我对NHibernate的感受(4):令人欣喜的Interceptor机制
2009-10-13 13:45 Jeffrey Zhao 阅读(22895) 评论(68) 收藏 举报之前谈了NHibernate的几个方面,似乎抱怨的居多,不过这次我想谈一下我对Interceptor的感受,则基本上都是好话了。这并不一定是说Interceptor设计的又多么好(事实上它使用起来还是挺麻烦的),但是这的确也是我认为NHibernate超越LINQ to SQL,尤其是Entity Framework的又一个重要方面——因为Entity Framework本身也已经不差了。更重要的是,Interceptor机制让我得以实现我“理想中的”数据访问功能。当然现在只是浅尝辄止一番,我打算以后再慢慢地,详细地谈谈我所满意的“数据访问层”设计。
Interceptor的作用是为NHIbernate中的Session(如LINQ to SQL中的DataContext)增加一个“拦截器”,这个拦截器会捕获到Session各个阶段所发生的事情,并且有机会访问到它们所牵涉到的数据。例如:
- OnLoad:当前Session加载了哪些对象
- OnDelete:当前Session删除了哪些对象
- OnSave:Session保存了哪些对象
- PostFlush:当前Session的Flush已经完成了
关于Interceptor功能,NHibernate的文档上只是一笔带过,更详细的信息可以参考Hibernate的API说明。由于Interceptor可以记录到Session中所经过的所有对象,因此它可以做的事情就很多了。例如已经被人写滥的“日志记录”或“审查(Audit)”,但好像少有人把它真正用在数据访问的功能上。我了解Interceptor之后感觉非常兴奋,因为终于有人为我想要实现的功能做好铺垫了。这个功能便是“结合其它数据访问机制”。
说到数据访问层,大家肯定知道它的职责是“从数据源读写数据”。在很长一段时间内,这个数据源基本上就是关系型数据库,无论是商业的SQL Server,Oracle还是开源的MySQL,PostgreSQL,万变不离其宗。于是有人提出了SqlHelper,Data Access Block这样的数据库读取辅助工具、iBatis这样的SQL-对象映射工具(我不认为它是ORM)、还有NHibernate、LINQ to SQL这样的ORM框架。但是无论是什么工具,无论怎么访问,数据访问层作的事情也无非是SQL、SQL、SQL,然后再把得到的数据集转化为内存中的对象。
但是到了如今的时代,数据访问层所负责的数据源已经远远不止这些了。例如,许超前在博客上介绍了手机之家的数据访问层功能,这是其中一幅截图:
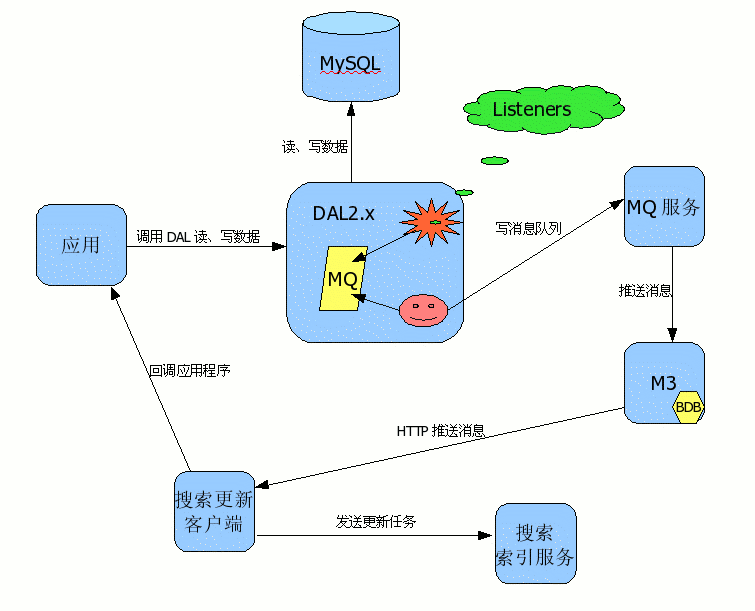
这是个目前比较典型的数据访问层功能,它除了访问关系型数据库之外,可能还需要访问异步消息队列(如MSMQ、ActiveMQ)、K/V存储(如Memcached,Tokyo Cabinet)或是其他文档型数据库(如MongoDB、CouchDB)。也就是说,我们在将数据存入关系型数据库的时候,可能还要添加一条异步消息,或是同步到其他存储方式中——而Interceptor便为我们提供了这样的可能。
例如,这是一个ArticleInterceptor的结构:
public class ArticleInterceptor : EmptyInterceptor { public override bool OnLoad(object entity, object id, ...) { var article = entity as Article; if (article == null) return false; // 记下所有加载的ArticleID return false; } public override void OnDelete(object entity, object id, ...) { var article = entity as Article; if (article == null) return; // 记下所有删除的ArticleID } public override void PostFlush(ICollection entities) { foreach (var article in entities.OfType<Article>()) { // 进行对比,将修改,创建或删除的Article内容提交至Lucene索引 } } }
NHibernate的优点之一是“自动跟踪”对象状态,而Interceptor也给我们这样插一手的机会。利用如上的ArticleInterceptor,我们就可以知道Session中修改了哪些Article对象,并且在Flush操作之后同步至Lucene索引。当然,这只是一个示例(事实上Lucene索引只能接受单个线程的写),具体情况需要根据各自需求来进行改变。而其中更关键的问题,可能便是“事务”了。
PostFlush会在Session的Flush操作完成之后调用,但是这时候当前数据库事务可能并没有完成——这可能是因为程序在使用NHibernate的时候选择了外部控制事务的方式,这个事务可能跨Session等等。于是,如果是像外部数据源的更新,它往往不会“卷入”当前的数据库事务(可能是做不到,也可能是故意避免分布式事务),因此如果它在PostFlush操作中就完成的写入,那么如果当前事务回滚之后,外部数据源的更新能一起撤销吗?
不过,对于程序员来说,这些应该都不是问题。例如,我们可以在PostFlush之后“纪录”需要更新的内容,然后在整个事务已经确保成功的时候才写入外部数据源。总之,要根据不同项目的需求来确定。
利用NHibernate的Interceptor,其实我们还可以在这方面做更多的文章。例如,我们可以把Article对象的Content数据放入K/V存储内,这样可以减少关系型数据库中表的每一行的大小,有利于性能的提高。然后在加载Article对象的时候,我们在Interceptor的OnLoad方法中可以再将Article的Content数据读回从K/V存储内读取回来。
因此在我看来,我们使用Interceptor,完全可以将NHibernate这个ORM框架打造成一个Object-Any-Mapping工具,将对象与“任何”存储方式进行映射。在大约两个月前,我想,如果我真要构建一个这样的OAM框架,我又该怎么做呢?
只不过,我想着想着最后放弃了。因为这样的框架实在过于复杂。因为在我的想法中,如果使用通用的OAM框架,需要能够支持多种数据源,并且可以将一个对象分为多个部分,分别放入不同的数据源中。在查询的时候,还可以根据不同数据源的特征选择查询方式(例如,全文查找去Lucene,根据ID获取数据则通过K/V存储,其他可能就是关系型数据库或是文档数据库了)——甚至于还会自动从不同数据源中获取数据后,在内存中作JOIN。
这些都是实际开发过程中所需要的真实功能,但是一个像NHibernate这样的ORM框架已经如此复杂了,这样的OAM的“可行性”如何……我想大家也都有思考结果。虽然Hibernate也已经有一些通用的框架,如Hiberante Search集成了Lucene,Hibernate Sharding可以支持自动的数据库划分,但是它们的“通用性”真有Hibernate这样高吗?我对此表示怀疑。
因此,就目前而言,我认为最可行的方式,可能就是基于NHibernate这样强有力的ORM框架打造的数据访问层,至于内部“在哪个时机选择什么样的数据操作方式”,还是由数据访问层本身根据自身需要来吧。由于不需要“通用”,这样的数据访问层可以变得相对简单很多。
由于存储方式的不断出现,对合适的操作选择合适的存储方式已经是一个重要的课题,因此数据访问层的构建也已经越来越重要,它不仅仅是无聊的CRUD操作了——反而是对于一些项目由于没有复杂的逻辑,它的“业务逻辑层”会显得非常薄。您的数据访问层是如何构建的,能分享一下这方面的经验吗?
在今后的文章中,我也会有更多展开的。
相关文章
- 我对NHibernate的感受(1):对延迟加载方式的误解
- 我对NHibernate的感受(2):何必到处都virtual
- 我对NHibernate的感受(3):有些尴尬的集合支持
- 我对NHibernate的感受(4):令人欣喜的Interceptor机制

 浙公网安备 33010602011771号
浙公网安备 33010602011771号