
Linux:cgroup 简析
1. 前言
限于作者能力水平,本文可能存在谬误,因此而给读者带来的损失,作者不做任何承诺。
2. 概述
2.1 概念
什么是 cgroup?将一组进程(包括它们的子进程)放置到分配了指定资源的分组(cgroup)中,分组(cgroup)的资源控制由一到多个 cgroup 子系统完成;多个分组(cgroup)组成一棵树,即 hierarchy 。
cgroup 有两大核心功能:
- 分组
- 资源控制
分组功能是资源控制功能的前提;资源控制不是必须的,可以只进行分组,而不进行资源控制,此时具体要怎么使用分组,取决于应用,systemd 就是一个例子。
2.2 发展简介
cgroup 发展到今天,已经衍生出两个版本:v1 和 v2 。v2 是对 v1 的改进,降低了实现的复杂度,增加了实用性,以及更多方面的提高。v1 和 v2 的版本的核心区别在于 cgroup 树 (hierarchy) 棵数:v2 只有唯一一棵树(hierarchy),即系统内置的 cgrp_dfl_root,然后所有的子系统共享这一颗树(hierarchy);而 v1 则是每子系统对应一棵树(hierarchy),或某几个子系统共享一棵树(如 cpu,cpuacct 共享一棵树(hierarchy))。
3. 实现
本文分析基于 Linux 4.14.111 内核。
3.1 核心数据结构
不管是在 v1 还是 v2,都有由 cgroup 组成的树结构,Linux 内核用数据结构 cgroup_root 来描述一棵树(hierarchy):
struct cgroup_root {
struct kernfs_root *kf_root; /* hierarchy 树根目录根节点 */
/* The bitmask of subsystems attached to this hierarchy */
unsigned int subsys_mask; /* 此 hierarchy 树 关联的 子系统 掩码 */
/* Unique id for this hierarchy. */
int hierarchy_id; /* 从 cgroup_hierarchy_idr 分配的全局唯一 hierarchy ID */
/* The root cgroup. Root is destroyed on its release. */
struct cgroup cgrp; /* 代表树根节点的 cgroup */
/* for cgrp->ancestor_ids[0] */
int cgrp_ancestor_id_storage;
/* Number of cgroups in the hierarchy, used only for /proc/cgroups */
atomic_t nr_cgrps; /* hierarchy 树中 cgroup 总数 */
/* A list running through the active hierarchies */
struct list_head root_list; /* 链接 cgroup_root 到全局 cgroup_roots 列表 */
/* Hierarchy-specific flags */
unsigned int flags;
/* IDs for cgroups in this hierarchy */
struct idr cgroup_idr; /* 管理此 hierarchy 树 所有 cgroup 的 ID */
/* The path to use for release notifications. */
char release_agent_path[PATH_MAX];
/* The name for this hierarchy - may be empty */
char name[MAX_CGROUP_ROOT_NAMELEN];
};
每个 cgroup_root 含有一个 cgroup 对象 cgroup_root::cgrp,称为 root cgroup,可以理解为树根节点,主要用来建立树(中 cgroup)的层级关系。
而 hierarchy 树中的树叶,则用数据结构 cgroup 描述。
struct cgroup {
/* self css with NULL ->ss, points back to this cgroup */
struct cgroup_subsys_state self;
unsigned long flags; /* "unsigned long" so bitops work */
/*
* idr allocated in-hierarchy ID.
*
* ID 0 is not used, the ID of the root cgroup is always 1, and a
* new cgroup will be assigned with a smallest available ID.
*
* Allocating/Removing ID must be protected by cgroup_mutex.
*/
int id;
/*
* The depth this cgroup is at. The root is at depth zero and each
* step down the hierarchy increments the level. This along with
* ancestor_ids[] can determine whether a given cgroup is a
* descendant of another without traversing the hierarchy.
*/
int level; /* 在 hierarchy 树中的层次, 也即目录层次深度 */
...
/*
* Keep track of total numbers of visible and dying descent cgroups.
* Dying cgroups are cgroups which were deleted by a user,
* but are still existing because someone else is holding a reference.
* max_descendants is a maximum allowed number of descent cgroups.
*/
int nr_descendants; /* 子节点(目录)数目 */
...
/* cgroup 对应的当前目录节点(相对于所在 cgroup_root 的挂载路径) */
struct kernfs_node *kn; /* cgroup kernfs entry */
...
...
/* Private pointers for each registered subsystem */
/*
* 各 cgroup 子系统 的 状态信息对象 指针:
* cpuset: struct cpuset *
* cpu : struct task_group *
* ......
* 所有 子系统 的 状态信息对象 结构体 开始位置
* 都是一个 struct cgroup_subsys_state 结构体对
* 象, 可以理解为 所有 子系统 的 状态信息对象
* 是 struct cgroup_subsys_state 派生的子类.
*/
struct cgroup_subsys_state __rcu *subsys[CGROUP_SUBSYS_COUNT];
/*
* cgroup 是 树 @root 中的一个节点.
* 同一棵 hierarchy 树中的所有节点(cgroup) 具有相同的树根 cgroup_root,
* 也即有相同的 @root 值.
*/
struct cgroup_root *root;
/*
* List of cgrp_cset_links pointing at css_sets with tasks in this
* cgroup. Protected by css_set_lock.
*/
/*
* cgroup 和 css_set 是 【多对多 MxN】 的 关系.
* - 一个 cgroup 对应多个 css_set, 为什么需要?
* 每个 css_set::tasks 对应的 进程列表不同, 可能需要不同的
* css_set::sub_sys[] 子系统控制管理数据 ???
* - 一个 css_set 对应多个 cgroup, 为什么需要?
* 多个 cgroup 可能是同样的 css_set::sub_sys[] 子系统控制管理数据 ???
* 用 cgrp_cset_link 来描述这种关系, cset_links 不是 cgroup 关联的 所有
* css_set 对象列表, 而是包含 css_set 对象指针的 cgrp_cset_link 对象列表,
* 这样:
* - 如果从 cgroup::cset_links 出发, 可以通过 cgrp_cset_link::cset
* 找到所有关联的 css_set;
* - 如果从 css_set::cgrp_links 出发, 可以通过 cgrp_cset_link::cgrp
* 找到所有关联的 cgroup.
*/
struct list_head cset_links;
/*
* On the default hierarchy, a css_set for a cgroup with some
* susbsys disabled will point to css's which are associated with
* the closest ancestor which has the subsys enabled. The
* following lists all css_sets which point to this cgroup's css
* for the given subsystem.
*/
/*
* cgroup 各 子系统 关联的 css_set 链表:
* e_csets[i] <-> css_set::e_cset_node[i] <-> ...
*/
struct list_head e_csets[CGROUP_SUBSYS_COUNT];
...
/* ids of the ancestors at each level including self */
int ancestor_ids[]; /* 父级 cgroup 的 cgroup::id 列表 (包括自身的 ID: ancestor_ids[0]) */
};
cgroup 是资源控制的基本单位,如 cgroup 的 CPU 子系统的一个 task_group。cgroup 包含一个 cgroup_subsys_state 对象 cgroup::self,该对象的 cgroup_subsys_state::ss == NULL,即该 cgroup::self 不关联到任何子系统,主要用来建立树(中 cgroup_subsys_state)的层级结构。
接下来是各个子系统的抽象和它们的状态管理数据。子系统用 cgroup_subsys 描述:
/*
* Control Group subsystem type.
* See Documentation/cgroups/cgroups.txt for details
*/
struct cgroup_subsys {
/*
* cpuset_cgrp_subsys: cpuset_css_alloc()
* cpu_cgrp_subsys: cpu_cgroup_css_alloc()
* ...
*/
struct cgroup_subsys_state *(*css_alloc)(struct cgroup_subsys_state *parent_css);
/*
* cpuset_cgrp_subsys: cpuset_css_online()
* cpu_cgrp_subsys: cpu_cgroup_css_online()
* ...
*/
int (*css_online)(struct cgroup_subsys_state *css);
/*
* cpuset_cgrp_subsys: cpuset_css_offline()
* ...
*/
void (*css_offline)(struct cgroup_subsys_state *css);
/*
* cpu_cgrp_subsys: cpu_cgroup_css_released()
* ...
*/
void (*css_released)(struct cgroup_subsys_state *css);
/*
* cpuset_cgrp_subsys: cpuset_css_free()
* cpu_cgrp_subsys: cpu_cgroup_css_free()
* ...
*/
void (*css_free)(struct cgroup_subsys_state *css);
void (*css_reset)(struct cgroup_subsys_state *css);
/*
* cpuset_cgrp_subsys: cpuset_can_attach()
* cpu_cgrp_subsys: cpu_cgroup_can_attach()
* ...
*/
int (*can_attach)(struct cgroup_taskset *tset);
/*
* cpuset_cgrp_subsys: cpuset_cancel_attach()
* ...
*/
void (*cancel_attach)(struct cgroup_taskset *tset);
/*
* cpuset_cgrp_subsys: cpuset_attach()
* cpu_cgrp_subsys: cpu_cgroup_attach()
* ...
*/
void (*attach)(struct cgroup_taskset *tset);
/*
* cpuset_cgrp_subsys: cpuset_post_attach()
* ...
*/
void (*post_attach)(void);
int (*can_fork)(struct task_struct *task);
void (*cancel_fork)(struct task_struct *task);
/*
* cpu_cgrp_subsys: cpu_cgroup_fork()
* ...
*/
void (*fork)(struct task_struct *task);
void (*exit)(struct task_struct *task);
void (*release)(struct task_struct *task);
/*
* cpuset_cgrp_subsys: cpuset_bind()
* ...
*/
void (*bind)(struct cgroup_subsys_state *root_css);
/*
* cpuset_cgrp_subsys: true
* cpu_cgrp_subsys: true
* ...
*/
bool early_init:1;
/*
* If %true, the controller, on the default hierarchy, doesn't show
* up in "cgroup.controllers" or "cgroup.subtree_control", is
* implicitly enabled on all cgroups on the default hierarchy, and
* bypasses the "no internal process" constraint. This is for
* utility type controllers which is transparent to userland.
*
* An implicit controller can be stolen from the default hierarchy
* anytime and thus must be okay with offline csses from previous
* hierarchies coexisting with csses for the current one.
*/
bool implicit_on_dfl:1;
/*
* If %true, the controller, supports threaded mode on the default
* hierarchy. In a threaded subtree, both process granularity and
* no-internal-process constraint are ignored and a threaded
* controllers should be able to handle that.
*
* Note that as an implicit controller is automatically enabled on
* all cgroups on the default hierarchy, it should also be
* threaded. implicit && !threaded is not supported.
*/
bool threaded:1;
/*
* If %false, this subsystem is properly hierarchical -
* configuration, resource accounting and restriction on a parent
* cgroup cover those of its children. If %true, hierarchy support
* is broken in some ways - some subsystems ignore hierarchy
* completely while others are only implemented half-way.
*
* It's now disallowed to create nested cgroups if the subsystem is
* broken and cgroup core will emit a warning message on such
* cases. Eventually, all subsystems will be made properly
* hierarchical and this will go away.
*/
bool broken_hierarchy:1;
bool warned_broken_hierarchy:1;
/* the following two fields are initialized automtically during boot */
int id; /* 子系统 ID */
const char *name; /* 子系统名称: "cpuset", "cpu", ... */
/* optional, initialized automatically during boot if not set */
const char *legacy_name;
/* link to parent, protected by cgroup_lock() */
/*
* 所属 cgroup 树(hierarchy) 的根(cgroup_root).
* - cgroup v1: 子系统树根 /sys/fs/cgroup/{cpuset,cpu,...}
* - cgroup v2: &cgrp_dfl_root
*/
struct cgroup_root *root;
/* idr for css->id */
struct idr css_idr; /* 用于分配对应子系统的 cgroup_subsys_state::id */
/*
* List of cftypes. Each entry is the first entry of an array
* terminated by zero length name.
*/
/*
* 子系统 控制文件对象 cftype 列表:
* dfl_cftypes (cgroup.clone_children, cgroup.procs, ...)
* 或
* [dfl_cftypes + legacy_cftypes] => (cgroup.clone_children, cgroup.procs, ..., cpuset.cpus, ...)
*/
struct list_head cfts;
/*
* Base cftypes which are automatically registered. The two can
* point to the same array.
*/
struct cftype *dfl_cftypes; /* for the default hierarchy */
/*
* cpuset_cgrp_subsys: files[]
* cpu_cgrp_subsys: cpu_files[]
* ...
*/
struct cftype *legacy_cftypes; /* for the legacy hierarchies */
/*
* A subsystem may depend on other subsystems. When such subsystem
* is enabled on a cgroup, the depended-upon subsystems are enabled
* together if available. Subsystems enabled due to dependency are
* not visible to userland until explicitly enabled. The following
* specifies the mask of subsystems that this one depends on.
*/
unsigned int depends_on;
}
子系统状态管理数据用 cgroup_subsys_state 描述:
struct cgroup_subsys_state {
/* PI: the cgroup that this css is attached to */
struct cgroup *cgroup; /* 关联的 cgroup */
/* PI: the cgroup subsystem that this css is attached to */
/*
* 情景 1: NULL (cgroup_root::cgrp.self.ss)
* 情景 2: &cpuset_cgrp_subsys, &cpu_cgrp_subsys, ...
*/
struct cgroup_subsys *ss;
/* reference count - access via css_[try]get() and css_put() */
struct percpu_ref refcnt;
/* siblings list anchored at the parent's ->children */
struct list_head sibling; /* 同一父 cgroup 的所有子 cgroup 同一子系统 cgroup_subsys_state 数据组成的链表 */
struct list_head children; /* 所有下级 cgroup 中 同一子系统 对应的 cgroup_subsys_state 数据组成的链表 */
/*
* PI: Subsys-unique ID. 0 is unused and root is always 1. The
* matching css can be looked up using css_from_id().
*/
int id; /* 子系统类型 cgroup_subsys 内唯一 ID, 从 cgroup_subsys::css_idr 分配 */
unsigned int flags;
/*
* Monotonically increasing unique serial number which defines a
* uniform order among all csses. It's guaranteed that all
* ->children lists are in the ascending order of ->serial_nr and
* used to allow interrupting and resuming iterations.
*/
u64 serial_nr;
/*
* Incremented by online self and children. Used to guarantee that
* parents are not offlined before their children.
*/
atomic_t online_cnt;
/* percpu_ref killing and RCU release */
struct rcu_head rcu_head;
struct work_struct destroy_work;
/*
* PI: the parent css. Placed here for cache proximity to following
* fields of the containing structure.
*/
struct cgroup_subsys_state *parent; /* 在 parent cgroup 中 同一子系统 的 cgroup_subsys_state 数据 */
}
cgroup 分组最终用来管理进程,css_set 用来关联 cgroup 和 一组进程;同时,css_set 的 cgroup_subsys_state 指针数组维护进程与各个子系统(如 CPU、内存 等)的关联状态。每个子系统对应的cgroup_subsys_state 实例存储了该进程在特定子系统下的资源限制和统计信息,从而实现对不同资源的精细化控制。cgroup 和 css_set 是多对多的关系:如果一个 cgroup 关联多个 css_set,表示 cgroup 使用 cpu, memory 等多个资源子系统来控制组内的进程资源分配;反过来,一个 css_set 也可能关联多个 cgroup,这意味着多个进程可能属于同一组资源限制配置(例如容器中的多个进程),css_set 通过引用计数(refcount)和任务链表(tasks)管理这些进程。当多个进程的 cgroup 配置完全相同时,它们会共享同一个 css_set,避免重复存储配置信息,提升内存效率。
struct css_set {
/*
* Set of subsystem states, one for each subsystem. This array is
* immutable after creation apart from the init_css_set during
* subsystem registration (at boot time).
*/
struct cgroup_subsys_state *subsys[CGROUP_SUBSYS_COUNT]; /* 进程关联的 cgroup 各子系统的信息 */
/* reference count */
refcount_t refcount; /* 一个 css_set 可能被多个进程 cgroup 共用 */
/*
* For a domain cgroup, the following points to self. If threaded,
* to the matching cset of the nearest domain ancestor. The
* dom_cset provides access to the domain cgroup and its csses to
* which domain level resource consumptions should be charged.
*/
struct css_set *dom_cset;
/* the default cgroup associated with this css_set */
struct cgroup *dfl_cgrp;
/* internal task count, protected by css_set_lock */
int nr_tasks; /* css_set 中管理的进程数目: @tasks 链表长度 */
/*
* Lists running through all tasks using this cgroup group.
* mg_tasks lists tasks which belong to this cset but are in the
* process of being migrated out or in. Protected by
* css_set_rwsem, but, during migration, once tasks are moved to
* mg_tasks, it can be read safely while holding cgroup_mutex.
*/
/*
* [cgroup fs 初次 mount (不管是 v1 还是 v2)] 时, 将当前系统中
* 所有进程添加到 @tasks (通过进程对象的 task_struct::cg_list):
* cgroup_mount()
* if (!use_task_css_set_links)
* cgroup_enable_task_cg_lists()
* ...
* use_task_css_set_links = true;
* ...
* do_each_thread(g, p) {
* ...
* list_add_tail(&p->cg_list, &cset->tasks);
* ...
* } while_each_thread(g, p);
*/
struct list_head tasks;
struct list_head mg_tasks;
...
/*
* On the default hierarhcy, ->subsys[ssid] may point to a css
* attached to an ancestor instead of the cgroup this css_set is
* associated with. The following node is anchored at
* ->subsys[ssid]->cgroup->e_csets[ssid] and provides a way to
* iterate through all css's attached to a given cgroup.
*/
/* 链接到 cgroup::e_csets[i] 的 css_set 对象链表 */
struct list_head e_cset_node[CGROUP_SUBSYS_COUNT];
...
/*
* List running through all cgroup groups in the same hash
* slot. Protected by css_set_lock
*/
struct hlist_node hlist; /* 所有的 css_set 通过 @hlist 连接到 全局哈希表 css_set_table */
/*
* List of cgrp_cset_links pointing at cgroups referenced from this
* css_set. Protected by css_set_lock.
*/
/*
* cgroup 和 css_set 是 【多对多】 的 关系。
* 用 cgrp_cset_link 来描述这种关系, @cgrp_links 不是 css_set 关联的 所有
* cgroup 对象列表, 而是包含 cgroup 对象指针的 cgrp_cset_link 对象列表,
* 这样:
* - 如果从 css_set::cgrp_links 出发, 可以通过 cgrp_cset_link::cgrp 找到所有关联的 cgroup
* - 如果从 cgroup::cset_links 出发, 可以通过 cgrp_cset_link::cset 找到所有关联的 css_set
*/
struct list_head cgrp_links;
...
/*
* If this cset is acting as the source of migration the following
* two fields are set. mg_src_cgrp and mg_dst_cgrp are
* respectively the source and destination cgroups of the on-going
* migration. mg_dst_cset is the destination cset the target tasks
* on this cset should be migrated to. Protected by cgroup_mutex.
*/
/*
* 进程 在 不同 cgroup 间迁移时使用的数据.
* cgroup_migrate_add_src(), cgroup_migrate_finish()
* ...
*/
struct cgroup *mg_src_cgrp;
struct cgroup *mg_dst_cgrp;
struct css_set *mg_dst_cset;
/* dead and being drained, ignore for migration */
bool dead;
/* For RCU-protected deletion */
struct rcu_head rcu_head;
};
后文为方便起见,可能将 cgroup_subsys 简称为 ss,将 cgroup_subsys_state 简称为 css。
最后看一下用来串联 css_set 和 cgroup 的数据结构 cgrp_cset_link:
/*
* A cgroup can be associated with multiple css_sets as different tasks may
* belong to different cgroups on different hierarchies. In the other
* direction, a css_set is naturally associated with multiple cgroups.
* This M:N relationship is represented by the following link structure
* which exists for each association and allows traversing the associations
* from both sides.
*/
/*
* cgroup 和 css_set 是 【多对多】 的 关系。
* 用 cgrp_cset_link 来描述这种关系, 这样:
* - 如果从 cgroup::cset_links 出发, 可以通过 cgrp_cset_link::cset
* 找到所有关联的 css_set;
* - 如果从 css_set::cgrp_links 出发, 可以通过 cgrp_cset_link::cgrp
* 找到所有关联的 cgroup.
*/
struct cgrp_cset_link {
/* the cgroup and css_set this link associates */
struct cgroup *cgrp;
struct css_set *cset;
/* list of cgrp_cset_links anchored at cgrp->cset_links */
struct list_head cset_link; /* 链接到 @cgrp->cset_links 列表 */
/* list of cgrp_cset_links anchored at css_set->cgrp_links */
struct list_head cgrp_link; /* 链接到 @cset->cgrp_links 列表 */
};
3.1.1 子系统特定的数据结构
这里只列举 cpuset 和 cpu 两个 cgroup 子系统的状态管理数据。
cpuset 子系统的状态管理数据:
struct cpuset {
struct cgroup_subsys_state css;
// 本文不关心剩余的部分
...
};
cpu 子系统的状态管理数据:
struct task_group {
struct cgroup_subsys_state css;
// 本文不关心剩余的部分
...
};
可以看到,每个子系统的状态管理数据,都以一个 cgroup_subsys_state 实例对象开头,这很关键,这意味着,在只关心 cgroup_subsys_state 数据部分的时候,可以将任意子系统的状态管理数据当做 cgroup_subsys_state 对象处理。而这恰恰是本文讨论的情形,因为本文不关注具体子系统的更多细节。
3.2 初始化
early 初始化 cgroup_init_early():
start_kernel()
cgroup_init_early()
int __init cgroup_init_early(void)
{
static struct cgroup_sb_opts __initdata opts;
struct cgroup_subsys *ss;
int i;
init_cgroup_root(&cgrp_dfl_root, &opts);
cgrp_dfl_root.cgrp.self.flags |= CSS_NO_REF;
RCU_INIT_POINTER(init_task.cgroups, &init_css_set);
/*
* 初始化 cgroup 子系统:
* . 设置 名称, ID
* . 对 early_init 子系统进行初始化
*/
for_each_subsys(ss, i) {
...
/*
* 设置 cgroup 子系统的 ID 和 名字:
* - kernel/sched/core.c: &cpu_cgrp_subsys
* cpu_cgrp_subsys.id = i
* cpu_cgrp_subsys.name = "cpu"
* ...
*/
ss->id = i;
ss->name = cgroup_subsys_name[i];
if (!ss->legacy_name)
ss->legacy_name = cgroup_subsys_name[i];
/*
* kernel/cgroup/cpuset.c: cpuset_cgrp_subsys.early_init = true
* kernel/sched/core.c: cpu_cgrp_subsys.early_init = true
* ...
*/
if (ss->early_init)
cgroup_init_subsys(ss, true);
}
return 0;
}
具体子系统的初始化,我们只看 cpu 子系统的 early 初始化:
/*
* 初始化子系统:
* . 设置子系统的 cgroup_root 为 cgrp_dfl_root
* . 分配、初始化 cgroup_subsys_state(设定 关联的子系统 和 cgroup),
* 最后将其记录到全局的 init_css_set.subsys[ss->id] 表项
* ...
*/
static void __init cgroup_init_subsys(struct cgroup_subsys *ss, bool early)
{
struct cgroup_subsys_state *css;
...
mutex_lock(&cgroup_mutex);
...
/* Create the root cgroup state for this subsystem */
ss->root = &cgrp_dfl_root;
/*
* kernel/cgroup/cpuset.c: &cpuset_cgrp_subsys, cpuset_css_alloc()
* kernel/sched/core.c: &cpu_cgrp_subsys, cpu_cgroup_css_alloc()
* mm/memcontrol.c: &memory_cgrp_subsys, mem_cgroup_css_alloc()
* ...
*/
css = ss->css_alloc(cgroup_css(&cgrp_dfl_root.cgrp, ss));
/* We don't handle early failures gracefully */
...
init_and_link_css(css, ss, &cgrp_dfl_root.cgrp); /* 设定 cgroup_subsys_state 关联 的 [子系统 和 cgroup] */
...
/* Update the init_css_set to contain a subsys
* pointer to this state - since the subsystem is
* newly registered, all tasks and hence the
* init_css_set is in the subsystem's root cgroup. */
init_css_set.subsys[ss->id] = css;
...
/*
* online 子系统:
* . 子系统的 online 操作: css->ss->css_online()
* . 置 CSS_ONLINE 标志位
* . 设置 css 到关联 cgroup: css->cgroup->subsys[ss->id] = css
*/
BUG_ON(online_css(css));
mutex_unlock(&cgroup_mutex);
}
cgroup_init_early() 之后是 cgroup_init() 初始化调用:
start_kernel()
cgroup_init_early()
cgroup_init()
/**
* cgroup_init - cgroup initialization
*
* Register cgroup filesystem and /proc file, and initialize
* any subsystems that didn't request early init.
*/
int __init cgroup_init(void)
{
struct cgroup_subsys *ss;
int ssid;
...
/*
* 设定所有 cgroup core 控制文件对象
* cgroup_base_files[] (cgroup v2)
* cgroup1_base_files[] (cgroup v1)
* 的 @kf_ops 和 子系统 @ss (NULL)
*/
BUG_ON(cgroup_init_cftypes(NULL, cgroup_base_files));
BUG_ON(cgroup_init_cftypes(NULL, cgroup1_base_files));
...
mutex_lock(&cgroup_mutex);
/*
* Add init_css_set to the hash table so that dfl_root can link to
* it during init.
*/
/* 将 init_css_set 添加到 css_set 的 全局 hash 表 css_set_table[] */
hash_add(css_set_table, &init_css_set.hlist,
css_set_hash(init_css_set.subsys));
/*
* 配置 cgroup 树(hierarchy) 根:
* - 为 root cgroup(cgroup_root::cgrp) 分配 hierarchy 内 唯一 ID
* - 为 cgroup_root 分配全局唯一 ID
* - 创建 树根目录节点对象
* - 链接 root cgroup (cgroup_root::cgrp) 和 相关的 css_set (这里是 init_css_set)
* - 添加 cgroup_root 对象到全局列表 cgroup_roots
* - 创建根节点下的控制文件
* - 其它
*/
BUG_ON(cgroup_setup_root(&cgrp_dfl_root, 0, 0));
mutex_unlock(&cgroup_mutex);
/* 初始化所有注册的 cgroup subsys */
for_each_subsys(ss, ssid) {
if (ss->early_init) { /* 已经在 early 时期进行了初始化 */
...
} else { /* 非 early 初始化 */
/*
* 初始化子系统:
* . 设置子系统的 cgroup_root 为 cgrp_dfl_root
* . 分配、初始化 cgroup_subsys_state(设定 关联的子系统 和 cgroup),
* 最后将其记录到全局的 init_css_set.subsys[ss->id] 表项
* ...
*/
cgroup_init_subsys(ss, false);
}
}
WARN_ON(sysfs_create_mount_point(fs_kobj, "cgroup")); /* 创建 /sys/fs/cgroup 文件夹 */
WARN_ON(register_filesystem(&cgroup_fs_type)); /* 注册 cgroup v1 文件系统类型 */
WARN_ON(register_filesystem(&cgroup2_fs_type)); /* 注册 cgroup v2 文件系统类型 */
WARN_ON(!proc_create("cgroups", 0, NULL, &proc_cgroupstats_operations)); /* 创建 /proc/cgroups 文件 */
return 0;
}
cgroup_init() 主要完成了:
- 配置系统默认树根
cgrp_dfl_root - 注册
cgroup v1, v2文件系统类型 - 创建 cgroup 挂载点
/sys/fs/cgroup - 创建
/proc/cgroups文件
3.3 构建 hierachy 树根
系统启动初期,系统仅有 cgrp_dfl_root 这一个树根,并通过 cgroup_setup_root() 进行了配置。如果只使用 cgroup v2,cgrp_dfl_root 将是系统中唯一的树根;但如果使用 cgroup v1,挂载子系统时会创建新的树根 cgroup_root,来看一下 cgroup v1 在挂载 cpu 子系统时创建树根的过程。
# mount -t tmpfs cgroup_root /sys/fs/cgroup
# mkdir /sys/fs/cgroup/cpu
# mount -t cgroup -o cpu none /sys/fs/cgroup/cpu
mount -t cgroup -o cpu none /sys/fs/cgroup/cpu 将触发下面的代码流程(省略了 vfs 部分调用路径):
static struct dentry *cgroup_mount(struct file_system_type *fs_type,
int flags, const char *unused_dev_name,
void *data)
{
...
/*
* The first time anyone tries to mount a cgroup, enable the list
* linking each css_set to its tasks and fix up all existing tasks.
*/
/*
* [cgroup fs 初次 mount (不管是 v1 还是 v2)] 时, 将当前系统中
* 所有进程添加到 进程关联的 css_set 的 css_set::tasks 链表(通
* 过进程对象的 task_struct::cg_list).
*/
if (!use_task_css_set_links)
cgroup_enable_task_cg_lists();
if (fs_type == &cgroup2_fs_type) { /* cgroup v2 */
...
} else { /* cgroup v1 */
dentry = cgroup1_mount(&cgroup_fs_type, flags, data,
CGROUP_SUPER_MAGIC, ns);
}
...
}
在分析 cgroup1_mount() 之前,先看下 cgroup_enable_task_cg_lists() 添加系统现有进程到系统默认、当前唯一 css_set 对象 init_css_set 的过程:
/*
* [cgroup fs 初次 mount (不管是 v1 还是 v2)] 时, 将当前系统中
* 所有进程添加到 进程关联的 css_set 的 css_set::tasks 链表(通
* 过进程对象的 task_struct::cg_list).
*/
static void cgroup_enable_task_cg_lists(void)
{
struct task_struct *p, *g;
spin_lock_irq(&css_set_lock);
if (use_task_css_set_links)
goto out_unlock;
use_task_css_set_links = true;
/*
* We need tasklist_lock because RCU is not safe against
* while_each_thread(). Besides, a forking task that has passed
* cgroup_post_fork() without seeing use_task_css_set_links = 1
* is not guaranteed to have its child immediately visible in the
* tasklist if we walk through it with RCU.
*/
read_lock(&tasklist_lock);
/*
* 从 init_task 开始, 遍历系统中所有的 进程 及 进程下所有线程,
* 将所有进程链接到 css_set::tasks 列表.
*/
do_each_thread(g, p) {
WARN_ON_ONCE(!list_empty(&p->cg_list) ||
task_css_set(p) != &init_css_set);
/*
* We should check if the process is exiting, otherwise
* it will race with cgroup_exit() in that the list
* entry won't be deleted though the process has exited.
* Do it while holding siglock so that we don't end up
* racing against cgroup_exit().
*
* Interrupts were already disabled while acquiring
* the css_set_lock, so we do not need to disable it
* again when acquiring the sighand->siglock here.
*/
spin_lock(&p->sighand->siglock);
if (!(p->flags & PF_EXITING)) {
struct css_set *cset = task_css_set(p); /* cset = p->cgroups */
if (!css_set_populated(cset)) /* css_set 中还没有包含任何进程 */
css_set_update_populated(cset, true);
list_add_tail(&p->cg_list, &cset->tasks); /* 将进程添加到 css_set::tasks 进程列表 */
get_css_set(cset); /* css_set 的引用计数 +1 */
cset->nr_tasks++; /* css_set 关联的进程数 +1 */
}
spin_unlock(&p->sighand->siglock);
} while_each_thread(g, p);
read_unlock(&tasklist_lock);
out_unlock:
spin_unlock_irq(&css_set_lock);
}
继续看 cgroup v1 的 mount 后续过程 cgroup1_mount():
struct dentry *cgroup1_mount(struct file_system_type *fs_type, int flags,
void *data, unsigned long magic,
struct cgroup_namespace *ns)
{
struct super_block *pinned_sb = NULL;
struct cgroup_sb_opts opts;
struct cgroup_root *root;
struct cgroup_subsys *ss;
struct dentry *dentry;
int i, ret;
bool new_root = false;
...
/* First find the desired set of subsystems */
ret = parse_cgroupfs_options(data, &opts); /* 解析 mount 参数选项 */
if (ret)
goto out_unlock;
...
/* 为 cgroup v1 子系统 (cpuset,cpu,...) 创建树根 (hierarchy) */
root = kzalloc(sizeof(*root), GFP_KERNEL);
if (!root) {
ret = -ENOMEM;
goto out_unlock;
}
new_root = true;
init_cgroup_root(root, &opts);
ret = cgroup_setup_root(root, opts.subsys_mask, PERCPU_REF_INIT_DEAD);
...
/* 挂载 cgroup 子系统 */
dentry = cgroup_do_mount(&cgroup_fs_type, flags, root,
CGROUP_SUPER_MAGIC, ns);
...
return dentry;
}
init_cgroup_root() 和 cgroup_setup_root() 对新建的树根进行初始化:
void init_cgroup_root(struct cgroup_root *root, struct cgroup_sb_opts *opts)
{
struct cgroup *cgrp = &root->cgrp;
INIT_LIST_HEAD(&root->root_list);
atomic_set(&root->nr_cgrps, 1);
cgrp->root = root;
...
}
int cgroup_setup_root(struct cgroup_root *root, u16 ss_mask, int ref_flags)
{
LIST_HEAD(tmp_links);
struct cgroup *root_cgrp = &root->cgrp;
struct kernfs_syscall_ops *kf_sops;
struct css_set *cset;
int i, ret;
...
/* 为 cgroup_root 包含的 cgroup (hierarchy 的根 cgroup: root->cgrp) 分配 ID */
ret = cgroup_idr_alloc(&root->cgroup_idr, root_cgrp, 1, 2, GFP_KERNEL);
if (ret < 0)
goto out;
root_cgrp->id = ret;
root_cgrp->ancestor_ids[0] = ret;
/* root cgroup self css 引用计数初始化 */
ret = percpu_ref_init(&root_cgrp->self.refcnt, css_release,
ref_flags, GFP_KERNEL);
if (ret)
goto out;
/*
* We're accessing css_set_count without locking css_set_lock here,
* but that's OK - it can only be increased by someone holding
* cgroup_lock, and that's us. Later rebinding may disable
* controllers on the default hierarchy and thus create new csets,
* which can't be more than the existing ones. Allocate 2x.
*/
/* 分配 cgrp_cset_link 对象,用来关联 root cgroup 和 相关的 css_set */
ret = allocate_cgrp_cset_links(2 * css_set_count, &tmp_links);
if (ret)
goto cancel_ref;
/* 为 cgroup_root 分配设置一个全局唯一 ID */
ret = cgroup_init_root_id(root);
if (ret)
goto cancel_ref;
/* 设定 树根节点目录 的 操作接口 */
kf_sops = root == &cgrp_dfl_root ?
&cgroup_kf_syscall_ops : &cgroup1_kf_syscall_ops;
/* 创建 hierarchy 在 kernfs 的 根节点 对象 */
root->kf_root = kernfs_create_root(kf_sops,
KERNFS_ROOT_CREATE_DEACTIVATED |
KERNFS_ROOT_SUPPORT_EXPORTOP,
root_cgrp);
...
/* 设定 [hierarchy root cgroup 的根节点] 为 [hierarchy 的根节点], 即两者有相同的根目录节点 */
root_cgrp->kn = root->kf_root->kn;
/*
* 创建 cgroup 树(hierarchy) 根目录下的 控制文件:
* cgroup.clone_children cgroup.procs cgroup.sane_behavior
* cpu.shares notify_on_release release_agent tasks
*/
ret = css_populate_dir(&root_cgrp->self);
...
ret = rebind_subsystems(root, ss_mask);
...
/*
* There must be no failure case after here, since rebinding takes
* care of subsystems' refcounts, which are explicitly dropped in
* the failure exit path.
*/
/* 添加 cgroup_root @root 到全局列表 @cgroup_roots */
list_add(&root->root_list, &cgroup_roots);
cgroup_root_count++;
/*
* Link the root cgroup in this hierarchy into all the css_set
* objects.
*/
/* 链接 新树根 root cgroup 和关联的 css_set */
spin_lock_irq(&css_set_lock);
hash_for_each(css_set_table, i, cset, hlist) {
link_css_set(&tmp_links, cset, root_cgrp);
if (css_set_populated(cset))
cgroup_update_populated(root_cgrp, true);
}
spin_unlock_irq(&css_set_lock);
...
kernfs_activate(root_cgrp->kn);
ret = 0;
goto out;
...
out:
/*
* 前面 allocate_cgrp_cset_links() 分配的 cgrp_cset_link,
* 可能没有被前面 css_set_table 表遍历循环里 link_css_set()
* 调用消耗完, 所以这里释放剩余的 cgrp_cset_link 对象.
*/
free_cgrp_cset_links(&tmp_links);
return ret;
}
展开下 rebind_subsystems():
/*
* 将 @ss_mask 指定的 子系统 从 当前所挂接的 cgroup_root,
* 重新绑定到新的 cgroup_root @dst_root.
*/
int rebind_subsystems(struct cgroup_root *dst_root, u16 ss_mask)
{
struct cgroup *dcgrp = &dst_root->cgrp;
struct cgroup_subsys *ss;
int ssid, i, ret;
lockdep_assert_held(&cgroup_mutex);
...
do_each_subsys_mask(ss, ssid, ss_mask) {
struct cgroup_root *src_root = ss->root;
struct cgroup *scgrp = &src_root->cgrp;
struct cgroup_subsys_state *css = cgroup_css(scgrp, ss);
struct css_set *cset;
WARN_ON(!css || cgroup_css(dcgrp, ss));
/* disable from the source */
src_root->subsys_mask &= ~(1 << ssid); /* 从 @src_root 移除 子系统 @ssid 掩码 */
WARN_ON(cgroup_apply_control(scgrp));
cgroup_finalize_control(scgrp, 0);
/* rebind */
RCU_INIT_POINTER(scgrp->subsys[ssid], NULL); /* 将 css 从 @src_root 移除绑定 */
rcu_assign_pointer(dcgrp->subsys[ssid], css); /* 将 css 绑定 到 @dst_root->cgrp */
ss->root = dst_root; /* 将 @ss 子系统 绑定 到 新的 @dst_root */
css->cgroup = dcgrp;
spin_lock_irq(&css_set_lock);
hash_for_each(css_set_table, i, cset, hlist)
list_move_tail(&cset->e_cset_node[ss->id],
&dcgrp->e_csets[ss->id]);
spin_unlock_irq(&css_set_lock);
/* default hierarchy doesn't enable controllers by default */
dst_root->subsys_mask |= 1 << ssid; /* 子系统 @ssid 掩码 添加到新的 @dst_root */
...
/* 将新的变动扩散到 @dcgrp 的子树 */
ret = cgroup_apply_control(dcgrp);
/* 子系统特定的 bind 动作 (cpu 子系统无此接口,其它有的子系统有该接口,如 cpuset) */
if (ss->bind)
ss->bind(css);
} while_each_subsys_mask();
kernfs_activate(dcgrp->kn);
return 0;
}
到此,cgroup v1 的 cpu 子系统的挂载过程已经完成,此时的简略数据视图大概如下(省略了目前非关键部分):

就这一会儿功夫,就够让人眼花缭乱了,简单的对上图解释一下:
cpu 子系统的挂载,系统创建了一棵树 (cgroup_root)第 1 次cgroup fs 的挂载,将系统中现有进程添加到init_css_set任务列表init_css_set.tasks- 挂载 cpu 子系统后,其唯一分组
root cgroup,也即 cpu 子系统的root_task_group分组中的进程,即init_css_set.tasks中的进程
再看一下 cpu 子系统挂载后的相关挂载信息和目录结构:
# mount | grep "cgroup"
tmpfs on /sys/fs/cgroup type tmpfs (ro,nosuid,nodev,noexec,mode=755)
cgroup on /sys/fs/cgroup/cpu type cgroup (rw,nosuid,nodev,noexec,relatime,cpu)
# cd /sys/fs/cgroup
# cd cpu
# ls -l
total 0
-rw-r--r-- 1 root root 0 Sep 11 06:48 cgroup.clone_children
-rw-r--r-- 1 root root 0 Sep 11 06:47 cgroup.procs
-r--r--r-- 1 root root 0 Sep 11 06:48 cgroup.sane_behavior
-rw-r--r-- 1 root root 0 Sep 11 06:48 cpu.shares
-rw-r--r-- 1 root root 0 Sep 11 06:48 notify_on_release
-rw-r--r-- 1 root root 0 Sep 11 06:48 release_agent
-rw-r--r-- 1 root root 0 Sep 11 06:48 tasks
3.4 构建 hierarchy 树叶:分组创建
创建 cgroup 分组,即创建一个 cgroup 数据对象,对应于用户空间在子系统目录下的 mkdir 操作,如:
# cd /sys/fs/cgroup/cpu
# mkdir test
其代码流程如下(同样省略了 vfs 部分):
int cgroup_mkdir(struct kernfs_node *parent_kn, const char *name, umode_t mode)
{
struct cgroup *parent, *cgrp;
struct kernfs_node *kn;
int ret;
...
/*
* 锁住 @parent_kn 目录并返回对应的 cgroup 。
*
* 我们例子中,是在 cpu 子系统根目录 /sys/fs/cgroup/cpu 下创建目录,
* 所以这里的 @parent 指向 root cgroup.
* 其它不是在子系统根目录下创建目录的情形,@parent 则指向上一级目录
* 所代表的 cgroup.
*/
parent = cgroup_kn_lock_live(parent_kn, false);
if (!parent)
return -ENODEV;
...
/* 为新建的目录创建一个 cgroup 对象, 父级 cgroup 为 @parent */
cgrp = cgroup_create(parent);
...
/* create the directory */
/* 创建新目录, 父级目录为 @parent cgroup 的目录 */
kn = kernfs_create_dir(parent->kn, name, mode, cgrp);
...
cgrp->kn = kn; /* 设定 新 cgroup 关联的目录 */
...
/*
* 在目录下创建 cgroup 公共控制文件:
* cgroup.clone_children
* cgroup.procs
* notify_on_release
* tasks
*/
ret = css_populate_dir(&cgrp->self);
...
/*
* 创建 子系统 css 及 控制文件, 如:
* cpu.cfs_period_us
* cpu.cfs_quota_us
* cpu.shares
* cpu.stat
*/
ret = cgroup_apply_control_enable(cgrp);
ret = 0;
goto out_unlock;
...
out_unlock:
cgroup_kn_unlock(parent_kn); /* 解锁 parent cgroup 的目录 */
return ret;
}
首先 cgroup_create() 创建了新的 cgroup 分组,建立树的层级关系,
static struct cgroup *cgroup_create(struct cgroup *parent)
{
struct cgroup_root *root = parent->root; /* @parent 所在 hierarchy 树的根 */
struct cgroup *cgrp, *tcgrp;
int level = parent->level + 1;
int ret;
/* allocate the cgroup and its ID, 0 is reserved for the root */
cgrp = kzalloc(sizeof(*cgrp) +
sizeof(cgrp->ancestor_ids[0]) * (level + 1), GFP_KERNEL);
...
ret = percpu_ref_init(&cgrp->self.refcnt, css_release, 0, GFP_KERNEL);
...
/*
* Temporarily set the pointer to NULL, so idr_find() won't return
* a half-baked cgroup.
*/
cgrp->id = cgroup_idr_alloc(&root->cgroup_idr, NULL, 2, 0, GFP_KERNEL);
...
init_cgroup_housekeeping(cgrp);
cgrp->self.parent = &parent->self; /* 指向 */
cgrp->root = root; /* hierarchy 树根的 cgroup, 即 root cgroup */
cgrp->level = level; /* 设置 cgroup 节点(目录) 在 hierarchy 树中层次 */
/*
* . 记录所有 父级节点(目录) 的 ID 到新的 cgroup
* . 更新 父级节点(目录) 的 子节点(目录) 数目
*/
for (tcgrp = cgrp; tcgrp; tcgrp = cgroup_parent(tcgrp)) {
cgrp->ancestor_ids[tcgrp->level] = tcgrp->id;
if (tcgrp != cgrp)
tcgrp->nr_descendants++;
}
...
cgrp->self.serial_nr = css_serial_nr_next++;
/* allocation complete, commit to creation */
list_add_tail_rcu(&cgrp->self.sibling, &cgroup_parent(cgrp)->self.children); /* 新 cgroup 添加到 父级节点(目录) 的 children 列表 */
atomic_inc(&root->nr_cgrps); /* 新 cgroup 所在 hierarchy 树根 (cgroup_root) 应用计数 +1 */
cgroup_get_live(parent); /* 增加 父级节点(目录) 的 引用计数 */
...
cgroup_propagate_control(cgrp);
return cgrp;
...
}
然后 cgroup_apply_control_enable() 对 cgroup_create() 新建 cgroup 分组做了进一步配置:
static int cgroup_apply_control_enable(struct cgroup *cgrp)
{
struct cgroup *dsct;
struct cgroup_subsys_state *d_css;
struct cgroup_subsys *ss;
int ssid, ret;
/* 从 cgrp 自身开始,先序遍历 @cgrp 及其子孙节点 */
cgroup_for_each_live_descendant_pre(dsct, d_css, cgrp) {
/* 遍历系统注册的 cgroup 子系统 (cgroup_subsys: cpuset, cpu, ...) */
for_each_subsys(ss, ssid) {
/*
* 获取 cgroup @dsct 中子系统 @ss 的 cgroup_subsys_state 数据指针.
*
* 在我们当前的例子中,@dsct 指向在上级函数 cgroup_mkdir() 中新建的
* cgroup,所以这里的 @css 总是返回 NULL.
*/
struct cgroup_subsys_state *css = cgroup_css(dsct, ss);
...
/*
* 不处理不和 @dsct 关联的子系统的情形。
*
* 如当前我们的例子中,只处理 cpu 子系统的情形
*/
if (!(cgroup_ss_mask(dsct) & (1 << ss->id)))
continue;
if (!css) {
css = css_create(dsct, ss);
...
}
if (css_visible(css)) {
/*
* 创建 @css 关联子系统 的 控制文件, 如:
* cpu.cfs_period_us cpu.cfs_quota_us cpu.shares cpu.stat
*/
ret = css_populate_dir(css);
...
}
}
}
return 0;
}
其中,css_create() 通过子系统接口创建了新的 cgroup_subsys_state,关联到对应的子系统对象(我们的例子是 cpu 子系统)和 cgroup 分组:
static struct cgroup_subsys_state *css_create(struct cgroup *cgrp,
struct cgroup_subsys *ss)
{
struct cgroup *parent = cgroup_parent(cgrp);
struct cgroup_subsys_state *parent_css = cgroup_css(parent, ss);
struct cgroup_subsys_state *css;
int err;
...
/*
* 创建子系统特定的 cgroup_subsys_state
* (cpuset::css, task_group::css, mem_cgroup::css, ...):
* kernel/cgroup/cpuset.c: &cpuset_cgrp_subsys, cpuset_css_alloc()
* kernel/sched/core.c: &cpu_cgrp_subsys, cpu_cgroup_css_alloc()
* mm/memcontrol.c: &memory_cgrp_subsys, mem_cgroup_css_alloc()
* ...
*/
css = ss->css_alloc(parent_css);
...
/* 设定 cgroup_subsys_state 关联 的 [子系统 和 cgroup] */
init_and_link_css(css, ss, cgrp);
/* 新 css 引用计数初始化 */
err = percpu_ref_init(&css->refcnt, css_release, 0, GFP_KERNEL);
...
/* 子系统 css ID 分配 */
err = cgroup_idr_alloc(&ss->css_idr, NULL, 2, 0, GFP_KERNEL);
...
/* @css is ready to be brought online now, make it visible */
/* 添加到 parent (cgroup 子系统 @ss 的) css 的 children 列表 */
list_add_tail_rcu(&css->sibling, &parent_css->children);
...
/* 上线新的 css */
err = online_css(css);
...
return css;
...
}
子系统接口创建了新的 cgroup_subsys_state 的意义,取决于具体的子系统。对于我们的例子,cpu 子系统的接口建立了新的 task_group:
static struct cgroup_subsys_state *
cpu_cgroup_css_alloc(struct cgroup_subsys_state *parent_css)
{
/*
* @parent_css: 上一级 cgroup 的 cpu 子系统的 css
* @parent: 上一级 task_group (对应 cpu 子系统的上一级目录)
*
* 如创建 cpu 子系统下的第 1 级目录时:
* cd /sys/fs/cgroup/cpu
* mkdir test
* 则这里的 @parent_css 为 cgroup_root::cgrp.subsys[cpu_cgrp_id]
* 指向的 css, 即 root_task_group.css, 此时, @parent = &root_task_group.
*
* 其它情形, 可以类似分析.
*/
struct task_group *parent = css_tg(parent_css);
struct task_group *tg;
if (!parent) { /* cgroup v1 mount CPU 子系统时, 返回内核定义的 root_task_group 的 css */
/* This is early initialization for the top cgroup */
return &root_task_group.css;
}
/*
* 非 子系统根目录下 创建新的目录(即 task_group) 的情形.
* 如:
* cd /sys/fs/cgroup/cpu/test
* mkdir test2
*/
tg = sched_create_group(parent);
if (IS_ERR(tg))
return ERR_PTR(-ENOMEM);
return &tg->css;
}
sched_create_group() 就不再继续展开了,这涉及到具体子系统的实现细节,不在本文讨论范围内,知道该函数是创建一个新的 task_group 就够了。
对 cgroup 分组创建的讨论,就到这里。
3.5 分组控制
3.5.1 cgroup 通用控制
cgroup 通用控制 指对所有子系统都有相同控制文件进行操作,它们的逻辑是一样的。
3.5.1.1 添加进程到分组
可以通过 cgroup.procs 写入进程 PID 来将进程加入 cgroup 分组。本文分析一下 cgroup v1 写入 cgroup.procs 的过程(省略 vfs 部分):
static ssize_t cgroup1_procs_write(struct kernfs_open_file *of,
char *buf, size_t nbytes, loff_t off)
{
return __cgroup1_procs_write(of, buf, nbytes, off, true);
}
static ssize_t __cgroup1_procs_write(struct kernfs_open_file *of,
char *buf, size_t nbytes, loff_t off,
bool threadgroup)
{
struct cgroup *cgrp;
struct task_struct *task;
const struct cred *cred, *tcred;
ssize_t ret;
/* 锁住 (打开文件节点 @of-kn) 并返回其所属的 cgroup 分组 */
cgrp = cgroup_kn_lock_live(of->kn, false);
if (!cgrp)
return -ENODEV;
/*
* 获取 @buf 指向进程的 task_struct.
* @buf: 进程 PID 字串
*/
task = cgroup_procs_write_start(buf, threadgroup);
ret = PTR_ERR_OR_ZERO(task);
if (ret)
goto out_unlock;
/* 将进程 @leader 添加到 cgroup @cgrp */
ret = cgroup_attach_task(cgrp, task, threadgroup);
out_finish:
cgroup_procs_write_finish(task);
out_unlock:
cgroup_kn_unlock(of->kn); /* 释放锁 */
return ret ?: nbytes;
}
最终,cgroup_attach_task() 完成了将进程添加到目标 cgroup 分组,其核心的工作是:将进程添加到目标 cgroup 分组关联的 css_set 的 css_set::tasks 列表中,同时中间可能涉及新 css_set 对象的创建(细节见 find_css_set()),以及子系统 attach 回调的触发,如 cpu 子系统的 cpu_cgroup_attach() 调用:
cgroup_attach_task()
cgroup_migrate()
cgroup_migrate_execute()
ss->attach(tset)
cpu_cgroup_attach() // 将进程迁移到目标 task_group
对于其它 cgroup 的通用控制文件的操作,感兴趣的读者可自行分析,本文就不再展开。
3.5.2 子系统的特定控制
如 cpu 子系统 cgroup 分组的 cpu.shares 配置,来看下具体的实现:
static int cpu_shares_write_u64(struct cgroup_subsys_state *css,
struct cftype *cftype, u64 shareval)
{
return sched_group_set_shares(css_tg(css), scale_load(shareval));
}
int sched_group_set_shares(struct task_group *tg, unsigned long shares)
{
int i;
/*
* We can't change the weight of the root cgroup.
*/
if (!tg->se[0])
return -EINVAL;
shares = clamp(shares, scale_load(MIN_SHARES), scale_load(MAX_SHARES));
mutex_lock(&shares_mutex);
if (tg->shares == shares)
goto done;
tg->shares = shares;
for_each_possible_cpu(i) {
struct rq *rq = cpu_rq(i);
struct sched_entity *se = tg->se[i];
struct rq_flags rf;
/* Propagate contribution to hierarchy */
rq_lock_irqsave(rq, &rf);
update_rq_clock(rq);
for_each_sched_entity(se) {
update_load_avg(se, UPDATE_TG);
update_cfs_shares(se);
}
rq_unlock_irqrestore(rq, &rf);
}
done:
mutex_unlock(&shares_mutex);
return 0;
}
static void update_cfs_shares(struct sched_entity *se)
{
struct cfs_rq *cfs_rq = group_cfs_rq(se);
struct task_group *tg;
long shares;
if (!cfs_rq)
return;
if (throttled_hierarchy(cfs_rq))
return;
tg = cfs_rq->tg;
#ifndef CONFIG_SMP
if (likely(se->load.weight == tg->shares))
return;
#endif
/* 计算 task_group 的权重 */
shares = calc_cfs_shares(cfs_rq, tg);
/* 更新 task_group 对应调度实体的权重 */
reweight_entity(cfs_rq_of(se), se, shares);
}
static void reweight_entity(struct cfs_rq *cfs_rq, struct sched_entity *se,
unsigned long weight)
{
if (se->on_rq) {
/* commit outstanding execution time */
if (cfs_rq->curr == se)
update_curr(cfs_rq);
account_entity_dequeue(cfs_rq, se);
}
update_load_set(&se->load, weight);
if (se->on_rq)
account_entity_enqueue(cfs_rq, se);
}
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}
4. cgroup 相关内核配置项
CONFIG_CGROUPS 是 cgroup 功能的总开关:

再接下来就是各子系统自身的配置开关:
memory: CONFIG_MEMCG
io: CONFIG_BLK_CGROUP
cpu: CONFIG_CGROUP_SCHED
pid: CONFIG_CGROUP_PIDS
rdma: CONFIG_CGROUP_RDMA
freezer: CONFIG_CGROUP_FREEZER
cpuset: CONFIG_CPUSETS
device: CONFIG_CGROUP_DEVICE
cpuacct: CONFIG_CGROUP_CPUACCT
perf: CONFIG_CGROUP_PERF
debug: CONFIG_CGROUP_DEBUG
...
其中 cpu 子系统的配置又可进一步细分:

CFS 组调度: CONFIG_FAIR_GROUP_SCHED
RT 组调度: CONFIG_RT_GROUP_SCHED
以及基于 CFS 组调度的带宽控制:
CONFIG_CFS_BANDWIDTH
5. cgroup 用户空间接口
/proc/cgroups 向用户展示了系统注册的子系统情况:
# cat /proc/cgroups
#subsys_name hierarchy num_cgroups enabled
cpuset 3 1 1
cpu 2 1 1
细节可参考 proc_cgroupstats_show() 函数代码。
挂载点目录如 /sys/fs/cgroup 展示了 cgroup 各子系统的控制文件:
# ls -l /sys/fs/cgroup
total 0
dr-xr-xr-x 2 root root 0 9月 11 14:46 blkio
lrwxrwxrwx 1 root root 11 9月 11 14:46 cpu -> cpu,cpuacct
lrwxrwxrwx 1 root root 11 9月 11 14:46 cpuacct -> cpu,cpuacct
dr-xr-xr-x 2 root root 0 9月 11 14:46 cpu,cpuacct
dr-xr-xr-x 2 root root 0 9月 11 14:46 cpuset
dr-xr-xr-x 5 root root 0 9月 11 14:46 devices
dr-xr-xr-x 2 root root 0 9月 11 14:46 freezer
dr-xr-xr-x 2 root root 0 9月 11 14:46 hugetlb
dr-xr-xr-x 2 root root 0 9月 11 14:46 memory
lrwxrwxrwx 1 root root 16 9月 11 14:46 net_cls -> net_cls,net_prio
dr-xr-xr-x 2 root root 0 9月 11 14:46 net_cls,net_prio
lrwxrwxrwx 1 root root 16 9月 11 14:46 net_prio -> net_cls,net_prio
dr-xr-xr-x 2 root root 0 9月 11 14:46 perf_event
dr-xr-xr-x 5 root root 0 9月 11 14:46 pids
dr-xr-xr-x 2 root root 0 9月 11 14:46 rdma
dr-xr-xr-x 5 root root 0 9月 11 14:46 systemd
$ tree /sys/fs/cgroup/cpu,cpuacct/
/sys/fs/cgroup/cpu,cpuacct/
├── cgroup.clone_children
├── cgroup.procs
├── cgroup.sane_behavior
├── cpuacct.stat
├── cpuacct.usage
├── cpuacct.usage_all
├── cpuacct.usage_percpu
├── cpuacct.usage_percpu_sys
├── cpuacct.usage_percpu_user
├── cpuacct.usage_sys
├── cpuacct.usage_user
├── cpu.cfs_period_us
├── cpu.cfs_quota_us
├── cpu.shares
├── cpu.stat
├── notify_on_release
├── release_agent
└── tasks
0 directories, 18 files
进程文件 /proc/<PID>/cgroup 展示了自身的 cgroup 分组信息:
$ cat /proc/1808/cgroup
$ cat /proc/1808/cgroup
12:memory:/
11:devices:/user.slice
10:pids:/user.slice/user-1000.slice
9:rdma:/
8:cpu,cpuacct:/
7:blkio:/
6:perf_event:/
5:net_cls,net_prio:/
4:cpuset:/
3:freezer:/
2:hugetlb:/
1:name=systemd:/user.slice/user-1000.slice/session-c2.scope
细节可参考 proc_cgroup_show() 函数代码。
6. cgroup 的应用
cgroup 的典型应用是容器。最简单的容器可以简单的理解为 cgroup + namespace 的结合使用:
cgroup: 管理资源(CPU,内存,网络,磁盘 I/O)的分配、限制namespace: 封装抽象,限制,隔离,使命名空间内的进程看起来拥有他们自己的全局资源
容器发展大概是这样: chroot -> Linux VServer -> cgroup -> Docker -> Kubernetes。
7. 示例
有如下的 busy_loop.c 程序代码:
#define _GNU_SOURCE
#include <unistd.h>
#include <malloc.h>
#include <pthread.h>
void *busy_loop(void *args)
{
int i;
while (1)
i++;
return (void *)0;
}
int main(void)
{
pthread_t *tids;
cpu_set_t cpuset;
int nr_cpu, i = 0;
nr_cpu = sysconf(_SC_NPROCESSORS_ONLN);
tids = malloc((nr_cpu - 1) * sizeof(pthread_t));
if (!tids)
return -1;
CPU_ZERO(&cpuset);
CPU_SET(i, &cpuset);
pthread_setaffinity_np(pthread_self(), sizeof(cpu_set_t), &cpuset);
for (++i; i < nr_cpu; i++) {
pthread_create(&tids[i-1], NULL, busy_loop, NULL);
CPU_ZERO(&cpuset);
CPU_SET(i, &cpuset);
pthread_setaffinity_np(tids[i-1], sizeof(cpu_set_t), &cpuset);
}
for (i = 1; i < nr_cpu; i++)
pthread_join(tids[i-1], NULL);
free(tids);
return 0;
}
在 QEMU 模拟的 4 核的 ARM 机器上运行起来后,top 观察到的 CPU 使用情况如下图:

从上图可以看到,busy_loop 程序占用了约 300% 的 CPU,即 3 个核,这是符合预期的。然后运行第 2 个 busy_loop 程序,然后观察到的 CPU 使用情况如下图:
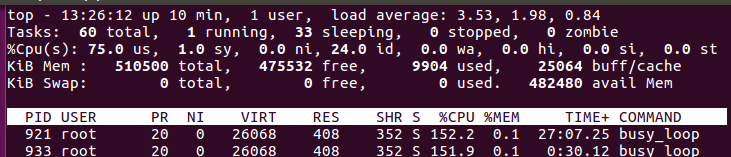
我们看到,两个 busy_loop 程序大概平分了 3 个 CPU,各占 150% 左右,这也是符合预期的。接下来,在 cpu 子系统目录 /sys/fs/cgroup/cpu 下,创建一个 cgroup 分组 A,并将 cgroup 分组 A 的 cpu.shares 设为 512(默认 1024),然后将第 2 个 busy_loop 程序添加到 cgroup 分组 A:
# cd /sys/fs/cgroup/cpu
# mkdir A
# echo 512 > A/cpu.shares
# echo 933 > A/cgroup.procs
然后观察到的 CPU 使用情况如下图:

第 1 个 busy_loop 程序约占用了 250% 的 CPU,而 第 2 个 busy_loop 程序约占用了 50% 的 CPU,是按照它们各自的所在 cgroup 分组的 cpu.shares 进行计算分配的。
目前,第 1 个 busy_loop 位于 cpu 子系统树根所在的 root cgroup 分组:
# cat /proc/921/cgroup
3:cpuset:/
2:cpu:/
1:name=systemd:/system.slice/system-getty.slice/getty@ttyAMA0.service
而 第 2 个 busy_loop 位于 cpu 子系统比树根次一级的 cgroup 分组 A 中:
# cat /proc/933/cgroup
3:cpuset:/
2:cpu:/A
1:name=systemd:/system.slice/system-getty.slice/getty@ttyAMA0.service
我们再建立一个 cpu 的 cgroup 分组 B,保持其 cpu.shares 的权重为默认值 1024,然后将第 1 个 busy_loop 程序添加到 cgroup 分组 B:
# cd /sys/fs/cgroup/cpu
# mdkir B
# echo 921 > B/cpu.shares
然后观察到的 CPU 使用情况如下图:

可见,两个 busy_loop 程序的 CPU 占比,已经变为大概 2:1:一个占约 200%,一个占约 100%,正式各 cgroup A 和 B 的 cpu.shares 的比值 1024/512 = 2:1。
cpu 子系统按 cpu.shares 权重分配 CPU 时间的算法细节可参考文章CFS调度器(3)-组调度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号