第六次作业
- 作业①:
(1)要求:
用requests和BeautifulSoup库方法爬取豆瓣电影Top250数据。
每部电影的图片,采用多线程的方法爬取,图片名字为电影名
了解正则的使用方法
code:
1、爬取电影信息
from bs4 import BeautifulSoup
import requests
import re
# 获取网页的内容
def get_html(URL):
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/79.0.3945.130 Safari/537.36'}
res = requests.get(URL, headers=header) # 获取网页,并带有伪装的浏览器头,一般好的网站会有检测是不是程序访问
res.encoding = res.apparent_encoding # 设置编码,防止乱码
return res.text # 返回网页的内容
def ana_by_bs4(html):
soup = BeautifulSoup(html, 'html.parser') # 注意需要添加html.parser解析
lis = soup.select("ol li") # 选择ol li标签
for li in lis:
id = li.find('em').text
title = li.find_all('span', class_='title')
name = title[0].text
director_actor = li.find('div', class_='bd').find('p').text.split('\n')[1].strip() # 导演和演员
strInfo = re.search("(?<=<br/>).*?(?=<)", str(li.select_one(".bd p")), re.S | re.M).group().strip() # 年份、国家、类型
infos = strInfo.split('/')
year = infos[0].strip() # 年份
area = infos[1].strip() # 国家,地区
genres = infos[2].strip() # 类型
rating = li.find('span', class_='rating_num').text # 评分
rating_num = li.find('div', class_='star').find_all('span')[3].text[:-3] # 评分人数
try:
quote = li.find('span', class_='inq').text # 名言
except: # 名言可能不存在
quote = ''
print(id, name, director_actor, year, area, genres, rating, rating_num, quote)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/79.0.3945.130 Safari/537.36'}
if __name__ == '__main__':
count=0
threads=[]
for page in range(10):
print('第{}页'.format(page + 1))
print('排名', '电影名称', '导演和主演', '年份', '地区', '类型', '评分', '评分人数','名言')
url = 'https://movie.douban.com/top250?start={}&filter='.format(page * 25) # 电影的url,有多页的时候需要观察url的规律
text = get_html(url) # 获取网页内容
ana_by_bs4(text) # bs4方式解析
# spider_douban250()
# for t in threads:
# t.join()
# print("The End")
2、爬取图片:
from urllib.request import urlopen
import re
import urllib
import threading
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie':'bid=wjbgW95-3Po; douban-fav-remind=1; __gads=ID=f44317af32574b60:T=1563323120:S=ALNI_Mb4JL8QlSQPmt0MdlZqPmwzWxVvnw; __yadk_uid=hwbnNUvhSSk1g7uvfCrKmCPDbPTclx9b; ll="108288"; _vwo_uuid_v2=D5473510F988F78E248AD90E6B29E476A|f4279380144650467e3ec3c0f649921e; trc_cookie_storage=taboola%2520global%253Auser-id%3Dff1b4d9b-cc03-4cbd-bd8e-1f56bb076864-tuct427f071; viewed="26437066"; gr_user_id=7281cfee-c4d0-4c28-b233-5fc175fee92a; dbcl2="158217797:78albFFVRw4"; ck=4CNe; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1583798461%2C%22https%3A%2F%2Faccounts.douban.com%2Fpassport%2Flogin%3Fredir%3Dhttps%253A%252F%252Fmovie.douban.com%252Ftop250%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.1583974348.1563323123.1572242065.1583798461.8; __utmb=30149280.0.10.1583798461; __utmc=30149280; __utmz=30149280.1583798461.8.7.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; __utma=223695111.424744929.1563344208.1572242065.1583798461.4; __utmb=223695111.0.10.1583798461; __utmc=223695111; __utmz=223695111.1583798461.4.4.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; push_noty_num=0; push_doumail_num=0; _pk_id.100001.4cf6=06303e97d36c6c15.1563344208.4.1583798687.1572242284.'}
base_url = 'https://movie.douban.com/top250?start=%d&filter='
class spider_douban250(object):
global threads
def __init__(self,url = None, start = 0, step = 25 , total = 250):
self.durl = url
self.dstart = start
self.dstep =step
self.dtotal = total
def start_download(self):
while self.dstart < self.dtotal:
durl = self.durl%self.dstart
print(durl)
self.load_page(durl)
self.dstart += self.dstep
def load_page(self,url):
req=urllib.request.Request(url=url,headers=headers)
req = urlopen(req)
if req.code != 200:
return
con = req.read().decode('utf-8')
listli = re.findall(r'<li>(.*?)</li>', con,re.S)
if listli:
listli = listli[1:]
else:
return
for li in listli:
imginfo = re.findall(r'<img.*?>', li)
if imginfo:
imginfo = imginfo[0]
info = [item.split('=')[1].strip()[1:-1] for item in imginfo.split(' ')[2:4]]
#self.load_img(info)
T = threading.Thread(target=self.load_img(info))
T.setDaemon(False)
T.start()
threads.append(T)
def load_img(self,info):
print("callhere load img:", info)
req = urllib.request.Request(url=info[1], headers=headers)
imgreq = urlopen(req,timeout=100)
img_c = imgreq.read()
path = r'E:\\image\\' + info[0] + '.jpg'
print('path:', path)
imgf = open(path, 'wb')
imgf.write(img_c)
imgf.close()
threads=[]
spider = spider_douban250(base_url,start=0,step=25,total=25)
spider.start_download()
for t in threads:
t.join()
print("The End")
结果:
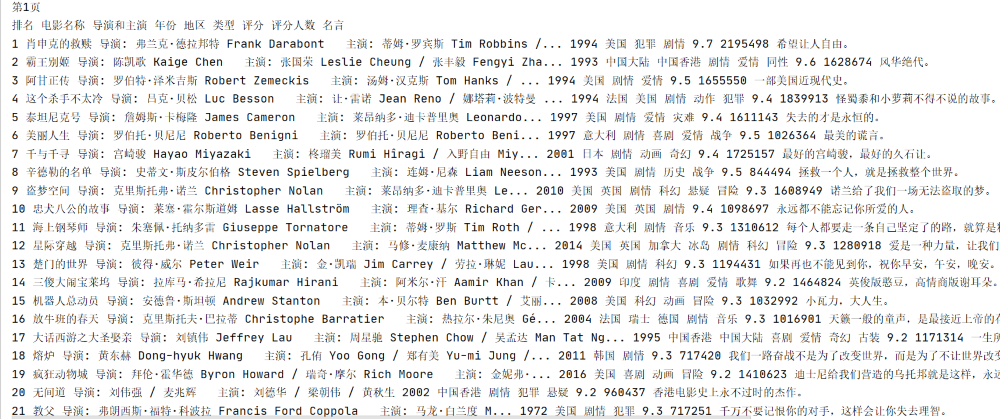


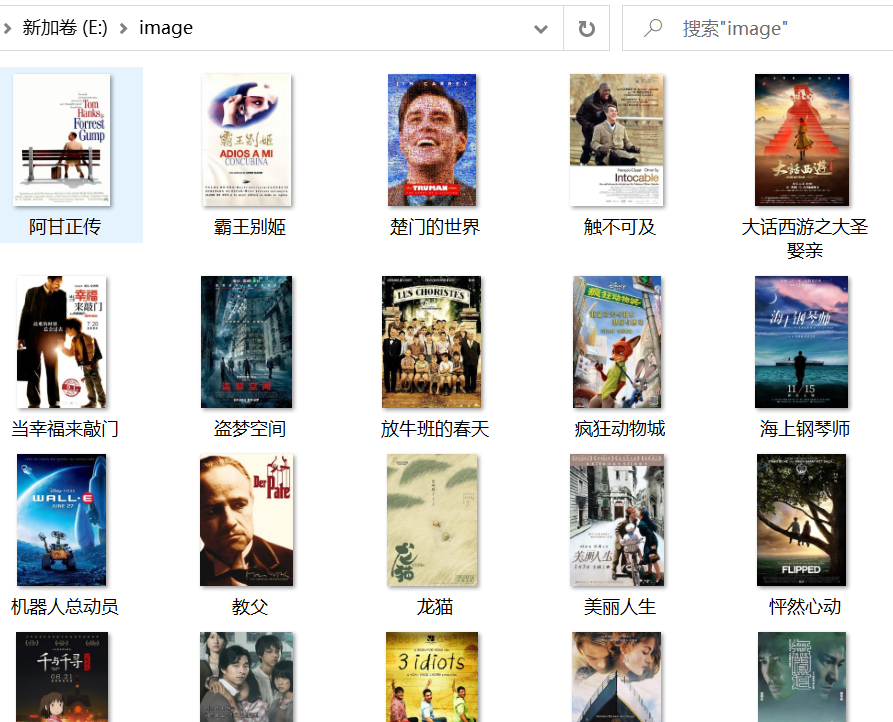
(2)心得体会:
可能是因为正则表达式之前掌握得也不是很好,所以现在用的时候,其实是已经有些遗忘了,临时又重新复习了一把。
- 作业②
(1)要求:
熟练掌握 scrapy 中 Item、Pipeline 数据的序列化输出方法;Scrapy+Xpath+MySQL数据库存储技术路线爬取科软排名信息
爬取科软学校排名,并获取学校的详细链接,进入下载学校Logo存储、获取官网Url、院校信息等内容。
code:
rank
from bs4 import UnicodeDammit
import scrapy
from ..items import RuankeItem
import urllib.request
import requests
from lxml import etree
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'
}
class RankSpider(scrapy.Spider):
name = 'rank'
start_url = 'https://www.shanghairanking.cn/rankings/bcur/2020'
def start_requests(self):
url = RankSpider.start_url
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
dammit = UnicodeDammit(response.body, ["utf-8", "gdk"])
data = dammit.unicode_markup
selector = scrapy.Selector(text=data)
lis = selector.xpath("//div[@class='rk-table-box']/table/tbody/tr")
cout = 0
for li in lis:
cout=cout+1
sNo=li.xpath("./td[position=1]/text()").extract_first()
sNo = str(sNo).strip()
schoolName=li.xpath("./td[@class='align-left']/a/text()").extract_first()
schoolName=str(schoolName).strip()
city=li.xpath("./td[position=3]/text()").extract_first()
city=str(city).strip()
mfile = str(cout) + '.png'
Url=li.xpath("./td[@class='align-left']/a//@href").extract_first()
urls='https://www.shanghairanking.cn/'
strurl=urllib.request.urljoin(Url)
data1 = UnicodeDammit(strurl, ["utf-8", "gbk"])
data2 = data1.unicode_markup
selector1 = scrapy.Selector(text=data2)
lssi = selector1.xpath("//div[@class='info-container']/tbody/tr")
officalUrl=lssi.xpath("./div[@class ='univ-website']/a/text()").extract_first()
info=lssi.xpath("./div[@class='univ-introduce'/p/text()").extract_first()
info = str(info).strip()
imgs=lssi.xpath("./td[@class='univ-logo'/ img")
for img in imgs:
url1 = img["src"] # src存储的是图片的名称
if (url1[len(url1) - 4] == "."): # 判断是否为目标文件(图片)
ext = url1[len(url1) - 4:] # 获取图片的格式jdp还是png
else:
ext = ""
req = urllib.request.Request(url1, headers=headers)
data2 = urllib.request.urlopen(req, timeout=100)
data2 = data2.read() # 进行图片的数据读
fobj = open("E:\\images\\" + str(count) + ext, "wb")
count = count + 1
fobj.write(data2) # 写数据
fobj.close() # 最后要关闭这个进程
item = RuankeItem()
item["sNo"] = sNo
item["schoolName"] = schoolName
item["city"] = city
item["offcialUrl"] = officalUrl
item["info"] = info
item["mfile"] = mfile
yield item
item:
import scrapy
class RuankeItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
sNo = scrapy.Field()
schoolName = scrapy.Field()
city = scrapy.Field()
officalUrl = scrapy.Field()
info = scrapy.Field()
mfile = scrapy.Field()
pipelines:
import pymysql
class RuankePipeline(object):
def open_spider(self, spider):
print("opened")
try:
self.con = pymysql.connect(host='localhost', port=3306, user="root", passwd="1394613257",
db="MyStock", charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("delete from ranks")
self.opened = True
self.count = 0
self.num = 1
except Exception as err:
print(err)
self.opened = False
def close_spider(self, spider):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
print("closed")
print("总共爬取", self.count, "大学")
def process_item(self, item, spider):
print(item['sNo'])
print(item['schoolName'])
print(item['city'])
print(item['officalUrl'])
print(item['info'])
print(item['mfile'])
print()
if self.opened:
n = str(self.num)
self.cursor.execute("insert into ranks(sNo,schoolName,city,officalUrl,info,mfile)values(%s,%s,%s,%s,%s,%s)",(item['sNo'],item['schoolName'],str(item['city']),str(item['officalUrl']),item['info'],item['mfile']))
self.count += 1
return item
图片:




(2)心得体会:
这一次的框架爬取的时候,出现不少的小意外,debug了好久的代码,可能是对于scrapy框架的学习掌握程度还不够,还需要再理清楚一点。另外在创建数据库的时候,还是要尽量考虑到存储内容的大小。
- 作业③:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素加载、网页跳转等内容。
使用Selenium框架+ MySQL数据库存储技术模拟登录慕课网,并获取学生自己账户中已学课程的信息并保存在MYSQL中。
其中模拟登录账号环节需要录制gif图。
code:
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.keys import Keys
import time
import pymysql
header = {
"User-Agent": "Mozilla/5.0(Windows;U;Windows NT 6.0 x64;en-US;rv:1.9pre)Gecko/2008072531 Minefield/3.0.2pre"}
url = "https://www.icourse163.org/"
def login():
driver = webdriver.Chrome()
driver.get(url)
driver.maximize_window()
begin = driver.find_element_by_xpath("//div[@class='unlogin']//a[@class='f-f0 navLoginBtn']")
begin.click()
time.sleep(1)
driver.find_element_by_xpath("//div[@class='ux-login-set-scan-code_ft']//span[@class='ux-login-set-scan-code_ft_back']").click()
time.sleep(1)
driver.find_element_by_xpath("//ul[@class='ux-tabs-underline_hd']//li[@class='']").click()
time.sleep(1)
frame1 = driver.find_element_by_xpath("//div[@class='ux-login-set-container']//iframe")
driver.switch_to.frame(frame1)
username = driver.find_element_by_xpath("//input[@id='phoneipt']")
username.send_keys('1*********')
time.sleep(1)
driver.find_element_by_xpath("//input[@placeholder='请输入密码']").send_keys("*******")
time.sleep(1)
driver.find_element_by_xpath("//div[@class='f-cb loginbox']//a[@id='submitBtn']").click()
time.sleep(2)
# click myCourse
driver.find_element_by_xpath("//div[@class='u-navLogin-myCourse-t']//span[@class='nav']").click()
time.sleep(2)
lis = driver.find_elements_by_xpath("//div[@class='course-card-wrapper']")
No = 0
for li in lis:
li.click()
time.sleep(3)
curr_window = driver.window_handles[-1]
driver.switch_to.window(curr_window)
time.sleep(2)
driver.find_element_by_xpath('//*[@id="g-body"]/div[3]/div/div[1]/div/a[1]').click()
curr_window1 = driver.window_handles[-1]
driver.switch_to.window(curr_window1)
time.sleep(2)
No = No + 1
cNo = No
try:
Course = driver.find_element_by_xpath("//span[@class='course-title f-ib f-vam']").text
College = driver.find_element_by_xpath("//a[@data-cate='课程介绍页']").get_attribute("data-label")
Teacher = driver.find_element_by_xpath("//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']").text
Count = driver.find_element_by_xpath("//span[@class='course-enroll-info_course-enroll_price-enroll_enroll-count']").text
Process = driver.find_element_by_xpath("//div[@class='course-enroll-info_course-info_term-info_term-time']//span[position()=2]").text
Brief = driver.find_element_by_xpath("//div[@class='course-heading-intro_intro']").text
t = 0
Team = ''
while (True):
try:
Teammerber = driver.find_elements_by_xpath("//div[@class='um-list-slider_con_item']//h3[@class='f-fc3']")[t].text
Team += Teammerber + ' '
t += 1
except:
break
time.sleep(1)
print(cNo, Course, College, Teacher, Team, Count, Process, Brief)
except Exception as err:
print(err)
Course = ""
College = ""
Teacher = ""
Team = ""
Count = ""
Process = ""
Brief = ""
insertDB(cNo, Course, College, Teacher, Team, Count, Process, Brief)
time.sleep(2)
# 关闭当前页
driver.close()
curr_window = driver.window_handles[-1]
driver.switch_to.window(curr_window)
driver.close()
time.sleep(2)
# 回到之前页面
backwindow = driver.window_handles[0]
time.sleep(2)
driver.switch_to.window(backwindow)
time.sleep(2)
def startUp(self):
try:
self.con = pymysql.connect(host="localhost", port=3306, user="root", passwd="1394613257", db="MyDB",
charset="utf8")
self.cursor = self.con.cursor(pymysql.cursors.DictCursor)
self.cursor.execute("DROP TABLE IF EXISTS mooc2")
# 创建表
self.cursor.execute("CREATE TABLE IF NOT EXISTS mooc2(cNo INT PRIMARY KEY,"
"Course VARCHAR(256),"
"College VARCHAR(256),"
"Teacher VARCHAR(256),"
"Team VARCHAR(256),"
"Count VARCHAR(256),"
"Process VARCHAR(256),"
"Brief VARCHAR(1024))")
self.opened = True
self.No = 0
except Exception as err:
print(err)
self.opened = False
def closeUp(self):
if self.opened:
self.con.commit()
self.con.close()
self.opened = False
self.driver.close()
print("closed")
def insertDB(cNo, Course, College, Teacher, Team, Count, Process, Brief):
try:
sql = "insert into mooc2 (cNo, Course, College, Teacher, Team, Count, Process, Brief) values (?,?,?,?,?,?,?,?)"
insertDB.cursor.execute(sql, (cNo, Course, College, Teacher, Team, Count, Process, Brief))
except Exception as err:
print(err)
# (cNo varchar(32) primary key, Course varchar(256),College varchar(256),Teacher varchar(256),Team varchar(256),Count varchar(256),Process varchar(256),Brief varchar(1024))"
def main():
print("Spider starting......")
login()
startUp()
print("Spider closing......")
closeUp()
print("Spider completed......")
if __name__ == '__main__':
main()
GIF:
结果:


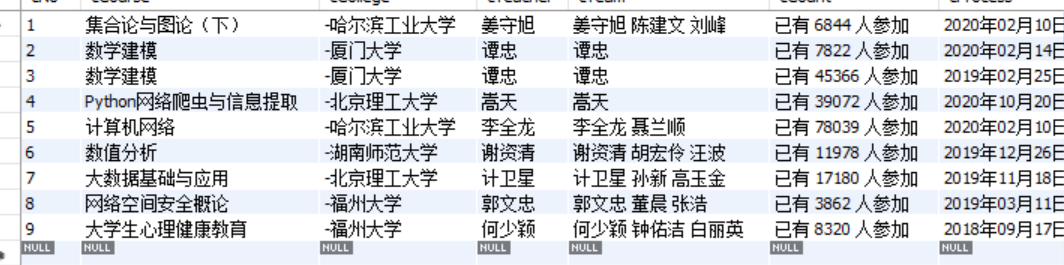
(2)心得体会:
在爬取自己个人中心的过程的时候,一开始代码一直走到进到这个界面就结束了,还以为是xpath那边解析错误,搞了好久,最后才发现是进去这个页面后,忘记衔接下一步的click操作了,还是需要好好的学习练习啊。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号