

个人项目作业
1.计算模块接口的设计与实现过程
设计概述
计算模块采用分层设计,主要包含两个核心部分:
文件管理类 (FileManager)
职责:封装文件操作,提供统一的文件读写接口
关键方法:构造函数、析构函数、read_lines()、write_lines()
查重算法模块 (PlagCheck命名空间)
职责:实现文本相似度计算的核心算法
关键函数:split_into_words()、compute_simhash()、hamming_distance()、calcu_simi()
关系图:
Main Program
↓
FileManager (文件操作) → PlagCheck (算法模块)
↓ ↓
文件读写 分词 → SimHash → 汉明距离 → 相似度计算
关键算法实现
1.分词算法 (split_into_words)
流程图:
开始
↓
初始化ICU分词器
↓
遍历文本字符
↓
识别单词边界
↓
过滤标点符号和空格(无法过滤中文标点)
↓
返回单词向量
算法关键点:
使用ICU库进行语言无关的分词处理
智能过滤纯英文标点符号的"伪单词"
支持中英文混合文本处理
2. SimHash算法 (compute_simhash)
流程图:
输入单词向量
↓
对每个单词计算64位哈希
↓
构建64维特征向量(统计每位1的出现频率)
↓
生成SimHash指纹(多数表决)
独到之处:
采用64位指纹,平衡精度和计算效率
基于词频加权的特征向量生成
对每个词的哈希值进行位级统计
- 相似度计算 (calcu_simi)
创新点:
基于汉明距离的相似度度量
归一化处理确保结果在[0,1]范围内
空文本检测和边界条件处理
2.计算模块接口部分的性能改进
性能瓶颈:分词算法与重复率计算
分词算法改进:原使用jieba,但效率过低,8k字文章大概需分词8s,改用icu分词
重复率计算算法改进:原使用lcs算法计算,时间复杂度为O(m*n),现改为SimHash算法,时间复杂度约为O(n)
3.计算模块部分异常处理说明。
当输入地址对应的文件不可读/不可写/无法打开时,抛出异常
4.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 23 |
| Estimate | 估计这个任务需要多少时间 | 5 | 2 |
| Development | 开发 | 300 | 410 |
| Analysis | 需求分析 (包括学习新技术) | 30 | 38 |
| Design Spec | 生成设计文档 | 60 | 30 |
| Design Review | 设计复审 | 20 | 15 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 5 |
| Design | 具体设计 | 40 | 38 |
| Coding | 具体编码 | 40 | 28 |
| Code Review | 代码复审 | 20 | 28 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 55 |
| Reporting | 报告 | 60 | 28 |
| Test Repor | 测试报告 | 25 | 15 |
| Size Measurement | 计算工作量 | 5 | 8 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 15 | 10 |
| 合计 | 670 | 733 |
附录
测试代码和测试结果(后续只改变边查重文章地址)


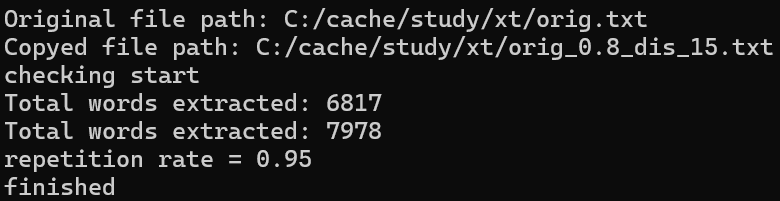
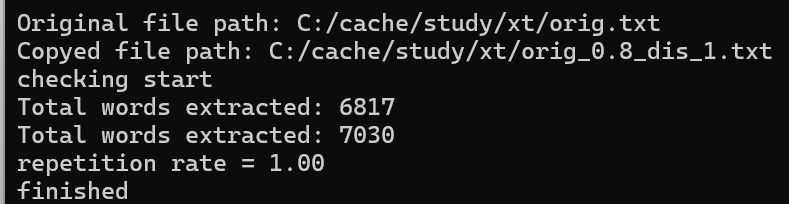
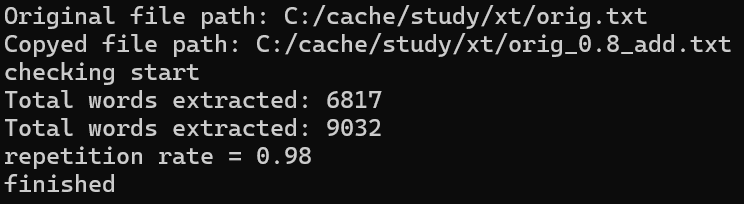
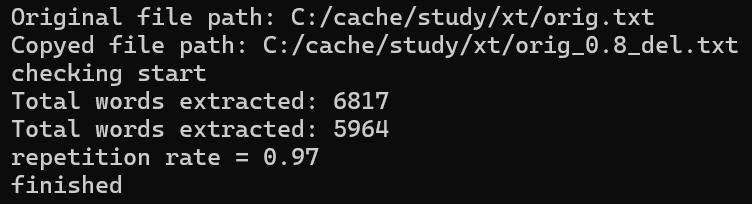

 浙公网安备 33010602011771号
浙公网安备 33010602011771号