
Python-序列化和反序列化
1、定义:
为什么要序列化:
内存中的字典,列表,集合以及各种对象,如何保存到一个文件中?
如果是自己定义的类型的实例,如何保存到一个文件中?
如何从文件中读取数据,并让它们在内存中再次恢复成自己对应 的类的实例?
定义:把内存中数据保存到文件中,文件是一个字节序列,所以必须把数据转换成字序列,输出到文件,这就是序列化,繁殖,从文件的字节序列恢复到内存,就是反序列化。并且保证数据结构的完整性!!!!
serialization 序列化
将内存中对象存储下来,把它变成一个个字节,---二进制
deserialization 反序列化
将文件的一个个字节恢复成内存中 对象 <------二进制
序列化保存到文件就是持久化
2、pickle库: 不推荐用,思想重要
dumps: 对象序列化为bytes 对象
dump: 对象序列化到文件对象,就是存入文件
loads:从bytes对象反序列化
load: 对象反序列化,从文件读取数据
1 import pickle 2 3 i = 99 4 s = 'abc' 5 6 7 with open('f:/c','wb') as f: 8 pickle.dump(i,f) 9 pickle.dump(s,f) 10 print("-----------------------------------") 11 with open('f:/c','rb') as f: 12 t = pickle.load(f) 13 print(type(t), t) 14 t = pickle.load(f) 15 print(type(t), t) 16 17 print("-----------------------------------") 18 class AA(): 19 def show(self): 20 print('asda') 21 22 a = AA() 23 24 with open('f:/c','wb') as f: 25 pickle.dump(a, f) 26 27 with open('f:c','rb') as f: 28 t = pickle.load(f) 29 print(type(t),t) 30 print("-----------------------------------") 31 class AA(): 32 a = 0x1111111 33 def show(self): 34 self.name = 0x1111111 # 这个是属于实例自己的,所以要序列化 35 print('asda') 36 37 a = AA() 38 #序列化 39 with open('f:/c','wb') as f: 40 pickle.dump(a, f) 41 # 反序列化 42 with open('f:c','rb') as f: 43 t = pickle.load(f) 44 print(type(t),t, t.a) 45 t.show() 46 47 # 通过实验发现,同一个类的属性是可以序列化的,但是每个实例的属性是没有序列化的 48 # 序列化 和 反序列化在不同的平台或者非本地,必须同时具有相同的类,如果只是类名相同,可能也会造成错误的反序列haul,蛋刀的值 49 # 不是自己要想用的 50 # t 和 a 是不同的实例!!! 51 print("-----------------------------------") 52 import pickle 53 54 class AA(): 55 def show(self): 56 print('asda') 57 58 a = AA() 59 # 先到内存,需要了在 存到文件中(序列化) 60 ser = pickle.dumps(a) 61 # print(ser) # b'\x80\x03c__main__\nAA\nq\x00)\x81q\x01.' 62 63 with open('f:/c','wb') as f: 64 f.write(ser) 65 66 67 68 69 70 71 ''' 72 ----------------------------------- 73 <class 'int'> 99 74 <class 'str'> abc 75 ----------------------------------- 76 <class '__main__.AA'> <__main__.AA object at 0x00000000029AEEF0> 77 ----------------------------------- 78 <class '__main__.AA'> <__main__.AA object at 0x00000000029AEE80> 17895697 79 asda 80 ----------------------------------- 81 82 '''
3、序列化应用:
一般来说,本地序列化的情况,应用比较少,大多说场景都是在网络中传输。
将数据序列化后通过网络传输到远程结点,远程服务器上的服务奖接受到的数据反序列化后,就可以使用了
但是要注意,远程接收端,反序列化时必须有对应的数据类型,否则就会报错,尤其是自定义类,必须远程得有一致的定义
现在,大多数项目,都不是单机的,也不是单服务的,需要通过网络将数据传送到其他节点上去,这就需要大量的序列化,反序列化,
但是,python程序之间还可以都使用pickle解决,如果跨平台,,语言,协议,就不适合了,所以用公共协议:xml(很少用了)Json,Protocol Buffer等,看效率,还是使用方便简单,做相应的选择。
4、Json
文本的序列方案!!!!
Json ---js对象标记,是一种轻量级的数据交换格式。它基于ECMAScript(w3c)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据!
值:双引号引起来的字符串,数值,true和false, null,对象, 数组,这些都是值
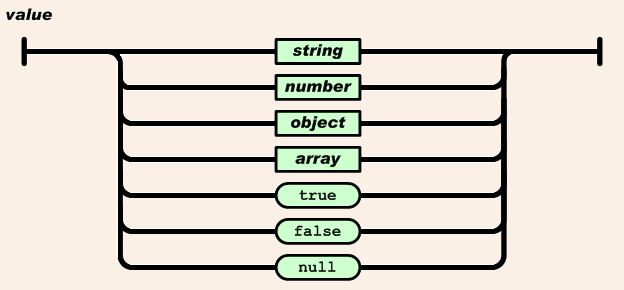
字符串:由双引号包围起来的任意字符的组合,可以有转义字符
数值:有正负,整,浮点
对象: 就是python中的字典,key必须是字符串
数组:就是python中的列表
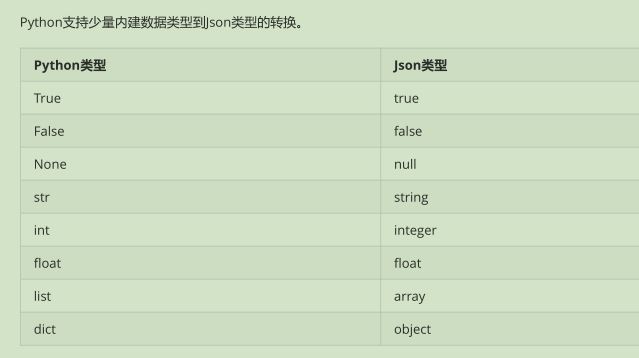
常用方法:
| Python类型 | Json类型 |
| dumps | json编码 |
| dump | json编码并存入文件 |
| loads | json解码 |
| load | json解码,从文件读取数据 |
1 import json 2 d = {'name':'tom','age':20,'id':123,'a':['b','c']} 3 4 j = json.dumps(d) 5 print(j) #"{"name": "tom", "age": 20, "id": 123, "a": ["b", "c"]}" 6 print(type(j)) # <class 'str'> 7 print('----------------------------------------------') 8 # 反序列化 9 d = json.loads(j) 10 print(d,type(d))
一般json 编码的数据很少落地,数据都是通过网络传输,传输的时候,要考虑压缩它
本质上,他就是一个文本,就是个字符串
5、MessagePack:
MessagePack 是一个基于二进制高效的对象序列化类库,可以跨语言通信
它可以向Json 那样,在许多种语言之间交换结构对象
但是,它比Json 更快,更轻巧
支持众多语言,兼容json 和pickle
对比序列化后的长度:
1 import json 2 import pickle 3 import msgpack 4 5 d = {'name':'tom','age':20,'id':123,'a':['b','c']} 6 7 tmp = pickle.dumps(d) 8 print(len(tmp)) #81 bytes 9 10 j = json.dumps(d) 11 print(len(j)) # 54 bytes 12 13 m = msgpack.dumps(d) 14 print(len(m)) # 26
所以 是选择简单易懂,易查错,还是效率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号