡)。
- Linux常用
- ext4:主流日志文件系统,支持大容量存储。
- XFS:高性能,适合大文件处理。
- swap分区:用作虚拟内存(类似Windows的页面文件)。
- macOS常用
- APFS:苹果专用,优化SSD性能,支持加密和快照。
- HFS+:旧版macOS文件系统。
- 跨平台共享
- 使用exFAT或FAT32(NTFS在macOS下需额外驱动)。
4. 总结raid 0, 1, 5, 10, 01的工作原理。总结各自的利用率,冗余性,性能,至少几个硬盘实现。
| RAID 类型 | 工作原理 | 利用率 | 冗余性 | 性能 | 最少硬盘数 |
|---|---|---|---|---|---|
| RAID 0 | 数据条带化(分块并行读写),无冗余机制 | 100% | 无冗余,单盘故障数据全毁 | 读写性能最高(并行操作) | 2+ |
| RAID 1 | 数据镜像(完全复制到两块硬盘) | 50% | 高冗余(单盘故障不影响运行) | 写入性能较低(需同步镜像),读取性能较高(可并行读) | 2+ |
| RAID 5 | 分布式奇偶校验(数据块与校验信息分散存储) | (N-1)/N(如 3 盘利用率为 66.7%) | 单盘容错(校验恢复) | 读取接近 RAID0,写入略低(需计算校验) | 3+ |
| RAID 10 | 先镜像再条带化(RAID 1 + RAID 0),每组镜像独立存储 | 50% | 高冗余(每组镜像允许单盘故障) | 读写性能优异(兼顾并行与镜像) | 4+(偶数) |
| RAID 01 | 先条带化再镜像(RAID 0 + RAID 1),单条带故障即全组失效 | 50% | 低冗余(条带故障导致数据全毁) | 性能与 RAID10 接近,但可靠性更低 | 4+(偶数) |
4.1、RAID 0
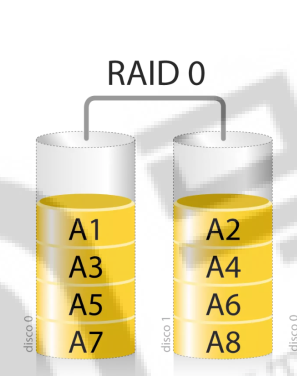
RAID 0将一块数据分割成多个部分,每块磁盘存储总数据的一部分,数据并行处理,读写效率高;但是由于没有数据备份,只要其中任意一块磁盘损坏,总数据丢失,安全性低。
4.2、RAID 1
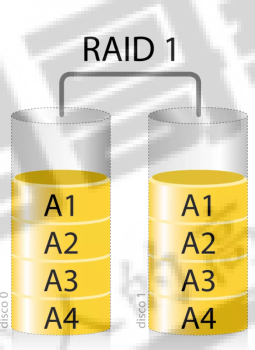
RAID 1将一块数据同时写入两块磁盘,其中一块磁盘作为数据备份。其中任意一块磁盘损坏不影响数据的使用,安全性高
4.3、RAID 5
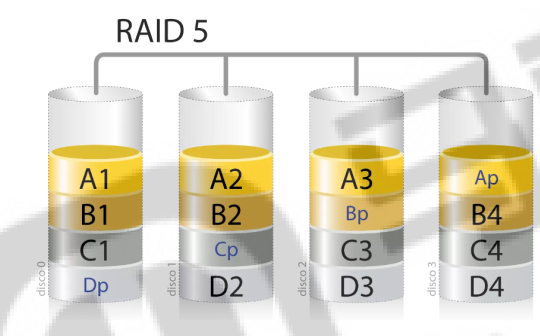
RAID 5也称为分布式奇偶校验(Distributed Parity),它将数据和奇偶校验信息分散在多个磁盘上。RAID 5可以容错一个磁盘的故障,同时提供较高的读写速度和磁盘利用率。它是目前综合性能最佳的数据保护解决方案之一,广泛应用于数据中心等场景
如上图,Dp,Cp,BP,Ap是我们的校验值,任意的A1-A4,B1-B4,C1-C4,D1-D4一块磁盘数据损坏后,我们都可以利用奇偶校验信息重新恢复数据
4.4、RAID 10
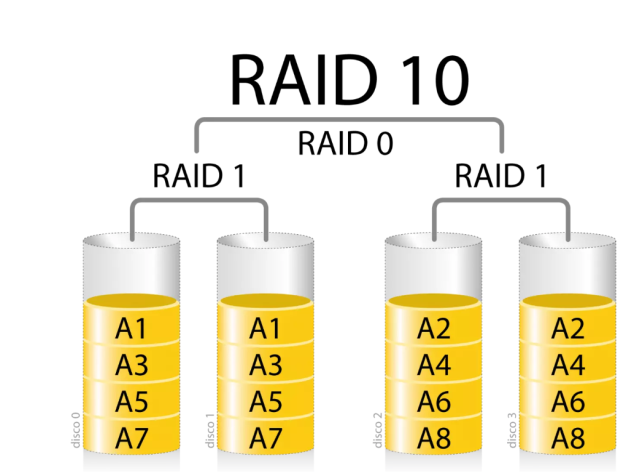
两个RAID1组成一个RAID10
RAID-10也被称为RAID 1+0,是RAID 1与RAID 0的结合体。它首先创建多个RAID 1镜像对,然后将这些镜像对组合成一个RAID 0阵列。这种结构既提供了RAID 0的高性能,又具备了RAID 1的数据冗余和容错能力。由于采用了RAID 0的条带化技术,RAID-10能够并行读写多个磁盘,从而显著提高数据传输速度。
4.5、RAID 01
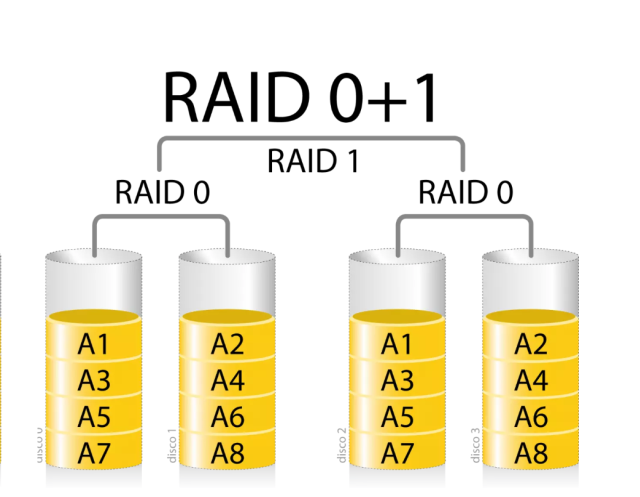
RAID-01也被称为RAID 0+1,是先将多个硬盘组合成RAID 0阵列,然后再对这些RAID 0阵列进行镜像。这种结构相对复杂,且在实际应用中较少见。RAID-01通过RAID 0阵列实现了数据的条带化存储,从而提高了数据传输速度。然而,由于镜像操作的存在,其整体性能可能略低于纯RAID 0阵列。
5. 总结LVM的基本原理,完成实验对LVM的创建和磁盘扩容。
5.1、LVM原理
LVM(逻辑卷管理)是 Linux 系统中用于动态管理磁盘空间的工具,通过抽象层将物理存储设备与逻辑存储分离,
提供灵活的容量调整、快照、备份等功能。其核心原理可分为以下层级结构:
1、核心组成
LVM 架构包含 物理存储层、逻辑抽象层 和 文件系统层:
| 层级 | 组件 | 作用 |
|---|---|---|
| 物理存储层 | 物理卷PV | 将物理磁盘(如 /dev/sda1)初始化为 LVM 可管理的存储单元。 |
| 逻辑抽象层 | 卷组VG | 聚合多个 PV 为统一存储池,支持动态扩展或缩减。 |
| 逻辑抽象层 | 逻辑卷LV | 从 VG 中划分的逻辑存储空间(如 /dev/vg01/lv_data),可挂载为文件系统。 |
| 文件系统层 | 文件系统(如 ext4、xfs) | 在 LV 上创建文件系统,供用户或应用程序使用。 |
2、 关键技术原理
2.1、物理卷(PV)与物理区域(PE)
- PV 由 物理区域(PE, Physical Extent) 组成,每个 PE 是固定大小的数据块(默认 4MB)
- PE 是 LVM 的最小存储单位,所有 PV 的 PE 大小需一致
2.2、 卷组(VG)的资源池化
- VG 将多个 PV 的空间合并为一个虚拟存储池,屏蔽底层物理设备差异。
- 支持随时向 VG 中添加或删除 PV,实现存储资源的动态扩展。
2.3、 逻辑卷(LV)的灵活性
- LV 从 VG 中分配空间,可动态调整大小(扩容/缩容),无需停机
- LV 空间由 逻辑区域(LE, Logical Extent) 组成,每个 LE 对应一个 PE
- 支持高级功能:快照、镜像、条带化等
3、LVM 核心优势
1、动态存储管理
- 在线调整 LV 大小,无需重新分区或重启系统。
2、存储资源池化 - 整合多块磁盘的空间,统一分配管理。
3、灵活的容量扩展 - 通过添加新磁盘扩展 VG,LV 可突破单物理盘容量限制。
4、高可用性与备份 - 快照功能支持快速备份与恢复。
4、LVM vs 传统分区
| 特性 | 传统分区 | LVM|
|---|---|---|---|
| 容量调整 | 需重新分区,可能丢失数据| 可能丢失数据 动态调整,无需停机 |
| 存储池化 | 单块磁盘独立管理 | 多磁盘合并为统一资源池 |
| 最大分区数 | 受分区表限制(如 MBR 最多4主分区 | 理论无限制(由 VG 容量决定) |
| 适用场景 | 简单存储需求 | 需要灵活扩展或复杂存储管理的场景 |
总结
LVM 通过 物理卷→卷组→逻辑卷 的三层抽象,实现了存储资源的动态管理与高效利用,
是服务器、虚拟机和大规模存储场景中的关键技术。
5.2、LVM实例创建
1、添加5块硬盘
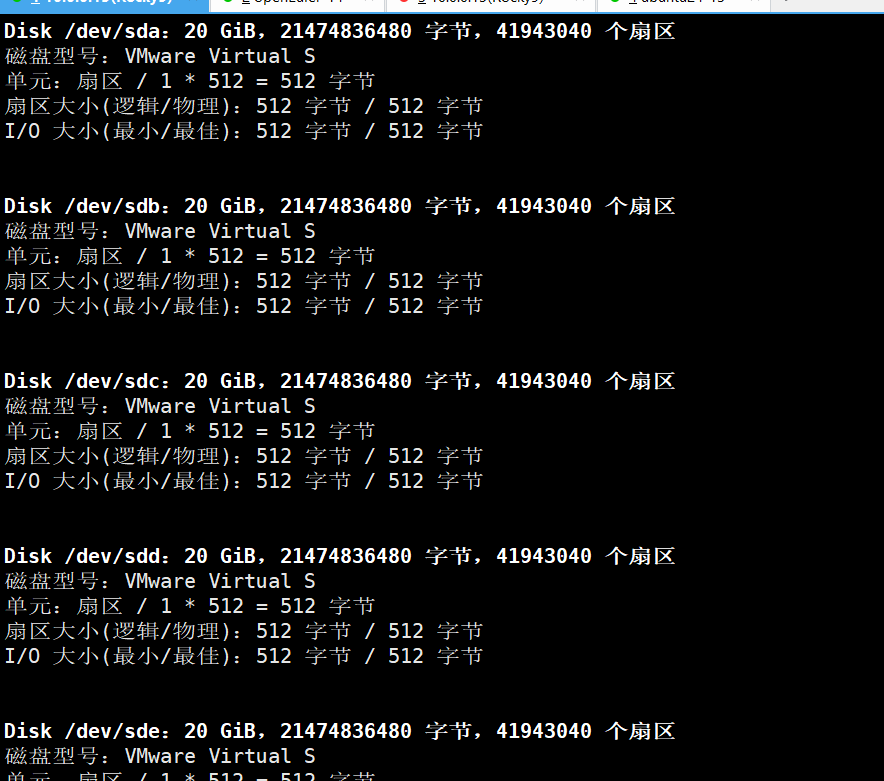
2、创建PV物理卷

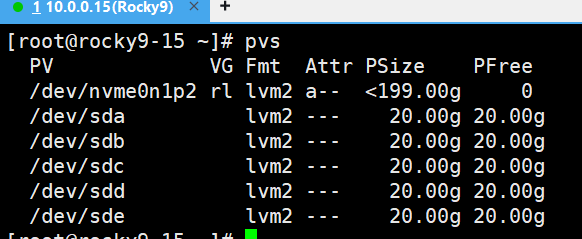
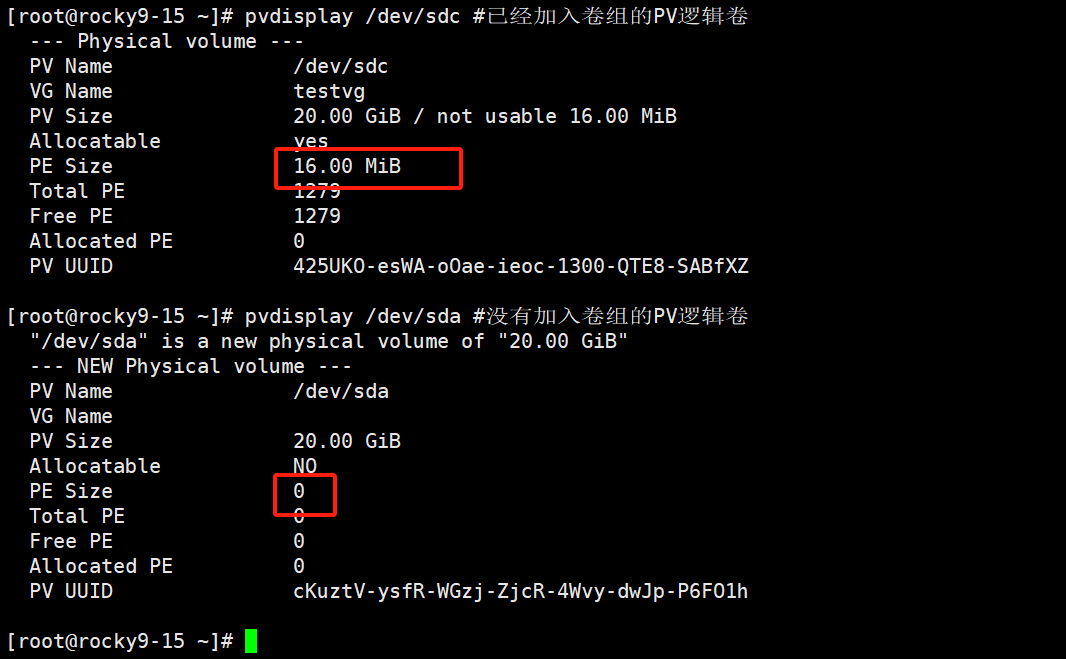
3、创建VG卷组

然后查看下PV的PE大小
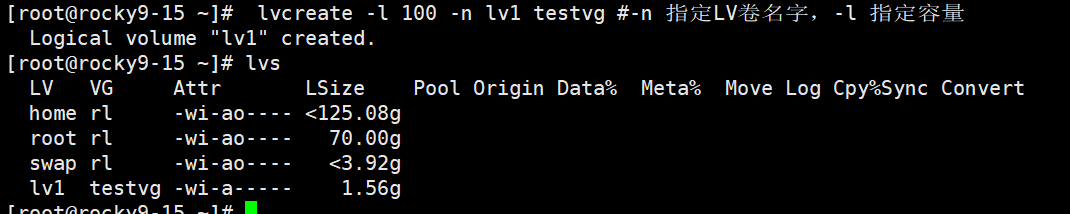
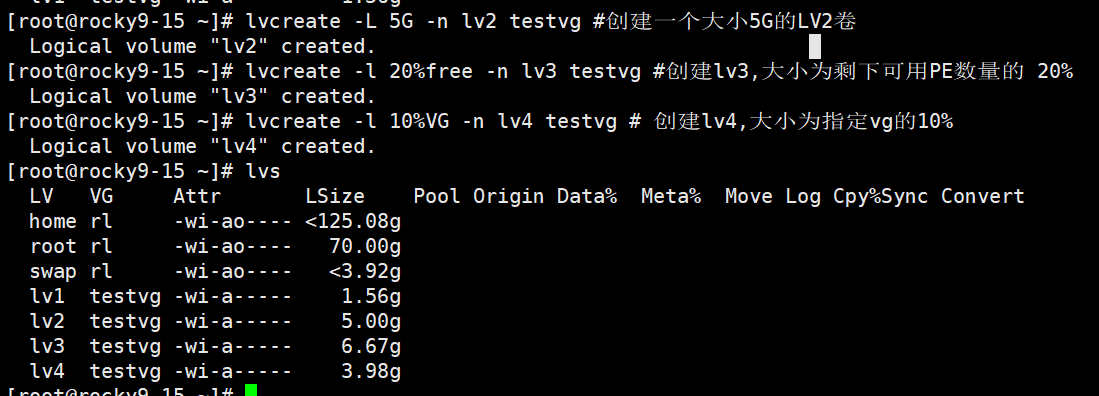
4、创建LV
5、应用lv环境
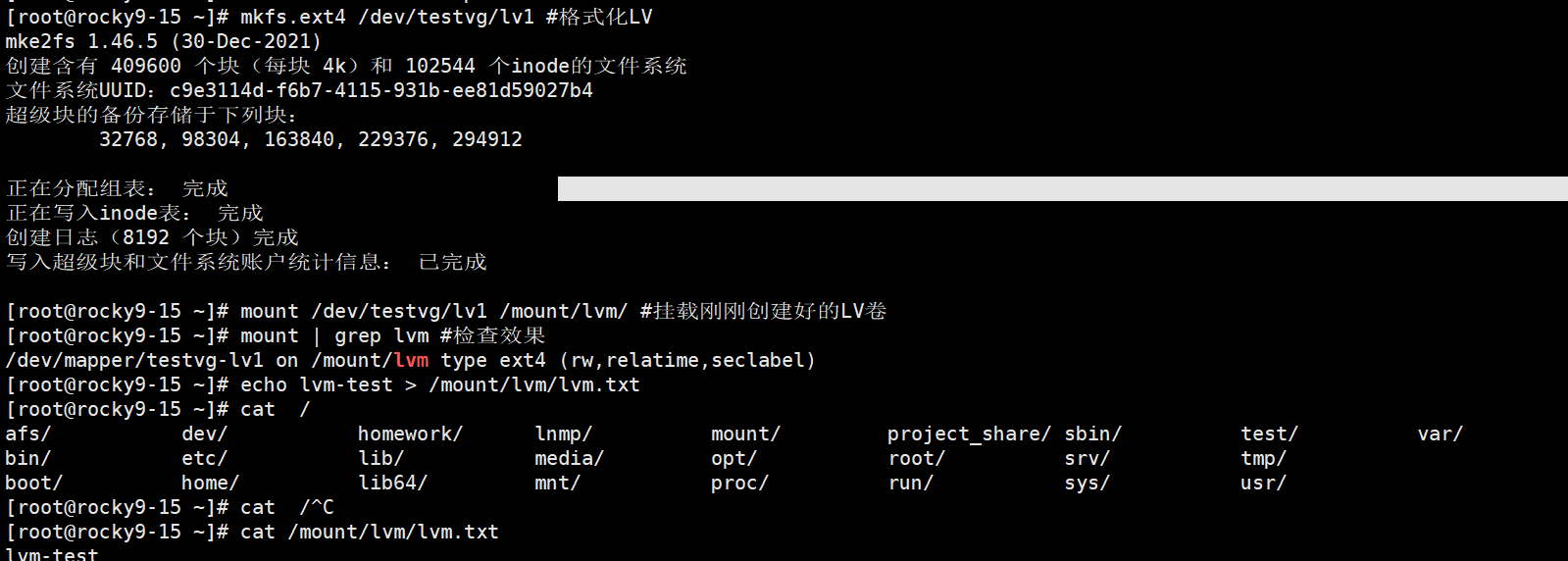
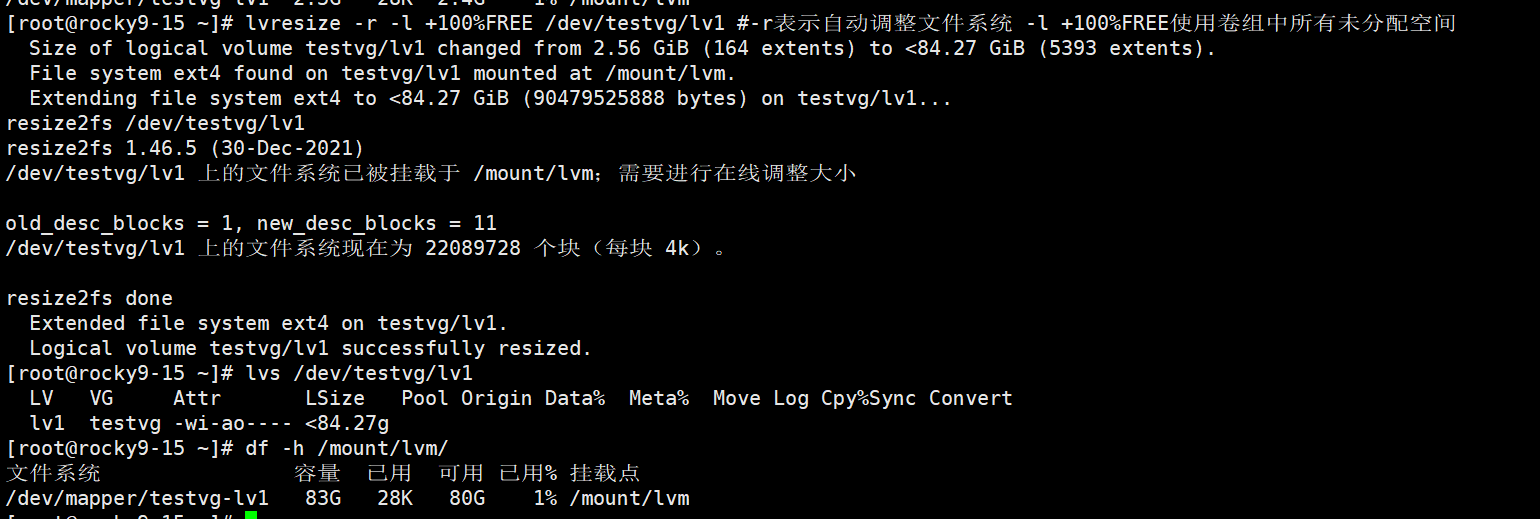
6、LV的动态扩容
我们先将VG卷组池扩容
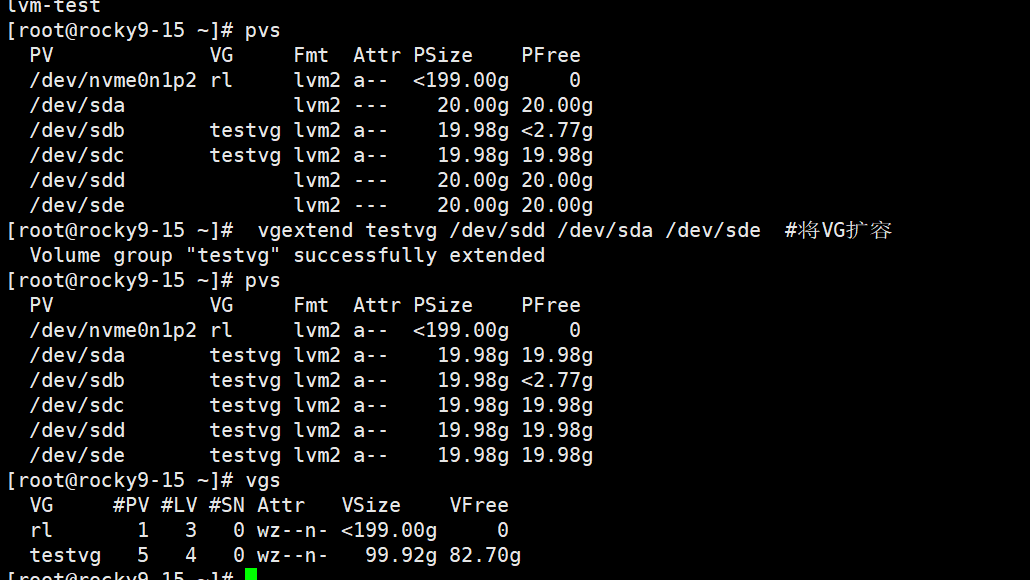
将lV1卷组扩容
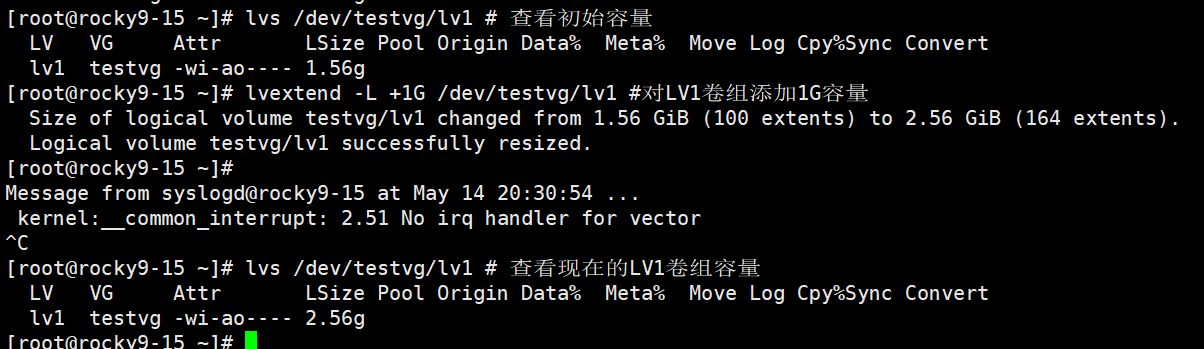
最后还要将文件系统扩容
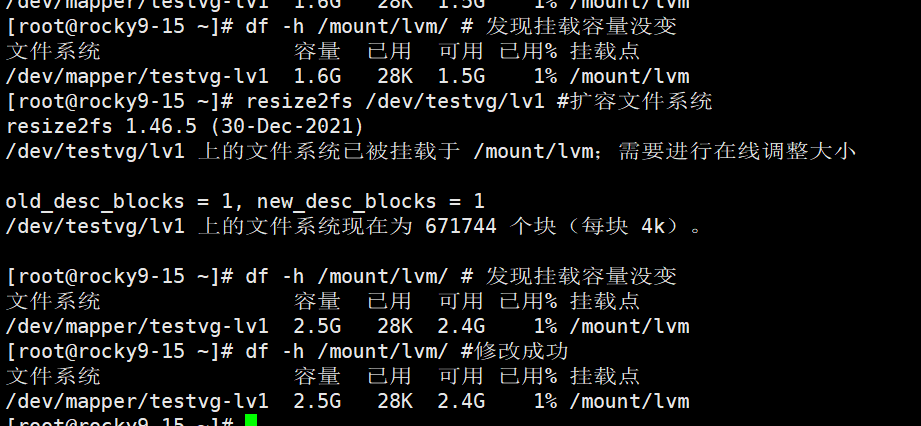
还有种一步到位的方法同时将卷组和文件系统同时扩容
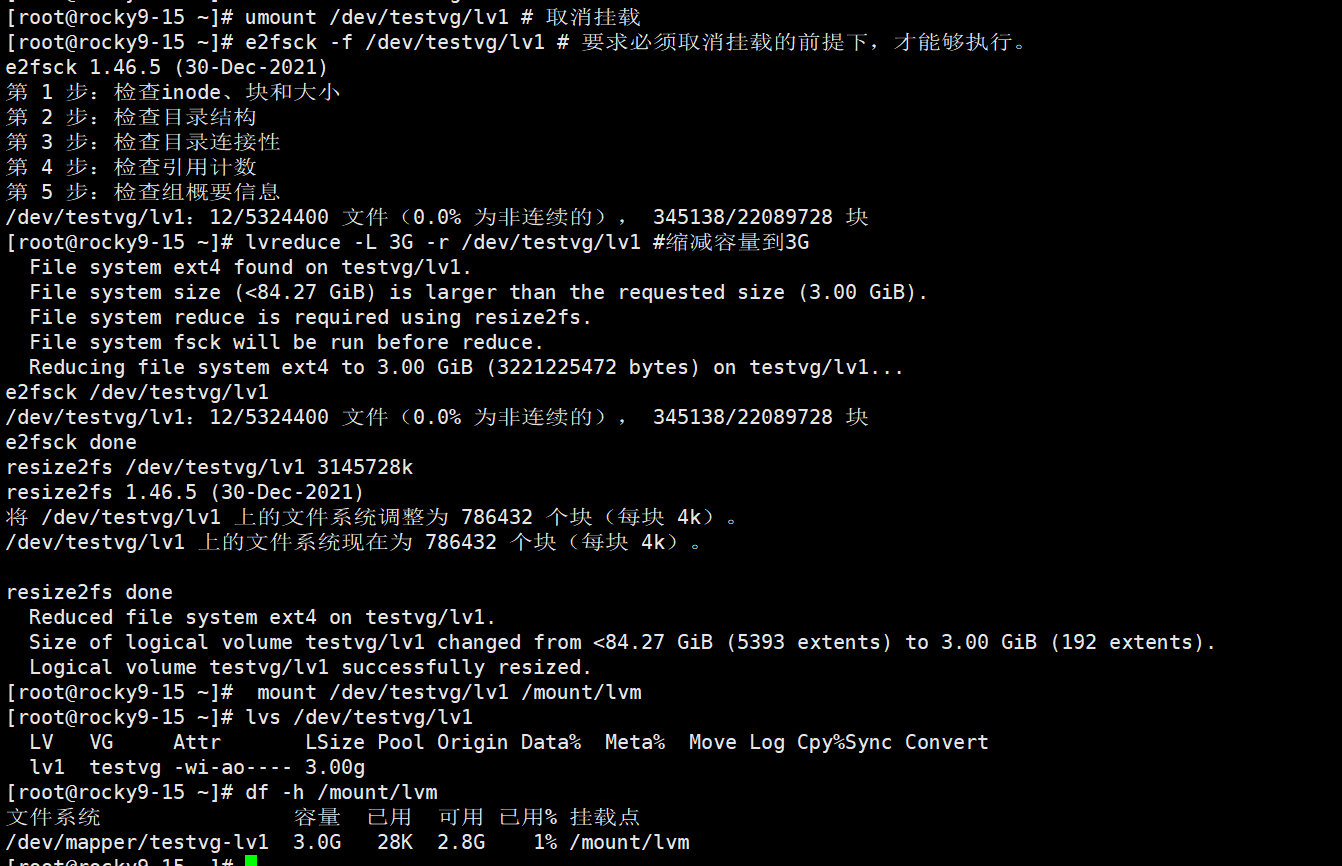
7、LV的缩容
LV的缩容就麻烦点

LV缩容实例
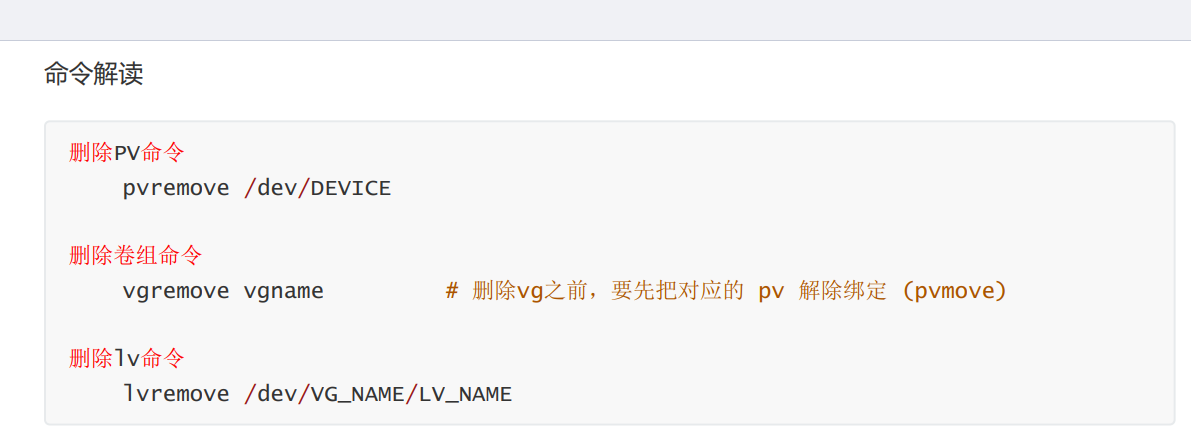
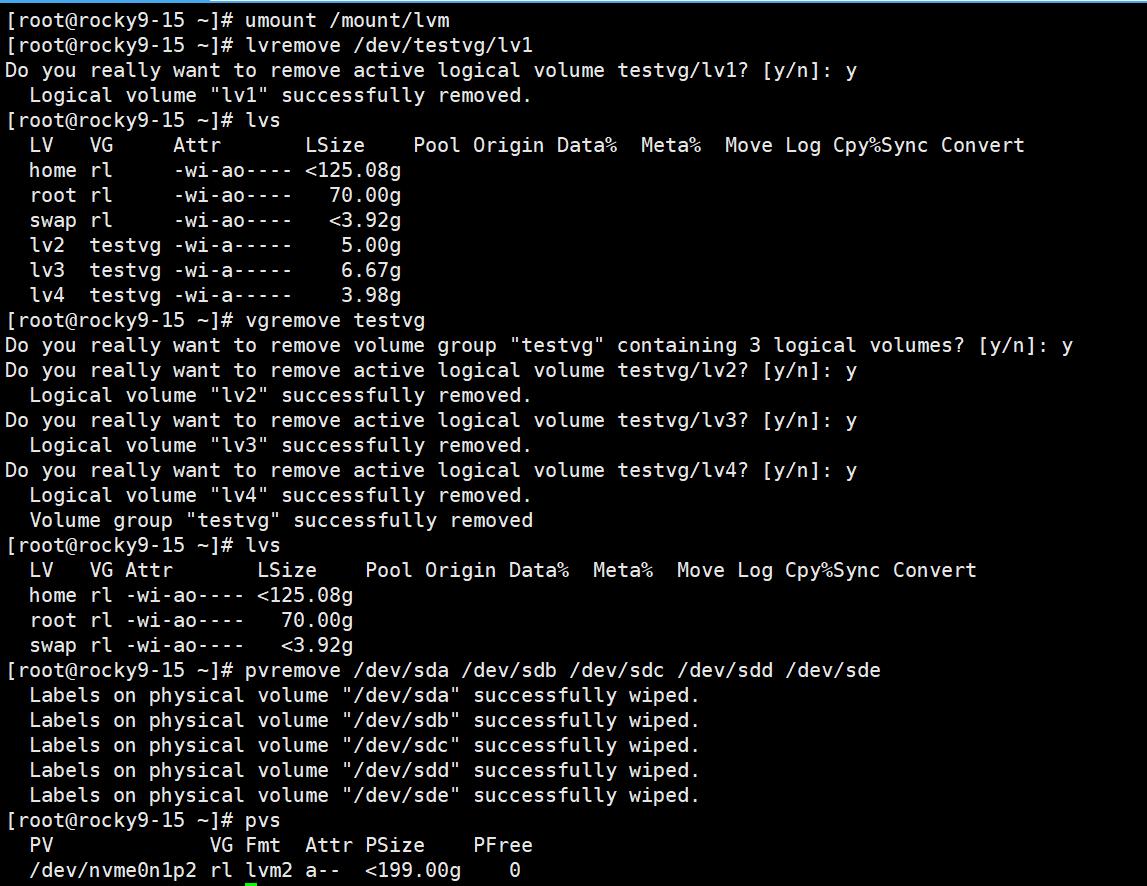
8、LV,VG,PV的删除
取消挂载的LV->删除LV->删除VG->删除PV
6. 总结变量命名规则,不同类型变量(环境变量,位置变量,只读变量,局部变量,状态变量)如何使用。
6.1变量命名规则
一、基本命名规则
1、字符组成
- 仅允许使用字母(a-z, A-Z)、数字(0-9)和下划线(_),且不能以数字开头
- 示例合法名:myVar、_count;非法名:9am、my-var
2、避免关键字 - 禁止使用 Shell 关键字(如 if、else、for 等),可通过 help 命令查看完整保留字列表
3、大小写敏感 - 区分大小写,例如 name 与 Name 视为不同变量
4、特殊符号与空格 - 变量名中不允许包含空格、连字符(-)或其他特殊符号(如 *、$)
二、赋值规范
1、格式要求
-
赋值符号 = 两侧禁止空格,例如 name=value 正确,name = value 错误
-
若变量值含空格或特殊字符,需用引号包裹:双引号允许变量替换 "\(var",单引号保留字面量 '\)var'
2、动态赋值 -
可通过命令输出赋值,例如
current_dir=$(pwd) #$(pwd)会执行shell的pwd命令,将命令结果赋值给 current_dir变量
三、注意事项
1、长度与兼容性
- 变量名理论上无长度限制,但为兼容老旧 Shell 环境,建议控制在 255 个字符内
2、只读变量 - 使用 readonly 声明常量,常量名通常全大写,例如:
readonly MAX_SIZE=100
四、命名建议
1、可读性
- 优先使用描述性名称(如 student_id 而非 var1)
- 多单词命名推荐小写字母 + 下划线分隔(如 file_path)
2、常量规范 - 常量推荐全大写(如 PI=3.14),并与普通变量区分
6.2、不同类型变量的使用场景
1、环境变量
-
全局有效,当前 Shell 及其所有子进程均可访问,使用
export或declare -x定义[root@rocky9-15 week3]# export NAME="jimmy" # 定义环境变量 [root@rocky9-15 week3]# env | grep NAME # 查看环境变量 HOSTNAME=rocky9-15 NAME=jimmy LOGNAME=root注:没有写进/etc/profile文件的环境变量会在随着shell进程中止而失效
2、位置变量
-
仅在脚本或函数内部有效,用于接收命令行参数;自动生成,通过
$1,$2...$n引用($0为脚本名)[root@rocky9-15 week3]# bash 1.sh "Hello 1" "Hello 2" 第一个位置变量:Hello 1 第二个位置变量:Hello 2 [root@rocky9-15 week3]# cat 1.sh #!/bin/bash first_var=$1 second_var=$2 echo "第一个位置变量:$1" echo "第二个位置变量:$2"
3、只读变量
-
取决于声明位置(可为全局或局部),使用
readonly或declare -r定义,作为一个常量使用[root@rocky9-15 week3]# readonly MAX=100 #定义一个只读变量 [root@rocky9-15 week3]# MAX=100 -bash: MAX:只读变量
4、局部变量
- 仅在当前函数或代码片段中有效,子进程不可见;
[root@rocky9-15 week3]# bash 2.sh
我是局部变量:10
[root@rocky9-15 week3]# cat 2.sh
#!/bin/bash
function demo() {
local count=10 # 局部变量
echo "我是局部变量:$count"
}
demo #调用函数
5、状态变量
- Shell 内置变量,全局有效;
- 典型变量:
$?:上一条命令的退出状态码(0 表示成功,非 0 表示失败)$$:当前 Shell 的进程 ID
[root@rocky9-15 week3]#
ls /nonexistent
ls: 无法访问 '/nonexistent': 没有那个文件或目录
[root@rocky9-15 week3]# echo $? # 输出非 0,表示失败
2
[root@rocky9-15 week3]# echo $$ #查看当前 Shell 的进程 ID
3116
| 变量类型 | 作用域 | 可修改性 | 生命周期 | 典型用途 |
|---|---|---|---|---|
| 环境变量 | 全局(含子进程) | 可修改 | 进程终止或配置文件持久化 | 系统路径、全局配置 |
| 位置变量 | 脚本/函数内部 | 只读 | 脚本执行期间 | 接收命令行参数 |
| 只读变量 | 定义位置决定(全局/局部) | 不可修改 | 进程终止 | 常量定义 |
| 局部变量 | 函数/代码块内部 | 可修改 | 函数/代码块结束 | 临时计算或数据隔离 |
| 状态变量 | 全局 | 自动更新 | 动态变化 | 获取命令状态或进程信息 |
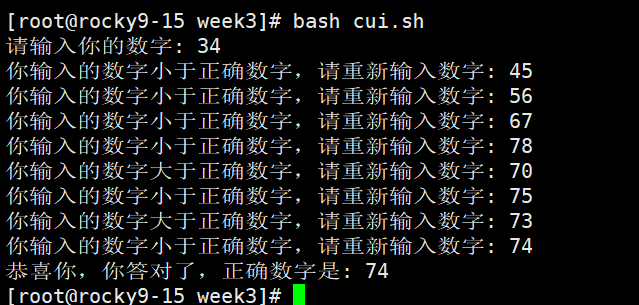
7、编写一个脚本猜数字,使用判断提示用户比目标数字是大还是小
[root@rocky9-15 week3]# cat cui.sh
#!/bin/bash
# 编写一个脚本猜数字,使用判断提示用户比目标数字是大还是小
read -p "请输入你的数字: " input_num #接受用户数据
suiji_num=$(( RANDOM % 100 + 1 )) # 生成1-100内的随机数字
while [ "$input_num" -ne "$suiji_num" ] #当用户输入的数字和我们随机生产的数字不同时进行循环
do
if [ "$input_num" -lt "$suiji_num" ]; then
read -p "你输入的数字小于正确数字,请重新输入数字: " input_num
else
read -p "你输入的数字大于正确数字,请重新输入数字: " input_num
fi
done
echo "恭喜你,你答对了,正确数字是: $suiji_num"
验证脚本效果

 浙公网安备 33010602011771号
浙公网安备 33010602011771号